요즘 MoE 모델은 계산 효율의 상징처럼 쓰인다.
토큰마다 모든 FFN을 돌리지 않고 일부 expert만 활성화하므로, 총 파라미터는 크게 키우면서도 active parameter는 제한할 수 있다.
그런데 실제 배포 관점에서 보면 MoE에는 불편한 역설이 있다.
토큰 단위로 expert가 바뀌기 때문에, 특정 애플리케이션이 수학·코딩·의학처럼 좁은 능력만 필요해도 결국 대부분의 expert weight를 메모리에 올려 두어야 한다는 점이다.
EMO: Pretraining Mixture of Experts for Emergent Modularity는 이 문제를 꽤 정면으로 건드린다.
논문의 질문은 “MoE expert를 더 잘 pruning할 수 있는가”가 아니다.
더 정확히는 처음부터 expert subset이 독립적으로 쓸 수 있게끔 MoE를 사전학습할 수 있는가다.
저자들은 이를 emergent modularity라고 부르고, 명시적인 도메인 라벨 없이 문서 경계만으로 expert 그룹이 자연스럽게 생기도록 만드는 학습 objective를 제안한다.
흥미로운 점은 결과의 형태다.
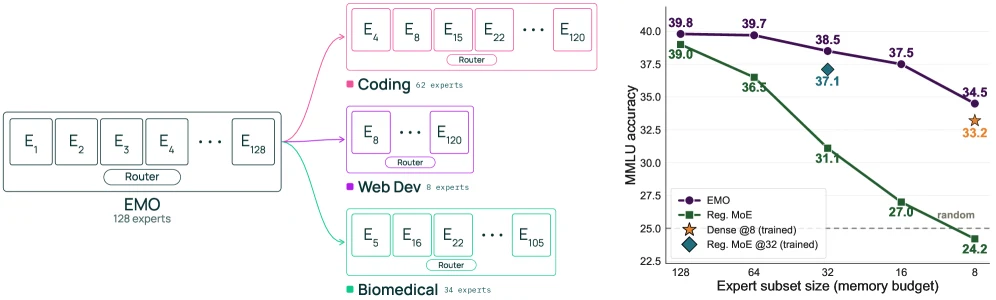
EMO는 1B active / 14B total 규모, 128개 expert, 토큰당 8개 active expert를 쓰는 MoE로 학습된다. full model로 평가하면 같은 구조의 표준 MoE와 거의 비슷한 성능을 낸다.
하지만 domain-specific expert subset만 남겨서 돌릴 때는 차이가 크게 벌어진다.
EMO는 25% expert만 유지해도 약 1%p, 12.5% expert만 유지해도 약 3%p 정도의 절대 성능 저하에 그친다고 보고한다.
반면 표준 MoE는 같은 제약에서 성능이 급격히 무너진다.
무엇을 해결하려는가
기존 MoE는 계산 그래프 관점에서는 sparse하지만, 배포 관점에서는 여전히 monolithic하다.
한 토큰은 expert 1·7·23을 쓰고, 다음 토큰은 expert 4·9·88을 쓸 수 있다.
문서 하나를 끝까지 생성하면 다양한 expert가 골고루 호출되고, 결국 serving system은 대부분의 expert weight를 준비해 둬야 한다.
이 구조는 “일부 능력만 필요한 애플리케이션”에서 특히 아깝다.
예를 들어 수학 문제 풀이, 코드 생성, biomedical QA, 법률 문서 질의처럼 도메인이 비교적 좁은 workload라면, 그 도메인에 필요한 expert subset만 로드하고 싶다.
하지만 표준 MoE에서는 그 subset이 의미 있는 기능 단위로 잘 분리되어 있지 않다.
논문과 Ai2 블로그는 표준 MoE expert가 종종 수학·코드 같은 고수준 도메인이 아니라 전치사, 관사, 구두점, 고유명사 같은 저수준 lexical pattern에 특화된다고 설명한다.
EMO가 노리는 것은 여기서 한 단계 더 나간 구조다.
- 전체 모델을 쓰면 general-purpose MoE처럼 동작해야 한다.
- 특정 도메인에서는 작은 expert subset만 독립적으로 써도 성능이 크게 떨어지지 않아야 한다.
- subset은 사람이 미리 정한 math/code/biology 라벨이 아니라, pretraining data 안에서 스스로 생겨야 한다.
즉 EMO의 목표는 sparsity 자체가 아니라 조립 가능한 sparsity다. expert를 단순한 계산 절감 장치가 아니라, 나중에 고르고 합칠 수 있는 기능 모듈로 만들겠다는 시도다.
핵심 아이디어 / 구조 / 동작 방식
EMO의 아이디어는 의외로 간단하다.
“같은 문서 안의 토큰은 대체로 같은 도메인에 속한다”는 약한 가정을 이용한다.
표준 MoE에서는 각 토큰이 독립적으로 top-k expert를 고른다.
EMO에서는 먼저 문서 단위로 공유 expert pool을 고르고, 그 문서의 모든 토큰이 그 pool 안에서만 active expert를 선택하도록 제한한다.
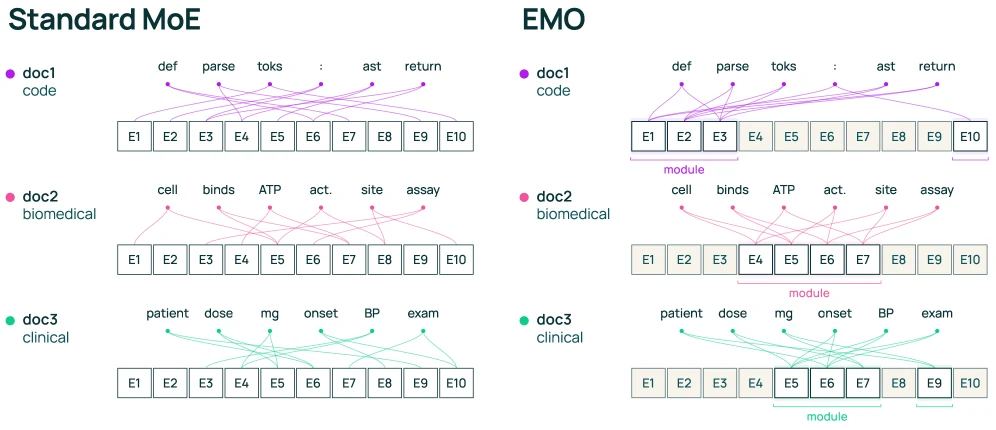
논문식으로 쓰면, 각 토큰의 router 분포를 문서 전체 토큰에 대해 평균낸 뒤 top-d expert를 뽑아 문서 expert pool D를 만든다.
이후 각 토큰의 routing distribution은 D 밖의 expert를 mask한 뒤 다시 normalize된다.
마지막으로 각 토큰은 이 제한된 분포 안에서 top-k expert를 고른다.
이 설계의 중요한 점은 두 가지다.
첫째, 도메인 라벨이 필요 없다.
FlexOlmo나 Branch-train-MiX 계열처럼 사람이 미리 domain partition을 정하고 expert를 배정하는 방식은 명시적이고 이해하기 쉽지만, 라벨링 비용과 human prior의 한계가 있다.
EMO는 문서 경계만 supervision으로 사용한다.
어떤 문서들이 반복적으로 비슷한 expert pool을 쓰게 되면, 그 pool이 자연스럽게 기능 단위로 굳어진다.
둘째, inference-time subset 크기를 하나로 고정하지 않는다.
문서 pool size d를 고정하면 모델이 특정 subset 크기에만 적응해 버릴 수 있다.
EMO는 학습 중 d를 k부터 전체 routed expert 수까지의 범위에서 샘플링한다.
그래서 나중에 8개, 16개, 32개, 64개처럼 다른 expert budget으로 잘라 써도 비교적 유연하게 버틴다.
| 구성 요소 | EMO에서의 역할 | 실무적으로 읽히는 의미 |
|---|---|---|
| Document expert pool | 문서마다 공유 expert 후보군을 먼저 선택 | 토큰 단위 routing을 문서 단위 기능 모듈로 묶음 |
| Pool-constrained routing | 각 토큰은 해당 문서 pool 안에서만 top-k expert 선택 | 같은 문서의 토큰이 일관된 expert subset을 사용 |
| Dynamic pool size | 학습 중 d를 여러 크기로 샘플링 |
다양한 메모리 예산의 subset inference를 지원 |
| Global load balancing | 여러 data-parallel group의 routing 통계를 모아 balance | 문서 내부 일관성과 전체 expert 활용을 동시에 유지 |
| Shared expert | routed expert 외에 항상 활성화되는 공통 expert 1개 사용 | 모든 도메인에 필요한 공통 계산 경로를 보존 |
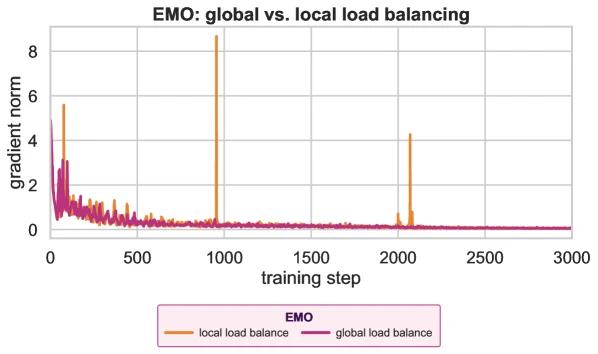
여기서 구현상 핵심은 load balancing이다.
표준 MoE의 local load balancing은 micro-batch 안에서 expert 사용을 고르게 만들려고 한다.
그런데 EMO는 문서 안 토큰들이 같은 pool을 쓰도록 묶고 싶다. micro-batch가 적은 수의 문서로 구성되면, local balancing은 같은 문서의 토큰을 여러 expert로 흩뿌리라는 압력으로 작동해 EMO objective와 충돌한다.
저자들은 이를 global load balancing으로 해결한다. data-parallel group 전체에서 routing 통계를 모아 expert 활용을 맞추면, 한 문서 안에서는 일관된 pool을 유지하면서도 전체 batch 수준에서는 모든 expert가 골고루 쓰이게 할 수 있다.
Figure 7의 gradient norm 비교도 이 선택이 학습 안정성에 중요했음을 보여 준다.
공개된 근거에서 확인되는 점
첫 번째 체크포인트는 full-model 성능이다. modularity를 강제했는데 전체 모델 성능이 떨어지면 실용성이 낮다.
Table 1 기준, EMO는 1T token 학습 설정에서 표준 MoE와 거의 같은 수준의 성능을 낸다.
예를 들어 MMLU는 표준 MoE 42.4, EMO 42.8이고, MMLU-Pro는 표준 MoE 19.3, EMO 18.5다.
GSM8K는 표준 MoE 13.9, EMO 12.0으로 낮지만, 전체적으로는 “modularity objective가 full model을 크게 망가뜨리지는 않는다”는 메시지에 가깝다.
| 모델 | 학습 토큰 | MC9 | Gen5 | MMLU | MMLU-Pro | GSM8K |
|---|---|---|---|---|---|---|
| OLMoE† | 5T | 63.5 | 57.6 | 42.8 | 18.7 | 13.7 |
| Reg. MoE | 1T | 63.9 | 59.7 | 42.4 | 19.3 | 13.9 |
| EMO | 1T | 63.1 | 57.9 | 42.8 | 18.5 | 12.0 |
| Dense | 130B | 54.1 | 41.5 | 33.0 | 12.2 | 2.7 |
| Reg. MoE | 130B | 60.1 | 51.0 | 37.5 | 15.8 | 5.2 |
| EMO | 130B | 59.1 | 49.2 | 38.1 | 15.5 | 4.2 |
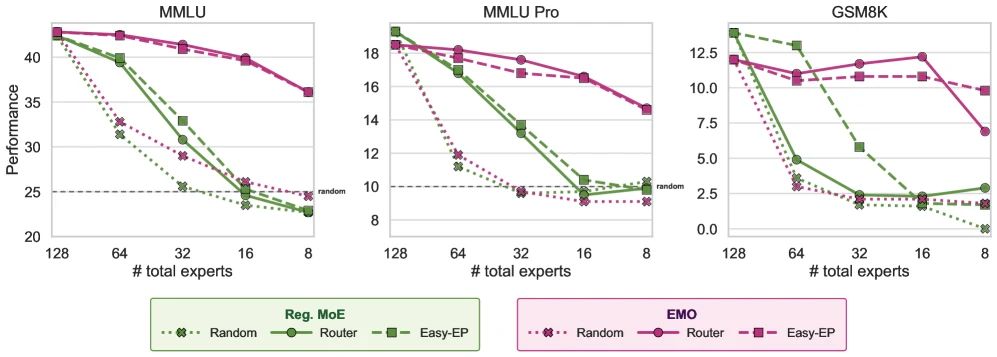
더 중요한 근거는 selective expert use다.
저자들은 MMLU와 MMLU-Pro를 domain group으로 묶고, 작은 validation set에서 expert routing 사용량을 집계해 각 도메인에 맞는 top-d expert를 고른다.
이후 나머지 expert는 버리고 subset 모델처럼 평가한다.
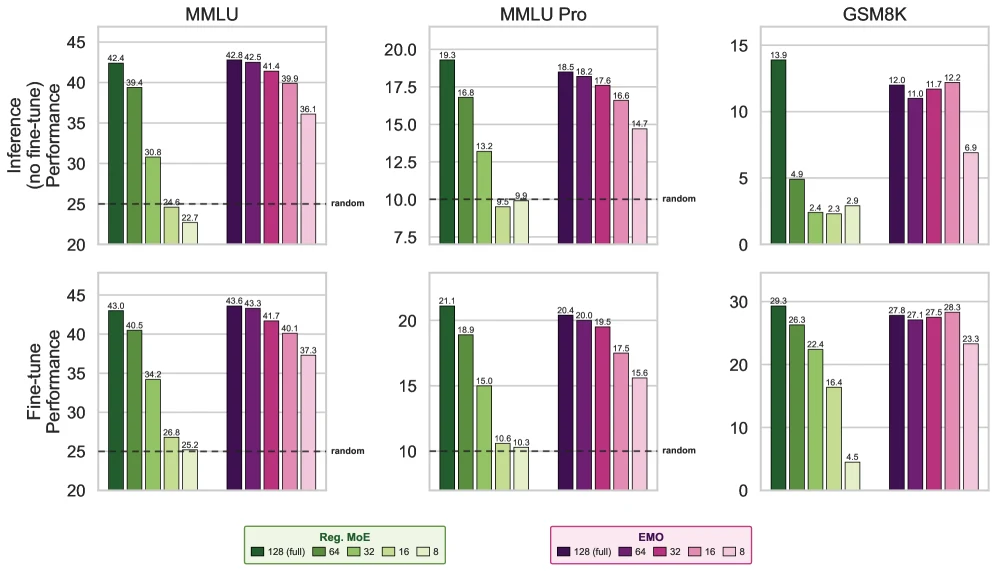
결과는 꽤 선명하다.
표준 MoE는 expert subset을 줄이면 빠르게 random 수준 근처까지 떨어진다.
반면 EMO는 25% expert retention, 즉 32 expert subset에서도 약 1%p drop에 그치고, 12.5% retention, 즉 16 expert subset에서도 약 3%p drop에 머문다고 요약된다. fine-tuning을 붙인 경우에도 비슷한 패턴이 유지되고, GSM8K에서는 12.5% subset이 full-model 성능을 거의 회복하는 구간도 보인다.
여기서 중요한 해석은 “좋은 expert selection 알고리즘만 있으면 표준 MoE도 살릴 수 있다”가 아니라는 점이다.
논문은 router 기반 selection뿐 아니라 Easy-EP 같은 expert pruning 방법도 비교한다.
표준 MoE에서는 Easy-EP가 일부 구간에서 낫지만, subset이 작아질수록 여전히 무너진다.
반면 EMO는 router 기반 selection과 Easy-EP 모두에서 비교적 robust하다.
즉 modularity는 사후 pruning으로 억지로 회수하는 성질이라기보다, 학습 중에 만들어 둬야 하는 성질에 가깝다.
세 번째 근거는 expert specialization 분석이다.
저자들은 1T token 학습 모델에서 12K개 pretraining document의 첫 100 token에 대한 routing behavior를 추출하고, PCA와 spherical k-means로 cluster를 만든다.
그 결과 표준 MoE는 “prepositions”, “proper names”, “copula verbs”, “definite articles”처럼 표면적·문법적 cluster를 많이 만든다.
EMO는 “Health, Medical & Wellness”, “News Reporting”, “US Politics & Elections”, “Film, Music, TV & Book Reviews”처럼 훨씬 semantic한 cluster를 만든다.

이 그림이 중요한 이유는 selective expert use의 원인을 설명하기 때문이다. expert subset이 수학이나 의학 같은 실제 도메인과 대응되려면, routing pattern 자체가 그 도메인을 반영해야 한다.
표준 MoE처럼 관사와 전치사 중심으로 나뉘면, 어떤 도메인 문서든 여러 문법 cluster를 지나가게 된다.
반대로 EMO처럼 문서 단위 domain routing이 생기면, 작은 expert subset이 하나의 기능 단위처럼 작동할 여지가 생긴다.
공개 아티팩트도 꽤 풍부하다.
Ai2는 논문, 공식 블로그, Hugging Face 모델 컬렉션, GitHub 코드, interactive visualization을 함께 공개했다.
GitHub 저장소 allenai/EMO는 Apache 2.0 라이선스 파일과 training/evaluation script를 포함하고, README에는 allenai/Emo_1b14b_1T, allenai/StdMoE_1b14b_1T, 130B-token ablation 모델, EMO-annealed baseline 등이 정리되어 있다.
Hugging Face API 기준 allenai/EMO index/model entry도 공개되어 있고 custom transformers code, safetensors shard, arxiv:2605.06663 tag를 포함한다.
다만 재현성은 완전히 “클릭 한 번” 단계라고 보긴 어렵다.
README는 pretraining script가 OLMoE와 같은 공개 data mixture를 사용한다고 밝히지만, 현재 script는 내부에 호스팅된 tokenized version을 읽고, 해당 데이터 endpoint는 추후 공개 예정이라고 적는다.
따라서 모델과 코드 공개는 분명 실질적이지만, 1T token pretraining을 외부 팀이 즉시 동일하게 재현하는 패키지라기보다는 연구 release + 공개 checkpoint 조합으로 읽는 편이 안전하다.
실무 관점에서의 해석
내가 보기에 EMO의 가장 중요한 의미는 MoE의 효율성을 “토큰당 active FLOPs”에서 “배포 가능한 기능 단위”로 확장했다는 데 있다.
기존 MoE는 계산은 sparse하지만 메모리와 운영은 여전히 전체 모델 중심이었다.
EMO가 보여 주려는 것은, sparse model이 정말로 modular해지면 특정 도메인 workload에 맞춰 일부 expert만 로드하는 serving이 가능해질 수 있다는 점이다.
이건 특히 큰 sparse model이 더 커질수록 중요해진다.
DeepSeek-V3, Qwen3 계열처럼 expert 수가 많아질수록 inactive expert weight를 어떻게 메모리에 유지할지가 시스템 병목이 된다.
EMO식 modular pretraining이 더 큰 모델에서도 통한다면, “모든 요청에 전체 expert bank를 준비한다”는 기본 가정을 줄이고, 도메인·사용자·애플리케이션별 expert subset을 동적으로 구성하는 방향이 열릴 수 있다.
또 하나 흥미로운 점은 interpretability와 control이다.
EMO는 expert cluster가 semantic domain에 가까워진다고 주장한다.
이것이 충분히 안정적이라면, 모델 개발자는 어떤 입력이 어떤 expert group을 쓰는지 더 의미 있게 감시할 수 있다.
논문도 child-facing app에서 특정 risky cluster를 비활성화하거나, biomedical 같은 민감 도메인 expert를 조건부로 노출하는 가능성을 언급한다.
물론 이것을 곧바로 안전장치로 쓰기에는 아직 이르지만, 적어도 MoE routing을 debugging signal로 쓰는 길은 더 선명해진다.
한계도 분명하다.
첫째, EMO의 핵심 성과는 같은 architecture의 표준 MoE와 비교한 연구 설정에서 나온다.
실제 초대형 production MoE에서 문서 단위 routing constraint가 throughput, expert parallelism, cache locality, serving scheduler와 어떻게 상호작용할지는 별도 검증이 필요하다.
둘째, selective expert use는 작은 validation/calibration set으로 expert를 고르는 절차를 전제로 한다.
도메인이 자주 바뀌거나 multi-domain query가 많은 애플리케이션에서는 subset 선택 자체가 또 하나의 routing problem이 된다.
셋째, semantic modularity는 좋은 일만은 아닐 수 있다.
특정 domain capability가 더 잘 분리되면 효율적 배포와 해석에는 유리하지만, 그 capability를 누가 언제 활성화할지 통제하는 문제도 함께 커진다.
예를 들어 biomedical, cybersecurity, persuasion 같은 domain expert가 명확해질수록 access control과 policy layer도 더 중요해진다.
그럼에도 EMO는 MoE 연구에서 꽤 좋은 질문을 던진다. expert는 단지 sparse computation unit인가, 아니면 나중에 잘라 쓰고 다시 조립할 수 있는 model module인가?
지금까지 많은 MoE는 전자에 가까웠다.
EMO는 후자를 pretraining objective 차원에서 만들 수 있다는 가능성을 보여 준다.
이 방향이 더 큰 스케일과 실제 serving system까지 이어진다면, 미래의 sparse LLM은 “거대한 하나의 모델”이라기보다 상황에 따라 expert subset을 고르고 조립하는 modular model family에 가까워질 수 있다.