LLM 에이전트 평가는 점점 더 정교해졌지만, 많은 학습 환경은 여전히 지나치게 깨끗하다.
사용자는 목표를 명확히 말하고, 도구는 안정적으로 응답하며, 중간 관측은 대체로 task solving에 필요한 정보만 담고 있다고 가정한다.
문제는 실제 배포 환경이 그렇게 친절하지 않다는 점이다.
Learning to Act under Noise: Enhancing Agent Robustness via Noisy Environments는 이 간극을 agent training의 핵심 병목으로 본다.
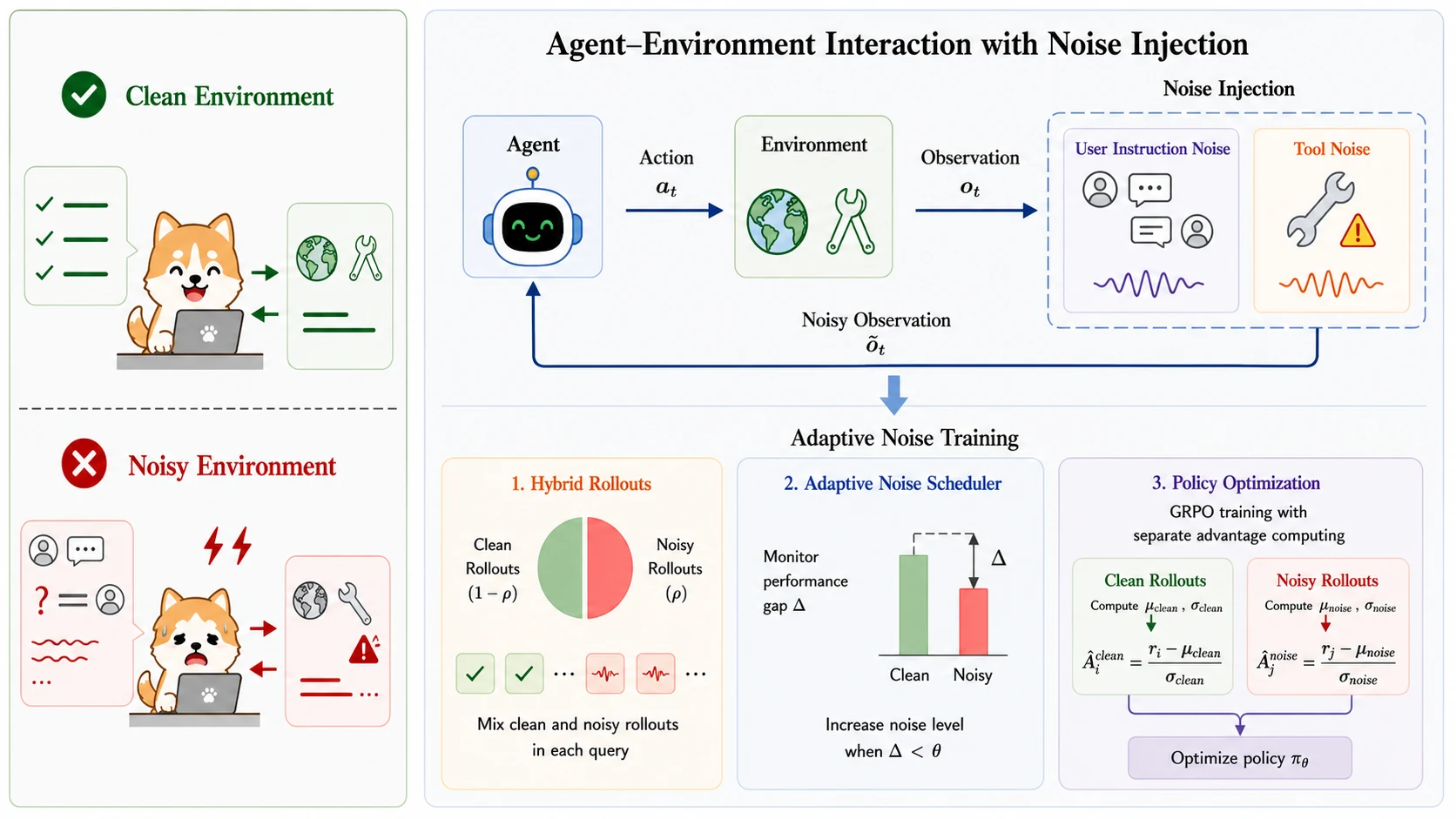
논문이 제안하는 NoisyAgent는 에이전트를 깨끗한 rollout에서만 강화학습시키지 않고, 모호한 사용자 발화와 실패·불완전·오염된 도구 응답을 훈련 환경 안에 의도적으로 주입한다.
다만 모든 rollout을 한 번에 망가뜨리는 식이 아니라, clean/noisy rollout을 섞고 모델이 적응할 때마다 noise 비율과 난도를 올리는 curriculum으로 안정성을 유지한다.
이 글에서 NoisyAgent는 agent runtime architecture라기보다 노이즈를 훈련 분포에 넣는 model-training recipe로 읽는 편이 정확하다.
논문은 공개 코드나 모델 weight bundle보다는 arXiv/Hugging Face Papers 기반의 연구 결과를 중심으로 공개되어 있으며, 핵심 근거는 Qwen3-8B/32B backbone을 AgentNoiseBench와 τ²-Bench/VitaBench에서 비교한 실험이다.
무엇을 해결하려는가
논문이 겨냥하는 문제는 “벤치마크에서 잘하는 agent가 왜 실제 환경에서 쉽게 흔들리는가”다.
기존 agentic RL 또는 RLVR 설정은 task prompt, user simulator, tool API, verifier가 비교적 안정적인 환경을 만든다.
이 설정은 성공/실패 reward를 주기 쉽고 대량 rollout을 병렬화하기 좋지만, 배포 환경에서 자주 생기는 불완전성을 충분히 반영하지 못한다.
사용자 쪽 noise는 의도 모호성, 중간 요구 변경, 불필요한 설명처럼 interaction pattern 자체를 흐린다.
도구 쪽 noise는 API failure, truncated output, 잘못된 field, 불필요한 정보처럼 observation을 흐린다.
에이전트 입장에서는 둘 다 long-horizon trajectory를 망가뜨릴 수 있다.
초반에 사용자의 진짜 목표를 잘못 잡거나, 중간 도구 결과의 오류를 그대로 믿으면 뒤의 행동은 형식적으로 그럴듯해도 실제 task completion과 멀어진다.
NoisyAgent의 질문은 여기서 출발한다.
에이전트를 깨끗한 환경에서만 최적화하지 않고, solvability는 유지한 채 현실적인 noise를 학습 중에 노출하면 robustness와 일반 성능을 함께 높일 수 있는가?
핵심 아이디어 / 구조 / 동작 방식
NoisyAgent의 첫 번째 구성요소는 automatic noise injection이다.
사용자 쪽에서는 task 시작 전 interaction pattern을 변형한다.
논문은 세 가지 대표 형태를 든다.
첫째, 목표가 충분히 특정되지 않는 ambiguous instruction.
둘째, 사용자의 요구가 시간이 지나며 바뀌거나 충돌하는 inconsistent interaction.
셋째, task와 직접 관련 없는 설명이 섞이는 redundant interaction이다.
중요한 제약은 원래 task objective는 유지한다는 점이다.
즉 reward가 깨질 정도로 문제 자체를 바꾸는 것이 아니라, 같은 문제를 더 지저분한 방식으로 풀게 만든다.
도구 쪽에서는 rollout 중 일부 tool response를 변형한다. failure는 tool call이 error를 돌려주는 상황, incomplete는 출력이 잘리는 상황, misleading은 잘못되거나 모순되는 정보를 포함하는 상황, redundant는 필요 없는 세부사항이 붙는 상황이다.
실제 API와 외부 시스템을 다루는 agent라면 모두 흔히 만나는 종류의 noise다.
두 번째 구성요소는 adaptive noise training이다.
논문은 GRPO/GSPO류 설정에서 한 task당 여러 rollout을 병렬로 만들고, 이 중 일부만 noisy trajectory로 둔다. clean rollout과 noisy rollout은 reward 분포와 난도가 다르기 때문에 advantage를 한 덩어리로 정규화하지 않고, clean group과 noise group 안에서 따로 계산한 뒤 union 위에서 최적화한다.
이 group-wise normalization은 heterogeneous rollout을 섞을 때 학습 신호가 한쪽으로 무너지는 것을 줄이기 위한 장치다.
세 번째는 noise scheduling이다.
논문은 같은 task의 clean rollout 성공률과 noisy rollout 성공률 차이를 Δ로 두고, 이 gap이 threshold보다 작아졌을 때 모델이 현재 noise level에 적응했다고 판단한다.
그 다음 noise 비율과 난도를 올린다.
메인 텍스트 기준 noisy trajectory 비율은 최대 50%로 제한되고, scheduling threshold는 Δ=0.05로 설정된다.
요지는 간단하다.
노이즈는 regularizer처럼 유용할 수 있지만, 통제 없이 많이 넣으면 학습을 망가뜨린다.
공개된 근거에서 확인되는 점
실험은 Qwen3-8B와 Qwen3-32B를 backbone으로 사용하고, GRPO·DAPO·GSPO와 비교한다.
평가 환경은 noisy setting의 AgentNoiseBench-τ²/AgentNoiseBench-Vita, ideal setting의 τ²-Bench/VitaBench다.
각 실험은 네 번 반복되며 Avg@4와 Pass@4를 보고한다.
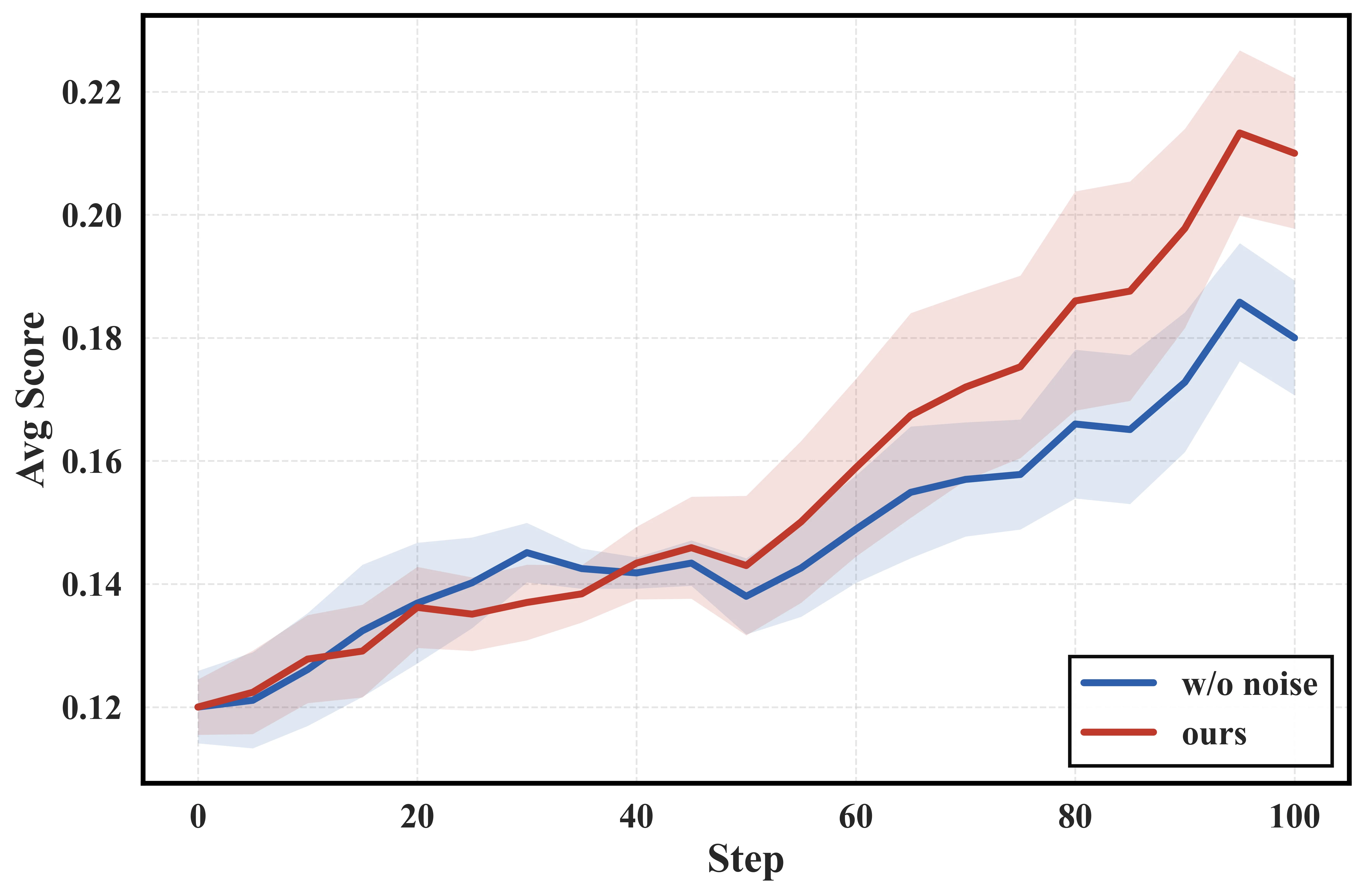
여섯 개 domain 평균으로 보면, noisy setting에서 NoisyAgent는 GSPO보다 더 큰 차이를 만든다.
도구·사용자 noise가 들어간 AgentNoiseBench에서 8B 모델은 평균 Avg@4가 GSPO 22.08에서 NoisyAgent 25.88로, Pass@4가 35.92에서 41.55로 오른다.
32B에서도 Avg@4는 27.45에서 32.15로, Pass@4는 43.89에서 48.83으로 오른다.
이 평균은 논문 Table 1의 Retail, Airline, Telecom, Delivery, In-Store, OTA 여섯 domain 값을 단순 평균한 값이다.
| 설정 | 비교 | 평균 Avg@4 | 평균 Pass@4 | 읽을 점 |
|---|---|---|---|---|
| Noisy / Qwen3-8B | GSPO → NoisyAgent | 22.08 → 25.88 | 35.92 → 41.55 | noise 조건에서 +3.80 Avg@4, +5.63 Pass@4 |
| Noisy / Qwen3-32B | GSPO → NoisyAgent | 27.45 → 32.15 | 43.89 → 48.83 | 더 큰 backbone에서도 robustness gain 유지 |
| Ideal / Qwen3-8B | GSPO → NoisyAgent | 28.63 → 29.94 | 45.99 → 48.52 | clean benchmark에서도 소폭 개선 |
| Ideal / Qwen3-32B | GSPO → NoisyAgent | 35.94 → 37.70 | 54.40 → 57.82 | noise training이 clean 성능을 반드시 해치지는 않음 |
개별 domain도 같은 방향이다.
예를 들어 AgentNoiseBench-Vita Delivery에서 Qwen3-8B base는 Avg@4 11.75, GSPO는 16.00, NoisyAgent는 21.50이다.
Qwen3-32B에서는 base 19.50, GSPO 23.75, NoisyAgent 28.75다.
OTA처럼 절대 점수가 낮은 domain에서도 8B는 2.75에서 4.75, 32B는 7.50에서 9.50으로 오른다.
즉 특정 쉬운 domain 하나가 평균을 끌어올린 결과로 보기는 어렵다.
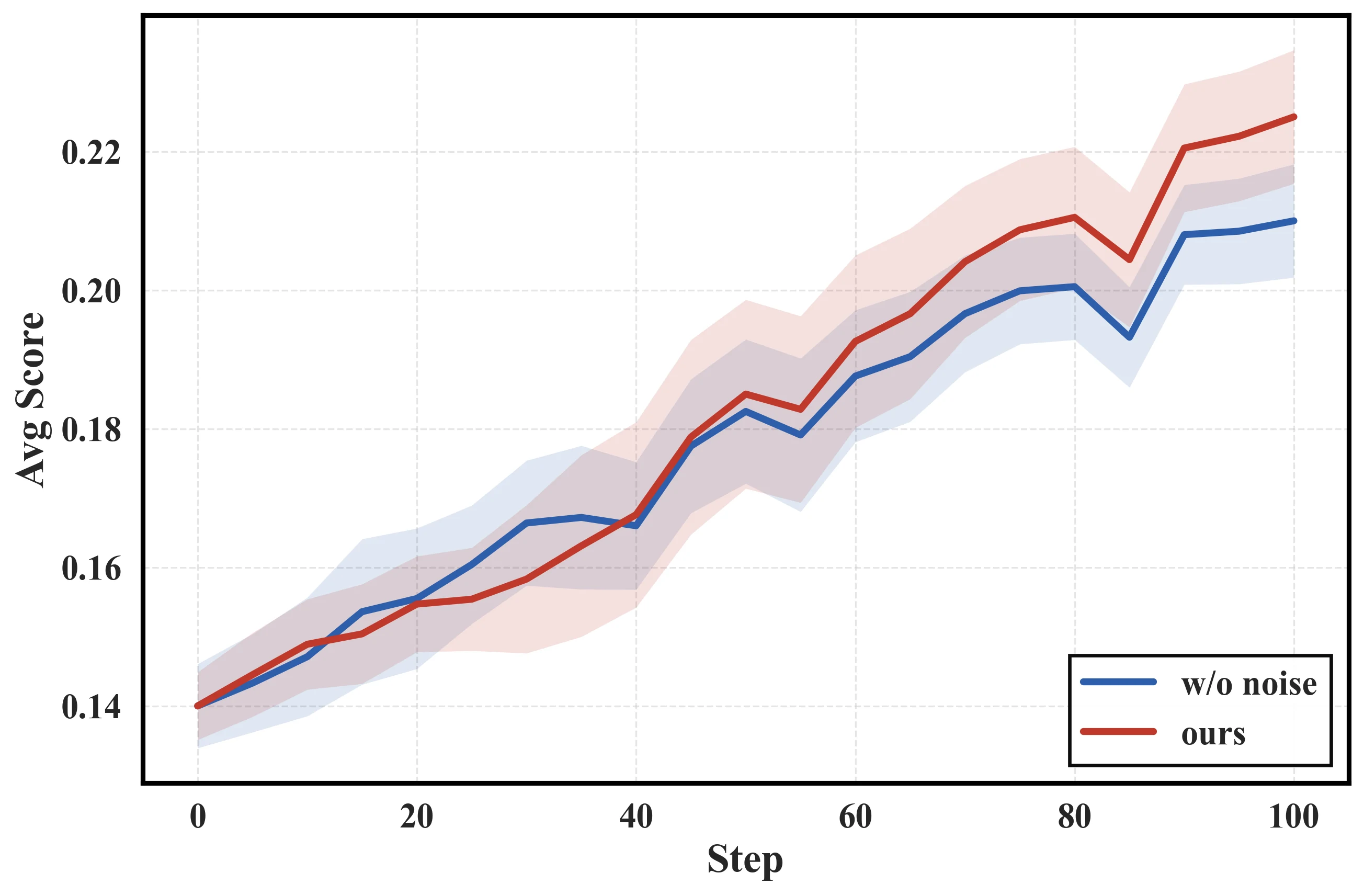
흥미로운 점은 ideal benchmark에서도 개선이 남는다는 것이다.
논문은 이를 noise가 단순 방해물이 아니라 controlled difficulty augmentation처럼 작동했기 때문으로 해석한다.
모호한 지시나 깨진 tool output을 처리하는 동안 모델은 error recovery, ambiguity resolution, goal maintenance를 더 자주 연습하게 되고, 이 습관이 깨끗한 환경에서도 도움이 된다는 주장이다.
Ablation은 “노이즈를 넣으면 다 좋다”는 식의 단순 결론을 막아 준다.
Qwen3-8B Delivery domain에서 full NoisyAgent는 noisy AgentNoiseBench-Vita Avg@4 21.50 / Pass@4 34.00을 기록한다.
반면 controlled injection 없이 모든 rollout을 noisy하게 만드는 설정은 Avg@4 13.25 / Pass@4 21.00까지 떨어진다. noise scheduling을 빼면 20.00 / 31.00, noise 자체를 빼면 16.00 / 26.00이다.
가장 큰 하락이 uncontrolled injection에서 나온다는 점은, robustness training이 단순 data corruption이 아니라 curriculum과 안정화 설계의 문제임을 보여 준다.
상호작용 패턴 분석도 실무적으로 중요하다.
Retail domain의 noisy setting에서 base Qwen3-8B는 episode당 tool call 13.9회, GSPO는 13.7회, NoisyAgent는 11.4회로 줄어든다.
반면 output token은 base 2,014에서 NoisyAgent 4,248로 늘어난다.
논문은 이를 noisy 환경에서 불필요한 tool interaction을 줄이고, 더 많은 언어 reasoning으로 상황을 정리하는 방향의 행동 변화로 해석한다.
단순히 tool을 덜 쓰는 모델이 된 것이 아니라, ideal setting에서는 tool call 수가 6.7~7.4 수준으로 큰 차이가 없다는 점도 함께 보고된다.
공개 release surface는 보수적으로 봐야 한다. arXiv HTML과 Hugging Face Papers mirror는 논문·그림·표를 제공하지만, 검색 시점에 논문 제목이나 NoisyAgent 이름으로 확인되는 공식 GitHub repository, Hugging Face model, dataset release는 찾지 못했다.
GitHub repository search도 exact title/NoisyAgent 기준 공식 구현을 반환하지 않았다.
따라서 현재 공개물은 논문 중심의 방법 제안과 실험 보고로 해석하는 것이 안전하다.
실무 관점에서의 해석
NoisyAgent의 가장 실용적인 메시지는 “agent robustness는 evaluation만의 문제가 아니라 training distribution의 문제”라는 점이다.
운영 환경에서 사용자는 instruction-following benchmark처럼 행동하지 않고, tool layer도 항상 정상 응답을 주지 않는다.
그런데 학습 단계가 이런 상황을 전혀 보지 못하면, agent는 관측이 조금만 지저분해져도 목표 유지와 action execution 사이에서 흔들린다.
특히 Appendix의 case study가 이 관점을 잘 보여 준다. τ²-Bench Retail noisy setting에서 base model과 NoisyAgent 모두 사용자 신원 확인, 주문 조회, 반품 대상 식별 같은 정보 수집은 수행한다.
하지만 API failure와 corrupted field가 섞인 뒤 base model은 최종 return API 호출을 하지 못하고 엉뚱한 추천으로 이동한다.
반면 NoisyAgent는 필요한 정보가 모이면 반품 action을 실행한다.
저자들은 NoisyAgent가 성공하고 base model이 실패한 23개 task 중 78%가 “이해는 했지만 critical action을 실행하지 못한” 패턴이었다고 보고한다. noise의 피해가 comprehension보다 understanding-to-action 전환에서 크게 나타난다는 해석이다.
제품 관점에서는 이 차이가 중요하다.
실제 고객지원, 예약, 주문, 환불, 내부 업무 자동화 agent에서 치명적인 실패는 “사용자 말을 아예 못 알아듣는 것”만이 아니다.
모델이 정보를 충분히 모았는데도 tool error나 잡음 이후 최종 조치를 놓치거나, 불필요한 조회를 반복하거나, 원래 목표에서 벗어나는 것이 더 흔하고 더 위험할 수 있다.
NoisyAgent는 이런 failure mode를 훈련 중에 일부러 재현해 action policy를 단단하게 만들자는 접근이다.
다만 적용에는 비용과 제약이 있다.
논문 Appendix 기준 Qwen3-8B training에는 32×NVIDIA H800 GPU, Qwen3-32B training에는 64×H800 GPU가 사용됐고, 100 training step에 모델 규모와 domain에 따라 3~5일이 걸린다.
또한 noise injector, user simulator, verifier, evaluator가 필요하며 논문 설정에서는 GPT-4.1, Claude-Sonnet-4.5, GLM-4.6, Qwen2.5-72B-Instruct, Qwen3-32B evaluator가 서로 다른 역할을 맡는다.
일반 팀이 그대로 재현하기에는 꽤 무거운 pipeline이다.
또 하나의 한계는 공개 artifact다.
현재 확인 가능한 범위에서는 코드와 모델 checkpoint가 동반된 release bundle이 아니라 논문 중심 공개다.
따라서 이 글의 결론도 “당장 가져다 쓰는 라이브러리”가 아니라 “agent RL/post-training 설계에서 noise curriculum을 어떤 방식으로 넣을 수 있는가”에 초점을 둔다.
그럼에도 NoisyAgent는 중요한 방향을 제시한다.
지금까지 많은 agent 개선은 더 강한 base model, 더 나은 tool schema, 더 똑똑한 prompt, 더 정교한 evaluator에 집중했다.
NoisyAgent는 그 위에 하나를 더한다.
배포 환경이 지저분하다면, 학습 환경도 통제된 방식으로 지저분해야 한다.
에이전트가 현실의 불완전성을 피할 수 없다면, robustness는 사후 방어막이 아니라 훈련 시점의 핵심 목표가 되어야 한다.