LLM post-training에서 데이터 믹스는 늘 중요했지만, 실제 운영 관점에서는 꽤 불편한 문제다.
코딩, 수학, instruction following, knowledge, safety 데이터를 어느 비율로 섞을지에 따라 모델 성능이 크게 달라지는데, 가능한 비율 조합은 연속 공간이고 큰 모델을 대상으로 전부 학습해 볼 수는 없다.
그래서 최근 방법들은 작은 proxy model을 여러 번 학습시키고, 그 결과로 더 큰 학습의 mixture weight를 추정한다.
CausalMix: Data Mixture as Causal Inference for Language Model Training의 흥미로운 점은 이 문제를 단순 회귀나 validation loss 최적화로 보지 않는다는 데 있다.
논문은 “하나의 정적 최적 비율”이 있다고 가정하지 않는다.
대신 현재 데이터 풀의 상태, 즉 난이도, 품질, 복잡도, 문체 같은 covariate를 조건으로 두고, 특정 도메인 비율을 늘렸을 때 downstream 성능이 어떻게 바뀌는지를 상태별 causal marginal return으로 추정한다.
요약하면 CausalMix는 SFT 데이터 레시피를 “좋은 데이터 비율 찾기”가 아니라, 현재 데이터 풀에서 어떤 도메인이 추가 효용을 내는지 추정하는 causal decision problem으로 바꾼다.
이 프레이밍은 데이터 큐레이션 팀에게 특히 중요하다.
같은 20% 수학 데이터라도 쉬운 instruction pool에 넣을 때와, 이미 복잡한 reasoning trace가 많은 pool에 넣을 때의 한계효용은 다를 수 있기 때문이다.
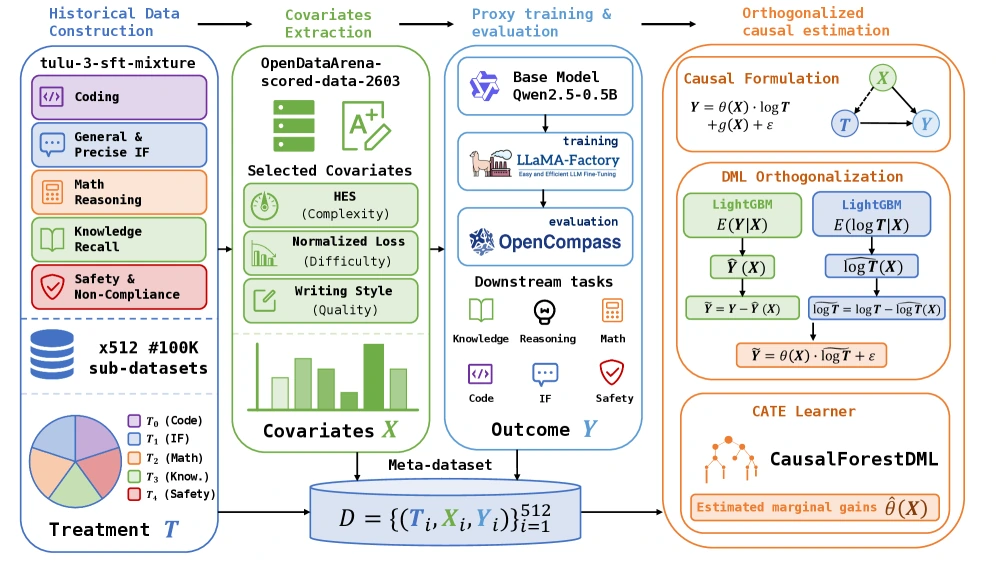
무엇을 해결하려는가
기존 data mixture optimization은 대체로 두 가지 형태다.
하나는 validation loss나 reference set loss를 예측하는 proxy model을 만들고, loss가 낮아지는 mixture를 고르는 방식이다.
다른 하나는 historical run에서 mixture weight와 성능 사이의 전역 mapping을 회귀로 학습하는 방식이다.
RegMix, DoReMi, ODM, DMO 같은 계열이 이 문제를 각자 다른 방식으로 다룬다.
CausalMix가 지적하는 병목은 이 전역 mapping이 데이터 상태 변화를 충분히 반영하지 못한다는 점이다.
SFT에서는 데이터 풀 자체가 계속 바뀐다.
수학 데이터의 난이도가 올라갈 수도 있고, instruction following 데이터의 문체가 좋아질 수도 있으며, safety 데이터가 reasoning 성능과 충돌하거나 오히려 보완할 수도 있다.
이때 “코딩 20%, 수학 30%, IF 20%” 같은 정적 비율은 데이터 풀 하나에서는 맞아도 다른 풀에서는 틀릴 수 있다.
논문은 이 문제를 causal inference의 potential outcome 관점으로 재정의한다.
각 proxy training run은 다음과 같은 triplet으로 본다.
| 구성 | CausalMix에서의 의미 | 예시 |
|---|---|---|
X |
학습 전에 관측 가능한 데이터 상태 covariate | Normalized Loss, Writing Style, HES |
T |
도메인 mixture treatment | Coding, IF, Math, Knowledge, Safety 비율 |
Y |
학습 후 downstream outcome | Knowledge, Reasoning, Math, Coding, IF, Safety 평가 평균 |
여기서 중요한 제약은 X가 반드시 학습 전에 알 수 있는 데이터 상태여야 한다는 점이다.
학습 후 모델 정보나 downstream 평가 결과가 covariate에 섞이면 causal effect 해석은 깨진다.
또한 mixture assignment가 downstream outcome을 보고 adaptive하게 선택된 것이 아니라는 ignorability 가정도 필요하다.
논문도 이 조건이 깨지는 경우에는 엄밀한 causal effect라기보다 “causally motivated marginal-response estimate”로 해석해야 한다고 선을 긋는다.
핵심 아이디어 / 구조 / 동작 방식
CausalMix의 treatment는 원래 simplex 위의 mixture vector다.K개 도메인이 있을 때 T = (T1, ..., TK), Tk >= 0, sum Tk = 1이다.
그런데 도메인 비율은 compositional data이고, 한 도메인을 늘리면 다른 도메인은 줄어든다.
논문은 diminishing return과 simplex geometry를 다루기 위해 원시 비율 T를 그대로 쓰지 않고 Z = log(T + epsilon) 형태의 log-mixture treatment로 바꾼다.
그 다음 핵심 추정량은 다음 직관으로 읽을 수 있다.
현재 데이터 상태
x에서 특정 도메인 비율을 조금 늘리면 downstream 성능이 얼마나 바뀌는가?
논문은 full response surface를 직접 학습하기 어렵다고 보고, 국소적으로 partially linear approximation을 둔다.
즉 성능은 데이터 상태만으로 설명되는 baseline g(x)와, log-mixture treatment의 marginal return theta0(x)의 합으로 근사된다.
여기서 theta0,k(x) > 0이면 상태 x에서 도메인 k를 늘리는 것이 유리하고, theta0,k(x) < 0이면 negative transfer 가능성이 있다는 뜻이다.
이때 단순히 (X, T) -> Y를 회귀하면 상태 자체가 좋은 데이터와 mixture 효과가 섞인다.
CausalMix는 Double Machine Learning을 사용해 outcome과 treatment를 각각 covariate X에 대해 residualize한다.
다시 말해 “이 데이터 상태라면 원래 기대되는 성능”과 “이 데이터 상태라면 원래 기대되는 mixture”를 빼고, 남은 residual treatment variation이 residual outcome variation을 얼마나 설명하는지 본다.
정리하면 파이프라인은 다음 순서다.
| 단계 | CausalMix의 처리 | 읽을 점 |
|---|---|---|
| Historical run 구성 | Qwen2.5-0.5B proxy model을 512개 100K sub-dataset mixture로 학습 | 큰 모델을 전부 grid search하지 않기 위한 meta-dataset |
| Covariate 추출 | OpenDataArena-scored-data-2603의 30개 metric 중 HES, Normalized Loss, Writing Style 선택 | Complexity, Difficulty, Quality를 각각 반영 |
| Causal estimation | LightGBM first-stage predictor + CausalForestDML | baseline state effect와 mixture effect를 분리하려는 설계 |
| Policy 변환 | CausalMix-A는 positive return을 normalize, CausalMix-S는 100,000개 Dirichlet candidate 중 top 100 평균 | 하나는 closed-form, 다른 하나는 search smoothing |
CausalMix-A는 positive marginal return만 남겨 simplex 위의 mixture로 정규화한다.
CausalMix-S는 RegMix식 후보 탐색에 가깝다.
Dirichlet에서 100,000개 candidate mixture를 뽑고, fitted causal model이 높게 평가한 상위 100개를 원래 mixture space에서 평균한다.
논문은 이 averaging이 단일 후보의 과대추정 노이즈를 줄이고 unseen generalization을 부드럽게 만든다고 설명한다.
공개된 근거에서 확인되는 점
실험의 중심 데이터는 tulu-3-sft-mixture다.
저자들은 Tulu 3의 도메인 구분을 따라 Coding, Instruction Following, Math Reasoning, Knowledge Recall, Safety & Non-Compliance를 다룬다.
General과 Precise IF는 IF로 묶고, multilingual subset은 제외한다.
평가는 OpenCompass를 사용하며, downstream task를 Knowledge, Reasoning, Math, Coding, IF, Safety 여섯 능력 축으로 묶는다.
논문의 main result는 “모든 cell에서 압도적 1등”이라기보다는, Dev 평균 기준으로 여러 scale과 model size에서 CausalMix가 일관된 강점을 보인다는 쪽에 가깝다.
특히 0.5B proxy에서 얻은 causal predictor를 800K data pool과 Qwen2.5-7B로 옮겼을 때도 같은 방향의 이득이 나온다는 점이 핵심이다.
| 설정 | CausalMix 결과 | 비교 기준 | 해석 |
|---|---|---|---|
| Qwen2.5-0.5B / 100K / Dev 평균 | CausalMix-A 29.91 | DoReMi 29.74, DMO 29.17 | 작은 scale에서도 Dev 평균 최고 |
| Qwen2.5-0.5B / 400K / Dev 평균 | CausalMix-A 33.41 | DMO 32.63, Equal 30.51 | 400K에서 더 뚜렷한 개선 |
| Qwen2.5-0.5B / 800K / Dev 평균 | CausalMix-A 33.94 | DMO 32.04, Equal 31.78 | large data pool에서도 baseline보다 높음 |
| Qwen2.5-7B / 800K / Dev 평균 | CausalMix-S 62.28 | DMO 60.35, RegMix 60.14 | 0.5B proxy 기반 추정이 7B로 전이 |
| Qwen3-4B LongCoT / 평균 | CausalMix 66.66 | Grid 64.74, Equal 63.80 | 다른 model family와 math/code 데이터로 확장 |
다만 Unseen 평균은 더 조심스럽게 읽어야 한다.
100K와 800K의 Unseen 평균에서는 DMO나 Equal이 일부 CausalMix 변형보다 높게 나온다.
7B 800K에서도 Equal의 Unseen 평균 49.55가 CausalMix-A 49.09보다 조금 높다.
따라서 이 논문을 “항상 모든 unseen benchmark에서 최고”라고 요약하면 과하다.
더 정확한 해석은 CausalMix가 Dev outcome을 최적화하면서도 cross-scale transfer와 LongCoT transfer에서 강한 신호를 보였다는 것이다.
LongCoT 확장 실험은 CausalMix의 주장을 더 흥미롭게 만든다.
저자들은 tulu-3-sft-mixture에서 학습한 historical data를 재사용하되, outcome을 coding/math 평균으로 바꾸고, 완전히 다른 AM-Thinking-v1-Distilled math/code 데이터 풀에 적용한다. target model도 Qwen2.5가 아니라 Qwen3-4B다.
이 설정에서 CausalMix는 평균 66.66으로 Grid 64.74, DMO 63.47, Equal 63.80보다 높다. proxy retraining 없이 다른 데이터 pool과 model family에 전이했다는 주장이 나오는 지점이다.
Ablation도 중요하다.
800K 설정에서 covariate X를 제거하면 global treatment-to-outcome mapping에 가까워지고, DML orthogonalization을 제거하면 일반 supervised regression에 가까워진다.
논문 Table 3에서는 둘 다 CausalMix보다 낮다.
| 설정 | w/o X | w/o Orthogonalization | CausalMix 최고 변형 | 해석 |
|---|---|---|---|---|
| Qwen2.5-0.5B / 800K 평균 | 33.29 | 32.66 | CausalMix-A 33.94 | 데이터 상태 conditioning과 orthogonalization 모두 기여 |
| Qwen2.5-7B / 800K 평균 | 61.30 | 59.65 | CausalMix-S 62.28 | 단순 회귀보다 causal residualization이 안정적 |
Covariate 선택과 CATE 해석
논문에서 가장 실무적으로 쓸 만한 부분은 covariate selection이다.
OpenDataArena-scored-data-2603은 63개 고품질 instruction-following dataset, 약 2,500만 sample에 대해 30차원 score를 제공한다.
CausalMix는 이 중 세 가지를 최종 covariate로 선택한다.
HES: Qwen3-8B reasoning trace에서 top 0.5% high-entropy token의 entropy 합으로, 중요한 결정 지점과 reasoning complexity를 반영한다.Normalized_Loss: Qwen3-8B 기반 normalized cross-entropy로, 데이터의 예측 가능성 및 학습 utility를 반영한다.Writing_Style: QuRater-1.3B 기반의 명확성, 일관성, 문체 품질 신호다.
흥미로운 점은 covariate를 많이 넣을수록 항상 좋아지는 것이 아니라는 것이다.
논문은 512개 historical record라는 작은 meta-dataset에서는 너무 많은 covariate가 curse of dimensionality를 일으켜 causal estimator를 약하게 만든다고 본다.
이건 데이터 큐레이션에도 현실적인 교훈이다.
“가능한 모든 데이터 품질 점수를 넣자”가 아니라, 현재 proxy run 수가 감당할 수 있는 상태 변수만 남겨야 한다.
CATE Interpreter 분석도 꽤 의미 있다.
논문은 trained causal model을 tree interpreter로 해석해 도메인별 marginal return이 어떤 데이터 상태에서 바뀌는지 보여 준다.
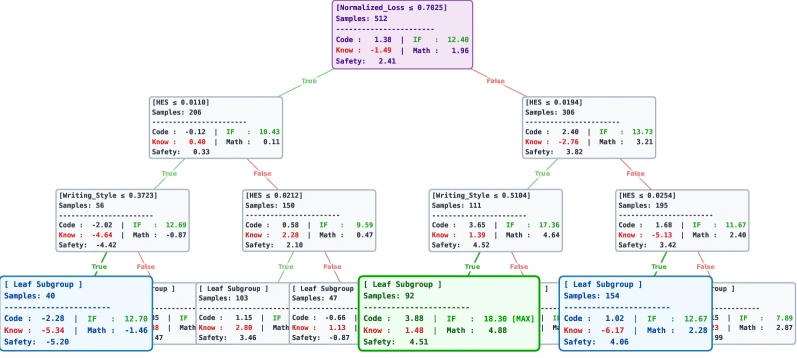
저자들의 해석에 따르면 IF 데이터는 여러 feature subspace에서 비교적 안정적인 positive return을 낸다.
반면 Knowledge 데이터는 high Normalized Loss와 high HES를 가진 어려운 reasoning-heavy target data에서는 negative effect를 보인다.
이는 factual knowledge injection과 complex logical reasoning 사이의 skill conflict 가능성을 뒷받침하는 신호로 제시된다.
Math, Coding, Safety 같은 복잡한 도메인은 품질이 낮거나 complexity가 낮은 영역에서는 distributional noise를 늘릴 수 있다.
하지만 Writing Style과 HES가 적당한 구간에서는 서로 synergy를 내며, 특히 Safety 데이터가 주는 penalty를 완화하는 효과까지 관찰된다고 논문은 설명한다.
이 관점은 “도메인별 고정 비율”보다 “현재 데이터 풀의 상태를 보고 도메인의 한계효용을 판단하자”는 CausalMix의 메시지와 맞물린다.
공개 아티팩트 상태와 재현성
현재 공개 표면은 논문 중심이다.
Hugging Face Papers와 arXiv abs/html/pdf에서는 paper 자체와 3개 figure, 실험 표, appendix hyperparameter를 확인할 수 있다. arXiv/HF Papers 표면에서 별도 공식 GitHub repository, model checkpoint, dataset release bundle은 확인되지 않았다.
논문은 구현 도구로 EconML, LightGBM, LlamaFactory, OpenCompass를 명시하지만, CausalMix 자체를 바로 실행할 수 있는 공식 코드 링크를 함께 공개한 형태는 아니다.
이 점은 실무 해석에서 중요하다.
CausalMix는 당장 pip install causalmix로 적용하는 라이브러리라기보다, 데이터 믹스 최적화 팀이 자신의 proxy-run infrastructure 위에 재구현할 수 있는 연구 프레임워크에 가깝다.
특히 512개 Qwen2.5-0.5B proxy model을 각각 100K SFT example로 학습했다는 설정은 가볍지 않다.
Appendix는 이 proxy training의 총 FLOPs를 약 5.53e20으로 추정한다.
| 표면 | 확인한 내용 | 실무적 의미 |
|---|---|---|
| Hugging Face Papers | 2607.01104 paper mirror와 요약 |
접근 entry point로 편리하지만 canonical version은 arXiv 확인 필요 |
| arXiv abs/html/pdf | arXiv:2607.01104v1, 2026-07-01 제출, 22 pages, 3 figures |
공식 source와 figure/benchmark table의 기준 |
| 공식 코드/모델 링크 | arXiv/HF Papers에서 별도 companion repo 또는 checkpoint 링크 미확인 | 즉시 재현 가능한 release bundle보다는 paper-only release로 보는 편이 안전 |
| 사용 도구 | EconML, LightGBM, LlamaFactory, OpenCompass | 구현 방향은 명확하지만 전체 pipeline은 독자가 재구성해야 함 |
실무 관점에서의 해석
CausalMix의 가장 큰 가치는 데이터 믹싱을 더 공학적으로 말하게 만든다는 데 있다.
지금까지 post-training data recipe는 “좋은 데이터를 많이 모았다”, “수학을 더 넣었다”, “코딩과 safety를 섞었다”처럼 정성적 표현에 머무르기 쉬웠다.
CausalMix는 여기에 “현재 데이터 상태에서 도메인 비율 변화의 marginal return은 무엇인가”라는 측정 가능한 질문을 넣는다.
특히 세 가지 메시지가 중요하다.
첫째, 데이터 품질 점수는 filter threshold만을 위한 것이 아니다.
HES, Normalized Loss, Writing Style 같은 metric은 어떤 데이터를 버릴지 고르는 데도 쓰이지만, CausalMix에서는 mixture policy의 context가 된다.
같은 도메인 데이터라도 target pool의 difficulty와 writing quality에 따라 한계효용이 바뀐다.
둘째, proxy run을 단순 성능 예측용으로만 쓰지 않는다.
DML residualization을 통해 “좋은 데이터 상태라서 원래 성능이 높았던 것”과 “mixture treatment 변화가 성능을 움직인 것”을 분리하려고 한다.
이게 완전한 causal identification을 보장하는 것은 아니지만, validation loss 회귀보다 더 적절한 질문을 던지는 것은 맞다.
셋째, mixture optimization의 output은 단일 숫자 표가 아니라 해석 가능한 데이터 운영 정책으로 이어질 수 있다.
예를 들어 어려운 reasoning-heavy pool에서 Knowledge domain이 negative return을 보인다는 결과는, 단순히 지식 데이터를 줄이라는 뜻이 아니라 factual injection과 reasoning supervision 사이의 충돌을 별도로 실험하라는 신호가 된다.
Safety 데이터도 무조건 성능을 떨어뜨리는 항목이 아니라, 데이터 품질과 complexity 조건에 따라 다른 도메인과 synergy를 낼 수 있다.
한계도 분명하다. causal inference라는 이름이 붙어 있지만, historical mixture assignment가 진짜로 outcome과 독립적으로 설계되었는지, 모든 중요한 confounder를 covariate가 잡았는지는 별도 문제다. proxy run 수가 512개라 covariate 공간을 넓히는 데 제약이 있고, mixture 도메인도 다섯 개 coarse domain에 머문다.
또한 Unseen 평균에서 항상 최고인 것은 아니므로, 실무 적용 시에는 Dev outcome을 그대로 제품 목표로 삼을지, unseen robustness를 별도 objective로 둘지 정해야 한다.
그래도 방향은 설득력 있다.
LLM post-training이 점점 데이터 공정의 문제로 이동하고 있다면, 다음 병목은 “무슨 데이터를 더 넣을까”가 아니라 “현재 데이터 상태에서 무엇을 더 넣으면 실제로 한계효용이 있는가”다.
CausalMix는 그 질문을 causal inference 언어로 바꾸고, proxy training run을 단순한 실험 로그가 아니라 mixture policy를 학습하는 meta-dataset으로 재사용한다.
공개 구현이 아직 보이지 않는 paper-only 단계라는 점은 아쉽지만, SFT 데이터 레시피를 설계하는 팀에게는 꽤 직접적인 사고 도구가 될 수 있다.