뇌가 임계점 근처에서 작동한다는 “critical brain” 가설은 오래된 질문을 남긴다.
신경 avalanche의 power-law, 긴 상관 길이, critical slowing down 같은 현상은 관찰되지만, 신경계가 왜 굳이 그런 불안정해 보이는 경계로 이동해야 하는지는 별도의 설명이 필요하다.
Efficient coding under constraint drives neural systems towards criticality and sloppiness는 이 질문을 효율적 코딩의 관점에서 다시 묶는다.
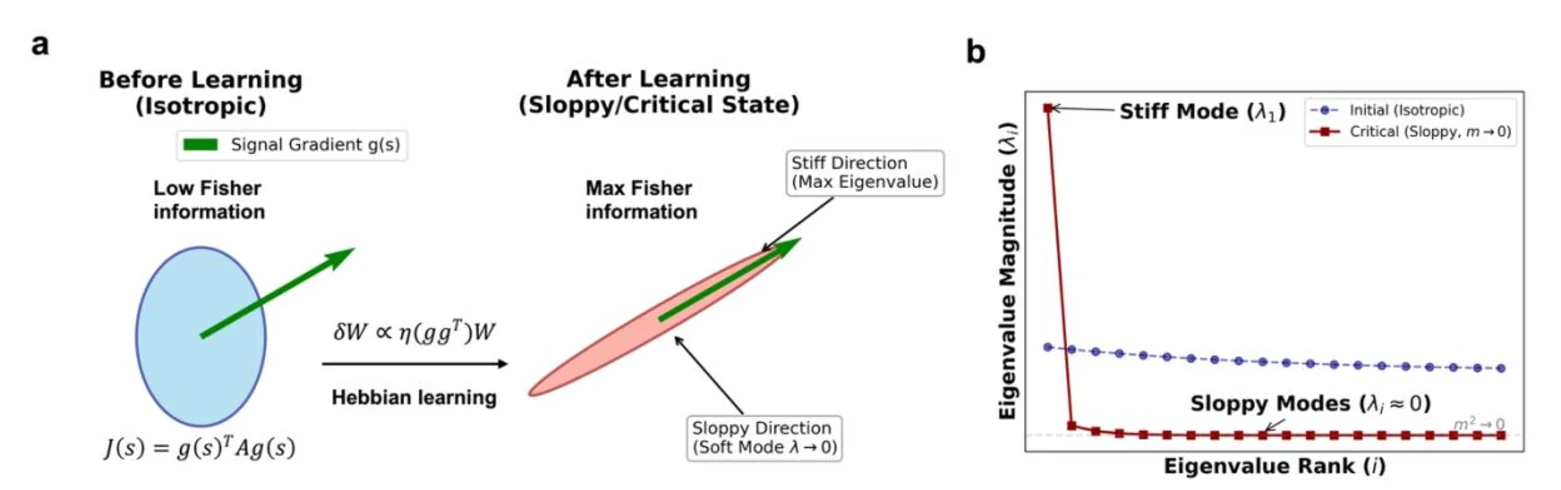
저자들은 신경 population이 제한된 자원 안에서 Fisher information을 키우려 할 때, 정보가 많은 방향에는 precision을 집중하고 나머지 방향은 거의 flat한 soft mode로 남기는 구조가 자연스럽게 생긴다고 본다.
이때 생기는 비등방성 민감도는 biological model에서 말하는 sloppiness와 맞닿고, soft mode의 상관 길이는 임계성의 신호가 된다.
이 글에서 이 논문은 새로운 AI 모델 릴리스라기보다, 제약이 있는 학습/표현 시스템에서 왜 stiff direction과 sloppy direction이 동시에 생기는가를 설명하는 이론적 프레임워크로 읽는 편이 정확하다.
실무 AI 시스템에 바로 적용할 코드나 체크포인트는 공개되어 있지 않지만, “효율적 표현 학습이 모든 방향을 균일하게 잘 만드는 것이 아니라, 중요한 소수 방향과 유연한 다수 방향을 분리한다”는 해석은 모델 학습·표현기하·강건성 논의와 연결된다.
무엇을 해결하려는가
논문이 겨냥하는 첫 번째 병목은 criticality의 기능적 이유다.
임계 상태는 넓은 dynamic range, 정보 전달, 계산 능력 측면에서 유리하다는 주장이 많지만, 그 자체가 왜 신경계의 학습 목표에서 나와야 하는지는 별개의 문제다.
기존 설명은 excitation-inhibition balance, anti-Hebbian plasticity, 경쟁 상호작용 같은 “어떻게 criticality가 생기는가”에 집중한 경우가 많았다.
두 번째 병목은 통계물리적 criticality와 동역학적 criticality의 분리다.
통계물리 쪽에서는 긴 상관 길이와 power-law가 핵심이고, 동역학 쪽에서는 marginal stability, bifurcation, critical slowing down이 핵심이다.
논문은 두 현상을 precision matrix의 가장 작은 eigenvalue가 0에 가까워지는 같은 기하학에서 설명하려 한다.
세 번째는 sloppiness다.
생물학적 모델에서는 일부 parameter direction만 기능에 강하게 영향을 주고, 많은 방향은 거의 영향을 주지 않는 비등방성 민감도가 자주 관찰된다.
이 논문은 이를 “나쁜 식별성”이 아니라, 자원 제약 아래 정보적으로 중요한 방향에 precision을 몰아주는 효율적 코딩의 결과로 해석한다.
핵심 아이디어 / 구조 / 동작 방식
모델은 매우 단순하게 시작한다.
연속 stimulus s에 대해 신경 population response x는 평균 f(s)와 Gaussian noise n으로 표현된다.
공분산을 C, precision matrix를 A = C⁻¹라고 두면, stimulus sensitivity g(s) = df/ds에 대한 Fisher information은 다음 형태가 된다.
J(s) = g(s)^T A g(s)
여기서 핵심은 A의 eigenvalue spectrum이다.
생물학적 시스템에서 variability를 줄여 precision을 유지하는 것은 대사 비용을 요구하므로, 저자들은 총 precision Tr(A)에 제약을 둔다.
이 제약 아래 Fisher information을 최대화하면, 가장 큰 eigenvalue의 eigenvector는 g(s) 방향으로 정렬되고 그 값은 커진다.
반대로 stimulus와 덜 관련된 방향의 eigenvalue는 작아진다.
즉 시스템은 모든 방향을 고르게 정밀하게 만드는 대신, 정보가 많은 방향에는 stiff하고 나머지 방향에는 sloppy한 구조로 이동한다.
논문은 collapse를 막기 위해 ln(det A)에 해당하는 entropy penalty도 둔다.
제약 없이 최적화하면 A가 사실상 rank-1에 가까워질 수 있기 때문이다.
이 penalty와 자원 제약이 함께 작동하면서, 시스템은 완전히 collapse하지 않지만 많은 near-zero eigenvalue를 가진 quasi-critical한 상태로 자리 잡는다.
학습 규칙도 이 구조와 맞물린다.A = W W^T로 두면 Fisher information gradient에서 δW ∝ η(gg^T)W 형태의 Hebbian-like update가 나온다.
저자들은 이를 predictive coding과 연결한다.
예측 오차 z = x - f(s)를 W^T가 filtering하고, 다시 W가 top-down 또는 lateral feedback처럼 작동하면, whitening된 prediction error와 state update를 같은 수식에서 읽을 수 있다.
공간 구조를 넣으면 criticality 해석이 더 직접적이 된다.
신경 population을 cortical sheet처럼 국소 연결을 가진 구조로 보고 spatial mask M와 graph Laplacian regularization을 적용하면, softest mode가 국소적인 defect에 갇히지 않고 전체 시스템에 퍼져 있어야 긴 상관 길이를 만든다.
이때 가장 작은 eigenvalue λ_min이 0에 가까워질수록 상관 길이 ξ는 대략 1 / sqrt(λ_min)처럼 커진다.
| 구성 요소 | 논문에서의 역할 | 임계성/Sloppiness와의 연결 |
|---|---|---|
Fisher information J(s) |
stimulus 변화에 대한 population response의 민감도 | 효율적 코딩의 최적화 목표 |
Trace constraint Tr(A) |
precision 유지 비용, 즉 자원 제약 | 모든 방향을 정밀하게 만들 수 없게 함 |
| 큰 eigenvalue 방향 | stimulus sensitivity g(s)와 정렬되는 stiff direction |
정보가 많은 소수 방향에 자원 집중 |
| 작은 eigenvalue 방향 | near-zero precision을 가진 soft/sloppy mode | 긴 상관 길이와 flat energy landscape의 원천 |
| Spatial mask + Laplacian | soft mode의 국소화를 막고 smoothness 부여 | delocalized global mode와 statistical criticality 연결 |
Transfer matrix I - dt A |
relaxation dynamics 근사 | λ_min → 0이면 eigenvalue가 1에 접근해 critical slowing down 발생 |
공개된 근거에서 확인되는 점
공개 표면은 현재 arXiv 논문이 중심이다. arXiv 기준 논문은 2026년 5월 21일 제출된 v1이며, q-bio.NC(Neurons and Cognition) 카테고리의 13쪽, 3개 figure 논문이다.
Hugging Face Papers URL은 요청 시점에 404를 반환했고, 제목·arXiv ID·정확한 문구로 GitHub와 Hugging Face Hub를 검색해도 공식 code, project page, model, dataset은 확인되지 않았다.
따라서 이 글의 근거는 PDF 본문과 figure에 한정된다.
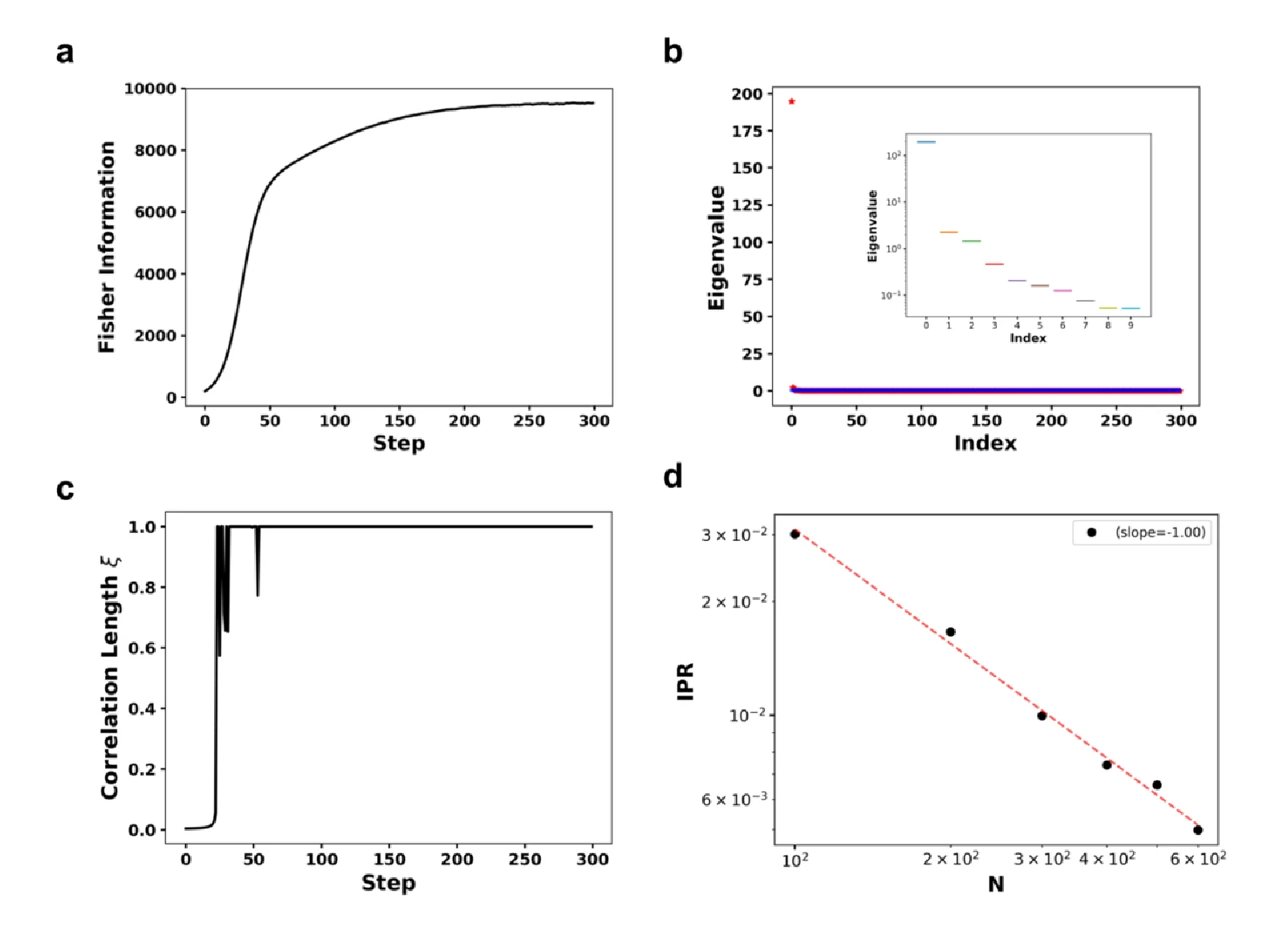
수치 실험에서 가장 먼저 확인되는 것은 Fisher information과 eigenvalue spectrum의 재배치다.
논문 Figure 2에 따르면 학습 초기에 낮고 여러 mode에 분산되어 있던 Fisher information은 약 200 iteration 이후 포화된다.
동시에 가장 큰 eigenvalue는 커지고, 나머지 eigenvalue는 0 근처로 눌린다.
저자들은 이를 “stimulus-sensitive direction에서는 stiff하고, 다른 방향에서는 sloppy한” spectrum으로 해석한다.
두 번째 근거는 상관 길이와 IPR이다.
논문은 λ_min → 0이 되면 correlation length가 커져 system size에서 포화된다고 보고한다.
또 softest mode의 inverse participation ratio가 IPR ∼ N⁻¹로 scaling된다고 제시한다.
이는 soft mode가 소수 노드에 localized된 것이 아니라, 전체 population에 퍼진 global mode라는 해석을 뒷받침한다.
세 번째 근거는 dynamics 쪽이다. relaxation dynamics를 ż = -Az로 근사하면, discrete transfer matrix는 T = I - dt A가 된다. λ_min이 0에 가까워지면 대응하는 transfer eigenvalue는 1에 접근한다.
이는 perturbation이 매우 천천히 사라지는 critical slowing down이고, 논문은 이를 bifurcation의 전조로 읽는다.
따라서 긴 상관 길이와 critical slowing down은 서로 다른 현상이 아니라 같은 near-zero eigenvalue에서 나온 두 관찰면이 된다.
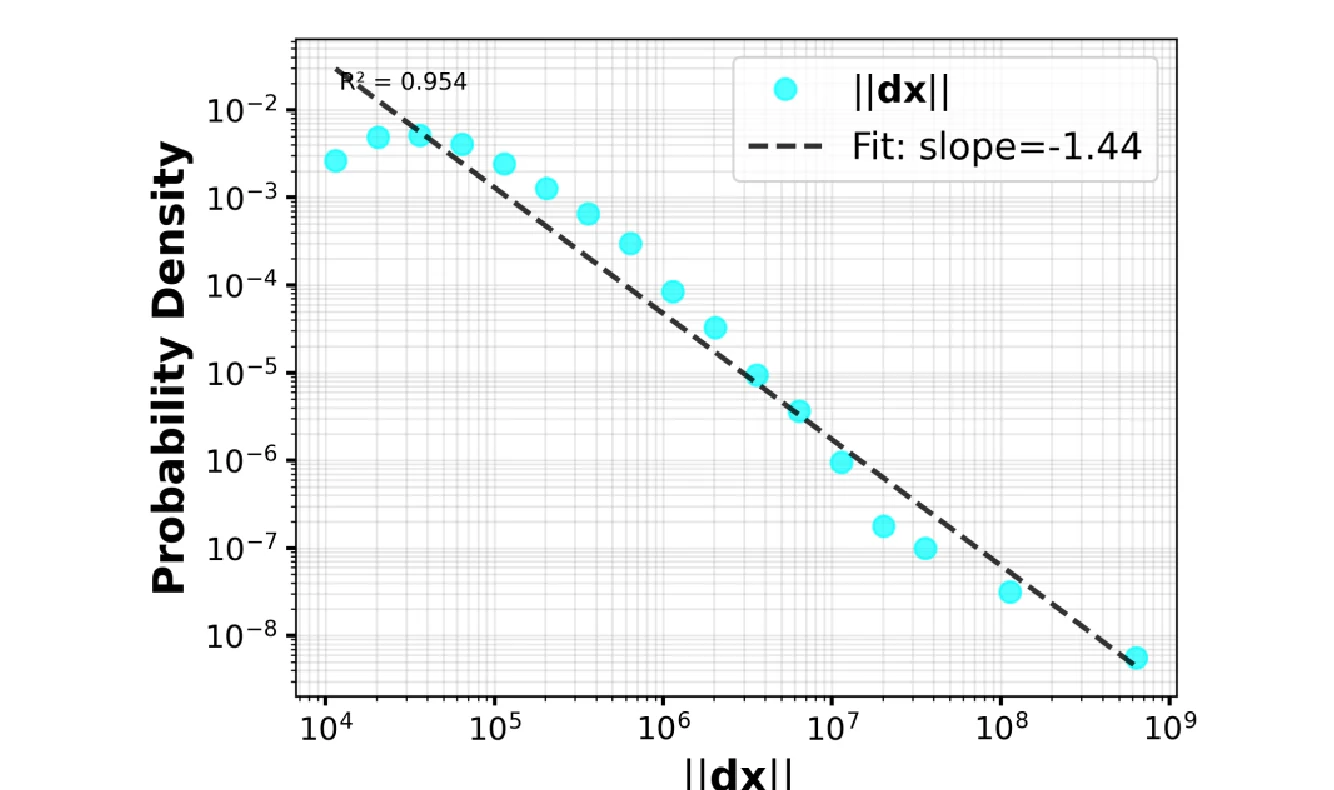
마지막으로 논문은 precision matrix에 quench event, 즉 빠른 fluctuation이 생겼을 때 response magnitude ||dx||의 분포를 본다.
근사식 dx ≈ -A⁻¹(δA)x* 때문에, near-zero eigenvalue를 많이 가진 sloppy system에서는 작은 구조적 noise가 큰 state displacement로 증폭될 수 있다.
Figure 3은 이 response magnitude가 heavy-tailed power law에 가까운 분포를 보이며, fit slope는 -1.44, R² = 0.954로 표시된다.
실무 관점에서의 해석
AI 관점에서 이 논문의 흥미로운 점은 “효율적 학습은 균일한 민감도를 만들지 않는다”는 메시지다.
우리는 종종 좋은 표현을 모든 방향에서 안정적이고 잘 분리된 embedding처럼 상상하지만, 실제 제약 최적화는 더 비등방적일 수 있다.
중요한 소수 방향에는 높은 precision과 빠른 분별력을 주고, 나머지 방향은 sloppy하게 두는 것이 오히려 자원 효율적이라는 해석이다.
이 관점은 대형 모델의 표현기하나 post-training에도 조심스럽게 비유할 수 있다.
모델은 모든 parameter/activation direction을 동등하게 쓰지 않는다.
어떤 direction은 성능과 alignment에 매우 민감하고, 많은 direction은 noise나 작은 perturbation에 둔감하다.
이 논문은 그런 stiff/sloppy 분리가 단순한 부작용이 아니라, 제한된 자원 아래 정보를 잘 쓰려는 시스템에서 자연스럽게 나올 수 있음을 보여주는 작은 이론 모형으로 읽힌다.
하지만 일반화에는 주의가 필요하다.
논문은 covariance가 stimulus와 독립이라고 가정하고, stimulus도 1차원으로 둔다.
실제 뇌나 현대 AI 모델은 다차원 입력, 비선형 dynamics, 학습 중 바뀌는 noise 구조를 가진다.
저자들도 다차원 stimulus에서는 scalar Fisher information이 아니라 Fisher information matrix의 determinant를 다뤄야 하며, stimulus-dependent precision과 실제 avalanche dynamics를 future work로 남긴다.
또 하나의 한계는 release maturity다.
현재 공개물은 이론 논문과 PDF figure가 전부에 가깝다.
공식 코드, 재현 스크립트, 데이터, interactive notebook이 없기 때문에 독자가 바로 실험을 재현하거나 다른 모델에 적용하기는 어렵다.
따라서 이 글은 “도구를 써 보자”가 아니라 “제약 최적화가 왜 critical/sloppy geometry를 만들 수 있는지 이해하자”에 가깝다.
결론적으로 이 논문은 critical brain 가설을 효율적 코딩, Fisher information, sloppiness라는 세 언어로 다시 번역한다.
가장 중요한 함의는 임계성이 반드시 외부에서 fine-tuning된 특수 상태가 아닐 수 있다는 점이다.
자원이 제한된 population code가 중요한 stimulus direction을 최대한 잘 구분하려고 하면, stiff한 정보 축과 soft한 global mode가 동시에 생기고, 그 결과 긴 상관 길이와 느린 relaxation, heavy-tailed response가 함께 나타날 수 있다.
실무 AI 연구자에게도 이 프레임은 모델을 “많은 방향이 균일하게 강한 시스템”이 아니라, 제약 속에서 정보가 몰리는 방향과 유연하게 남는 방향이 공존하는 시스템으로 보는 데 도움을 준다.