Reddit r/vibecoding에 올라온 SmallCode 소개 글은 꽤 강한 숫자로 시작한다. 작성자는 Gemma 4 계열의 4B active-parameter 모델로 100개 벤치마크 과제 중 87개를 통과했다고 주장한다. Cursor, Claude Code, OpenCode 같은 도구가 사실상 frontier model을 전제로 설계되어 있어서, 로컬 소형 모델을 붙이면 tool call이 깨지고, context가 넘치고, multi-step task가 무너진다는 문제의식에서 출발했다는 설명이다.
흥미로운 지점은 숫자 자체보다 설계 방향이다. SmallCode는 “작은 모델도 충분히 똑똑하다”고 말하는 프로젝트라기보다, 작은 모델이 잘 못하는 일을 runtime harness가 대신 흡수하면 어디까지 갈 수 있는가를 묻는 프로젝트에 가깝다. compound tool, error feedback loop, failure decomposition, token budgeting, code graph retrieval, optional cloud escalation 같은 장치가 모두 같은 방향을 본다. 모델에게 더 긴 생각을 요구하는 대신, 모델이 헷갈릴 상황을 줄이는 것이다.
따라서 이 글은 SmallCode를 “87%를 찍은 신형 코딩 에이전트”로만 보지 않는다. 공개된 GitHub 저장소, npm package, benchmark 파일, 비교 문서, 보안 문서를 기준으로 보면 더 정확한 해석은 이렇다. SmallCode는 소형 로컬 LLM을 위한 agent harness engineering 실험이며, 공개 벤치마크 숫자는 강하지만 아직은 매우 이른 release maturity와 자체 평가 한계를 함께 읽어야 한다.
무엇을 해결하려는가
현재 코딩 에이전트 생태계의 기본 가정은 꽤 무겁다. 모델은 긴 context를 견디고, JSON tool call을 안정적으로 내고, 35단계 작업을 기억하며, 실패 로그를 보고 다시 고칠 수 있어야 한다. Claude, GPT, Gemini 계열 frontier model이라면 이 가정이 어느 정도 맞지만, 7B20B 로컬 모델에서는 작은 균열이 빠르게 누적된다.
SmallCode의 문제의식은 여기서 나온다. 로컬 모델은 privacy, latency, 비용, offline 사용성에서 매력이 있지만, agent loop 안에서는 “그냥 endpoint만 바꾸면 된다”가 잘 통하지 않는다. 작은 모델은 긴 파일을 한 번에 읽으면 핵심을 놓치고, tool schema가 길면 instruction budget이 줄고, full-file rewrite를 시키면 truncation이나 drift가 생긴다. 그래서 SmallCode는 모델을 키우는 대신 모델 주변의 실행 환경을 더 강하게 구조화한다.
이 관점은 최근 agent harness 논의와 맞닿아 있다. 코딩 에이전트의 성능은 base model 하나로 결정되지 않는다. 어떤 tool을 노출하는지, tool 결과를 얼마나 줄여서 보여 주는지, 실패를 누가 판정하는지, verification signal이 다음 시도에 어떻게 들어가는지가 모두 성능의 일부다. SmallCode의 차별점은 이 원칙을 “frontier model을 더 잘 쓰기 위한 하네스”가 아니라 작은 로컬 모델을 실용 구간으로 끌어올리기 위한 하네스로 적용한다는 데 있다.
핵심 아이디어 / 구조 / 동작 방식
공식 README 기준 SmallCode는 npm install -g smallcode 또는 npx smallcode로 실행하는 terminal-native coding agent다. Node.js 18+를 요구하고, LM Studio, Ollama, OpenAI-compatible endpoint를 모델 backend로 붙이는 방식을 안내한다. 루트 package.json은 bin/smallcode.js를 CLI entrypoint로 노출하고, programmatic API는 src/api/index.js에서 제공한다고 적고 있다.
구조상 핵심은 단순 chat loop가 아니라 executor, tools, model_client, governor, escalation, mcp_bridge, session, plugins, skills로 나뉜 harness다. README의 디렉터리 설명은 bin/smallcode.js를 agent loop와 TUI orchestration의 중심으로 두고, governor.js가 tool scoring, verification, decompose를 맡는다고 설명한다. 즉 SmallCode가 파는 것은 모델 자체가 아니라 모델을 감싸는 runtime policy다.
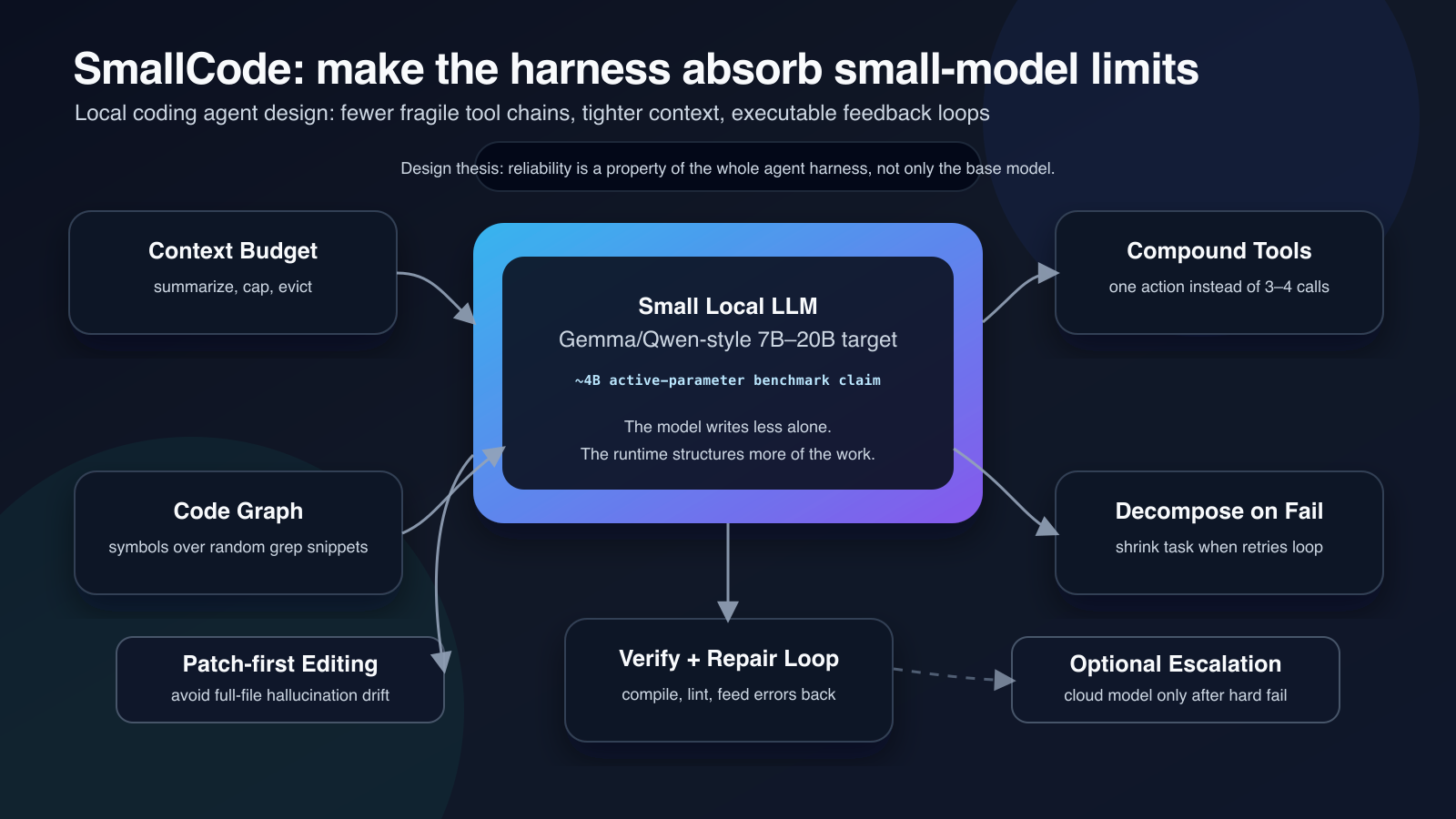
SmallCode가 강조하는 설계 선택을 줄이면 다음과 같다.
| 설계 장치 | 무엇을 줄이는가 | 공개 문서에서 확인되는 설명 |
|---|---|---|
| Compound tools / BoneScript | 작은 모델이 3~4개 tool call을 순서대로 이어 가다 망가지는 문제 | .bone 하나로 backend project를 생성하거나, read→edit→verify 같은 연쇄를 더 큰 단위 tool로 묶는 방향 |
| Improvement loop | “한 번에 맞춰야 한다”는 부담 | 코드 작성 뒤 compile/lint/validation 결과를 즉시 feedback으로 돌려 재수정하게 함 |
| Decompose on failure | 같은 실패를 반복하는 retry loop | 두 번 실패하면 더 작은 하위 문제로 쪼개도록 설계 |
| Forgiving parser | 작은 모델의 깨진 tool call format | JSON, YAML, XML, Hermes format, plain text를 파싱하고 흔한 parameter 오류를 보정 |
| Context budget engine | context overflow와 중간 truncation | tool result cap, mid-turn eviction, semantic compression으로 context window를 관리 |
| Patch-first editing | full-file rewrite의 truncation·hallucination | search-and-replace patch를 기본 edit primitive로 사용 |
| Code graph retrieval | 무작위 grep snippet 과다 주입 | function, class, caller/callee 관계를 이용해 관련 코드만 좁혀 가져오는 방식 |
| Optional escalation | 작은 모델로 끝까지 버티다 실패하는 문제 | Claude/OpenAI/DeepSeek key가 있을 때 hard fail task만 cloud model로 넘김 |
여기서 중요한 포인트는 SmallCode가 “local only”와 “cloud fallback”을 동시에 말한다는 점이다. README와 Security 문서는 escalation이 opt-in이고 API key가 있어야 하며, 기본적으로 telemetry나 phone-home을 하지 않는다고 적는다. 다만 escalation을 켜면 해당 task context가 설정한 provider로 전송될 수 있다. 따라서 SmallCode의 privacy claim은 완전한 offline agent라기보다 “기본 경로는 local이고, 사용자가 명시적으로 설정하면 제한적으로 cloud fallback을 쓴다”에 가깝다.
공개된 근거에서 확인되는 점
릴리스 표면은 빠르게 커지고 있지만 아직 매우 초기다. GitHub API 조회 기준 Doorman11991/smallcode 저장소는 2026-05-18 생성되었고, 기본 branch는 master, 주 언어는 JavaScript, license는 MIT로 표시된다. 같은 시점 저장소는 657 stars, 37 forks, 4 open issues를 보였지만, GitHub Releases와 tags는 비어 있었다. npm registry에는 smallcode package가 올라와 있고 latest dist-tag는 0.6.9다. 반면 GitHub package.json은 0.6.10을 가리켜, 저장소와 npm 배포 사이에 한 버전 정도의 시차가 보인다.
| 항목 | 확인한 값 | 해석 |
|---|---|---|
| GitHub repo | Doorman11991/smallcode |
공식 공개 저장소 |
| 생성일 | 2026-05-18 | 매우 이른 프로젝트, maturity 판단에 주의 필요 |
| npm latest | 0.6.9 | 전역 CLI 설치 경로는 존재 |
GitHub package.json |
0.6.10 | npm latest와 repo head 사이에 버전 시차 |
| GitHub releases / tags | 없음 | semver tag 기반 재현성은 아직 약함 |
| License | MIT | GitHub API와 package.json 모두 MIT 방향으로 일치 |
| Node requirement | >=18.0.0 | Node LTS 환경을 전제로 함 |
| Optional dependencies | budget-aware-mcp, Playwright stealth 관련 package |
code graph / browsing 계층은 optional dependency 영향을 받음 |
벤치마크는 더 조심해서 읽어야 한다. Reddit 글과 COMPARISON.md는 SmallCode가 huihui-gemma-4-e4b-it-abliterated라는 Gemma 4 MoE 모델로 100개 task 중 87개를 통과했다고 설명한다. bench/stress_results.json도 실제로 summary를 passed: 87, failed: 13, total: 100으로 기록한다. category breakdown은 Python 10/10, JavaScript 8/10, TypeScript 10/10, HTML 10/10, Rust 5/10, Go 9/10, data structures 10/10, testing 7/10, multifile 10/10, bugfix 8/10이다.
하지만 이 87%는 SWE-bench류의 독립 검증 benchmark로 읽으면 안 된다. bench/stress_test.js를 보면 single-file stress test의 pass 판정은 기본적으로 CLI 출력이 충분히 있고 No response from model이 없으면 통과로 계산한다. hasError flag는 기록하지만 pass 여부를 직접 뒤집지는 않는다. 즉 이 숫자는 “과제를 받아 agent가 의미 있는 실행을 끝냈는가”에 가까운 자체 stress signal이지, 생성된 코드의 의미론적 correctness를 촘촘히 채점한 결과는 아니다.
더 엄격한 힌트는 bench/stress_results_v2.json 쪽에 있다. v2는 multi-file project와 dependency-aware task 50개를 두고, 최소한 필요한 파일이 만들어졌는지 post-check를 수행한다. 이 raw result의 summary는 22/50, 즉 44%다. JavaScript multi와 web multi는 각각 5/5로 좋았지만, Rust multi와 Go multi는 1/5, fullstack은 0/5, config는 1/5, refactor는 1/5에 머물렀다. COMPARISON.md는 multi-file overall을 46% 또는 BoneScript 사용 시 60%+ 방향으로 표현하지만, 저장소에 체크인된 raw JSON 기준으로는 44%가 확인된다.
따라서 공개 근거를 정리하면 이렇다.
| 근거 | 확인되는 내용 | 읽는 법 |
|---|---|---|
| Reddit post | “4B active model로 87/100”이라는 강한 claim과 설계 요약 | 프로젝트의 narrative source. 다만 community post이므로 공식 repo와 교차 확인 필요 |
bench/stress_results.json |
100 task 중 87 pass | 자체 single-file stress run. pass 판정이 느슨하므로 headline number로만 소비하면 위험 |
bench/stress_test.js |
출력 존재 여부 중심 pass logic | correctness benchmark라기보다 non-interactive agent run 안정성 지표에 가까움 |
bench/stress_results_v2.json |
multi-file 22/50 pass | 복잡도가 올라가면 아직 실패가 크게 늘어난다는 근거 |
COMPARISON.md |
OpenCode/Pi Agent 대비 추정 비교 | 같은 harness·same-model controlled benchmark가 아니라 community benchmark 추정치와의 비교임 |
SECURITY.md |
agent는 사용자 권한으로 shell/file 작업을 수행, sandbox는 아님 | 로컬 실행이라고 해서 자동으로 안전해지는 것은 아님 |
이 caveat가 SmallCode의 가치를 없애지는 않는다. 오히려 숫자를 정확히 읽게 해 준다. SmallCode의 87% claim은 “작은 모델이 모든 실전 코딩 과제를 잘 푼다”가 아니라, 간단한 파일 생성·수정 stress suite에서는 harness 설계만으로도 꽤 높은 completion signal을 만들 수 있다는 의미에 가깝다. 그리고 v2 결과는 같은 설계가 multi-file dependency, fullstack, refactor로 넘어가면 아직 큰 숙제를 남긴다는 점을 보여 준다.
실무 관점에서의 해석
SmallCode에서 배울 가장 큰 교훈은 “4B 모델로 충분하다”가 아니다. 더 유용한 교훈은 작은 모델을 쓸수록 agent harness의 인터페이스 설계가 더 중요해진다는 점이다. 모델이 길게 생각하지 못한다면 작업을 더 작게 잘라야 한다. 모델이 tool call을 자주 깨뜨린다면 parser와 repair path를 두어야 한다. 모델이 context를 잃는다면 필요한 코드만 좁혀 주고, 불필요한 tool schema를 줄이고, 오래된 결과를 압축해야 한다.
이건 비용 절감 이상의 문제다. 많은 조직은 보안, latency, 데이터 주권, offline 요구 때문에 로컬 모델을 검토한다. 하지만 “로컬 모델을 OpenAI-compatible endpoint로 열고 Claude Code류 agent에 꽂는다”는 방식만으로는 frontier model workflow의 신뢰성을 복제하기 어렵다. SmallCode가 보여 주는 방향은 endpoint compatibility가 아니라 runtime compatibility다. 작은 모델이 견딜 수 있는 tool granularity, context shape, verification feedback, retry policy를 다시 설계해야 한다.
반대로 도입 관점에서는 신중해야 한다. 저장소가 생성된 지 매우 짧고, GitHub tag/release가 없으며, npm version history가 하루 이틀 사이에 빠르게 쌓였다. README와 comparison 문서도 강한 claim을 담고 있지만, benchmark harness는 아직 연구용 자체 stress test에 가깝다. 실무 팀이 바로 production coding agent로 받아들이기보다는, 특정 내부 repo에서 작은 task class를 정하고, 자체 acceptance test와 sandbox를 붙인 뒤 실험하는 편이 맞다.
보안 면에서도 “local”이라는 단어에 안심하면 안 된다. SECURITY.md는 SmallCode가 사용자 계정과 같은 권한으로 파일을 읽고 쓰며 shell command를 실행한다고 설명한다. 기본적으로 network server를 열거나 telemetry를 보내지는 않는다고 하지만, bash tool, plugin, optional web browsing, optional cloud escalation은 모두 별도의 trust boundary를 만든다. 특히 escalation을 켜면 실패한 task context가 외부 API로 나갈 수 있고, plugin ecosystem이 커질수록 prompt/tool supply-chain risk도 생긴다.
내가 보기에 SmallCode의 현재 가치는 완성도 높은 Claude Code 대체재라기보다, 소형 모델 agent를 설계할 때 어떤 실패를 runtime이 흡수해야 하는지 보여 주는 압축된 case study에 있다. compound tool은 “작은 모델에게 긴 procedure를 시키지 말라”는 교훈이고, patch-first editing은 “생성 능력보다 edit surface를 줄여라”는 교훈이며, v2 benchmark의 낮은 multi-file 성능은 “복잡한 작업일수록 단순 completion metric이 금방 무너진다”는 경고다.
앞으로 SmallCode가 더 설득력을 얻으려면 세 가지가 중요해 보인다. 첫째, benchmark를 실제 correctness check 중심으로 강화해야 한다. 둘째, release tag와 reproducible benchmark environment를 제공해야 한다. 셋째, cloud escalation, plugin, web browsing, shell execution에 대한 permission model을 더 명확히 해야 한다. 그 세 가지가 붙으면 SmallCode는 단순한 Reddit 흥행 프로젝트를 넘어, 로컬 소형 모델 시대의 agent harness reference implementation에 가까워질 수 있다.
지금 단계에서의 결론은 이렇다. SmallCode의 87% 숫자는 그대로 믿을 headline이라기보다, 모델보다 하네스가 중요하다는 좋은 실험 신호다. 작은 로컬 모델을 실제 개발 workflow에 넣고 싶다면, 더 큰 모델을 기다리는 것만이 답은 아니다. 작업을 작게 만들고, 도구를 묶고, 실패를 검증하고, context를 아끼고, 위험한 경계는 runtime이 소유하게 만드는 하네스 설계가 같은 만큼 중요하다.