추천 시스템에서 롱테일 문제는 단순히 “인기 없는 상품을 더 노출하자”의 문제가 아니다.
대형 커머스에서는 대부분의 상품과 사용자가 sparse하다.
반대로 head 상품·활성 사용자는 충분한 클릭·전환 로그를 갖고 있어 기존 CTR 모델이 이미 꽤 잘 맞춘다.
따라서 tail을 살리기 위해 모든 ID를 같은 방식으로 섞으면, tail의 noisy signal이 head 표현까지 망가뜨릴 수 있다.
From Head to Tail: Asymmetric Knowledge Transfer in Long-tail Recommendation with Generative Semantic IDs는 이 지점을 정면으로 다룬다.
Alibaba Group과 Peking University 저자진이 제안한 AKT-Rec는 LLM/MLLM으로 사용자·상품 semantic representation을 만들고, RQ-VAE로 이를 discrete semantic ID cluster로 바꾼 뒤, head에서 tail로 지식이 주로 흐르도록 embedding과 feature fusion을 설계한 industrial recommendation framework다.
논문은 arXiv 2605.23310으로 공개된 5쪽짜리 cs.IR preprint이며, 실험은 Tmall 모바일 앱의 대규모 산업 데이터와 온라인 A/B 테스트를 포함한다.
공개된 자료 기준으로는 별도 공식 GitHub 구현이나 공개 모델 카드가 확인되지 않았기 때문에, 이 글의 중심은 release 사용법이 아니라 운영 추천 시스템에서 semantic ID를 어떻게 롱테일 완화 장치로 쓸 수 있는가에 있다.
무엇을 해결하려는가
커머스 추천의 데이터 분포는 본질적으로 long-tail이다.
논문이 사용한 Tmall 데이터에서도 학습 구간 기준 상호작용이 5회 미만인 사용자가 85.58%, 노출이 10회 미만인 상품이 95.8%를 차지한다.
사용자 또는 타깃 상품 중 하나라도 long-tail ID인 sample은 22.4%로 정의된다.
즉 운영 지표에서 tail은 “예외 케이스”가 아니라 모델이 매일 마주치는 큰 표면이다.
기존 접근은 대략 세 갈래다.
Graph 기반 방법은 user-item interaction graph를 통해 sparse node로 정보를 전파하지만, edge 구성 규칙이 수동적이고 noise가 들어가기 쉽다.
Sample augmentation은 tail item의 pseudo interaction을 늘리지만, synthetic sample 품질을 통제하기 어렵고 실제 분포를 왜곡할 수 있다.
LLM/content 기반 방법은 이미지·텍스트·속성에서 풍부한 feature를 뽑을 수 있지만, collaborative signal 중심의 CTR 모델 안에서 그 정보가 충분히 쓰이지 않거나 head ID에 대한 부정적 영향을 따로 막지 못한다.
AKT-Rec의 문제의식은 여기서 조금 더 날카롭다.
Head와 tail 사이의 knowledge transfer는 대칭적이지 않다.
Head ID는 interaction이 많아 representation이 안정적이고, 비슷한 tail ID에 도움이 될 수 있다.
반대로 tail ID의 signal은 sparse하고 noisy하므로 head representation을 끌어내리는 방향으로 섞이면 손해가 크다.
따라서 논문은 “비슷한 ID를 cluster로 묶자”에서 멈추지 않고, 어느 방향으로 지식이 흘러야 하는가를 loss와 gate로 제어한다.
핵심 아이디어 / 구조 / 동작 방식
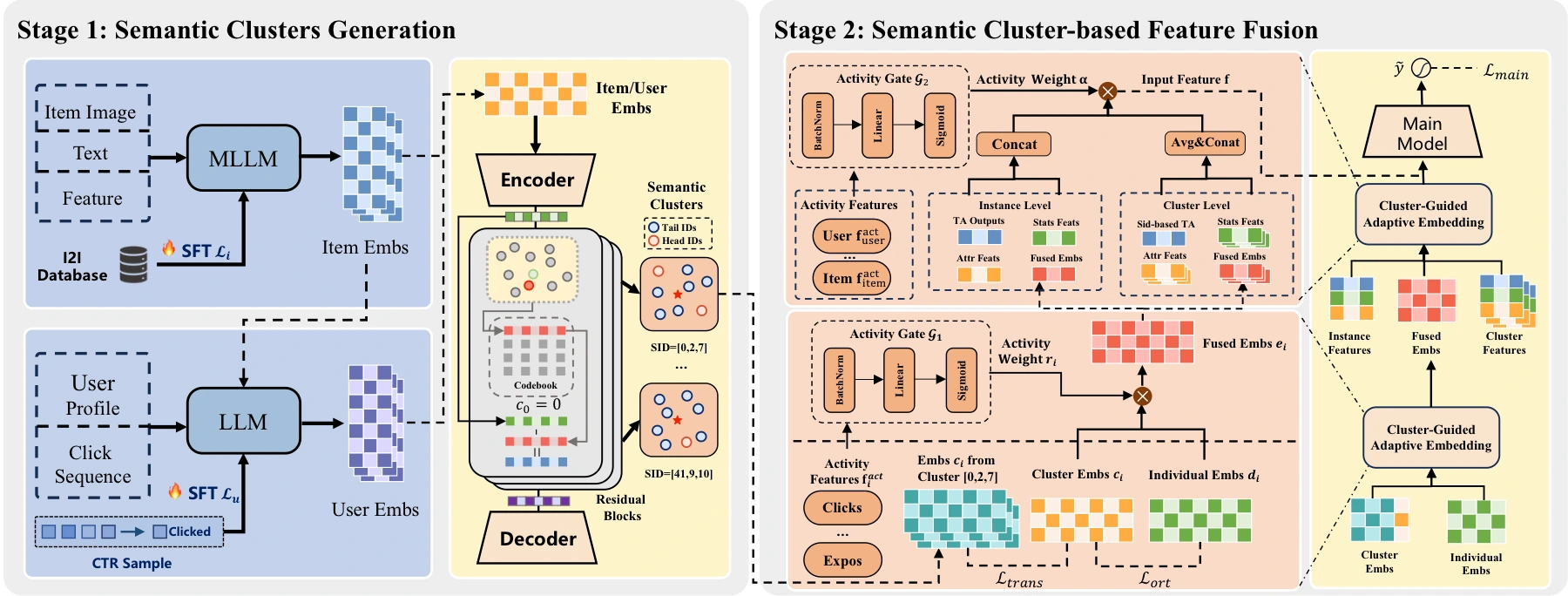
AKT-Rec는 크게 두 단계로 구성된다.
첫 번째 단계는 semantic cluster generation이다.
상품 쪽에서는 pretrained MLLM인 GME-Qwen2-VL-7B를 사용해 상품 이미지, 텍스트 설명, N-day CTR·CVR·add-to-cart rate 같은 통계 feature를 함께 넣는다.
이때 item-to-item co-occurrence pair를 InfoNCE로 정렬해 content representation이 collaborative signal과 맞물리도록 한다.
사용자 쪽에서는 별도의 LLM, 논문 구현에서는 Qwen3-30B-A3B, 을 supervised 방식으로 fine-tuning한다.
Prompt에는 사용자 속성, 최근 30일 클릭 sequence, categorical/statistical data가 들어가고, 모델은 사용자의 future preference를 나타내는 interest token과 대응 item category를 예측한다.
즉 item은 multimodal content와 co-occurrence로, user는 profile과 chronological behavior로 semantic representation을 얻는다.
이 representation은 RQ-VAE를 통해 discrete semantic ID로 양자화된다.
중요한 설정은 collision을 너무 낮추지 않는다는 점이다.
Semantic ID 하나가 단일 상품·사용자 하나만 가리키면 cluster가 아니라 또 다른 ID가 된다.
AKT-Rec는 여러 유사 item/user가 같은 semantic ID를 공유하도록 codebook layer와 size를 조정해, semantic cluster가 tail ID를 위한 공유 지식 단위가 되게 만든다.
두 번째 단계는 semantic cluster-based feature fusion이다.
각 user/item ID는 두 가지 embedding을 가진다.
| 구성 요소 | 역할 | 롱테일 추천에서의 의미 |
|---|---|---|
| Cluster embedding | 같은 semantic cluster의 shared semantics를 담음 | tail ID가 비슷한 head ID의 안정된 패턴을 빌릴 수 있는 통로 |
| Individual embedding | ID 고유의 세부 특성을 보존 | head ID처럼 충분한 로그가 있는 경우 과도한 평균화를 막는 장치 |
| Activity-aware gate | activity feature를 보고 두 embedding 비중을 조절 | head/tail 정도에 따라 cluster 의존도를 동적으로 바꿈 |
| Asymmetric InfoNCE | stop-gradient와 서로 다른 weight로 전이 방향을 제어 | tail에서 head로 noise가 역전파되는 것을 줄이고 head-to-tail 전이를 강화 |
논문은 cluster embedding과 individual embedding이 같은 정보를 중복해서 담아 optimization collapse를 일으키지 않도록 soft orthogonality regularizer도 넣는다.
최종적으로는 activity gate가 cluster embedding과 individual embedding을 섞어 user/item embedding을 만든다.
그 위에 Hierarchical Feature Aggregation이 올라간다.
Instance-level view는 개별 user/item feature, user history, candidate item target attention을 사용한다.
Cluster-level view는 user cluster와 item cluster의 대표 feature를 평균·검색·attention으로 요약한다.
특히 cluster-level behavior sequence가 온라인 serving latency를 깨뜨릴 만큼 길어질 수 있으므로, 논문은 top-level semantic ID 기반 hard retrieval로 candidate item과 관련 높은 behavior를 가져온 뒤 target attention을 적용한다.
마지막 fusion network는 user activity, item activity, cross activity feature를 보고 instance-level representation과 cluster-level representation의 비중을 정한다.
Tail sample에서는 cluster-level shared signal이 더 중요하고, head sample에서는 개별 behavior sequence가 더 중요할 가능성이 높기 때문에, 이 adaptive fusion이 AKT-Rec의 운영상 핵심 장치가 된다.
공개된 근거에서 확인되는 점
실험 데이터는 2025년 6월부터 8월까지 Tmall 모바일 앱에서 수집된 두 달치 click log다.
규모는 3,600만 사용자와 약 3억 상품이며, 마지막 5일을 test set으로 사용한다.
Offline metric은 AUC와 GAUC, online A/B test metric은 Clicks, CTR, CTCVR, GMV다.
Baseline에는 온라인 base model, SaviorRec, TailNet, POSO, SimTier가 포함된다.
논문 Table 1의 주요 결과는 다음과 같다.
| 모델 | Total AUC | Total GAUC | Head AUC | Head GAUC | Tail AUC | Tail GAUC |
|---|---|---|---|---|---|---|
| Online base | 0.7510 | 0.6385 | 0.7528 | 0.6477 | 0.7485 | 0.6137 |
| SaviorRec | 0.7521 | 0.6455 | 0.7534 | 0.6516 | 0.7507 | 0.6347 |
| TailNet | 0.7491 | 0.6370 | 0.7509 | 0.6453 | 0.7479 | 0.6448 |
| POSO | 0.7518 | 0.6412 | 0.7520 | 0.6472 | 0.7497 | 0.6321 |
| SimTier | 0.7515 | 0.6398 | 0.7529 | 0.6481 | 0.7496 | 0.6279 |
| AKT-Rec | 0.7536 | 0.6483 | 0.7543 | 0.6528 | 0.7522 | 0.6397 |
Online base와 비교하면 AKT-Rec는 total AUC를 0.7510에서 0.7536으로, total GAUC를 0.6385에서 0.6483으로 올린다.
논문은 이를 각각 +0.35% AUC, +1.53% GAUC 개선으로 보고한다.
Tail 구간만 보면 AUC는 0.7485에서 0.7522, GAUC는 0.6137에서 0.6397로 올라간다.
계산상 tail GAUC의 상대 개선폭은 약 4.24%로, cluster 기반 지식 전이가 특히 tail 쪽에서 강하게 작동한다는 해석과 잘 맞는다.
Ablation도 구조의 의도를 뒷받침한다.
Cluster embedding을 제거하면 tail AUC/GAUC가 각각 -0.44%, -1.20% 하락한다.
Individual embedding을 제거하면 전체 AUC/GAUC가 -0.46%, -0.92% 하락하고 head 쪽 손실도 커진다.
Instance-level feature를 제거하면 전체 AUC가 -1.14%, GAUC가 -1.55%까지 떨어진다.
이 조합은 “cluster만 있으면 tail은 돕지만 head precision을 잃고, individual/instance feature만 있으면 tail sparse 문제를 충분히 못 푼다”는 AKT-Rec의 균형 논리를 보여 준다.
온라인 A/B 테스트는 Tmall production environment에서 2주 동안 진행됐고, control과 experiment group에 각각 online traffic 10%를 배정했다고 설명한다.
보고된 gain은 Clicks +2.73%, CTR +2.76%, CTCVR +1.7%, GMV +3.47%다.
추천 논문에서 offline AUC improvement는 작아 보일 수 있지만, 대형 커머스 ranking layer에서는 이런 수준의 offline gain이 online GMV까지 이어졌는지가 더 중요하다.
AKT-Rec는 그 연결고리를 A/B test로 제시한다.
실무 관점에서의 해석
AKT-Rec의 실용적 메시지는 LLM을 추천 모델 위에 얹는 방식이 점점 구체화되고 있다는 점이다.
여기서 LLM은 사용자에게 직접 답을 생성하는 agent가 아니다.
상품 이미지·텍스트·통계 feature를 collaborative signal과 맞춘 semantic representation으로 바꾸고, 사용자 history를 preference representation으로 압축한 뒤, 기존 CTR ranking stack이 쓸 수 있는 semantic ID와 cluster feature를 공급하는 infrastructure 역할에 가깝다.
이 접근의 장점은 tail ID에 대해 “내용 기반 feature를 좀 더 넣는다”가 아니라, 비슷한 head ID의 안정된 behavior knowledge를 cluster 단위로 전달한다는 점이다.
RQ-VAE semantic ID는 item/user를 discrete하게 묶기 때문에 online serving에서 feature lookup과 aggregation 단위로 쓰기 쉽다.
Activity-aware gate는 tail일수록 cluster signal을 더 믿고, head일수록 individual behavior를 더 믿는 방향의 정책을 학습할 수 있다.
동시에 이 논문은 공개 재현성 측면에서는 제한적이다.
데이터는 Tmall 산업 로그이고, online A/B 테스트도 내부 production 환경에서만 검증된다.
공개 코드나 checkpoint가 확인되지 않기 때문에, 외부 팀이 같은 수치를 재현하거나 구현 세부를 바로 검증하기는 어렵다.
따라서 이 글을 읽을 때는 AKT-Rec를 “당장 가져다 쓰는 오픈소스 모델”이 아니라, 대형 추천 조직이 LLM-generated semantic ID를 CTR stack에 통합하는 한 가지 설계 패턴으로 보는 편이 정확하다.
제품 팀 관점에서는 세 가지 질문이 남는다.
첫째, semantic ID cluster를 만들 때 collision rate를 얼마나 높여야 tail transfer와 head precision 사이의 균형이 맞는가.
둘째, cluster-level behavior retrieval이 online latency budget 안에서 안정적으로 동작하는가.
셋째, LLM/MLLM representation을 주기적으로 갱신할 때 drift와 비용을 어떻게 관리할 것인가.
논문은 이 질문들에 대한 완전한 운영 매뉴얼을 주지는 않지만, head-to-tail 비대칭성이라는 관점을 명확히 제시한다는 점에서 가치가 있다.
결론적으로 AKT-Rec의 핵심은 “LLM으로 추천을 한다”가 아니라, LLM이 만든 semantic ID를 이용해 추천 시스템의 지식 전이 방향을 설계한다는 데 있다.
롱테일 추천이 어려운 이유는 tail에 정보가 부족해서만이 아니라, tail의 noise가 head 품질을 해칠 수 있기 때문이다.
AKT-Rec는 이 비대칭성을 loss, gate, cluster/individual embedding 분리, hierarchical feature fusion으로 모델 구조 안에 넣은 사례다.