대형 언어모델 이후의 AI 논의는 자주 “더 큰 모델이 더 많은 세계 지식을 압축하면 충분한가”라는 질문으로 돌아간다.
하지만 실제 에이전트가 브라우저, 코드베이스, 로봇, API, 사람과 상호작용하는 순간 문제는 단순한 지식 압축이 아니다.
에이전트는 세계를 관찰하고, 행동하고, 그 행동이 다시 관찰 조건을 바꾸는 순환 안에 놓인다.
Toward Enactive Artificial Intelligence는 이 지점을 정면으로 잡는다.
Banafsheh Rafiee와 Richard Sutton은 enactive cognition, 즉 인지가 내부 표상 처리만이 아니라 세계와의 능동적·체화된 상호작용 속에서 생긴다는 관점을 AI에 더 깊게 들여와야 한다고 주장한다.
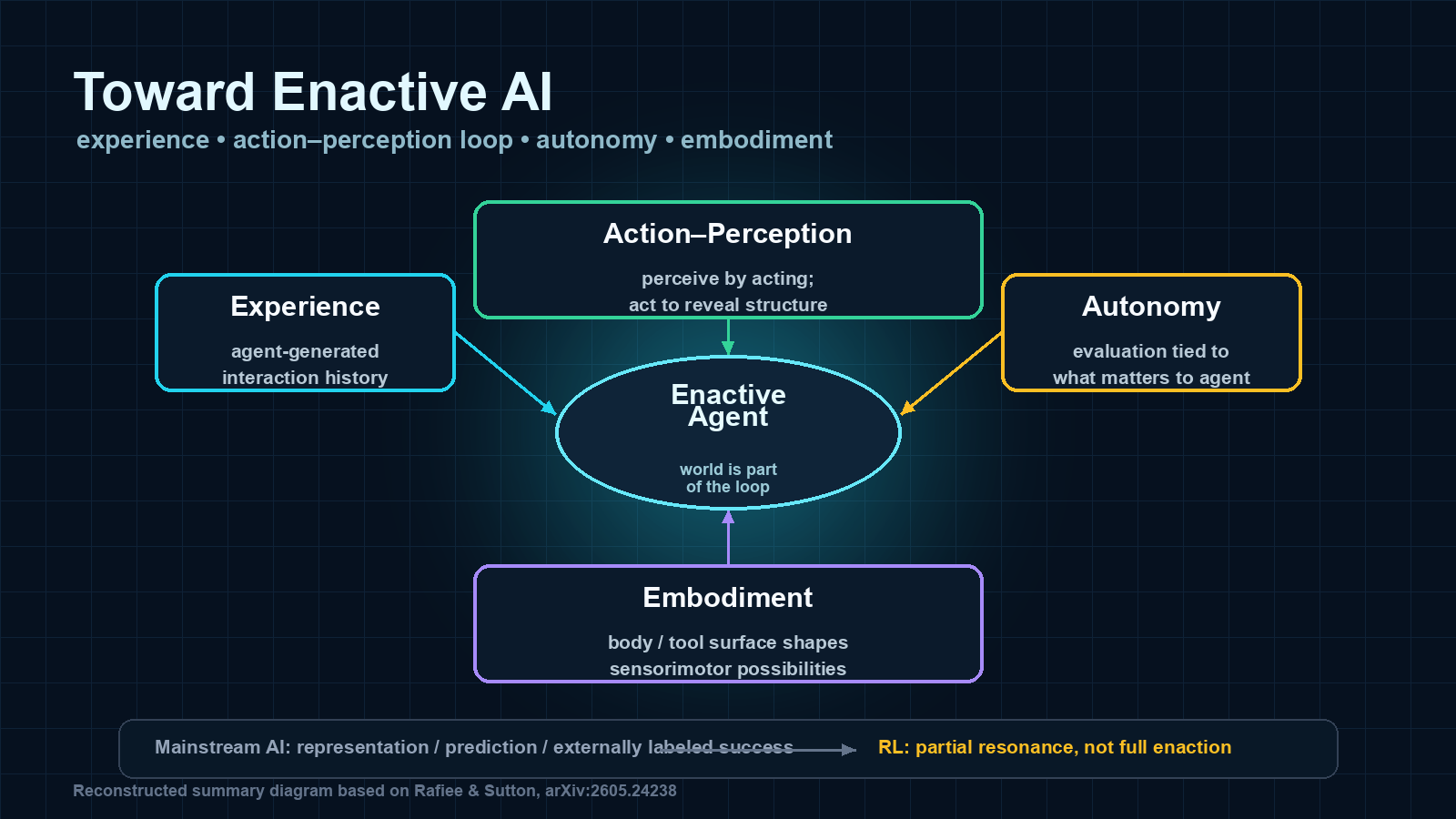
논문은 네 가지 핵심 개념을 중심으로 mainstream AI와 reinforcement learning을 다시 읽는다.
그 네 개념은 experience, action–perception inseparability, autonomy, embodiment다.
이 글에서 중요한 점은 이 논문을 새로운 모델 release나 benchmark paper로 읽지 않는 것이다.
공개된 형태는 arXiv v1 논문과 HTML 렌더링이며, 조회 시점 기준 공식 GitHub 저장소, Hugging Face 모델·데이터셋, 프로젝트 페이지는 확인되지 않는다.
따라서 이 글은 구현 성숙도 평가가 아니라, LLM·RL·agent system을 설계할 때 어떤 철학적·시스템적 빈칸이 남는지 보는 개념적 지도에 가깝다.
무엇을 해결하려는가
논문이 겨냥하는 병목은 AI가 세계를 “표상”하는 능력과 세계 안에서 “살아 움직이며” 배우는 능력 사이의 간극이다.
고전적 AI와 많은 현대 ML 시스템은 감각 입력을 받아 내부 표현을 만들고, 그 표현을 바탕으로 추론하거나 행동을 출력하는 구조로 이해되어 왔다.
이 관점에서는 지각이 행동보다 앞서고, 세계는 내부 모델로 대체될 수 있는 대상으로 취급된다.
Enactive 관점은 이 그림을 뒤집는다.
지각은 수동적으로 들어오는 데이터를 처리하는 과정이 아니라, 에이전트가 움직이고 개입하면서 세계가 어떻게 드러나는지 익히는 능력이다.
논문은 이를 sensorimotor contingency, 즉 행동이 감각 입력을 어떻게 바꾸는지에 대한 숙련된 이해로 설명한다.
눈, 머리, 손, 몸의 움직임이 바뀌면 보이는 것과 들리는 것과 만져지는 것이 달라진다.
따라서 지각은 행동과 분리된 입력 단계가 아니라 행동을 통해 성립하는 활동이다.
이 문제의식은 최근 LLM 기반 에이전트에도 그대로 적용된다.
모델이 웹페이지를 읽고, 툴을 호출하고, 코드를 실행하고, 실패하면 다시 시도하는 구조에서는 세계가 정적인 prompt가 아니다.
세계는 매 행동 뒤에 달라지는 상태 공간이다.
그럼에도 많은 시스템은 여전히 “관찰 → 내부 추론 → 액션”이라는 직렬 파이프라인으로 설계된다.
논문은 바로 이 분리 자체가 AI의 한계를 만든다고 본다.
핵심 아이디어 / 구조 / 동작 방식
논문은 enactive AI를 네 개념으로 정리한다.
첫째는 경험이다.
경험은 단순히 데이터셋을 많이 보는 것이 아니라, 에이전트가 세계와 계속 상호작용하면서 자기 행동의 결과를 통해 얻는 것이다.
저자들은 Brooks의 표현처럼 “세계가 자기 자신의 가장 좋은 모델”이라는 관점을 가져온다.
어떤 내부 모델도 세계의 열린 변화 가능성을 완전히 담을 수 없기 때문에, 에이전트는 세계와의 실시간 접촉을 유지해야 한다.
둘째는 행동-지각 불가분성이다.
논문은 “to perceive is to act”라는 강한 명제를 반복한다.
생성 비디오 모델이 교통신호의 색 변화 패턴을 이어 그릴 수 있다고 해서, 신호가 고장 났을 때 무엇을 해야 하는지 이해한 것은 아니다.
Enactive system은 예측 패턴이 깨졌을 때 개입하고, 탐색하고, 상황을 바꿀 수 있어야 한다.
이 차이는 정확도의 차이가 아니라 종류의 차이다.
셋째는 자율성이다.
여기서 자율성은 단순히 외부 명령 없이 행동한다는 뜻이 아니다.
에이전트가 자기 조직을 유지하기 위해 무엇이 성공이고 실패인지 평가할 수 있는가, 그리고 그 평가 기준이 외부에서 주어진 label이나 reward가 아니라 에이전트 자신의 조직과 필요에서 나오는가라는 질문이다.
논문은 supervised learning과 LLM이 대체로 외부 평가에 의존한다고 보고, RL은 이보다 한 걸음 더 나아가 trajectory의 결과를 통해 행동을 평가한다고 본다.
넷째는 체화다.
체화는 로봇 몸체를 붙이면 해결되는 부품 문제가 아니다.
몸의 구조, 감각 배치, 움직일 수 있는 방식, 도구 표면은 무엇이 지각적으로 의미 있는지 자체를 바꾼다.
Gibson식 affordance 관점에서 문턱, 손잡이, 통로, 버튼은 에이전트가 어떤 몸과 행동 가능성을 갖고 있는지에 따라 다른 의미를 갖는다.
소프트웨어 에이전트라면 이 질문은 “브라우저, 파일시스템, API, 메모리, 승인 큐 같은 도구 표면이 어떤 종류의 체화인가”로 확장된다.
| Enactive 개념 | 논문이 강조하는 의미 | 현재 AI/RL에서 남는 빈칸 |
|---|---|---|
| Experience | 고정 데이터가 아니라 에이전트가 세계와 상호작용하며 생성하는 경험 | supervised data와 offline corpus는 경험의 부산물일 뿐, 에이전트 자신의 경험은 아님 |
| Action–perception inseparability | 지각은 행동을 통해 세계가 드러나는 방식을 익히는 능력 | 많은 모델은 관찰·표상·행동을 여전히 분리된 단계로 다룸 |
| Autonomy | 성공/실패의 기준이 에이전트 자신의 조직과 필요에서 생기는가 | RL도 reward function은 대체로 외부에서 주어짐 |
| Embodiment | 몸과 도구 표면이 무엇을 지각하고 할 수 있는지 구조화함 | 로봇/에이전트 시스템에서도 몸은 종종 실행 인터페이스로만 취급됨 |
공개된 근거에서 확인되는 점
arXiv metadata 기준 이 논문은 2026년 5월 22일 제출된 cs.AI v1 paper이며, 저자는 Banafsheh Rafiee와 Richard S.
Sutton이다.
논문 길이는 비교적 짧고, 공식 HTML 렌더링은 Abstract, Enactive Cognition, Experience, Action–perception inseparability, Autonomy, Embodiment, Conclusion의 흐름으로 구성된다.
공식 figure나 benchmark table은 없다.
논문이 RL을 보는 방식은 균형이 있다.
RL은 trial-and-error를 통해 에이전트 자신의 경험을 만들고, 행동을 학습의 중심에 놓으며, reward를 통해 시간적으로 확장된 평가를 도입한다.
저자들은 이 점에서 RL이 많은 mainstream AI보다 enactive principle과 구조적으로 더 가깝다고 본다.
특히 control system이 “지금 목표에 얼마나 가까운가”를 묻는다면, RL은 “이 행동이 장기 결과 관점에서 좋았는가”를 묻는다고 구분한다.
하지만 논문은 RL을 enactive cognition과 동일시하지 않는다.
Reward function은 여전히 외부에서 정의되는 경우가 많고, 에이전트의 normativity가 자기 조직에서 생긴다고 말하기 어렵다.
또한 일반적인 RL pipeline에서도 perception은 행동보다 앞선 observation processing으로 남는 경우가 많고, embodiment는 cognition의 구성 조건이라기보다 environment interface나 hardware constraint로 처리되는 경우가 많다.
공개 artifact 관점에서는 보수적으로 읽어야 한다.
Hugging Face Papers URL은 조회 시점에 Paper not found 계열 404 응답을 반환했고, Hugging Face model/dataset API에서 arXiv ID 기반 검색 결과도 비어 있었다.
GitHub exact-title 검색에서도 공식 companion repo는 확인되지 않았다.
따라서 “논문이 제안한 enactive AI 구현체”가 공개되어 있다고 말하면 안 된다.
현재 확인 가능한 것은 개념적 argument와 AI/RL literature를 연결하는 paper text다.
실무 관점에서의 해석
이 논문의 실무적 가치는 당장 가져다 쓸 알고리즘보다, agent system을 설계할 때 빠뜨리기 쉬운 질문을 선명하게 만든다는 데 있다.
LLM agent를 만들 때 흔한 설계는 관찰을 context에 넣고, reasoning을 생성하고, tool call을 실행한 뒤, 결과를 다시 context로 넣는 것이다.
겉으로는 interaction loop가 있지만, 그 loop가 정말 행동-지각의 불가분성을 반영하는지는 별개의 문제다.
예를 들어 좋은 에이전트는 단지 웹페이지를 요약하는 모델이 아니라, 무엇을 더 보아야 하는지 결정하고, 어떤 조작이 정보 구조를 더 잘 드러내는지 선택하고, 실패한 행동 뒤에 환경을 다시 읽는 능력을 가져야 한다.
이 관점에서는 retrieval, browser control, code execution, human approval, long-term memory가 모두 단순 도구가 아니라 에이전트의 지각 구조를 바꾸는 surface가 된다.
RL 쪽에서도 이 논문은 중요한 경고를 준다.
Reward를 더 정교하게 만들고 rollout을 늘리는 것만으로 enactive autonomy가 완성되지는 않는다.
논문이 말하는 자율성은 외부 목표를 잘 최적화하는 능력이 아니라, 무엇이 에이전트에게 중요한지 자체가 그 에이전트의 조직과 유지 조건에서 나오는가에 가깝다.
현재의 AI 제품에서는 이 기준이 사용자 목표, 정책, 비용, 안전 규칙, 승인 체계로 외부에서 부여된다.
그렇기 때문에 enactive AI를 말하려면 reward design보다 governance와 embodiment surface까지 같이 봐야 한다.
소프트웨어 에이전트의 “몸”이라는 질문도 흥미롭다.
로봇이 아니라도 에이전트는 브라우저 viewport, shell, 파일시스템, API 권한, memory store, scheduler, notification channel 같은 행동 가능성의 묶음을 가진다.
이 도구 표면은 에이전트가 무엇을 볼 수 있고, 무엇을 바꿀 수 있고, 어떤 실패를 감지할 수 있는지 결정한다.
따라서 future agent architecture에서 embodiment는 하드웨어 로봇만의 문제가 아니라, capability boundary와 feedback channel 설계의 문제로도 읽을 수 있다.
한계도 분명하다.
논문은 스스로 결론에서 이 아이디어들을 아직 operationalize하지 않았다고 말한다.
어떤 benchmark가 skillful engagement를 측정하는가, action–perception inseparability의 정도를 어떻게 정량화하는가, artificial agent의 self-maintenance가 배터리·하드웨어 무결성·학습된 competence 중 무엇을 뜻하는가 같은 질문은 열려 있다.
다시 말해 이 논문은 답안지가 아니라 연구 프로그램의 방향표다.
그래도 지금 시점에 이 방향표는 유용하다.
AI 에이전트가 점점 더 많은 외부 상태와 도구를 다루게 될수록, intelligence를 내부 추론 품질만으로 설명하기 어려워진다.
중요한 것은 모델이 세계를 얼마나 잘 압축했는가만이 아니라, 세계와 어떤 loop를 만들고, 어떤 표면을 통해 지각하며, 어떤 기준으로 자기 행동을 평가하고, 어떤 형태의 체화를 통해 더 나은 affordance를 얻는가다.
결론적으로 Toward Enactive Artificial Intelligence는 LLM 시대의 agent 논의를 다시 RL과 embodied cognition 쪽으로 당겨 오는 짧지만 밀도 있는 position paper다.
에이전트 시스템을 제품으로 만들거나 연구 플랫폼으로 설계한다면, 이 논문의 네 단어—experience, action–perception, autonomy, embodiment—는 체크리스트처럼 써볼 만하다.
우리 시스템은 스스로 경험을 만들고 있는가.
행동이 지각을 바꾸는가.
평가 기준은 어디서 오는가.
도구와 몸은 cognition의 일부로 설계되어 있는가.