LLM에서 machine unlearning은 단순한 fine-tuning 문제가 아니다.
특정 데이터나 행동은 지워야 하지만, 모델의 일반 지식과 downstream 성능은 남겨야 한다.
이때 forget set과 retain set은 서로 다른 방향의 gradient를 만들고, 두 목표를 같은 optimizer state로 섞으면 utility가 무너질 수 있다.
반대로 완전히 분리하면 실제로 공유해도 되는 신호까지 끊어 버릴 수 있다.
DualOptim+: Bridging Shared and Decoupled Optimizer States for Better Machine Unlearning in Large Language Models는 이 중간 지점을 optimizer state 수준에서 설계한다.
핵심은 forget objective와 retain objective가 공유하는 성분은 base state에 보관하고, 각 목표에만 필요한 잔차는 delta state로 따로 보관하는 것이다.
논문은 이를 AdamW 같은 stateful optimizer에 붙일 수 있는 plug-and-play framework로 제시하며, 8-bit quantization 변형도 함께 실험한다.
중요한 점은 이 논문이 “언러닝용 새 loss 하나”를 제안하는 것이 아니라는 점이다.
기존의 IDK+GD, ME+GD, DPO+GD, NPO+GD 같은 unlearning objective 위에서 optimizer가 forget-retain trade-off를 어떻게 처리할지 바꾸는 쪽에 가깝다.
그래서 이 글에서는 DualOptim+를 safety/privacy 응용 논문이라기보다 LLM unlearning을 위한 model-training optimizer recipe로 읽는다.
무엇을 해결하려는가
LLM 언러닝의 기본 목표는 forget set의 영향을 지우면서 retain set의 성능을 유지하는 것이다.
기존 LLM unlearning 방법은 대체로 forget loss와 retain loss를 합쳐 한 번에 update하거나, 두 objective를 번갈아 update한다.
전자는 gradient를 단순 합산하기 때문에 “너무 잘 잊어서” 모델 utility가 크게 떨어질 수 있고, 후자는 objective를 번갈아 쓰더라도 optimizer state는 공유되기 때문에 충돌하는 정보가 moving average 안에서 얽힌다.
DualOptim은 이 문제를 보고 forget optimizer와 retain optimizer를 완전히 분리했다.
이 방식은 objective가 강하게 충돌하는 경우에는 유리하지만, 논문은 LLM unlearning에서 두 gradient가 항상 충돌하지는 않는다고 관찰한다.
특히 optimization 후반에는 forget과 retain gradient가 부분적으로 같은 방향을 가질 수 있는데, 이때 완전 분리는 공유 가능한 신호를 버리는 선택이 된다.
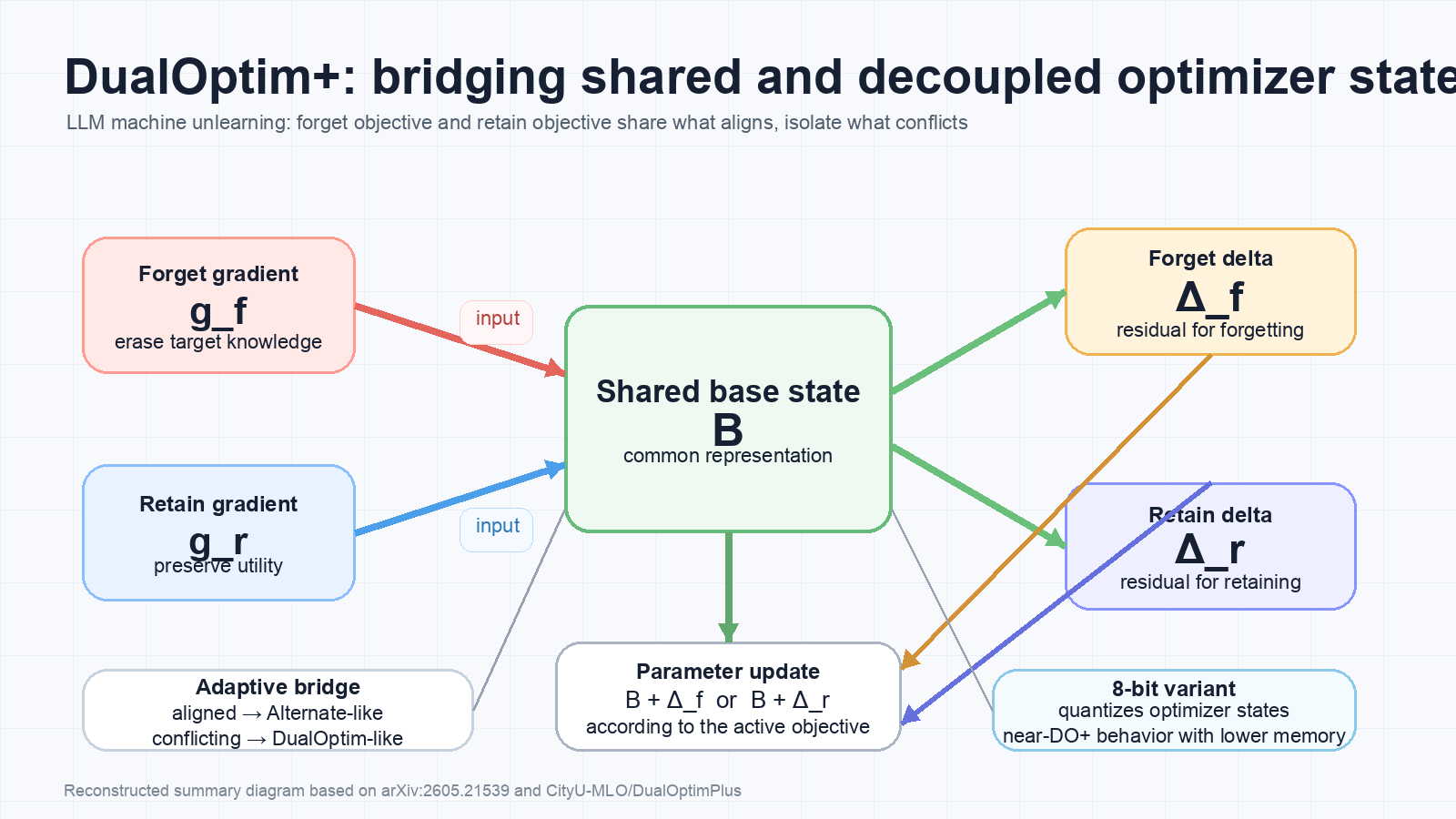
DualOptim+의 질문은 여기서 나온다. forget과 retain이 같은 방향일 때는 shared state처럼 행동하고, 충돌할 때는 decoupled state처럼 행동할 수 있는 optimizer state 구조를 만들 수 있는가?
논문은 base + delta decomposition으로 이 중간 구조를 만든다.
핵심 아이디어 / 구조 / 동작 방식
DualOptim+는 optimizer state를 두 층으로 나눈다.
| 구성 요소 | 역할 | 해석 |
|---|---|---|
Base state B |
forget·retain objective가 공유하는 공통 표현을 축적 | gradient가 정렬될 때 shared optimizer처럼 동작하게 하는 축 |
Delta state Δ_f, Δ_r |
각 objective의 gradient에서 base state로 설명되지 않는 잔차를 축적 | forget 또는 retain에만 필요한 residual memory |
| Parameter update | 현재 active objective에 맞춰 B + Δ_f 또는 B + Δ_r를 사용 |
완전 공유와 완전 분리 사이의 adaptive bridge |
AdamW 관점에서 보면 1차 momentum뿐 아니라 2차 moment도 같은 방식으로 분해할 수 있다.
공개 코드의 custom_optimizer_plus.py 역시 base state와 delta state를 따로 들고, update 시점에는 bias-corrected base와 bias-corrected delta를 더해 exp_avg와 denominator를 만든다.
8-bit variant는 bitsandbytes block-wise quantization으로 base와 delta state를 양자화한다.
논문이 강조하는 설계상의 디테일은 base state update timing이다. ablation에서 base를 parameter update 이후에 갱신하는 설정이 TOFU forget 5% / IDK+GD / Phi-1.5 기준 OVR 59.57로 가장 좋았다. before-delta update는 58.93, after-delta update는 58.14였다.
저자들은 이를 delta state가 안정된 lagged reference를 기준으로 residual을 계산하게 만들기 때문이라고 해석한다.
또 하나 흥미로운 부분은 이 구조가 theoretical boundary를 가진다는 점이다. forget·retain gradient의 기대 방향이 같으면 delta state가 작아져 Alternate에 가까워지고, 음의 상관이 강하면 base state가 약해져 DualOptim에 가까워진다.
즉 DualOptim+는 “항상 공유”나 “항상 분리”가 아니라, gradient 관계에 따라 두 극단 사이에 놓이는 optimizer state 설계다.
공개된 근거에서 확인되는 점
논문은 TOFU 기반 fictitious unlearning, real-world person unlearning, safety alignment, multi-task learning을 모두 실험한다.
모든 숫자를 하나의 평균으로 뭉개기보다는, 각 설정에서 무엇이 좋아졌는지 분리해 보는 편이 낫다.
| 실험 축 | 대표 결과 | 해석 |
|---|---|---|
| TOFU / Llama 2 / IDK+GD / forget 10% | OVR: Alternate 72.57, DO 72.27, DO+ 73.25, DO+ 8bit 73.48 | targeted unlearning에서 완전 분리보다 base+delta가 utility를 더 잘 보존 |
| Real-world / Llama 3 / ME+GD | OVR: Alternate 66.49, DO 67.60, DO+ 73.13, DO+ 8bit 73.52 | 실제 인물 기반 언러닝에서는 DO+ 계열의 utility 보존 이득이 크게 나타남 |
| Safety alignment / Alpaca-Llama 3 | DO+ OVR 56.45, utility AVG 32.81, XSTest over-refusal 28.13 | safety rate를 높이면서 과도한 거절과 utility 손실을 일부 줄임 |
| Multi-task learning / Llama 2 | AVG: Joint 65.05, Alternate 65.22, DO 8bit 64.36, DO+ 8bit 67.14 | objective conflict가 약한 multi-task 설정에서도 완전 분리보다 base+delta가 유리 |
TOFU 결과에서는 Joint가 forget efficacy는 높게 만들 수 있지만 model utility를 크게 희생하는 패턴이 반복된다.
예를 들어 Phi-1.5 / IDK+GD / forget 5%에서 Joint는 UFE 72.55, TFE 58.32를 보이지만 MU는 36.26에 머문다.
반면 DO+는 UFE 67.63, TFE 67.60, MU 51.52, OVR 59.57이다.
즉 “더 많이 잊는 것”만 보면 Joint가 강해 보일 수 있지만, 언러닝의 실제 목표는 forget efficacy와 retain utility의 균형이다.
Real-world unlearning 결과는 더 선명하다.
Llama-3-8B-Instruct에서 실제 인물 20명을 unlearning target으로 잡고, neighbor individuals와 ARC-c, MMLU, TruthfulQA, TriviaQA, GSM8K로 utility를 본다.
ME+GD 설정에서 DO+는 MU 48.40, OVR 73.13을 기록했고, DO+ 8bit는 MU 49.29, OVR 73.52를 기록했다.
Alternate의 OVR 66.49, DO의 OVR 67.60과 비교하면, fully decoupled optimizer만으로는 실제 데이터 언러닝의 복잡성을 충분히 처리하지 못한다는 논문 해석이 설득력을 얻는다.
Safety alignment 실험은 이 방법을 “unsafe knowledge를 지우고 utility를 유지하는 언러닝”으로 본다.
Alpaca-finetuned Llama 3에 20,000개 Alpaca instruction과 2,000개 safety instruction을 섞고, harmful instruction dataset과 XSTest over-refusal로 평가한다.
DO+는 safety AVG 97.43, utility AVG 32.81, OVR 56.45를 기록했다.
모든 unlearning 기반 방법이 initial보다 safety metric을 크게 올리지만, DO+는 utility와 over-refusal 측면에서 상대적으로 균형이 좋다는 점이 핵심이다.
효율성은 단순하지 않다.
Table 11 기준 Phi-1.5-1.3B / AdamW / 300 steps / batch size per GPU 4 / 2×NVIDIA H20 환경에서 DO+는 39.04GB/GPU, 475초를 썼고, DO+ 8bit는 33.68GB/GPU, 468초를 썼다.
Alternate는 33.26GB/GPU, 443초다.
즉 8-bit variant는 DO+의 추가 state 비용을 크게 줄여 Alternate에 가까운 메모리 footprint로 가져오지만, 완전히 공짜인 개선은 아니다.
연구/운영 환경에서는 “언러닝 품질 이득이 이 정도 optimizer 복잡도와 구현 리스크를 정당화하는가”를 별도로 판단해야 한다.
공개 artifact도 확인할 만하다. arXiv 논문은 ICML 2026 accepted로 표시되어 있고, 코드 링크는 CityU-MLO/DualOptimPlus다.
GitHub API 기준 이 저장소는 2026년 5월 15일 생성됐고, 조회 시점에 stars 1, forks 0, open issues 0, default branch main이다. /releases/latest는 404, tags는 빈 배열이며, GitHub license metadata와 /license endpoint 모두 라이선스를 확인해 주지 않는다.
README는 requirements.txt, config/phi1-5_tofu.yaml, scripts/tofu_phi1-5/ 중심의 재현용 사용법을 설명한다.
따라서 현재 공개 코드는 versioned library라기보다 논문 실험 재현을 위한 초기 연구 코드에 가깝다.
실무 관점에서의 해석
DualOptim+의 가장 큰 의미는 LLM 언러닝을 loss engineering만으로 보지 않는다는 데 있다.
같은 forget objective와 retain objective를 쓰더라도 optimizer state가 두 gradient의 과거 정보를 어떻게 기억하느냐에 따라 결과가 달라진다.
이는 post-training 파이프라인에서 optimizer를 “그냥 AdamW”로 고정하는 습관에 대한 좋은 반례다.
실무적으로는 특히 세 가지 상황에서 의미가 있다.
첫째, 개인정보·저작권·오래된 지식처럼 특정 기억을 지우되 모델의 일반 성능을 유지해야 하는 경우다.
둘째, safety alignment처럼 harmful behavior를 줄이면서 과도한 refusal을 피해야 하는 경우다.
셋째, 여러 objective를 동시에 다루는 multi-task fine-tuning에서 완전 공유와 완전 분리 중 하나를 고르는 것이 너무 거친 선택일 때다.
다만 바로 제품 인프라에 넣을 단계로 읽으면 곤란하다.
논문 결과는 강하지만, 공개 repo는 초기 연구 코드 형태이고 release/tag/license 표면이 아직 정리되어 있지 않다.
또한 실험은 특정 loss 조합, benchmark, 모델군에서 수행됐기 때문에, 실제 기업 모델의 데이터 삭제 요청이나 safety policy update에 적용하려면 별도의 감사 가능성, regression suite, rollback 전략, 법무·정책 기준이 필요하다.
개념적으로 더 중요한 메시지는 “forget과 retain은 항상 싸우는 것도, 항상 협력하는 것도 아니다”라는 점이다.
기존 Joint는 둘을 너무 쉽게 섞고, DualOptim은 둘을 너무 강하게 갈라놓는다.
DualOptim+는 그 사이에 base와 delta라는 구조적 완충층을 넣는다.
LLM post-training이 점점 더 많은 objective를 동시에 다루게 될수록, 이런 optimizer-state-level decomposition은 언러닝을 넘어 alignment, personalization rollback, domain adaptation에서도 재사용될 수 있는 설계 패턴으로 보인다.