온디바이스 LLM의 어려움은 “모델을 조금 작게 만든다”로 끝나지 않는다.
실제 기기에서는 긴 입력을 읽는 prefill, 한 토큰씩 생성하는 decode, KV cache와 메모리 대역폭, 양자화 후 품질, 런타임 커널, 배포 포맷이 모두 병목이 된다.
같은 8B 모델이라도 서버 GPU에서의 평균 벤치마크 점수와 Jetson·PC GPU·모바일 계열 장치에서의 체감 지연은 전혀 다른 문제다.
OpenBMB의 MiniCPM4: Ultra-Efficient LLMs on End Devices는 이 문제를 모델 하나가 아니라 스택 전체로 푼다.
기술 보고서는 0.5B와 8B 두 크기의 MiniCPM4, reasoning/non-reasoning을 함께 겨냥한 MiniCPM4.1, 극저비트 BitCPM4, 그리고 MiniCPM4-Survey·MiniCPM4-MCP 같은 응용 변형까지 하나의 릴리스 묶음으로 제시한다.
공개 표면도 arXiv 논문, Hugging Face 컬렉션, OpenBMB/MiniCPM GitHub repo, CPM.cu 추론 repo로 나뉘어 있다.
핵심 메시지는 분명하다.
MiniCPM4는 온디바이스 LLM의 효율을 아키텍처, 데이터, 학습 알고리즘, 추론 시스템 네 층에서 동시에 끌어내리려 한다.
이 점 때문에 MiniCPM4는 단순한 “또 하나의 8B 오픈 모델”이라기보다, 작은 모델을 실제 edge-side 장치에서 빠르게 돌리려면 무엇을 같이 설계해야 하는지를 보여 주는 시스템 보고서에 가깝다.
무엇을 해결하려는가
MiniCPM4가 겨냥하는 병목은 두 가지다.
하나는 학습 비용 대비 품질이고, 다른 하나는 긴 문맥 추론 비용이다.
대형 LLM 경쟁이 수십 조 토큰 학습과 서버 GPU 중심으로 흐를수록, edge-side 장치에 맞는 모델을 만드는 팀은 같은 방식으로 따라가기 어렵다.
작은 모델은 학습 데이터 품질이 조금만 흔들려도 성능이 크게 떨어지고, 긴 문맥을 다루는 순간 attention 비용과 메모리 접근이 지연으로 바로 나타난다.
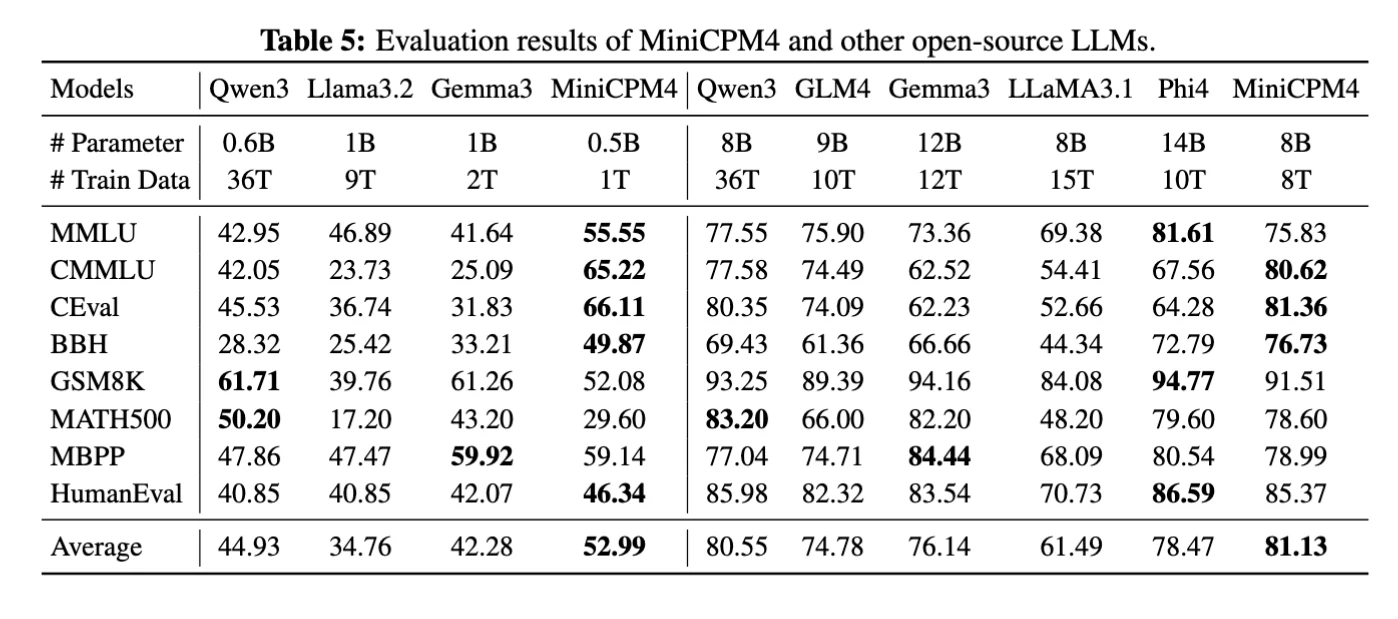
논문은 MiniCPM4-8B가 약 8.3T high-quality tokens로 사전학습되었다고 설명한다.
같은 표에서 Qwen3-8B는 36T training data로 비교된다.
결과적으로 MiniCPM4-8B는 Table 8 기준 평균 81.13을 기록해 Qwen3-8B의 80.55와 비슷하거나 약간 높은 평균을 보인다.
저자들은 이를 “Qwen3-8B training data의 22% 수준으로 comparable performance를 얻었다”는 효율성 주장으로 연결한다.
추론 쪽에서는 장문이 핵심이다. full attention은 문맥 길이가 늘어날수록 prefill과 decode 양쪽에서 비용이 커진다.
MiniCPM4는 InfLLM v2라는 trainable sparse attention을 통해 각 query가 전체 KV를 보는 대신 의미적으로 관련 있는 block을 선택하도록 만든다.
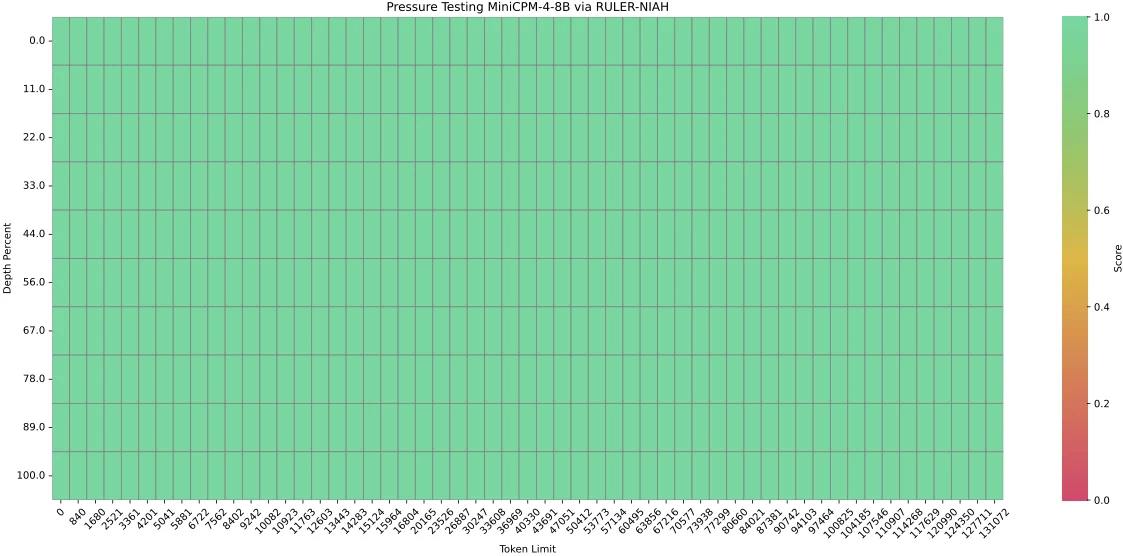
논문은 MiniCPM4가 128K needle-in-a-haystack에서 100% 정확도를 달성하면서 토큰당 약 6K context tokens만 attend한다고 설명한다.
128K 기준으로는 attention density가 약 5%라는 뜻이다.
따라서 이 보고서의 문제의식은 “8B 모델을 만들었다”가 아니다.
더 정확히는 8B급 모델을 장문·reasoning·tool-use까지 쓰려는 상황에서, 학습 데이터와 attention, 양자화, speculative decoding, 런타임을 어디까지 함께 줄일 수 있는가다.
핵심 아이디어 / 구조 / 동작 방식
MiniCPM4의 구조는 네 층으로 나눠 읽는 편이 가장 이해하기 쉽다.
| 층 | MiniCPM4가 제안하는 구성 | 온디바이스 관점의 의미 |
|---|---|---|
| 모델 아키텍처 | InfLLM v2 trainable sparse attention | 긴 문맥에서 모든 token을 보지 않고 block 단위로 선택해 prefill/decode 비용을 줄인다. |
| 학습 데이터 | UltraClean, UltraFineWeb, UltraChat v2 | 더 많은 토큰보다 고품질 데이터와 검증 가능한 필터링을 중시한다. |
| 학습 알고리즘 | ModelTunnel v2, chunk-wise rollout, BitCPM4 | 사전학습 전략 탐색·RL rollout·ternary QAT의 비용을 낮춘다. |
| 추론 시스템 | CPM.cu, ArkInfer, speculative sampling, quantization | 모델 특성을 실제 CUDA/edge runtime에서 살리는 배포 경로를 만든다. |
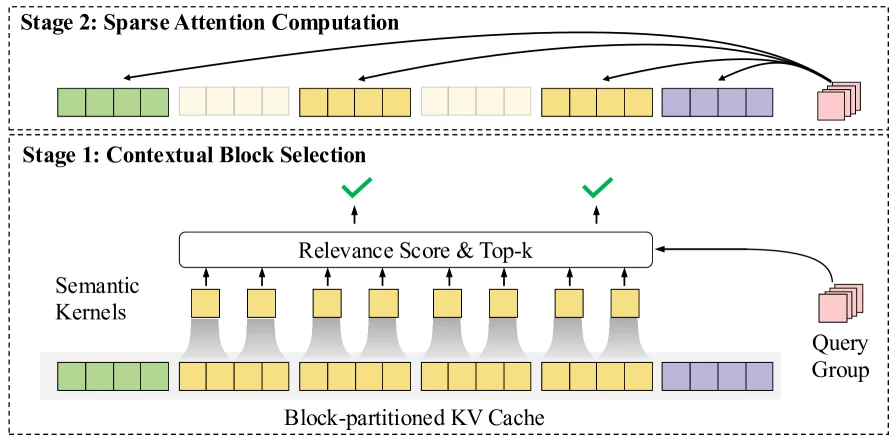
가장 중요한 구성은 InfLLM v2다.
논문 그림은 KV cache를 block으로 나누고, query group마다 일부 key-value block만 attention 대상으로 고르는 흐름을 보여 준다.
초기 token block과 sliding-window local block은 항상 선택하고, 나머지는 semantic kernel로 관련도를 계산해 top-k block을 고르는 방식이다.
이 설계는 sparse attention이 단순히 prefill만 줄이는 것이 아니라 decode 단계에서도 선택적으로 작동하도록 만드는 데 초점을 둔다.
데이터 쪽에서는 UltraClean과 UltraFineWeb이 중요하다.
논문은 기존 model-based filtering이 seed data 선택과 품질 검증에 취약하다고 보고, efficient verification strategy를 통해 고품질 pre-training data를 선별·생성하는 흐름을 제안한다.
Table 1에서는 1B 모델 기준 효율적 검증 전략의 비용을 110 GPU hours로 제시하는데, 100B from scratch의 1,200 GPU hours나 380B from scratch의 4,600 GPU hours와 비교하면 “검증을 위해 매번 크게 학습하지 말자”는 의도가 선명하다.
학습 알고리즘도 같은 철학을 따른다.
ModelTunnel v2는 pre-training hyperparameter search의 비용을 낮추고, chunk-wise rollout은 long chain-of-thought RL에서 긴 응답이 worker를 오래 점유하는 문제를 줄인다.
Table 5 기준 Vanilla rollout은 step 488.57, sampling 392.61로 측정되지만 Chunk-4k는 step 281.27, sampling 148.14로 낮아진다.
BitCPM4는 ternary LLM 방향의 QAT 실험으로, “모델을 작게 만든다”가 weight bit width를 극단적으로 줄이는 문제와도 연결되어 있음을 보여 준다.
마지막 층은 추론 시스템이다.
CPM.cu는 sparse attention, quantization, speculative sampling을 통합한 CUDA inference framework로 공개되어 있고, MiniCPM4 README는 장문 가속을 재현하려면 LongRoPE 관련 rope_scaling 설정과 CPM.cu 경로를 사용하라고 안내한다.
ArkInfer는 여러 backend 환경을 지원하는 cross-platform deployment system으로 설명된다.
다만 이 둘은 논문 속 구성요소이자 별도 공개 표면이므로, “모든 스마트폰에서 바로 같은 속도가 난다”는 뜻으로 읽으면 안 된다.
실무에서는 어떤 backend가 dense/sparse를 지원하는지, 어떤 양자화 포맷이 필요한지, 어떤 hardware path가 실제로 쓰이는지를 따로 확인해야 한다.
공개된 근거에서 확인되는 점
표준 성능표에서 MiniCPM4는 작은 체급 대비 강한 숫자를 낸다.
Table 8의 핵심만 정리하면 다음과 같다.
| 모델 | 파라미터 | 학습 데이터 | 평균 | 해석 |
|---|---|---|---|---|
| Qwen3 | 0.6B | 36T | 44.93 | 작은 Qwen3 baseline |
| Gemma3 | 1B | 2T | 42.28 | 1B급 비교 모델 |
| MiniCPM4 | 0.5B | 1T | 52.99 | 0.5B 체급에서 높은 평균 |
| Qwen3 | 8B | 36T | 80.55 | 강한 8B baseline |
| GLM4 | 9B | 10T | 74.78 | 9B 비교 모델 |
| MiniCPM4 | 8B | 8T | 81.13 | 8B 체급에서 Qwen3-8B와 비슷하거나 높은 평균 |
MiniCPM4.1은 reasoning 쪽 변형이다.
Table 9에서는 MiniCPM4.1-8B full attention이 평균 80.17, sparse attention이 79.69를 기록한다.
같은 표의 Qwen3-8B full attention은 78.02, R1-Qwen3-8B는 79.72다.
여기서 흥미로운 점은 sparse attention의 평균 하락이 크지 않다는 것이다. full 대비 sparse가 모든 항목에서 이기는 것은 아니지만, 평균 0.48점 차이로 장문 추론 비용 절감 여지를 남긴다.
장문 평가도 같은 방향이다.
논문은 YaRN으로 MiniCPM4 context window를 128K까지 확장해 RULER-NIAH를 평가하고, 128K에서 100% needle-in-a-haystack accuracy를 제시한다.
RULER 32K Table 10에서는 MiniCPM4.1 full attention의 weighted average가 88.93, sparse attention이 85.84다.
성능이 무손실은 아니지만, sparse attention이 장문 이해 능력을 상당 부분 유지한다는 근거로 읽을 수 있다.
릴리스 표면을 보면 MiniCPM4는 단일 체크포인트보다 넓은 패키지다.
Hugging Face의 MiniCPM4 컬렉션은 paper 1개와 모델·데이터셋을 포함해 30개 item을 담고 있다.
확인 시점의 Hub API 기준으로 openbmb/MiniCPM4-8B와 openbmb/MiniCPM4.1-8B는 모두 Apache-2.0 라이선스, text-generation pipeline, custom_code 태그, 약 8.185B safetensors parameter metadata를 갖는다.
같은 컬렉션에는 0.5B 모델, GGUF·GPTQ·AWQ·MLX·Marlin 변형, Eagle speculative decoding 관련 repo, Ultra-FineWeb dataset, MiniCPM4-Survey, MiniCPM4-MCP가 함께 있다.
GitHub 쪽은 조금 더 복합적이다.OpenBMB/MiniCPM repo는 MiniCPM4만이 아니라 MiniCPM5까지 포함하는 메인 repo로 발전했고, 확인 시점 API 기준 별도 latest release는 MiniCPM5-1B다.
반면 OpenBMB/CPM.cu는 MiniCPM4 추론 최적화를 위해 2025년 6월 공개된 별도 CUDA framework이며, repo 설명 자체가 “end-device inference, sparse architecture, speculative sampling, quantization”을 전면에 둔다.
다만 CPM.cu API에서는 tags나 latest release가 확인되지 않았으므로, 실무 적용 시에는 설치 가능성·지원 GPU·커널 상태를 README와 실제 빌드로 다시 확인해야 한다.
실무 관점에서의 해석
MiniCPM4의 가장 큰 가치는 “온디바이스 LLM의 효율은 모델 크기 하나로 결정되지 않는다”는 점을 매우 노골적으로 보여 준다는 데 있다.
8B 모델이든 0.5B 모델이든 실제 제품이 되려면 학습 데이터 품질, 장문 attention, post-training, 양자화, speculative decoding, runtime kernel이 하나의 경로로 이어져야 한다.
MiniCPM4는 그 경로를 기술 보고서와 공개 artifact 묶음으로 제시한다.
앱 팀이나 edge AI 팀이 볼 때 이 릴리스는 세 가지 질문을 던진다.
첫째, 모델 품질이 target task에 충분한가.
Table 8과 Table 9의 평균은 강하지만, author-reported benchmark이고 task별 우열은 다르다.
예를 들어 MiniCPM4-8B는 HumanEval 85.37, CMMLU 80.62, CEval 81.36처럼 강한 항목이 있지만 MATH500은 Qwen3-8B보다 낮다.
Reasoning 변형도 sparse attention에서 평균은 잘 유지되지만 LCB나 일부 code 항목에서는 하락이 보인다.
둘째, 패키징이 제품 경로와 맞는가.
Hugging Face 모델은 custom_code를 포함하므로 Transformers에서 trust_remote_code를 켜는 경로가 필요할 수 있다.
GGUF, GPTQ, AWQ, MLX, Marlin, Eagle 변형이 있다는 것은 선택지가 많다는 뜻이지만, 동시에 각 포맷의 지원 runtime, quality loss, memory footprint, license, 업데이트 주기를 따로 검증해야 한다는 뜻이기도 하다.
셋째, sparse 효율을 실제 runtime에서 살릴 수 있는가.
MiniCPM README는 vLLM과 SGLang이 dense inference 경로를 지원하고, sparse inference는 Hugging Face Transformers와 CPM.cu 쪽을 사용하라고 안내한다.
즉 모델이 sparse attention을 배웠다고 해서 모든 서빙 프레임워크에서 자동으로 같은 가속이 나오지는 않는다.
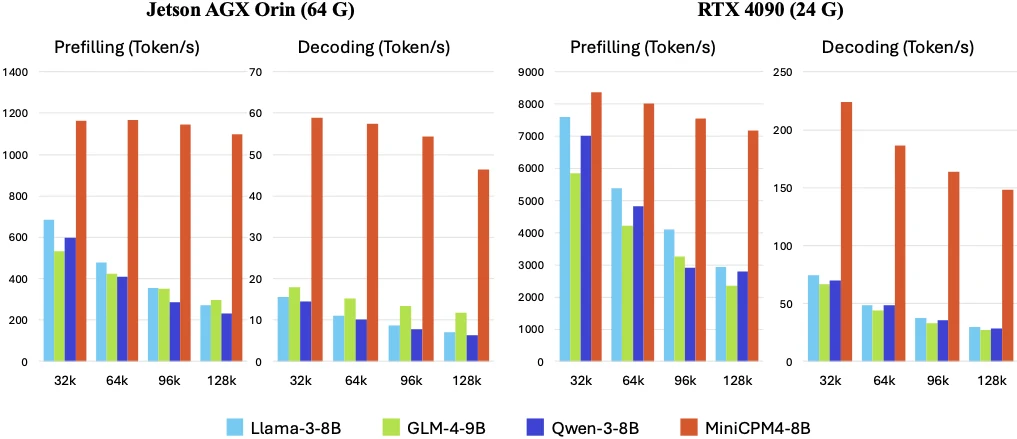
Jetson AGX Orin이나 RTX 4090에서의 수치는 강한 신호지만, 스마트폰 NPU/ANE/DSP나 일반 소비자 노트북에서는 별도의 runtime adaptation이 필요하다.
그럼에도 MiniCPM4는 온디바이스 LLM 경쟁의 방향을 잘 보여 준다.
앞으로 작은 모델 릴리스는 단순히 “몇 B 파라미터인가”보다 더 복잡한 질문으로 평가될 가능성이 높다.
어떤 데이터 필터링으로 학습 토큰을 줄였는가.
긴 문맥에서 attention density를 어디까지 낮췄는가.
양자화와 speculative decoding이 실제 decode 지연을 줄였는가.
공개 모델이 어떤 runtime과 포맷으로 내려오는가.
MiniCPM4는 이 질문들을 한 번에 묶은 사례다.
내가 보기에는 MiniCPM4를 바로 “모든 온디바이스 앱의 정답”으로 받아들이기보다, 온디바이스 LLM을 만들 때 점검해야 할 설계 checklist로 보는 편이 유용하다.
모델·데이터·학습·추론 시스템이 같은 목표를 향해야 효율이 난다는 점, 그리고 논문 수치가 아무리 좋아도 배포 단계에서는 custom code, runtime support, hardware target, artifact maturity를 다시 확인해야 한다는 점이 이 릴리스의 실무적 교훈이다.
결론: 작은 모델이 아니라 작은 실행 경로를 만든다
MiniCPM4의 강점은 8B 모델 하나의 점수보다, 그 점수를 만들기 위해 줄인 경로에 있다.
InfLLM v2로 긴 문맥 attention을 줄이고, UltraClean 계열 데이터 전략으로 학습 토큰 효율을 높이며, ModelTunnel v2와 chunk-wise rollout로 학습·RL 비용을 낮추고, CPM.cu와 ArkInfer로 실제 edge runtime을 겨냥한다.
이 네 층이 맞물릴 때 “온디바이스 LLM”이라는 말이 단순 슬로건이 아니라 시스템 설계 문제가 된다.
서버 LLM 시대의 릴리스 단위가 API endpoint와 checkpoint였다면, 온디바이스 LLM 시대의 릴리스 단위는 더 넓다. checkpoint, tokenizer, sparse attention implementation, quantization format, speculative draft model, runtime kernel, device별 배포 가이드가 함께 움직여야 한다.
MiniCPM4는 그 전환을 꽤 선명하게 보여 주는 공개 사례다.