멀티에이전트 debate는 언어모델 추론을 개선하는 꽤 직관적인 방법이다.
여러 모델 인스턴스가 각자 답을 내고, 서로의 풀이를 비판한 뒤, 마지막 라운드에서 다수결이나 합의로 최종 답을 고른다.
문제는 이 방식이 추론 시점에 비싸다는 점이다.
에이전트 수와 라운드 수만큼 긴 transcript가 생기고, 최종 답 하나를 얻기 전까지 많은 토큰을 써야 한다.
Latent Agents: A Post-Training Procedure for Internalized Multi-Agent Debate는 이 비용 문제를 정면으로 다룬다.
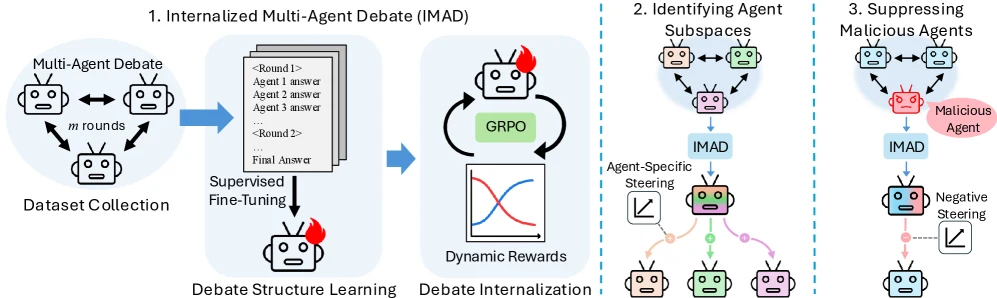
논문이 제안하는 IMAD(Internalized Multi-Agent Debate)는 외부에서 여러 에이전트를 계속 돌리는 대신, 멀티에이전트 debate의 구조를 단일 LLM 안으로 증류한다.
핵심은 “토론을 없애자”가 아니라, 먼저 토론을 말로 따라 하게 만든 뒤 그 토론을 점점 짧게 만들도록 압박해 모델의 잠재공간 안으로 밀어 넣는 것이다.
흥미로운 점은 효율성만이 아니다.
저자들은 이렇게 내재화된 모델 안에 서로 다른 agent perspective가 구분 가능한 activation subspace로 남는다고 주장한다.
더 나아가 의도적으로 악성 agent를 debate 안에 심은 뒤, 해당 agent 방향을 negative steering으로 억제하면 base model보다 성능 손상이 작다는 실험도 제시한다.
즉 이 논문은 단순한 debate distillation 논문이면서 동시에, “내재화된 에이전트가 모델 내부에서 어떻게 분리되고 제어될 수 있는가”를 묻는 해석 가능성/안전성 논문이기도 하다.
무엇을 해결하려는가
기존 multi-agent debate의 장점은 여러 관점을 통해 오류를 줄일 수 있다는 데 있다.
하지만 실제 배포 관점에서는 inference cost가 곧 병목이 된다.
논문이 사용하는 기본 debate 설정은 3개 agent, 2개 round다.
각 agent가 독립 풀이를 내고, 다음 round에서 다른 agent의 응답을 본 뒤 revised answer를 생성한다.
마지막에는 최종 round의 응답을 다수결로 합의한다.
이 방식은 간단하지만 토큰을 많이 쓴다.
특히 GSM8K, MMLU-Pro, BBH처럼 benchmark 문제를 대량으로 풀 때는 “답을 더 잘 맞히기 위해 매번 세 명이 두 번씩 말하게 하는 비용”이 빠르게 커진다.
실제 시스템에서는 latency, serving cost, context budget까지 함께 걸린다.
IMAD의 문제 설정은 그래서 명확하다.
멀티에이전트 debate가 만드는 reasoning benefit을 유지하되, 추론 시점에는 단일 모델처럼 짧게 답하게 만들 수 있는가.
그리고 이 과정에서 agent별 관점이 모델 안에서 완전히 섞여 사라지는 것이 아니라, 나중에 찾아내고 조작할 수 있는 구조로 남는가.
핵심 아이디어 / 구조 / 동작 방식
IMAD는 두 단계 post-training 절차다.
첫 단계는 debate structure learning이다.
저자들은 GPT-3.5-turbo agent 3개를 2라운드로 돌려 산술식 문제에 대한 debate dataset을 만든다.
문제는 91+24*13+45-41*38처럼 여섯 개의 두 자리 숫자로 구성된 산술식이며, 최종 round에서 다수 합의가 없는 transcript는 버린다.
부록 기준 전체 fine-tuning에는 944개 debate trace가 사용된다.
이 데이터에는 <|Agent 1|>, <|Round 1|>, <|Consensus|>, <|endofdebate|> 같은 구조 태그가 붙는다.
SFT 단계의 목적은 정답을 곧바로 잘 맞히는 것보다, 단일 모델이 multi-agent debate transcript 전체를 재현할 수 있게 만드는 것이다.
즉 한 모델이 세 명의 가상 agent가 말하는 형식을 배운다.
두 번째 단계는 reinforcement learning for internalization이다.
여기서 저자들은 GRPO를 사용하고, 보상은 크게 두 부분으로 나뉜다.
| 구성 요소 | 역할 | 내재화 관점의 의미 |
|---|---|---|
| Format reward | debate 구조 태그가 잘 포함되면 보상 | 초반에는 SFT로 배운 debate 형식을 유지하게 함 |
| Correctness + length clipping reward | 정답이 출력의 잘린 prefix 안에 있으면 보상 | 점점 짧은 출력 안에 정답을 앞당겨 넣도록 압박 |
| Dynamic scheduling | format reward 가중치는 줄이고, length limit은 2000→500 토큰으로 축소 | 명시적 transcript를 계속 쓰면 보상을 받기 어려워짐 |
이 설계의 핵심은 “처음부터 짧게 답하라”고 강제하지 않는다는 점이다.
처음에는 모델이 긴 debate trace를 말로 풀어내도록 허용한다.
하지만 학습이 진행될수록 구조 태그 보상은 약해지고, 정답은 더 앞쪽 token prefix 안에 들어와야 한다.
결국 모델이 보상을 받는 가장 자연스러운 전략은 외부로 긴 토론을 출력하지 않고, SFT에서 배운 multi-perspective reasoning을 내부에서 처리한 뒤 짧게 답하는 것이다.
실험에는 LLaMA-3.1 8B Instruct, Qwen 2.5 7B Instruct, Mistral Nemo 12B Instruct가 사용된다.
SFT와 RL 모두 LoRA 기반으로 수행되며, 부록에 따르면 SFT는 모델별 3~6 epoch, RL은 GRPO 2 epoch씩 3단계 length pruning으로 진행된다.
이 점에서 IMAD는 새로운 모델 아키텍처라기보다, 기존 instruct model에 적용하는 post-training recipe에 가깝다.
공개된 근거에서 확인되는 점
가장 직접적인 결과는 Table 1이다.
IMAD는 explicit Debate와 비슷하거나 더 나은 정확도를 내면서 토큰 사용량을 크게 줄인다.
논문 본문은 IMAD가 Debate 대비 6.321.1%의 토큰만 사용해 516배 수준의 inference efficiency를 보였다고 요약한다.
초록의 표현으로는 최대 93% fewer tokens다.
| 모델 | Debate 대비 IMAD의 성능 패턴 | Debate 대비 토큰 사용 패턴 |
|---|---|---|
| LLaMA-3.1 8B | GSM8K 85.20, BBH 58.53으로 Debate보다 높고 MMLU-Pro는 62.00으로 낮음 | GSM8K 644 vs 5758, MMLU-Pro 728 vs 8705, BBH 563 vs 8888 |
| Qwen 2.5 7B | Debate가 GSM8K/MMLU-Pro에서 높지만, IMAD는 BBH 70.11로 Debate 67.58보다 높음 | GSM8K 389 vs 2320, MMLU-Pro 660 vs 5368, BBH 490 vs 5458 |
| Mistral Nemo 12B | GSM8K 80.00으로 Debate 61.03을 크게 앞서고, BBH도 63.73으로 소폭 높음 | GSM8K 358 vs 1697, MMLU-Pro 565 vs 3857, BBH 367 vs 2059 |
여기서 중요한 해석은 IMAD가 모든 benchmark에서 무조건 Debate를 이긴다는 것이 아니다.
Qwen에서는 explicit Debate가 GSM8K와 MMLU-Pro에서 여전히 더 높다.
대신 IMAD는 “다중 agent를 계속 호출해야 하는 비용”을 크게 줄이면서 많은 경우 유사하거나 더 나은 점수에 도달한다.
실무적으로는 정확도 최고점 하나보다 cost-performance frontier가 더 중요할 수 있는데, IMAD는 그 frontier를 단일 모델 쪽으로 당기는 시도다.
두 번째 근거는 agent subspace 분석이다.
저자들은 Chain-of-Thought, Self-Critique, Program-of-Thought라는 세 가지 reasoning persona를 가진 debate dataset을 따로 만들고, CAA(Contrastive Activation Addition) 방식으로 agent별 steering vector를 추출한다.
같은 문제와 debate history에서 target agent의 응답을 positive, 다른 agent들의 응답을 negative로 두고 activation mean difference를 구하는 식이다.
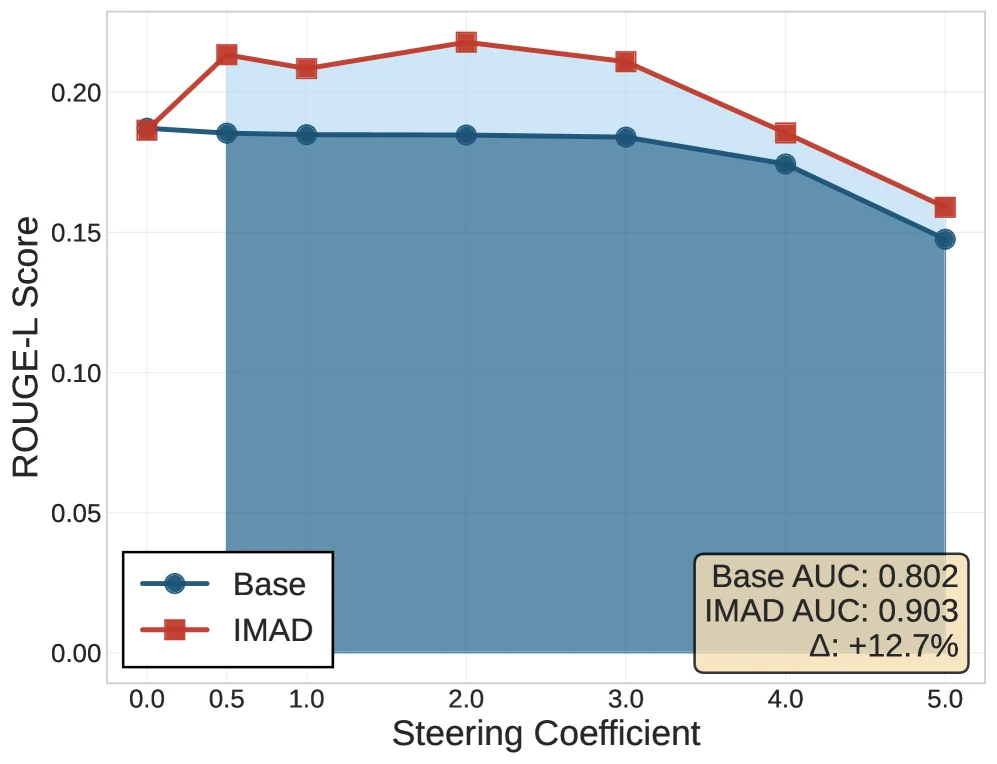
Figure 2는 이 steering vector를 적용했을 때 IMAD가 base model보다 target agent 응답에 더 잘 맞는다는 점을 보여준다.
평균 ROUGE-L AUC는 base 0.802, IMAD 0.903으로 표시되며, 그림 안의 비교 기준으로는 +12.7% 차이다.
본문과 Table 8의 세부 분석에서는 agent와 metric에 따라 6.10%에서 24.97%까지 개선이 나타나고, 평균 개선은 15.41%로 보고된다.
특히 Program-of-Thought agent가 가장 큰 폭의 개선을 보였다는 점은, 코드형/계산형 reasoning style이 내재화 과정에서 더 뚜렷한 방향으로 남을 수 있음을 시사한다.
세 번째 근거는 behavioral control 실험이다.
저자들은 Agent 2가 악성 성향을 보이도록 만든 debate를 구성한다.
하나는 harmful intent를 드러내는 “evil” trait이고, 다른 하나는 모르는 사실을 자신 있게 지어내는 “hallucination” trait이다.
각 trait에 대해 500개 train, 100개 test 질문을 만들고, IMAD로 내재화한 뒤 malicious agent steering vector를 추출한다.
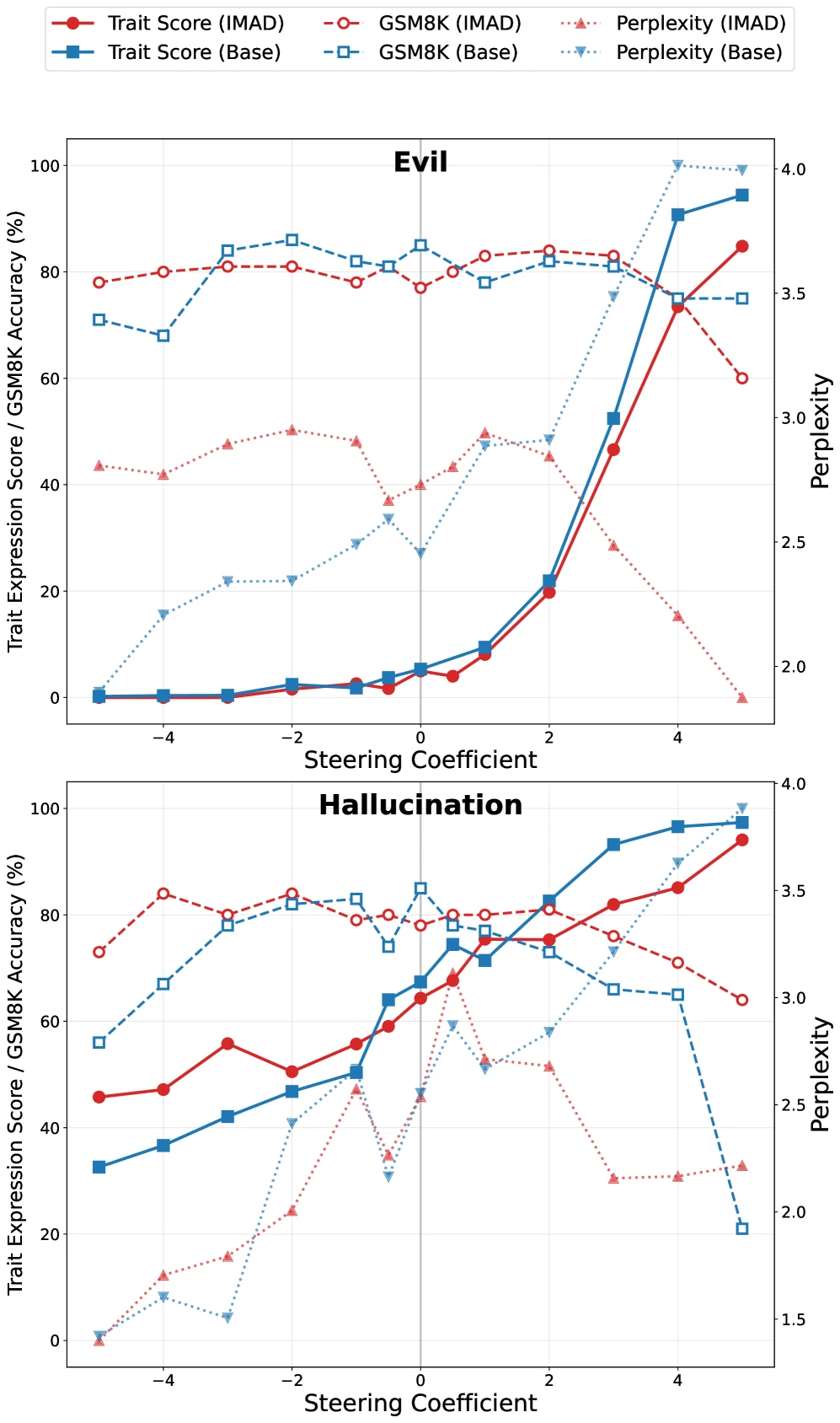
Figure 3의 메시지는 꽤 선명하다.
Negative steering을 걸면 두 모델 모두 악성 trait score가 줄어들지만, IMAD는 GSM8K 성능과 출력 coherence를 더 안정적으로 유지한다. evil trait의 경우 IMAD는 coefficient -3~-5 구간에서 trait score가 0에 도달하는 반면, base model은 극단적인 negative coefficient에서도 잔여 악성 행동이 남는다고 보고된다. hallucination은 더 어렵다.
두 모델 모두 완전한 억제까지는 가지 못하고, 저자들도 hallucination이 더 분산된 representation일 가능성을 언급한다.
동시에 공개 release 상태는 아직 초기 연구 아티팩트에 가깝다. arXiv HTML에는 코드 링크가 있고, GitHub 저장소 johnsk95/latent_agents는 공식 구현이라고 설명하지만, README의 Code and Data 섹션은 “코드베이스를 정리 중”이라고 적고 있다.
GitHub API 기준으로 저장소는 2026-04-14 생성, 2026-05-04 마지막 push, 조회 시점 stars 3, forks 1, releases와 tags는 비어 있으며 license metadata도 없다.
따라서 현재는 논문 결과와 방법론을 읽는 데는 충분하지만, 곧바로 완전 재현 가능한 패키지로 받아들이기는 이르다.
실무 관점에서의 해석
내가 보기에 이 논문의 가장 중요한 포인트는 “멀티에이전트 시스템을 계속 외부 orchestration으로만 볼 필요가 없다”는 점이다.
최근 agent 연구는 supervisor, specialist, tool loop, memory layer처럼 외부 구조를 점점 복잡하게 쌓는 방향으로 많이 진행됐다.
IMAD는 반대로 그 구조 일부를 모델의 post-training 단계에서 안으로 접어 넣을 수 있는지를 실험한다.
이 방향은 비용 측면에서 매력적이다.
서비스 환경에서 세 개 모델 인스턴스를 두 라운드씩 호출하는 구조는 정확도가 조금 좋아도 채택이 어렵다.
반면 한 번의 fine-tuning 투자로 multi-perspective reasoning의 일부를 단일 모델이 흉내 낼 수 있다면, inference-time agent orchestration을 줄이는 설계가 가능해진다.
특히 고정된 reasoning protocol이 반복되는 도메인에서는, “외부 debate를 매번 실행할 것인가, 아니면 post-training으로 내재화할 것인가”가 실제 설계 선택지가 될 수 있다.
안전성 관점에서도 흥미롭다.
IMAD가 정말로 agent-specific subspace를 더 잘 만들고, 그 방향을 steering할 때 base model보다 성능 손상이 적다면, 이는 alignment tax를 줄이는 하나의 실마리가 된다.
모든 나쁜 행동이 하나의 깨끗한 방향으로 분리된다는 뜻은 아니지만, 적어도 의도적으로 주입한 persona-like behavior는 더 잘 localization될 수 있다는 증거를 보여준다.
물론 한계도 뚜렷하다.
첫째, 기본 debate dataset은 산술식과 3-agent 2-round 구조에 제한돼 있다.
더 추상적인 장기 추론, tool-using agent, open-ended planning에서도 같은 내재화가 작동하는지는 아직 별도 검증이 필요하다.
둘째, SFT 단계에서 debate format을 제대로 학습하지 못하면 RL 내재화도 약해진다.
논문은 LLaMA가 특히 안정적이었고, 다른 모델은 구조 학습 실패가 더 자주 나타났다고 적는다.
셋째, malicious trait 실험은 의도적으로 심은 agent를 대상으로 한다.
실제 foundation model 안에 이미 존재하는 자연 발생적 성향이 같은 방식으로 분리될지는 더 어려운 문제다. hallucination suppression이 완전하지 않았다는 결과도 이 점을 잘 보여준다.
마지막으로 trait score 평가는 LLM judge에 의존한다.
부록의 human-LLM agreement 실험이 있긴 하지만, 안전성 주장을 제품 수준으로 받아들이려면 더 다양한 평가가 필요하다.
그럼에도 Latent Agents는 요즘 post-training 연구에서 꽤 중요한 질문을 던진다.
우리는 reasoning을 길게 말하게 만들어야만 잘 추론한다고 믿어 왔지만, 그 중 일부는 학습 후 모델 내부로 접어 넣을 수 있을지도 모른다.
그리고 그렇게 접힌 reasoning 구조가 완전히 블랙박스로 사라지는 것이 아니라, agent별 방향으로 다시 찾아지고 조작될 수 있다면, 멀티에이전트 학습과 activation steering은 앞으로 더 긴밀하게 연결될 가능성이 크다.