툴 호출 에이전트의 실패는 대개 실행된 뒤에야 드러난다.
잘못된 API를 불렀거나, 존재하지 않는 파라미터를 넣었거나, 아무 도구도 쓰면 안 되는 요청에서 억지로 도구를 고른 뒤에는 이미 상태가 바뀌었을 수 있다.
알람 삭제, 주문 변경, 계정 설정 수정처럼 외부 상태를 건드리는 작업이라면 “나중에 반성해서 고치기”가 생각보다 비싸다.
Reinforced Agent: Inference-Time Feedback for Tool-Calling Agents는 이 문제를 사후 평가가 아니라 실행 전 검토로 옮긴다.
기본 에이전트가 툴 호출을 바로 실행하지 않고 먼저 provisional call을 만들면, 별도의 reviewer agent가 그 호출을 보고 “실행해도 되는가, 수정해야 하는가”를 판단한다.
핵심은 모델을 다시 학습시키는 것이 아니라, 기존 tool-calling pipeline 앞에 작은 리뷰 루프를 붙이는 것이다.
논문이 흥미로운 이유는 단순히 “검토자를 붙이면 좋아진다”에서 끝나지 않는다는 점이다. reviewer는 오류를 잡을 수도 있지만, 원래 맞았던 호출을 괜히 깨뜨릴 수도 있다.
이 논문은 그 양면을 Helpfulness와 Harmfulness라는 지표로 분리해 측정한다.
에이전트 안전장치를 논할 때 자주 빠지는 “방어막 자체의 부작용”을 정면으로 수치화한 셈이다.

무엇을 해결하려는가
기존 툴 호출 평가는 대부분 post-hoc이다.
BFCL 같은 벤치마크는 툴 선택과 파라미터 정확도를 잘 측정하지만, 그 평가는 실행 루프 바깥에서 이뤄진다.
오류를 발견한 뒤에는 프롬프트를 고치거나 모델을 다시 학습시키는 식으로 다음 실행을 개선할 수는 있어도, 지금 막 잘못 실행되려는 호출을 막지는 못한다.
Self-Refine이나 Reflexion 계열 접근도 비슷한 한계를 가진다.
모델이 스스로 반성하고 수정하도록 만들 수는 있지만, 툴 호출이 이미 실행된 뒤라면 복구해야 할 상태가 생긴다.
논문은 이를 state recovery problem으로 설명한다.
복잡한 멀티턴 환경에서는 이전 상태, 가능한 대안 trajectory, 외부 시스템의 부작용을 모두 context에 유지해야 하는데, 이는 비용과 신뢰성 측면에서 빠르게 어려워진다.
Reinforced Agent가 노리는 병목은 바로 이 지점이다.
에이전트가 외부 세계를 바꾸기 전에 잠시 멈추고, 별도 reviewer가 provisional call을 검사하게 하자는 것이다.
이는 사람 조직에서 중요한 작업을 merge하기 전에 코드 리뷰를 붙이는 방식과 닮았다.
리뷰어는 완벽하지 않지만, 리뷰어의 품질을 따로 측정하고 개선할 수 있다면 전체 시스템의 안정성을 점진적으로 높일 수 있다.
핵심 아이디어 / 구조 / 동작 방식
논문은 base tool-calling agent와 reviewer agent를 분리한다.
실험에서 base agent는 GPT-4o이고, reviewer로는 GPT-4o, o3-mini, GPT-5 mini 계열을 비교한다.
중요한 점은 base agent의 가중치나 구조를 바꾸지 않는다는 것이다. reviewer의 모델, 프롬프트, 리뷰 방식만 독립적으로 바꿔가며 개선할 수 있다.
리뷰 메커니즘은 세 가지로 나뉜다.
| 메커니즘 | 동작 방식 | 논문 내 표기 | 해석 |
|---|---|---|---|
| Progressive Feedback | reviewer가 provisional call을 보고 오류가 있으면 피드백을 주고, base agent가 다시 호출을 만든다 | rN |
가장 “코드 리뷰”에 가까운 반복 수정 루프 |
| Best-of-N Selection | base agent가 여러 후보를 만들고 reviewer가 하나를 고른다 | sN |
sampling 후보 중 선택하는 selector 방식 |
| Best-of-N Grading | reviewer가 후보마다 점수와 근거를 매기고 최고점을 고른다 | gN |
selection보다 명시적인 rubric 평가 방식 |
이 중 가장 강한 신호를 보인 것은 Progressive Feedback이다.
특히 “아무 도구도 쓰면 안 되는 요청”을 걸러내는 irrelevance detection과, 상태·정책 제약이 걸린 멀티턴 환경에서 효과가 컸다.
반면 Best-of-N 방식은 후보 다양성을 활용할 수 있지만, reviewer가 잘못된 기준으로 고르면 오히려 baseline보다 나빠질 수 있다.
논문이 별도로 강조하는 지표는 다음 세 가지다.
| 지표 | 의미 | 왜 중요한가 |
|---|---|---|
| Helpfulness | base agent가 틀렸고 reviewer가 이를 고친 비율 | 방어막이 실제 오류를 얼마나 줄이는지 보여준다 |
| Harmfulness | base agent가 맞았는데 reviewer가 오류를 만든 비율 | 방어막 자체의 부작용을 드러낸다 |
| Benefit-to-Risk Ratio | Helpfulness ÷ Harmfulness | reviewer를 붙일 가치가 있는지 판단하는 요약 지표 |
이 지표 설계가 이 논문의 가장 실무적인 부분이다.
에이전트 안전장치는 “오류를 얼마나 잡는가”만으로 평가하면 안 된다.
승인해야 할 정상 호출을 과도하게 막거나, 불필요한 수정을 유도하거나, user-facing 답변을 기대하면서 tool-only call을 틀렸다고 판단하면 전체 성공률이 떨어진다.
논문은 실제로 이런 over-skepticism을 주요 실패 모드로 관찰한다.
공개된 근거에서 확인되는 점
BFCL Non-Live 결과에서 초기 reviewer 설정 4o-r5-4o-v1은 irrelevance 점수를 84.9%에서 89.6%로 올렸다. relevance suite 평균은 90.9%에서 91.4%로 작게 개선됐다.
즉 단순 함수 호출 정확도 전체를 크게 끌어올린다기보다, “도구를 쓰면 안 되는 요청을 걸러내는 능력”에서 강한 이득이 먼저 나타난다.
그 다음 논문은 reviewer 모델과 프롬프트를 더 세밀하게 비교한다.
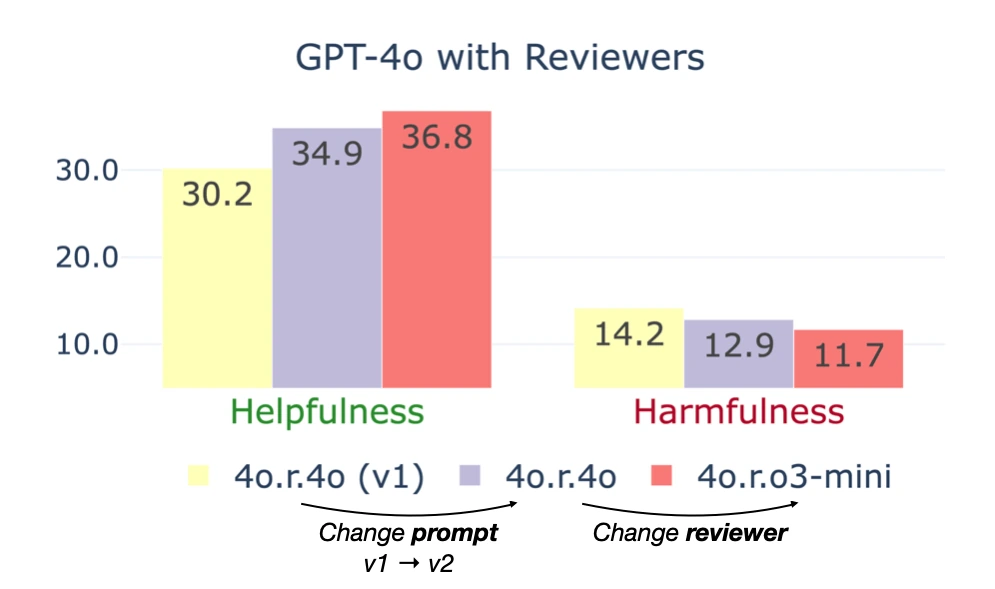
GPT-4o reviewer v1은 Helpfulness 30.2%, Harmfulness 14.2%로 2.1:1 ratio를 보인다.
프롬프트를 v2로 다듬으면 34.9% / 12.9%, 2.7:1로 좋아진다. o3-mini reviewer v2는 36.8% / 11.7%, 3.1:1까지 올라간다.
즉 reasoning model이 reviewer로 들어갈 때 “더 많이 고치고, 덜 망가뜨리는” 방향의 개선이 관찰된다.
GEPA 기반 자동 프롬프트 최적화도 작은 폭이지만 의미 있는 개선을 만든다.
BFCL Non-Live에서 4o-r2-5-mini-v2는 relevance 91.0%, irrelevance 87.6%였고, GEPA-optimized v3-gepa는 relevance 92.5%, irrelevance 90.4%를 기록했다.
논문은 이를 각각 +1.5%, +2.8% 개선으로 보고한다. baseline GPT-4o와 비교하면 irrelevance는 84.9%에서 90.4%로 +5.5%, relevance suite는 90.9%에서 92.5%로 +1.6%다.
멀티턴 쪽에서는 τ²-Bench 결과가 중요하다.
GPT-4o baseline 평균은 48.7%이고, Progressive Feedback 4o-r5-4o-v1은 평균 55.8%를 기록한다. +7.1%p 개선이다.
다만 domain별로 보면 균일한 개선은 아니다.
Airline은 42.0%에서 40.7%로 조금 내려가고, Retail도 62.9%에서 62.6%로 거의 같거나 약간 낮다.
큰 개선은 Telecom에서 41.2%에서 64.0%로 나타난다.
이 결과는 reviewer가 모든 도메인을 보편적으로 개선한다기보다, 특정 정책·상태 제약이 강한 영역에서 특히 잘 작동할 수 있음을 시사한다.
| 실험 축 | baseline | best reported reviewer setting | 변화 | 해석 |
|---|---|---|---|---|
| BFCL irrelevance | 84.9% | 90.4% | +5.5%p | 도구를 쓰면 안 되는 요청 판별에서 큰 개선 |
| BFCL relevance suite | 90.9% | 92.5% | +1.6%p | 일반 함수 호출 정확도는 완만한 개선 |
| τ²-Bench average | 48.7% | 55.8% | +7.1%p | 멀티턴 상태·정책 제약에서 유의미한 개선 |
| o3-mini reviewer ratio | - | 3.1:1 | - | reviewer가 오류를 고치는 효과가 새 오류보다 약 3배 큼 |
오류 분석도 실무적으로 유용하다. τ²-Bench에서 reviewer는 policy constraint violation을 31%에서 18%로 줄이고, missing context awareness를 24%에서 15%로 줄였다.
반면 incorrect tool selection은 19%에서 22%, argument errors는 16%에서 18%로 조금 늘었고, over-verbalization은 10%에서 27%로 크게 늘었다. reviewer가 정책 위반은 잘 잡지만, “더 설명해야 한다”거나 “이 호출만으로는 불충분하다”고 과잉 판단하는 문제가 남는다는 뜻이다.
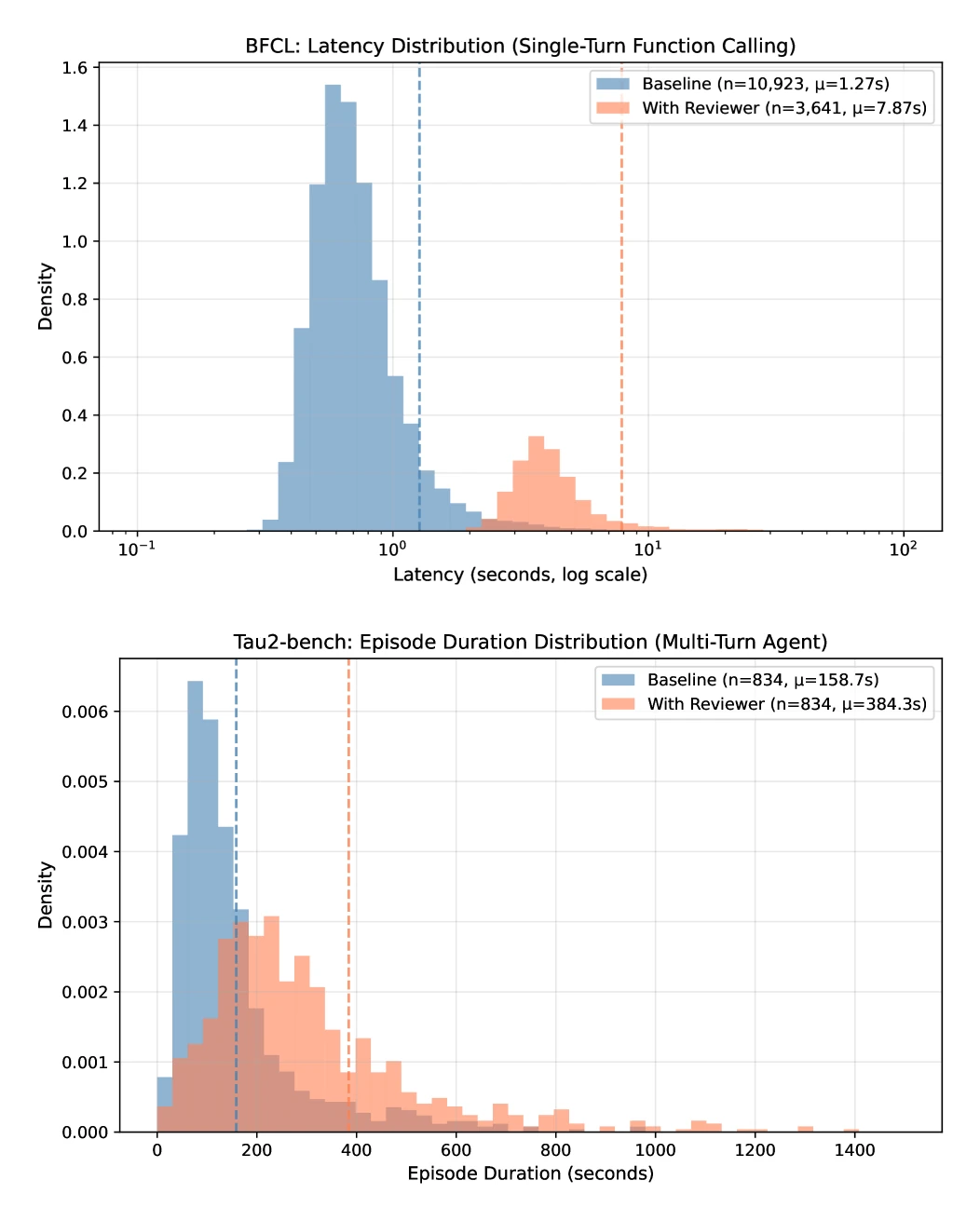
지연 시간 비용은 꽤 크다.
BFCL 단일 턴에서는 평균 latency가 1.27초에서 7.87초로 늘어 6.2배가 된다. τ²-Bench 멀티턴 episode에서는 158.7초에서 384.3초로 늘어 2.4배다.
절대 시간으로는 여전히 크지만, 멀티턴에서는 reviewer overhead가 여러 턴에 분산되기 때문에 상대 배율은 낮아진다.
공개 표면만 보면 이 논문은 현재 arXiv HTML/PDF 중심의 연구 발표에 가깝다. arXiv abs와 HTML에서 별도 공식 GitHub repository나 project page 링크는 확인되지 않았다.
따라서 공개 구현이나 재현 패키지가 이미 성숙하게 배포됐다고 보기는 어렵고, 현재로서는 논문 안의 실험 설계와 수치가 주요 근거다.
실무 관점에서의 해석
내가 보기에 Reinforced Agent의 핵심 가치는 “에이전트에게 또 다른 에이전트를 붙인다”는 표면적 아이디어보다, tool execution boundary를 명확한 검토 지점으로 만든다는 데 있다.
지금 많은 agent framework는 tool call을 모델 출력의 자연스러운 일부로 처리한다.
하지만 외부 상태를 바꾸는 tool call은 사실상 작은 transaction이다.
실행 전에 별도 정책·인자·상태 precondition 검사를 거치는 것이 더 자연스럽다.
이 접근은 특히 세 종류의 워크플로우에 잘 맞는다.
첫째, API 비용이나 부작용이 큰 작업이다.
잘못된 호출 한 번이 결제, 예약, 삭제, 권한 변경으로 이어질 수 있다면 reviewer overhead는 충분히 정당화될 수 있다.
둘째, 멀티턴 업무처럼 상태와 정책 제약이 누적되는 환경이다. τ²-Bench에서 policy violation과 context awareness 오류가 줄어든 것은 이 방향의 가능성을 보여준다.
셋째, 기존 base agent를 재학습하기 어려운 조직이다. reviewer만 교체하거나 prompt optimization을 돌릴 수 있다면 운영 부담이 낮다.
반대로 고속 단일 턴 서비스에는 바로 넣기 어렵다.
BFCL에서 6.2배 latency 증가는 실시간 대량 호출 서비스에는 부담이 크다.
이런 경우에는 모든 호출을 reviewer에 태우기보다, base agent confidence가 낮거나, destructive tool이거나, irrelevance 가능성이 높은 케이스만 선택적으로 리뷰하는 방식이 더 현실적이다.
또 하나 중요한 해석은 reviewer prompt의 역할이다.
논문은 reviewer가 tool-only response를 “사용자에게 답하지 않았다”고 오해하는 문제를 발견했고, 이를 critical guideline으로 줄였다.
이건 agent safety layer가 단순히 더 강한 모델을 붙인다고 해결되지 않는다는 뜻이다. reviewer는 실행 환경의 평가 기준을 정확히 알아야 한다.
BFCL처럼 tool call만 평가하는 환경과 τ²-Bench처럼 대화 맥락과 정책을 보는 환경은 다른 reviewer policy가 필요하다.
GEPA를 reviewer prompt에 적용한 부분도 흥미롭다.
여기서는 base agent를 개선하는 것이 아니라, 검토자의 판단 정책을 최적화한다.
이는 앞으로 agent runtime에서 꽤 중요한 패턴이 될 수 있다.
실행 agent, reviewer, selector, grader, policy checker가 분리되면 각 컴포넌트의 prompt와 model choice를 독립적으로 평가하고 최적화할 수 있다. agent system의 개선 단위가 “하나의 거대한 프롬프트”에서 “역할별 판단 모듈”로 쪼개지는 셈이다.
한계와 남은 질문
논문의 한계도 분명하다. base tool-calling agent는 GPT-4o 하나에 집중되어 있고, open-source model이나 더 작은 proprietary model에서 같은 패턴이 유지되는지는 아직 검증되지 않았다. reviewer 비교도 BFCL 중심이며, Helpfulness-Harmfulness와 GEPA 최적화 역시 주로 BFCL에서 체계적으로 분석됐다. τ²-Bench에서는 멀티턴 전파 오류와 partial credit을 다루는 문제가 더 복잡하기 때문에 같은 지표를 그대로 확장하기 어렵다.
또한 latency 문제는 단순한 부록 이슈가 아니다. reviewer agent는 정확도를 올리는 동시에 비용과 지연 시간을 늘린다.
논문은 distillation을 통해 작은 reward model이나 classifier로 줄일 수 있다고 제안하지만, 그 단계까지 공개 검증된 것은 아니다.
실제 제품에서는 reviewer를 언제 호출할지, 어떤 tool class에만 적용할지, 실패 시 사람 승인으로 넘길지 같은 routing policy가 성능만큼 중요해질 것이다.
그럼에도 방향은 꽤 실용적이다.
에이전트가 외부 도구를 더 많이 다룰수록, “모델이 다음 토큰을 잘 맞히는가”보다 “실행해도 되는 행동인지 누가 언제 판단하는가”가 더 중요해진다.
Reinforced Agent는 그 판단을 사후 로그 분석이 아니라 inference-time control loop로 끌어온다.
완성된 제품이라기보다는, 툴 호출 에이전트에 필요한 pre-execution review layer를 어떻게 측정하고 개선할지 보여주는 좋은 기준선에 가깝다.