프롬프트 엔지니어링이라고 하면 보통 사람이 자연어 지시문을 바꿔 가며 좋은 문장을 찾는 장면을 떠올린다.
하지만 prefix-tuning과 prompt tuning이 말하는 프롬프트는 조금 다르다.
여기서의 프롬프트는 사람이 읽는 문장이 아니라, 모델 입력이나 내부 activation에 붙는 학습 가능한 연속 벡터다.
모델 본체는 얼려 두고, 그 작은 벡터만 역전파로 학습한다.
이 관점에서 보면 prefix-tuning, soft prompt tuning, suffix prompt tuning, passage-specific prompt tuning은 서로 다른 논문 이름이라기보다 같은 질문에 대한 여러 답에 가깝다.
“거대한 LLM을 매번 다시 학습하거나 복사하지 않고, 특정 태스크에 필요한 steering signal만 어디에 저장할 것인가?”
라는 질문이다.
답은 태스크에 따라 달라진다.
생성 태스크에서는 prefix가 모든 토큰을 steer하고, 분류·이해 태스크에서는 입력 앞의 soft prompt가 충분할 수 있으며, 임베딩 태스크에서는 causal LLM의 마지막 토큰이 앞 문장을 보도록 suffix가 더 자연스럽다.
리랭커에서는 passage마다 달라지는 정보까지 prompt module 안에 넣는다.
이 글은 개인 기술 노트 형태의 원문이 엮은 네 갈래를, 각 논문의 primary source 기준으로 다시 정리한다.
핵심은 “프롬프트를 잘 쓰자”가 아니라, 프롬프트를 학습 가능한 parameter-efficient adapter로 보자는 전환이다.
무엇을 해결하려는가
풀 파인튜닝은 가장 직관적인 적응 방식이다.
태스크 데이터로 모델 전체를 업데이트하면 된다.
문제는 모델이 커질수록 이 방식이 배포와 운영에서 무거워진다는 점이다.
태스크마다 7B, 11B, 70B 모델 사본을 따로 저장하고 서빙하는 것은 비싸다.
LoRA나 adapter처럼 일부 파라미터만 업데이트하는 방법이 등장한 이유도 여기에 있다.
반대로 사람이 쓰는 hard prompt는 가볍지만 불안정하다.
자연어 prompt는 사람이 읽을 수 있다는 장점이 있지만, 작은 표현 차이에 민감하고, 학습 데이터가 충분히 있을 때 그 신호를 체계적으로 흡수하기 어렵다.
GPT-3식 in-context learning도 입력 context 길이에 묶인다.
학습 데이터 전체에서 온 신호를 하나의 작은 조건부 상태로 압축하고 싶다면, 자연어 문자열보다 연속 벡터가 더 직접적이다.
검색·RAG 시스템에서는 이 문제가 더 복잡해진다.
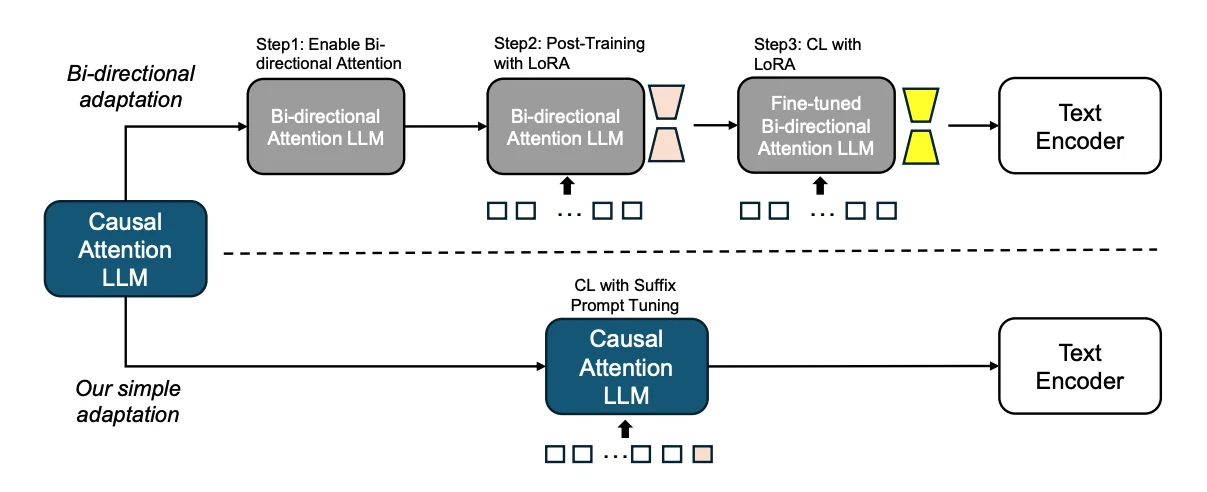
LLM을 embedding model로 쓰려면 decoder-only 모델의 causal attention이 문장 표현에 충분한가라는 문제가 생긴다.
기존 방식은 bi-directional attention으로 바꾸고, masked next-token prediction 같은 post-training을 거친 뒤, contrastive learning으로 다시 튜닝하는 식으로 무거워지기 쉽다.
리랭킹에서는 query-document 관련성을 더 잘 보려면 LLM을 candidate passage마다 실행해야 하는데, hard prompt만으로는 relevance pair 데이터와 passage-specific 정보를 충분히 활용하기 어렵다.
그래서 prompt tuning 계열의 질문은 하나로 모인다.
| 문제 | 전통적 해결 | prompt tuning식 재해석 |
|---|---|---|
| 생성 태스크 적응 | 모델 전체 또는 adapter 업데이트 | frozen LM에 task-specific prefix를 붙인다 |
| 대형 모델 다중 태스크 서빙 | 태스크별 모델 사본 저장 | frozen backbone 하나 + task별 soft prompt 저장 |
| decoder-only LLM의 임베딩화 | bi-directional 변환, post-training, LoRA | causal attention을 유지하고 입력 뒤 suffix prompt만 학습 |
| passage reranking | hard prompt 또는 LLM 전체 파인튜닝 | passage-specific soft prompt로 query likelihood를 조정 |
핵심 아이디어 / 구조 / 동작 방식
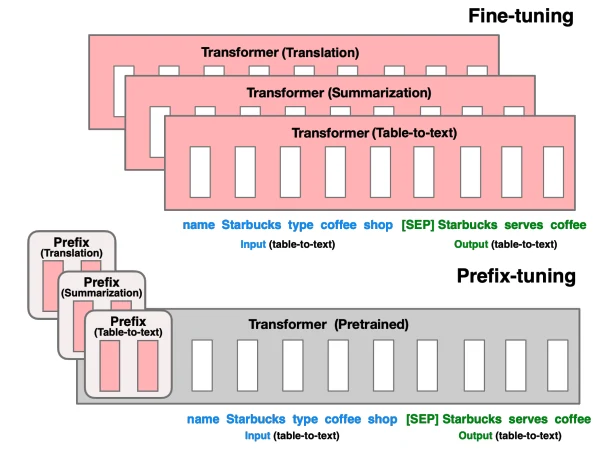
가장 먼저 구분해야 할 것은 prefix-tuning과 prompt tuning이다.
Li와 Liang의 Prefix-Tuning은 모델 파라미터를 얼린 뒤, 각 layer의 activation 앞에 붙는 continuous prefix를 학습한다.
논문 표현을 빌리면 이후 토큰들이 이 prefix를 “virtual tokens”처럼 attend할 수 있다.
중요한 점은 prefix가 실제 단어가 아니라 free parameter라는 것이다.
즉 “요약해줘” 같은 문장을 찾는 것이 아니라, 모델 내부가 특정 generation task를 수행하도록 하는 연속 steering vector를 찾는다.
Lester et al.
의 Prompt Tuning은 이를 더 단순화한다.
모든 layer에 prefix activation을 넣는 대신, 입력 embedding 앞에 몇 개의 tunable token만 붙인다.
이 soft prompt는 end-to-end로 학습되지만, frozen model 자체는 그대로다.
그래서 서빙 관점에서는 하나의 거대한 generalist model을 공유하고, 태스크별로 작은 prompt만 교체할 수 있다.
두 방식의 차이는 “얼마나 깊게 개입하느냐”다.
Prefix-tuning은 더 깊은 layer activation까지 직접 만지므로 표현력은 크지만, prompt tuning은 입력 embedding 레벨에서만 개입하므로 단순하고 저장 비용이 더 작다.
Lester et al.
은 T5 실험에서 모델 크기가 커질수록 prompt tuning이 full model tuning과의 격차를 닫는다는 점을 보였다.
즉 soft prompt가 작은 모델에서는 부족할 수 있지만, 대형 모델에서는 frozen backbone의 능력을 꺼내는 조건부 key처럼 작동할 가능성이 커진다.
임베딩 모델로 넘어가면 위치가 바뀐다.
“Prompt Tuning Can Simply Adapt Large Language Models to Text Encoders”는 decoder-only LLM을 text encoder로 바꾸기 위해 앞에 prompt를 붙이는 대신, 입력 문장 뒤에 soft prompt를 append한다. causal attention에서는 뒤쪽 토큰이 앞쪽 문장 전체를 볼 수 있기 때문이다.
논문은 Suffix Prompt Tuning(SPT)에서 appended soft prompt의 출력, 특히 prompt 길이가 1보다 클 때 마지막 soft prompt token의 hidden state를 sentence embedding으로 사용한다.
이 벡터를 contrastive learning objective로 학습하면 frozen LLM을 sentence encoder처럼 쓸 수 있다.
리랭커 쪽의 PSPT는 한 단계 더 특수하다.
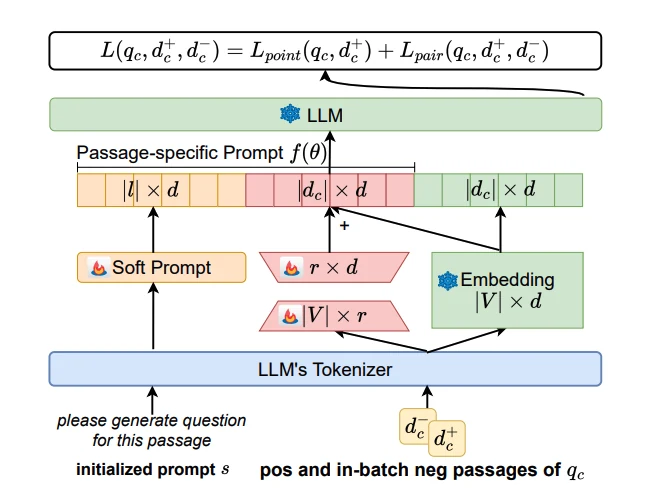
“Passage-specific Prompt Tuning for Passage Reranking in Question Answering with Large Language Models”는 passage를 보고 원래 question을 생성할 log-likelihood를 relevance score로 쓰는 query-generation reranking 계열이다.
여기에 단순 task prompt만 넣지 않고, passage마다 달라지는 passage-specific prompt module을 학습한다.
LLM 파라미터는 고정하고, soft prompt와 passage-specific embedding layer만 업데이트한다.
정리하면 각 기법은 같은 철학을 공유하지만, prompt가 들어가는 위치와 읽히는 방식이 다르다.
| 기법 | 학습되는 것 | 붙는 위치 | frozen 상태 | 주 사용처 |
|---|---|---|---|---|
| Prefix-tuning | layer별 continuous prefix activation | 여러 transformer layer의 앞 | LM 본체 frozen | table-to-text, summarization 같은 generation |
| Prompt tuning | 입력 앞 soft prompt token | input embedding 앞 | LM 본체 frozen | NLU / text-to-text task adaptation |
| Suffix Prompt Tuning | 입력 뒤 soft prompt token | sentence 뒤쪽 | LLM 본체 frozen | decoder-only LLM의 sentence embedding화 |
| PSPT | task soft prompt + passage-specific embedding module | passage embedding과 결합된 LLM 입력 | LLM 본체 frozen | ODQA passage reranking |
공개된 근거에서 확인되는 점
Prefix-Tuning 논문은 GPT-2를 table-to-text generation에, BART를 summarization에 적용했다.
핵심 수치는 단순하다.
전체 파라미터의 약 0.1%만 수정해 full-data setting에서는 full fine-tuning과 비교 가능한 성능을 얻고, low-data setting에서는 fine-tuning보다 나은 결과를 보였다고 보고한다.
논문은 또한 topic이 training set에 없던 예시로 extrapolate할 때도 prefix-tuning이 더 잘 버틴다고 주장한다.
이 결과가 중요한 이유는, prefix가 단순한 저장비 절약 장치가 아니라 low-data regularization처럼도 작동할 수 있음을 보여주기 때문이다.
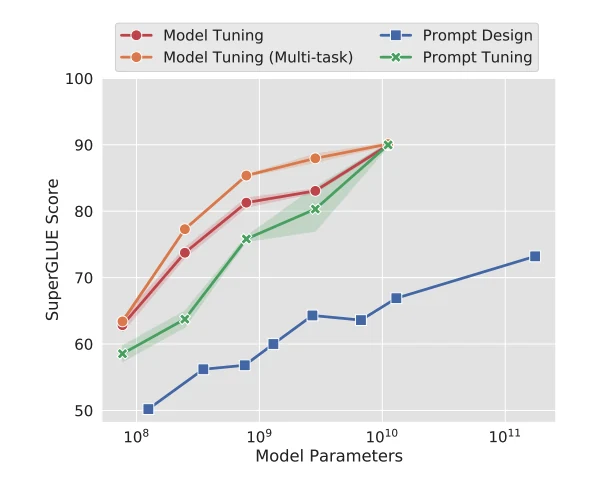
Prompt Tuning 논문은 T5 계열을 대상으로 SuperGLUE를 평가했다.
여기서 포인트는 scaling이다.
작은 모델에서는 prompt tuning이 full model tuning을 따라가기 어렵지만, 수십억 파라미터 이상으로 커질수록 격차가 줄어든다.
논문은 T5 XXL 11B 크기에서 prompt tuning이 강한 multi-task model tuning baseline과 match한다고 보고하며, task별 prompt만 저장하면 되므로 태스크별 full model copy를 저장하는 방식보다 훨씬 작다.
논문 예시에서는 prompt length 5일 때 task prompt가 20,480개 파라미터 규모이고, task별 11B 모델 사본과 대비된다.
Google Research는 이 Prompt Tuning 실험 재현용 코드와 체크포인트를 google-research/prompt-tuning 저장소로 공개했다.
따라서 이 논문은 개념 제안뿐 아니라, T5X/Flax 기반 재현 경로까지 비교적 명확한 편이다.
SPT 논문은 임베딩 쪽에서 더 흥미로운 수치를 준다.
저자들은 OPT-125M, LLaMA2-7B, LLaMA3-8B를 대상으로 retrieval, STS, clustering, classification을 평가했다.
LLaMA2-7B에서는 SPT-uni k=16이 trainable parameter 0.000973%로 평균 69.70을 기록해 LoRA-uni 69.66과 거의 같거나 조금 높았다.
LLaMA3-8B에서는 SPT-uni k=5가 0.000255% trainable parameter로 평균 71.73을 기록해 LoRA-uni 71.24와 LoRA-bi 70.61을 넘었다.
OPT-125M에서도 SPT k=16은 0.009812% trainable parameter로 full fine-tuning 평균 65.00에 가까운 64.79를 냈다.
| 모델 / 설정 | Trainable params | Retrieval | STS | Clustering | Classification | Avg |
|---|---|---|---|---|---|---|
| OPT-125M full fine-tuning | 100% | 81.33 | 79.69 | 39.46 | 59.53 | 65.00 |
OPT-125M SPT k=16 |
0.009812% | 81.39 | 78.71 | 39.21 | 59.84 | 64.79 |
| LLaMA2-7B LoRA-uni | 0.59% | 85.64 | 85.24 | 45.97 | 61.79 | 69.66 |
LLaMA2-7B SPT-uni k=16 |
0.000973% | 85.34 | 84.93 | 45.74 | 62.77 | 69.70 |
| LLaMA3-8B LoRA-uni | 0.56% | 86.65 | 85.87 | 49.63 | 62.81 | 71.24 |
LLaMA3-8B SPT-uni k=5 |
0.000255% | 87.18 | 86.00 | 49.98 | 63.75 | 71.73 |
이 결과를 “LoRA는 필요 없다”로 읽으면 과장이다.
논문 조건은 비교적 짧은 NLI training set과 선택된 MTEB/SentEval 태스크이며, 도메인별 production embedding 품질은 별도 검증이 필요하다.
다만 “decoder-only LLM을 text encoder로 쓰려면 반드시 bi-directional 변환과 MNTP post-training을 해야 한다”는 강한 가정에는 꽤 날카로운 반례를 제시한다. causal attention을 그대로 둔 채 suffix prompt만 학습해도 경쟁적인 성능이 나온다는 점이 핵심이다.
PSPT는 open-domain QA의 passage reranking에서 비슷한 parameter-efficient 발상을 적용한다.
논문은 Llama-2-chat-7B를 사용하고, NQ, SQuAD, TriviaQA에서 BM25, MSS, Contriever, DPR, MSS-DPR 같은 retriever의 top-k 결과를 다시 정렬한다. baseline으로는 UPR과 instruction variant인 UPR-Inst를 둔다.
PSPT는 Table 1에서 여러 retriever/dataset 조합에 걸쳐 base retriever와 UPR 대비 통계적으로 유의한 개선을 보고한다.
| Retriever family | NQ R@10 / H@10 | SQuAD R@10 / H@10 | TriviaQA R@10 / H@10 | 해석 |
|---|---|---|---|---|
| BM25 + UPR | 32.31 / 59.45 | 42.33 / 64.78 | 36.17 / 71.80 | hard/LLM prompt reranking baseline |
| BM25 + PSPT | 36.89 / 62.24 | 46.04 / 66.76 | 42.63 / 73.71 | BM25 후보 위에서 PSPT가 일관 개선 |
| DPR + UPR | 41.73 / 75.60 | 41.57 / 66.01 | 36.83 / 80.28 | supervised retriever + UPR |
| DPR + PSPT | 45.73 / 77.84 | 45.27 / 68.45 | 42.53 / 81.67 | relevance pair를 prompt module에 흡수 |
| MSS-DPR + UPR | 38.79 / 76.81 | 46.96 / 77.10 | 31.33 / 81.56 | 강한 supervised retriever 조합 |
| MSS-DPR + PSPT | 43.02 / 79.09 | 51.23 / 79.36 | 36.24 / 82.83 | 상위 후보 분포가 달라도 개선 |
PSPT의 장점은 hard prompt의 취약성을 줄이면서도 LLM 전체를 fine-tune하지 않는다는 데 있다.
그러나 한계도 명확하다.
이 비교의 중심은 UPR 계열과 여러 retriever 조합이며, RankGPT류 listwise reranker나 최신 cross-encoder reranker 전체와의 정면 비교까지 포함하지는 않는다.
또한 reranking은 후보마다 LLM scoring이 필요하므로, parameter-efficient training이 곧 inference-efficient ranking을 의미하지는 않는다.
실무 관점에서의 해석
내가 보기에 이 계보의 핵심은 “프롬프트를 텍스트가 아니라 배포 가능한 상태값으로 본다”는 점이다. hard prompt는 사람이 편집하는 instruction이고, soft prompt는 데이터로 학습한 adapter state다.
모델 가중치를 바꾸지 않기 때문에 backbone은 공유할 수 있고, task별·고객별·도메인별로 작은 prompt artifact만 갈아 끼울 수 있다.
이 발상은 멀티테넌트 LLM 서비스나 사내 RAG 시스템처럼 하나의 기반 모델 위에 많은 업무를 얹는 환경에서 특히 중요하다.
다만 soft prompt는 만능 대체재가 아니다.
사람이 읽기 어려운 연속 벡터이기 때문에, prompt engineering처럼 규칙을 직접 검토하거나 수정하기 어렵다.
또한 작은 prompt가 모델의 모든 부족함을 해결해주지는 않는다. backbone이 해당 능력을 충분히 갖고 있어야 하고, 학습 데이터가 prompt에 적절한 방향성을 줄 수 있어야 한다.
Prompt Tuning 논문이 scaling을 강조한 것도 이 때문이다.
작은 모델에서는 prompt만으로 꺼낼 수 있는 잠재 능력이 제한될 수 있다.
기법 선택은 태스크의 정보 흐름에 따라 달라진다.
생성에서는 prefix가 이후 생성 토큰을 steer하면 된다.
NLU/text-to-text에서는 입력 앞의 soft prompt로 충분할 수 있다.
임베딩에서는 causal LLM의 마지막 hidden state가 앞 문장을 모두 볼 수 있게 suffix 위치가 중요하다.
리랭킹에서는 passage마다 다른 evidence를 반영해야 하므로 passage-specific prompt module이 필요해진다.
결국 “soft prompt를 쓴다”보다 더 중요한 질문은 어떤 토큰이 어떤 정보를 attend해야 하는가다.
RAG 관점에서는 SPT와 PSPT가 특히 흥미롭다.
SPT는 embedding layer를 더 가볍게 domain-adapt할 수 있는 가능성을 보여준다.
특정 조직의 문서 분포에 맞춰 거대한 embedding model을 다시 만들기 어렵다면, frozen LLM 또는 기존 LLM 기반 encoder 위에 suffix prompt만 학습하는 실험은 비용 대비 시도해볼 만하다.
PSPT는 reranker가 단순한 cross-encoder가 아니라 generative likelihood scorer일 때, relevance pair 데이터를 어떻게 prompt module에 넣을 수 있는지 보여준다.
그러나 운영에서는 항상 비용 축을 분리해야 한다.
Trainable parameter가 작다는 것은 학습 artifact가 작다는 뜻이지, inference가 자동으로 싸다는 뜻은 아니다.
SPT embedding은 한 번 인코딩한 벡터를 인덱싱할 수 있어 운영상 장점이 비교적 명확하지만, PSPT류 LLM reranking은 후보 passage마다 log-likelihood scoring을 해야 하므로 latency budget을 따로 계산해야 한다.
최신 RAG 스택에서는 bi-encoder retrieval, lightweight reranker, LLM-based reranker를 단계별로 섞는 설계가 더 현실적일 수 있다.
그래도 이 흐름은 계속 중요해질 가능성이 높다.
LoRA가 “가중치 업데이트를 작게 만들자”는 방향이었다면, prompt tuning 계열은 “업데이트 자체를 모델 바깥의 작은 조건부 벡터로 밀어내자”는 방향이다.
앞으로 좋은 라이브러리는 단순히 prompt_length=20을 지원하는 수준을 넘어, generation용 prefix, embedding용 suffix, reranking용 passage-specific module을 같은 adapter registry와 evaluation loop 안에서 다룰 필요가 있다.
프롬프트가 문장에서 벡터로, 다시 운영 가능한 adapter artifact로 바뀌고 있다는 점이 이 계보의 가장 큰 의미다.