기계번역은 한동안 범용 LLM의 부가 기능처럼 보였다.
GPT류 모델이 대부분의 언어 쌍에서 꽤 괜찮은 번역을 내놓기 시작하면서, 별도의 번역 전용 모델을 만드는 이유가 약해진 것처럼 보였기 때문이다.
하지만 실제 제품 환경으로 들어가면 이야기가 달라진다.
법률·금융·의학 용어, 웹페이지와 회의록 같은 잡음 많은 입력, “용어집을 반드시 지켜라”, “태그와 레이아웃은 보존하라” 같은 번역 전용 지시를 안정적으로 따라야 한다.
Tencent Hunyuan의 Hy-MT2는 이 지점을 정면으로 겨냥한 공개 모델 패키지다.
공식 README와 기술 보고서는 Hy-MT2를 “fast-thinking” 다국어 번역 모델 패밀리로 설명하며, 1.8B, 7B, 30B-A3B MoE 세 가지 크기를 함께 내놓았다.
보고서 기준으로는 33개 언어 간 번역을 지원한다고 설명하고, README의 supported languages 표는 한국어를 포함한 여러 언어·문자 변형을 열거한다.
가장 눈에 띄는 포인트는 단순히 큰 번역 모델을 하나 공개한 것이 아니라는 점이다.
Hugging Face 컬렉션에는 BF16 계열 모델, FP8 변형, GGUF 변형, 1.8B의 2-bit와 1.25-bit GGUF, 그리고 번역 instruction-following 벤치마크인 IFMTBench가 함께 올라와 있다.
특히 AngelSlim 1.25-bit 양자화 버전은 README에서 1.8B 모델의 저장 용량을 440MB 수준으로 줄이고 추론 속도도 1.5배 개선한다고 설명한다.
실제 Hugging Face 파일 HEAD 기준 Hy-MT2-1.8B-1.25Bit.gguf는 461,860,736 bytes, 즉 약 440.5MiB다.
무엇을 해결하려는가
Hy-MT2가 겨냥하는 첫 번째 병목은 범용 LLM 번역과 실무 번역 사이의 간극이다.
일반 대화형 모델은 문맥을 이해하고 자연스러운 문장을 만드는 데 강하지만, 번역 제품에서 중요한 것은 항상 자연스러움만은 아니다.
용어집 준수, 숫자와 형식 보존, 코드·태그 유지, 특정 문체 지시, 도메인별 고정 번역 같은 요구가 함께 들어온다.
보고서는 Hy-MT1.5 이후 실제 커뮤니티와 비즈니스 피드백에서 domain-specific translation, real-world scenario translation, translation instruction following, on-device deployment에 개선 여지가 드러났다고 정리한다.
두 번째 병목은 비용과 배포다.
번역은 채팅봇처럼 한 번씩 호출되는 기능이 아니라, 문서·메신저·브라우저·자막·모바일 입력기 안에서 대량으로 발생할 수 있다.
클라우드 API만으로 처리하면 지연, 비용, 개인정보, 오프라인 사용성 문제가 남는다.
Hy-MT2가 1.8B 모델과 1.25-bit GGUF를 함께 강조하는 이유도 여기에 있다.
모델 품질을 끌어올리는 동시에, 작은 단말에서도 로컬 번역기로 쓸 수 있는 형태를 만들려는 시도다.
세 번째 병목은 번역 전용 평가다.
범용 instruction-following 벤치마크만으로는 “번역 중 지시를 잘 따르는가”를 충분히 재기 어렵다.
Tencent는 이번 릴리스에서 IFMTBench를 함께 공개했다.
IFMTBench README 기준 이 벤치마크는 glossary compliance, style following, background disambiguation, layout preservation, structured data, code/tag preservation 등 6개 constraint type을 다룬다.
즉 번역 품질만 보는 것이 아니라, 번역 과정에서 지시와 형식을 얼마나 잘 지키는지 보려는 평가 축이다.
핵심 아이디어 / 구조 / 동작 방식
Hy-MT2의 학습 구조는 크게 세 단계로 읽을 수 있다.
첫째는 MT-oriented mid-training이다.
기술 보고서는 Hy-series pretraining model에서 출발해 약 1T tokens의 대규모 multilingual translation-related data로 계속 학습한다고 설명한다.
이 단계는 일반 모델을 번역 작업에 맞는 공통 출발점으로 바꾸는 역할을 한다.
둘째는 Family-Centric Post-training, FCPT다.
Hy-MT2는 모든 언어를 하나의 큰 덩어리로 섞어 후처리하지 않고, 언어 family를 기준으로 branch를 나누어 다룬다.
보고서는 Western European, East Asian, Middle Eastern right-to-left languages 같은 다양한 언어 그룹을 예로 든다.
각 family branch 안에서 일반 번역 데이터, 도메인 특화 번역 데이터, real-world business scenario 데이터, translation instruction-following 데이터를 섞어 family-specific teacher를 만든다는 설명이다.
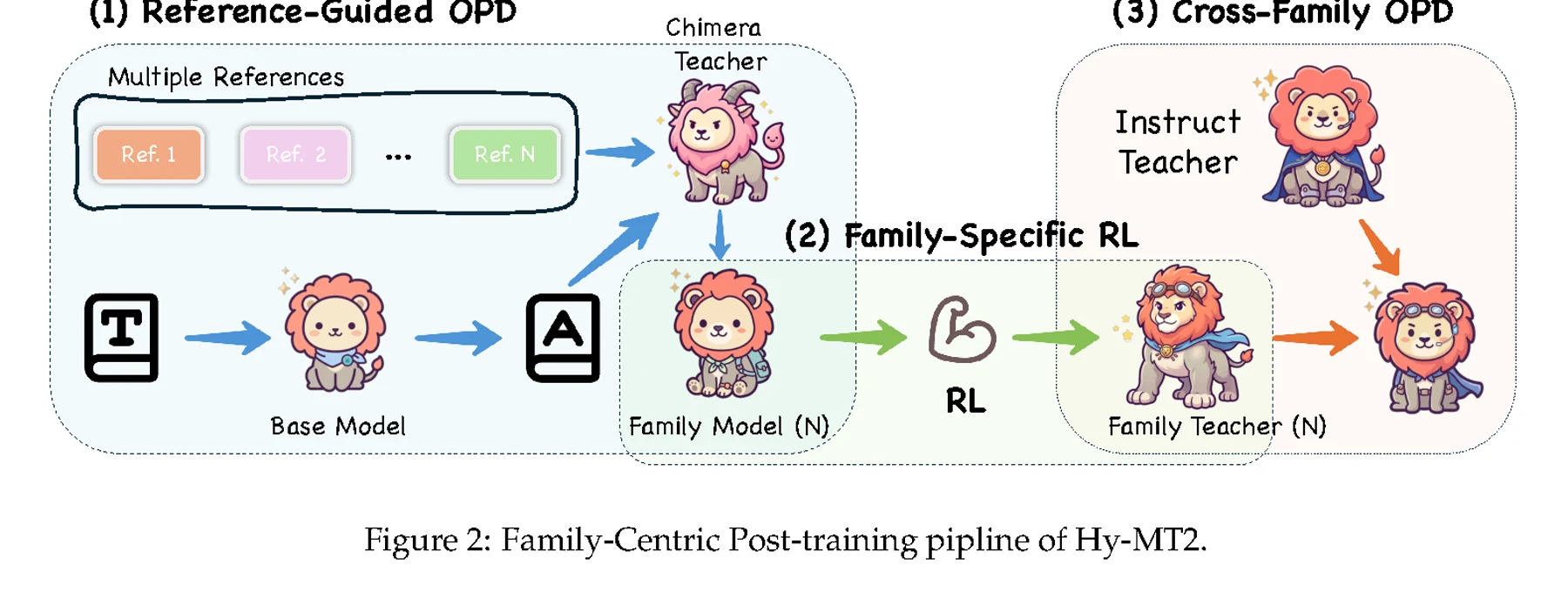
FCPT 내부는 다시 세 과정으로 나뉜다.
Reference-Guided On Policy Distillation은 여러 Hy-series reference model과 원래 데이터 라벨을 결합해 Chimera Teacher를 구성한다.
Family-specific RL Training은 family branch별로 번역 선호와 언어적 특성을 더 맞춘다.
마지막 Cross-family On Policy Distillation은 여러 family teacher의 능력을 다시 통합 student model로 이전하면서, 번역 밖 일반 instruction-following 능력도 보존하려 한다.
요약하면 Hy-MT2의 핵심은 “언어권별 강한 번역 교사들을 만든 뒤, 다시 하나의 범용 번역 모델 패밀리로 압축하는” 설계다.
셋째는 양자화와 배포 패키징이다.
README는 AngelSlim을 large model compression toolkit으로 소개하고, Hy-MT2 모델 링크에는 FP8, GGUF, 2-bit GGUF, 1.25-bit GGUF가 함께 올라와 있다.
다만 1.25-bit GGUF README는 해당 GGUF가 Tencent의 STQ kernel에 의존하며 llama.cpp PR #22836을 언급한다.
따라서 “그냥 모든 llama.cpp 환경에서 즉시 돌아가는 초경량 파일”이라기보다, 특정 저비트 커널 지원까지 함께 봐야 하는 배포물에 가깝다.
| 구성 요소 | 공개 자료에서 확인되는 내용 | 해석 |
|---|---|---|
| Hy-MT2-1.8B | BF16/safetensors, FP8, GGUF, 2-bit GGUF, 1.25-bit GGUF | 온디바이스·로컬 번역을 가장 강하게 겨냥한 축 |
| Hy-MT2-7B | BF16/safetensors, FP8, GGUF | 품질과 배포 비용의 중간 지점 |
| Hy-MT2-30B-A3B | MoE, BF16/safetensors, FP8 | 최고 품질을 노리는 큰 번역 모델 축 |
| IFMTBench | 6개 constraint type의 번역 instruction-following 벤치마크 | 번역 품질과 지시 준수를 함께 평가 |
| AngelSlim | FP8·저비트·GGUF 양자화 변형과 연결 | 모델 릴리스를 압축·단말 배포까지 확장 |
공개된 근거에서 확인되는 점
공식 결과에서 Hy-MT2는 꽤 공격적인 주장을 한다.
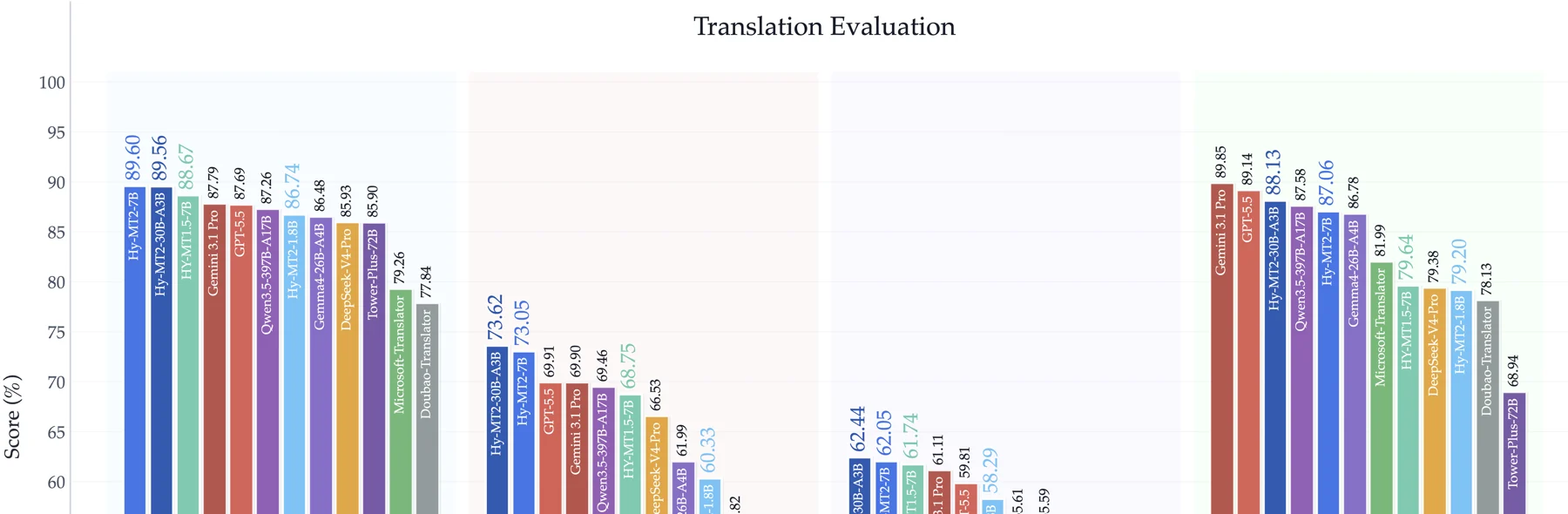
기술 보고서는 FLORES-200의 XX↔XX 설정에서 Hy-MT2-1.8B, 7B, 30B-A3B가 각각 79.77, 86.89, 87.47을 기록했으며, 이는 Gemini 3.1 Pro T 대비 89.9%, 97.9%, 98.6% 수준이라고 적는다.
같은 문단에서 7B와 30B-A3B는 DeepSeek-V4-Pro, Kimi K2.6, Qwen3.5-397B-A17B, Gemma4-26B-A4B 같은 강한 baseline을 해당 설정에서 앞선다고 설명한다.
WMT25에서도 7B는 63.86 / 71.21 / 82.24, 30B-A3B는 62.89 / 71.08 / 84.34를 보고한다.
보고서 표현을 그대로 옮기면 30B-A3B는 비교 대상 중 GEMBA 점수에서 가장 높은 값을 냈고, Hy-MT1.5-7B 대비 7B 모델은 세 지표 모두 개선됐다.
다만 이런 수치는 모두 공식 보고서의 평가 프로토콜 안에서 읽어야 한다.
제3자 재현이나 독립 리더보드 결과와 같은 의미로 받아들이면 과하다.
DomainMTBench와 WildMTBench 결과도 Hy-MT2의 포지션을 잘 보여준다.
WildMTBench에서 Hy-MT2-7B는 90.28 / 88.93, 30B-A3B는 89.87 / 89.25를 기록했다고 보고서는 적는다.
특히 30B-A3B는 LLM-based evaluation인 GEMBA에서 Gemini 3.1 Pro를 넘었다고 주장한다.
1.8B 모델 역시 WildMTBench에서 Hy-MT1.5-1.8B 대비 GEMBA가 80.84에서 86.04로 올랐고, Microsoft Translator와 Doubao Translator 같은 상용 번역 시스템보다 우세하다고 설명한다.
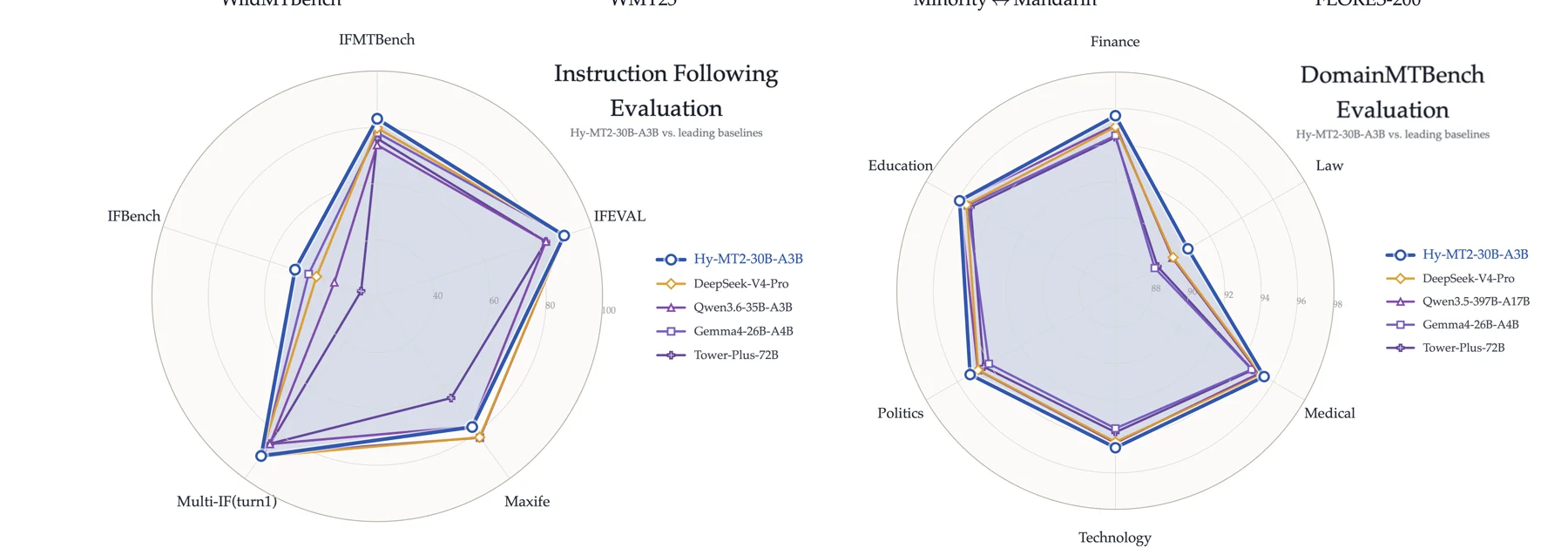
IFMTBench에서는 번역 전용 instruction-following의 차이가 더 직접적으로 드러난다.
보고서 기준 Hy-MT2-7B는 Simple / Complex / Total에서 89.73 / 72.67 / 83.14, Hy-MT2-30B-A3B는 90.20 / 75.94 / 84.69를 기록한다.
반면 일반 instruction-following benchmark에서는 Multi-IF 후속 turn에서 일부 비교 모델보다 낮은 구간도 있다고 보고서가 스스로 적는다.
이 점은 중요하다.
Hy-MT2의 장점은 “모든 지시 따르기에서 최고”라기보다, 번역 작업 안에서의 제약 준수와 품질에 집중된 것으로 읽는 편이 맞다.
릴리스 표면도 함께 봐야 한다.
GitHub API 기준 저장소 Tencent-Hunyuan/Hy-MT2는 2026-05-18에 생성됐고, 2026-05-21 현재 stars 54, forks 4, open issues 0으로 확인된다. /releases/latest는 404이고 /tags는 비어 있다.
루트에는 README.md, IFMTBench, train, imgs, LICENSE.txt, LICENSE-IFMTBench.txt가 있으며 공식 보고서는 arXiv 2605.22064로 제공된다.
즉 모델·보고서·벤치마크·학습 문서는 공개됐지만, 아직 태그가 붙은 안정 릴리스 형태라기보다는 막 공개된 연구/모델 패키지에 가깝다.
라이선스도 “오픈소스”라는 단어만으로 뭉뚱그리면 안 된다.
GitHub API의 license 필드는 NOASSERTION으로 잡히며, LICENSE.txt는 Tencent HY Community License Agreement다.
이 라이선스는 EU에는 적용되지 않는다고 명시하고, acceptable use policy를 포함한다.
반면 IFMTBench는 별도 LICENSE-IFMTBench.txt에서 CC-BY-4.0으로 공개됐다고 설명한다.
모델 가중치, 코드, 벤치마크 데이터의 라이선스 성격을 분리해서 봐야 하는 이유다.
Hugging Face 컬렉션 API 기준으로는 tencent/hy-mt2 컬렉션에 11개 항목이 들어 있다.
30B-A3B, 7B, 1.8B 기본 모델과 FP8/GGUF 변형, IFMTBench dataset이 포함되며 컬렉션 자체는 gated가 아니다.
다만 공개 직후라 다운로드 수는 아직 매우 작다.
2026-05-21 현재 API 기준 기본 모델 다운로드 수는 30B-A3B 43, 7B 19, 1.8B 17 수준이다.
이는 인기의 부재라기보다 릴리스 직후의 초기 카운터로 보는 편이 자연스럽다.
실무 관점에서의 해석
내가 보기에 Hy-MT2의 핵심 의미는 번역 모델을 다시 “전용 시스템”으로 끌어올렸다는 데 있다.
최근에는 범용 LLM이 번역까지 잘하니, 별도 MT 모델은 과거 인프라처럼 보이기 쉽다.
하지만 실제 번역 제품은 품질뿐 아니라 비용, latency, 형식 보존, instruction compliance, 개인정보, 오프라인성까지 요구한다.
Hy-MT2는 이 요구를 하나의 큰 모델 점수 경쟁이 아니라, 모델 패밀리·벤치마크·양자화·학습 문서까지 묶은 배포 패키지로 다룬다.
특히 1.8B + 1.25-bit GGUF 조합은 온디바이스 번역의 상상력을 자극한다.
440MiB급 번역 모델이 충분한 품질을 낼 수 있다면 브라우저, 메신저, 회의록, 자막, 문서 뷰어에서 “서버에 보내지 않는 번역”이 훨씬 현실적인 선택지가 된다.
공식 README가 on-device deployment와 440MB급 1.25-bit 변형을 함께 강조하는 이유도 여기에 있다.
다만 운영 관점에서는 아직 조심스럽다.
첫째, 저비트 GGUF는 STQ kernel 의존성을 갖는다.
즉 범용 llama.cpp 생태계의 모든 실행 경로에서 즉시 같은 성능을 낸다고 가정하면 안 된다.
둘째, GitHub release/tag가 없고 저장소가 막 공개된 상태라 버전 안정성은 아직 약하다.
셋째, 공식 보고서의 강한 성능 주장은 중요하지만, 독립 평가와 실제 제품 로그에서 같은 양상이 반복되는지는 별도 검증이 필요하다.
라이선스도 실무 의사결정에서 중요한 변수다.
모델은 Tencent HY Community License Agreement 아래 공개되고, IFMTBench는 CC-BY-4.0으로 따로 공개된다.
상용 제품, EU 배포, hosted service, 파생 모델 학습, 벤치마크 데이터 재사용을 고민하는 팀이라면 “Hugging Face에 올라와 있다”는 사실만으로 충분하지 않다.
어떤 항목을 어떤 용도로 쓰는지에 따라 라이선스 검토가 달라진다.
그럼에도 Hy-MT2는 꽤 선명한 방향을 보여준다.
범용 LLM이 번역을 흡수하는 흐름과 별개로, 번역이라는 고빈도·저지연·제약 많은 작업은 여전히 전용 모델과 전용 평가, 전용 압축 스택을 요구한다.
Hy-MT2는 그 스택을 한 번에 공개한 사례다.
앞으로 번역 제품의 경쟁은 “가장 큰 모델이 가장 좋은 번역을 한다”보다, “충분히 작은 모델이 얼마나 많은 실무 제약을 안정적으로 지키는가”로 옮겨갈 가능성이 크다.