Claude Code, Codex, OpenCode 같은 코딩 에이전트 하네스는 세션을 관리하고, 도구를 호출하고, 코드를 수정하고, 개발자의 의도를 실행하는 데 강하다.
하지만 기업형 딥리서치로 들어가면 문제가 달라진다.
내부 문서, 정책, 데이터베이스, 웹 검색, 인증, 출처 추적, 장기 job 관리, 평가까지 한꺼번에 붙어야 한다.
이 복잡도를 매번 하네스 안에서 다시 구현하면, 범용 에이전트는 금방 “리서치 백엔드”까지 떠안게 된다.
NVIDIA Technical Blog의 **“Add a Specialized Deep Research Skill to Agent Harnesses”**는 이 경계를 분리하는 방법으로 AI-Q agent skill을 제시한다.
핵심은 간단하다.
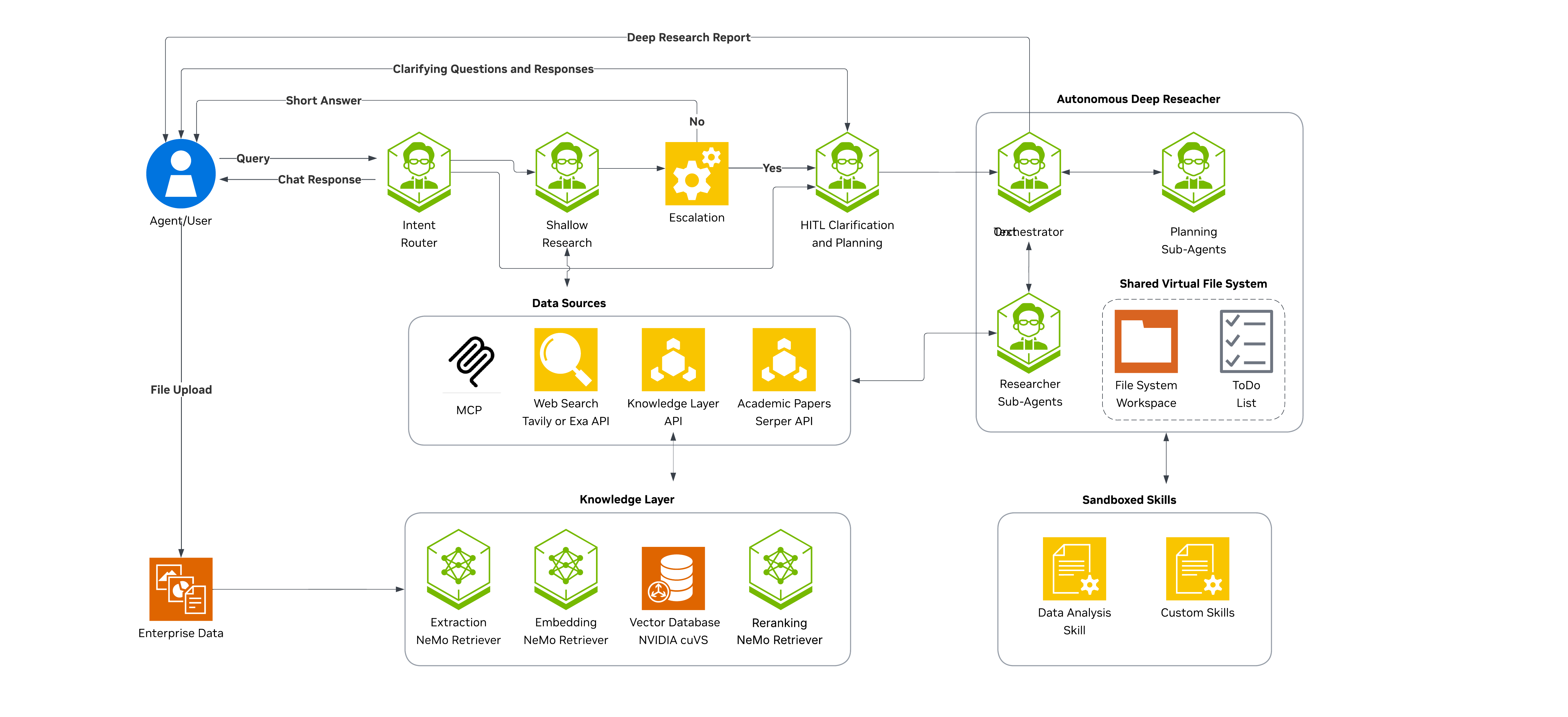
하네스는 사용자 의도와 작업 흐름을 잡고, 실제 딥리서치 파이프라인은 로컬 또는 사내망에 배포된 NVIDIA AI-Q Blueprint 서버가 처리한다.
하네스 입장에서는 SKILL.md와 scripts/aiq.py가 들어 있는 하나의 agent skill을 설치하면 되고, AI-Q 서버는 intent classification, clarification, shallow/deep research, MCP 데이터 소스, citation-backed report를 담당한다.

이 글이 흥미로운 이유는 “AI가 리서치를 더 잘한다”가 아니라, 딥리서치를 어디에 배치할 것인가를 제품 아키텍처 문제로 다룬다는 점이다.
앞으로 기업형 에이전트 시스템에서는 모델 성능만큼이나, 어떤 기능을 하네스 내부에 둘지, 어떤 기능을 별도 governed backend로 분리할지가 중요해진다.
AI-Q skill은 무엇인가
공식 글과 NVIDIA-AI-Blueprints/aiq v2.1.0 저장소를 함께 보면 AI-Q skill의 정체는 “검색 도구 하나”가 아니다.
더 정확히는 에이전트 하네스가 AI-Q 서버의 리서치 API를 안전하게 호출하게 하는 어댑터 패키지다.
저장소의 canonical 위치는 다음과 같다.
.agents/skills/aiq-research/
├── SKILL.md
└── scripts/aiq.py
SKILL.md는 하네스에게 언제 AI-Q를 호출해야 하는지 설명한다. scripts/aiq.py는 실제로 로컬 AI-Q 서버에 요청을 보내고, 비동기 딥리서치 job을 제출하고, 상태를 polling하고, 최종 report를 가져오는 helper다.
기본 서버 주소는 http://localhost:8000이고, 다른 배포를 쓰는 경우 AIQ_SERVER_URL로 바꿀 수 있다.
공식 skill metadata는 Claude Code, OpenCode, Codex 및 Agent Skills-compatible tools를 호환 대상으로 둔다.
설치 방식은 하네스마다 조금씩 다르다.
| 하네스 | skill 설치 형태 | 의미 |
|---|---|---|
| Claude Code | repo-local .claude/skills/aiq-research 또는 user-level ~/.claude/skills/aiq-research |
저장소 단위 또는 사용자 단위로 AI-Q 호출 능력을 추가 |
| Codex | 런타임이 설정한 skills directory 아래 aiq-research/SKILL.md |
Codex 환경의 skill loader에 맞춰 복사 |
| OpenCode | ~/.config/opencode/skills/aiq-research |
user skill로 설치 후 새 세션에서 로드 |
중요한 점은 skill을 설치한다고 AI-Q가 자동으로 생기는 것이 아니라는 점이다. skill은 “호출 인터페이스”이고, 별도로 실행 중인 AI-Q Blueprint 서버가 필요하다.
이 서버는 개발자 노트북에서 Docker Compose로 띄울 수도 있고, 온프레미스 또는 클라우드 Kubernetes에 Helm chart로 배포할 수도 있다.

왜 하네스 안에서 직접 리서치하지 않는가
범용 에이전트도 웹 검색, 파일 읽기, RAG 호출, 요약을 조합하면 리서치처럼 보이는 결과를 만들 수 있다.
하지만 기업형 딥리서치는 “몇 번 검색해서 요약하기”와 다르다.
NVIDIA가 AI-Q skill을 강조하는 이유는 이 차이에 있다.
딥리서치 파이프라인에는 적어도 다음 요소가 필요하다.
| 요소 | 하네스 내부 구현의 문제 | AI-Q 분리의 효과 |
|---|---|---|
| 데이터 접근 | 하네스가 내부 문서·정책·DB 권한까지 직접 가져야 함 | 데이터가 있는 환경 안에서 AI-Q가 retrieval/synthesis 수행 |
| 장기 실행 | 긴 리서치 작업의 상태, 재연결, 취소, event replay를 직접 관리해야 함 | /v1/jobs/async 기반 job lifecycle로 분리 |
| 출처 추적 | 검색 hit와 최종 문장 사이의 provenance가 흐려지기 쉬움 | citation-backed report와 verification pipeline 중심으로 설계 |
| 평가와 튜닝 | 프롬프트와 도구 조합이 하네스별로 흩어짐 | FreshQA, Deep Research Bench 등 평가 harness를 blueprint에 포함 |
| 보안 경계 | 범용 에이전트가 raw source에 넓게 접근할 위험 | 하네스는 cited output을 받고, raw data access는 AI-Q 배포 경계 안에 유지 |
즉 AI-Q skill의 메시지는 “하네스가 리서치를 못 한다”가 아니라, 리서치의 복잡도를 하네스의 책임으로 두면 운영하기 어렵다는 것이다.
하네스는 orchestration shell이고, AI-Q는 research runtime이다.
이 둘을 skill이라는 얇은 인터페이스로 연결하면 각자의 책임이 더 명확해진다.
AI-Q 내부 파이프라인: 빠른 답과 장기 리포트를 분기한다
AI-Q v2.1.0 README와 architecture 문서는 이 Blueprint를 NeMo Agent Toolkit 기반의 enterprise-grade research agent로 설명한다.
내부적으로는 LangGraph state machine을 사용하고, 요청은 intent classifier를 통과해 meta response, shallow research, deep research 중 하나로 라우팅된다.
핵심 구성 요소는 다음과 같다.
| 구성 요소 | 역할 |
|---|---|
| Intent Classifier | 사용자 요청이 일반 대화인지, 리서치인지, 리서치라면 shallow/deep 중 어느 쪽인지 판정 |
| Shallow Researcher | 빠르고 bounded된 tool-augmented research로 citation-backed answer 생성 |
| Clarifier | deep research 전에 계획을 만들고 ambiguity를 사람에게 확인하는 HITL 단계 |
| Deep Researcher | planner와 researcher subagent를 사용해 장기 multi-phase report 작성 |
| Data Source Registry | web, paper, enterprise, collaboration, knowledge-layer source를 request 단위로 선택 |
| Async Job API | submit, stream, state, report, cancel 등 긴 작업의 lifecycle 관리 |
이 구조의 장점은 “모든 질문을 딥리서치로 보내지 않는다”는 점이다.
간단한 요청은 shallow path로 빠르게 처리하고, 긴 분석이 필요한 요청만 clarification과 deep research로 보낸다.
공식 architecture 문서는 shallow 결과가 부족할 때 escalation keyword와 empty response 등을 보고 clarifier로 올리는 경로도 설명한다.
즉 AI-Q는 하나의 거대한 agent가 아니라, 리서치 깊이를 조절하는 state machine에 가깝다.
MCP 통합이 중요한 이유
이번 NVIDIA 글에서 agent skill만큼 중요한 축은 MCP다.
기업 데이터는 보통 한 곳에 있지 않다.
문서 저장소, CRM, 정책 시스템, 금융 데이터, 내부 검색 API, 협업 도구가 따로 움직인다.
AI-Q가 딥리서치 백엔드가 되려면 이 데이터 소스들을 새 RAG stack으로 다시 복사하는 대신, 기존 도구와 권한 경계에 붙어야 한다.
AI-Q 2.1 문서는 MCP 서버를 NeMo Agent Toolkit의 function group으로 붙이는 세 가지 패턴을 정리한다.
| 시나리오 | AI-Q 패턴 | 해석 |
|---|---|---|
| MCP 서버에 사용자별 인증이 없음 | mcp_client function group |
가장 단순한 tool discovery/registration |
| MCP 서버가 backend/app credential을 사용 | mcp_client + mcp_service_account |
CI, batch job, 공유 enterprise data source에 적합 |
| downstream API가 AI-Q 사용자 bearer token을 신뢰 | custom AI-Q tool에서 get_auth_token() 사용 |
job submit 시점의 사용자 identity를 async worker 안으로 전달 |
운영 관점에서 특히 중요한 것은 streamable-http 권장이다.
공식 문서는 새 배포와 보호된 MCP 서버에는 streamable-http를 쓰고, production auth scenario에서는 legacy sse를 피하라고 설명한다.
또한 AI-Q 2.1에서 native per-user MCP OAuth는 아직 UI가 직접 consent flow를 구동하는 단계가 아니며, AI-Q 2.2/2.3 계획으로 분리되어 있다.
지금 당장 per-user identity를 넘겨야 한다면 custom tool 또는 custom auth provider를 설계해야 한다.
이 지점은 실무 도입에서 중요하다.
“MCP를 붙일 수 있다”와 “기존 기업 권한 모델을 안전하게 보존한다”는 같은 말이 아니다.
AI-Q는 서비스 계정, 사용자 토큰 전달, 데이터 소스 registry, requires_auth flag 같은 조각을 제공하지만, 최종 trust boundary와 token lifecycle은 배포자가 설계해야 한다.
보안과 운영에서 봐야 할 점
AI-Q skill은 하네스에게 편리한 deep research capability를 주지만, 운영자가 주의해야 할 면도 명확하다.
첫째, local development에서는 auth가 꺼진 구성이 기본일 수 있다.
공식 authentication 문서는 production에서 OAuth/OIDC provider, backend JWT validator, REQUIRE_AUTH=true, external hostname 설정을 함께 구성하라고 설명한다.
인증 없는 AI-Q API를 외부에 노출하면 모델 사용 비용, 내부 데이터 접근, resource exhaustion 문제가 동시에 생길 수 있다.
둘째, async deep research는 장기 job이다.
공식 글은 signed-in AI-Q user의 bearer token이 job-submit 시점에 캡처되어 Dask worker 안에서 복원된다고 설명한다.
하지만 token이 job 중간에 refresh되는 구조는 아직 계획 단계이므로, access token TTL보다 오래 걸리는 job은 auth-required tool call에서 실패할 수 있다.
긴 리서치 job과 enterprise auth를 붙일 때 반드시 확인해야 할 지점이다.
셋째, 로그와 trace에는 민감한 정보가 들어갈 수 있다.
AI-Q README의 security considerations는 middleware, backend, demo app 로그가 개발 목적으로 prompt와 completion을 stdout에 출력할 수 있다고 경고한다.
딥리서치 시스템은 출처와 reasoning trace를 잘 남겨야 하지만, 그 자체가 새로운 민감 데이터 저장소가 될 수 있다. tracing, redaction, retention policy를 같이 설계해야 한다.
넷째, AI-Q는 reference blueprint다.
GitHub 저장소는 Apache-2.0으로 공개되어 있고 v2.1.0 release가 올라와 있지만, 공식 README도 production security review, container patching, access control, monitoring을 배포자 책임으로 둔다.
즉 “바로 붙이면 enterprise-ready”라기보다는, 기업이 자신들의 trust boundary 안에 배포하고 검증할 수 있는 starting point로 읽는 편이 맞다.
데모가 보여주는 사용감
공식 블로그는 Codex agent가 여러 데이터 소스에 걸친 research task를 AI-Q skill로 위임하는 영상을 함께 제공한다.
영상의 포인트는 하네스가 직접 검색 루프를 전부 수행하지 않는다는 점이다.
하네스는 skill을 통해 AI-Q에 작업을 넘기고, AI-Q는 async job으로 리서치를 진행한 뒤 structured report를 돌려준다.
이 사용감은 이전에 다룬 agent skill 논의와도 연결된다.
SkillsVote나 MMSkills가 “어떤 스킬을 어떻게 추천하고 표현할 것인가”를 다뤘다면, AI-Q skill은 특정 고부가가치 capability를 별도 서버형 skill로 빼는 패턴을 보여준다.
모든 스킬이 local Markdown 절차일 필요는 없다.
어떤 스킬은 작은 helper script를 가진 원격 또는 사내 capability adapter가 될 수 있다.
실무적으로 가져갈 설계 원칙
이 NVIDIA 글에서 바로 가져갈 만한 원칙은 네 가지다.
-
하네스와 전문 런타임의 경계를 나눈다.
Claude Code나 Codex가 모든 도메인 워크플로를 직접 소유하게 하지 말고, 장기 리서치·규제 문서 분석·감사 가능한 synthesis처럼 무거운 capability는 별도 backend로 분리한다. -
Skill은 단순 prompt가 아니라 capability contract가 될 수 있다.
AI-Q의SKILL.md는 하네스용 사용 설명이고,scripts/aiq.py는 API lifecycle을 감싼다.
즉 skill bundle은 절차 문서, helper script, API contract를 함께 담는 작은 integration package다. -
데이터는 하네스가 아니라 governed environment 안에 둔다.
하네스가 raw enterprise data를 직접 훑는 대신, AI-Q가 데이터가 있는 환경에서 retrieval과 synthesis를 수행하고 cited report만 반환하게 할 수 있다.
규제 산업에서는 이 차이가 크다. -
MCP integration은 권한 설계와 함께 봐야 한다.
MCP server를 붙이는 것은 시작일 뿐이다. service-account, user token pass-through, per-user OAuth 계획, token TTL, data source registry, audit trace까지 같이 설계해야 한다.
한계와 다음 질문
AI-Q agent skill은 좋은 방향을 제시하지만, 모든 팀에 바로 맞는 해법은 아니다.
AI-Q 서버를 별도로 운영해야 하고, NVIDIA API key, Tavily/Serper 같은 검색 API, optional knowledge layer, Docker Compose 또는 Helm 배포가 필요하다. self-hosted Nemotron/NIM까지 고려하면 인프라 복잡도는 더 올라간다.
또 하나의 질문은 하네스별 skill 표준의 차이다.
Claude Code, Codex, OpenCode가 모두 skill-like mechanism을 갖고 있지만, directory layout, allowed tools, helper script 실행 방식, permissions model은 다를 수 있다.
AI-Q가 .agents/skills/aiq-research를 canonical path로 두고 .claude/skills symlink를 제공하는 것은 이런 portability 문제를 의식한 설계로 보인다.
하지만 장기적으로는 agent skill package format과 capability discovery가 더 표준화되어야 한다.
마지막으로, 딥리서치 quality는 pipeline architecture만으로 보장되지 않는다.
좋은 data source, retrieval quality, source verification, evaluation benchmark, human review loop가 함께 있어야 한다.
AI-Q는 FreshQA, Deep Research Bench, DeepSearchQA 같은 평가 surface를 제공하지만, 실제 기업 데이터에서의 정확도는 별도 검증이 필요하다.
정리
NVIDIA AI-Q의 deep research skill은 agent harness를 더 똑똑하게 만드는 플러그인이라기보다, 범용 하네스와 전문 리서치 백엔드 사이의 책임 경계를 정의하는 사례다.
하네스는 사용자와 대화하고 작업을 조율한다. skill은 AI-Q 호출 규약을 알려 주고 helper script로 job lifecycle을 감싼다.
AI-Q 서버는 데이터가 있는 곳에서 검색, 계획, synthesis, citation, evaluation을 처리한다.
이 구조는 앞으로 enterprise agent architecture에서 자주 보게 될 가능성이 크다.
범용 에이전트가 모든 것을 직접 하는 대신, 특정 고부가가치 capability를 governed backend로 분리하고, agent skill은 그 capability를 발견하고 호출하는 contract가 된다.
AI-Q는 딥리서치라는 무거운 작업을 이 방식으로 패키징한 구체적인 예다.
참고한 공개 자료
- NVIDIA Technical Blog: Add a Specialized Deep Research Skill to Agent Harnesses
- NVIDIA-AI-Blueprints/aiq GitHub repository, v2.1.0
- AI-Q Agent Skill package
- AI-Q Agent Skills documentation
- AI-Q MCP Tools and Authentication documentation
- AI-Q Authentication documentation
- AI-Q API documentation
- NVIDIA NeMo Agent Toolkit documentation
- NVIDIA AI-Q on NVIDIA Build