긴 컨텍스트는 LLM 메모리 문제의 가장 직관적인 해법처럼 보인다.
대화 기록과 도구 실행 결과를 더 많이 넣으면 모델이 더 잘 기억할 것 같기 때문이다.
하지만 실제 agent나 long-term assistant에서는 컨텍스트 창을 키우는 것만으로는 부족하다.
비용은 커지고, 오래된 정보는 attention 안에서 희석되며, 모델이 긴 히스토리에서 정말 필요한 조각을 안정적으로 쓰리라는 보장도 없다.
δ-mem: Efficient Online Memory for Large Language Models는 이 문제를 “더 긴 입력”이 아니라 작고 계속 갱신되는 내부 상태로 다룬다.
Jingdi Lei, Di Zhang, Junxian Li, Weida Wang, Kaixuan Fan, Xiang Liu, Qihan Liu, Xiaoteng Ma, Baian Chen, Soujanya Poria가 제안한 δ-mem은 frozen full-attention backbone 옆에 Online State of Associative Memory(OSAM)를 두고, 현재 토큰이나 상호작용 segment가 들어올 때마다 이 상태를 delta-rule로 업데이트한다.
핵심은 메모리를 텍스트로 다시 prompt에 넣지 않는다는 점이다. δ-mem은 과거 정보를 작은 행렬 상태에 압축하고, 이 상태를 읽어 attention query와 output 쪽에 저랭크 보정을 만든다.
논문은 8×8 온라인 상태만으로 Qwen3-4B-Instruct 기준 평균 점수를 46.79에서 51.66으로 끌어올렸다고 보고한다.
이 결과가 흥미로운 이유는 절대 점수보다도, 메모리 경로가 retrieval prompt가 아니라 Transformer 계산 안으로 직접 들어간다는 데 있다.
무엇을 해결하려는가
LLM 메모리 기법은 대체로 세 갈래로 나눌 수 있다.
첫째는 텍스트 메모리다.
RAG, MemoryBank, 요약 기반 메모리처럼 과거 정보를 문서나 요약문으로 저장한 뒤 다시 컨텍스트에 넣는다.
유연하지만 retrieval noise, 압축 손실, 컨텍스트 예산 문제가 따라온다.
둘째는 외부 채널 메모리다. hidden representation이나 별도 memory bank를 저장하고, 별도 모듈로 읽어 모델에 융합한다.
텍스트 요약보다는 풍부한 표현을 보존할 수 있지만, retrieval/fusion 경로가 backbone attention과 따로 놀기 쉽고 시스템 복잡도가 올라간다.
셋째는 parametric memory다.
LoRA, prefix, model editing처럼 추가 파라미터나 가중치 보정을 통해 기억을 넣는다. frozen backbone과 잘 맞고 효율적이지만, 한 번 학습된 뒤에는 메모리가 정적이어서 계속 변하는 대화·작업 히스토리에는 덜 자연스럽다.
δ-mem은 이 셋 사이의 빈틈을 겨냥한다.
저장 상태는 텍스트가 아니라 작은 연상기억 행렬이고, 업데이트는 inference 중 online으로 일어나며, 사용 경로는 외부 retrieval 결과를 붙이는 것이 아니라 attention 계산을 직접 보정하는 방식이다.
따라서 논문의 질문은 “얼마나 많은 히스토리를 prompt에 넣을 것인가”가 아니라 과거의 key-value association을 얼마나 작은 상태로 유지하고, 그 상태를 현재 attention에 어떻게 연결할 것인가다.
핵심 아이디어 / 구조 / 동작 방식
δ-mem은 선택된 Transformer layer에서 hidden state를 낮은 차원의 memory query/key/value로 투영한다.
이때 메모리 상태 S는 r×r 행렬이며, 논문의 기본 설정은 r=8이다.
새로운 정보가 들어오면 현재 memory key가 이전 상태에서 어떤 value를 예측하는지 계산하고, 실제 value와의 차이를 delta-rule 형태로 쓴다.
이미 잘 예측되는 association은 작게 바뀌고, 예측 오차가 큰 부분만 상태를 보정한다.
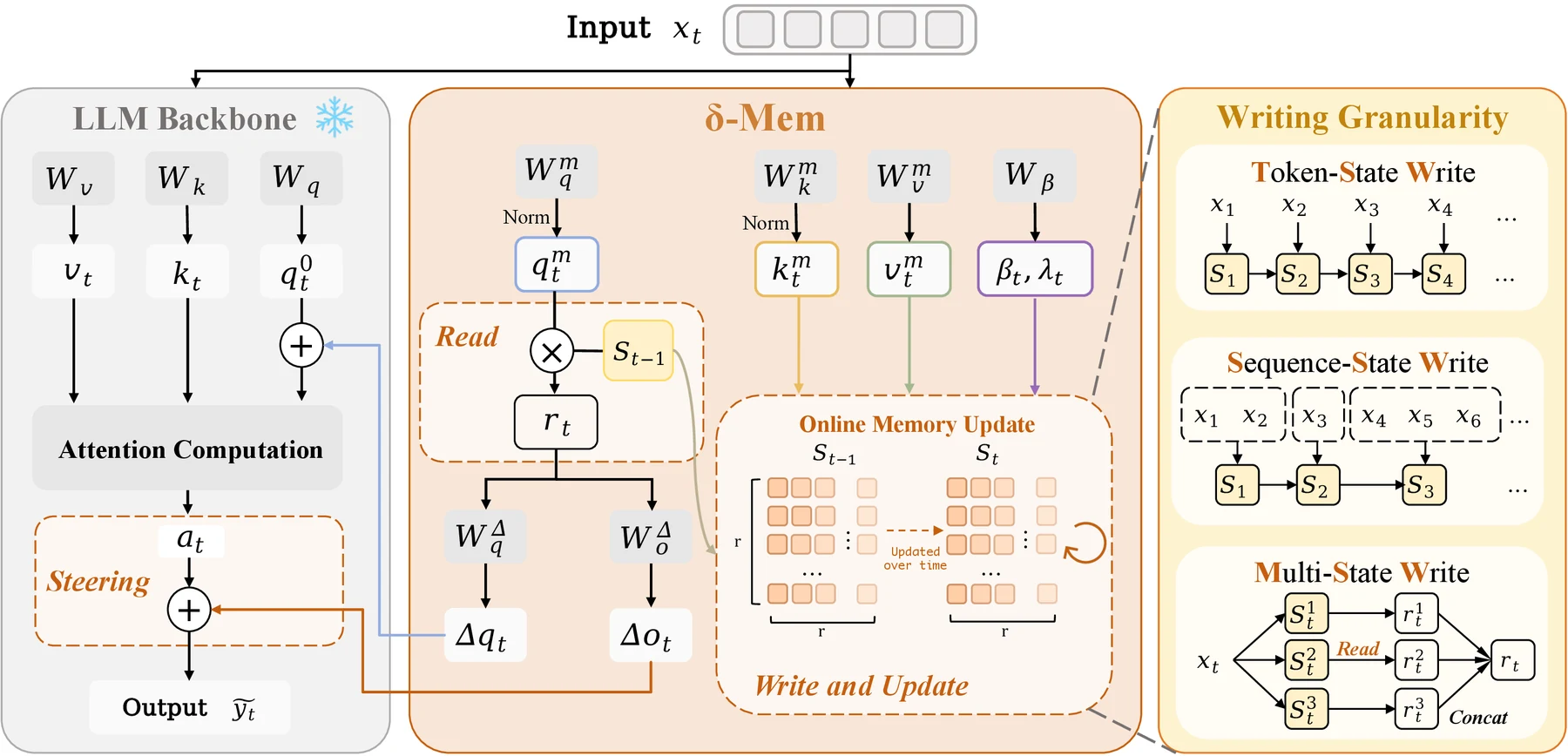
논문 source bundle에서 추출한 δ-mem 공식 개요도. frozen LLM backbone의 attention 계산 옆에 작은 온라인 상태가 붙고, read signal이 query/output 보정으로 들어간 뒤 현재 정보가 다시 상태에 쓰인다.
읽기 단계도 단순 retrieval과 다르다.
현재 입력에서 만든 memory query가 이전 상태 S를 조회해 read vector를 만들고, 이 read vector가 두 종류의 보정으로 바뀐다.
하나는 원래 backbone query에 더해지는 query-side correction이고, 다른 하나는 attention output 뒤에 더해지는 output-side correction이다.
논문은 q/o 경로만 쓰는 설정을 기본값으로 삼는다. qkvo 전체를 보정하면 평균 점수는 조금 더 높지만, 추가 파라미터 대비 이득이 크지 않다는 판단이다.
쓰기 단위는 세 가지로 실험한다.
| 쓰기 전략 | 의미 | 해석 |
|---|---|---|
| TSW, Token-State Write | 토큰마다 온라인 상태를 갱신 | 가장 세밀하지만 형식 토큰과 잡음에도 민감할 수 있음 |
| SSW, Sequence-State Write | 메시지·segment 단위로 hidden state를 평균내 한 번 갱신 | 중복 write를 줄이고 상태 변화를 부드럽게 만듦 |
| MSW, Multi-State Write | 여러 병렬 sub-state에 나누어 쓰고 readout을 결합 | 사실, 선호, 진행 상태 같은 정보가 한 상태에서 간섭하는 문제를 완화하려는 방향 |
학습은 표준 SFT loss로 진행된다.
논문 설정에서는 QASPER의 2,219개 sample split을 사용하고, backbone training sequence length는 512, memory write budget은 8,192 tokens로 둔다. backbone은 frozen 상태로 두고 δ-mem 쪽 파라미터만 학습한다.
즉 이 방식은 “모델 전체를 다시 학습한 새 foundation model”이라기보다, frozen backbone 위에 붙는 동적 메모리 adapter에 가깝다.
공개된 근거에서 확인되는 점
논문의 주 실험은 Qwen3-4B-Instruct를 기준으로 BM25 RAG, LLMLingua-2, MemoryBank, Context2LoRA, MemGen, MLP Memory와 비교한다.
일반 능력 쪽은 IFEval, HotpotQA, GPQA-Diamond를 보고, 메모리 중심 평가는 MemoryAgentBench와 LoCoMo를 쓴다.
가장 압축해서 보면 다음과 같다.
| 설정 | HotpotQA EM/F1 | MemoryAgentBench Avg. | LoCoMo Avg. | 최종 Avg. |
|---|---|---|---|---|
| Qwen3-4B-Instruct | 42.35 / 56.00 | 29.54 | 40.79 | 46.79 |
| Context2LoRA | 37.85 / 50.88 | 32.53 | 48.11 | 44.90 |
| δ-mem SSW | 49.22 / 63.43 | 37.84 | 47.05 | 51.44 |
| δ-mem TSW | 49.41 / 63.66 | 36.48 | 46.53 | 51.66 |
| δ-mem MSW | 46.86 / 60.47 | 38.85 | 49.12 | 50.74 |
TSW는 전체 평균에서 가장 높고, MSW는 MemoryAgentBench와 LoCoMo 평균에서 가장 좋다.
이 차이는 중요하다.
토큰 단위 write는 세밀한 reasoning benchmark에서 유리할 수 있지만, 대화형 장기 메모리처럼 정보 종류가 섞이는 환경에서는 여러 상태로 나누는 MSW가 더 잘 맞을 수 있다는 신호로 읽힌다.
논문은 “명시적 과거 컨텍스트가 제거된 상황에서도 상태가 일부 정보를 회복하는가”도 따로 본다.
No Context baseline에서는 HotpotQA overall EM/F1이 0.08/8.27에 그치지만, state-enhanced 설정은 6.48/15.20으로 오른다.
LoCoMo 쪽도 평균 3.49에서 8.05로 개선된다.
절대값은 아직 낮지만, 작은 상태가 단순 장식이 아니라 일부 context-relevant signal을 보존한다는 근거로는 의미가 있다.
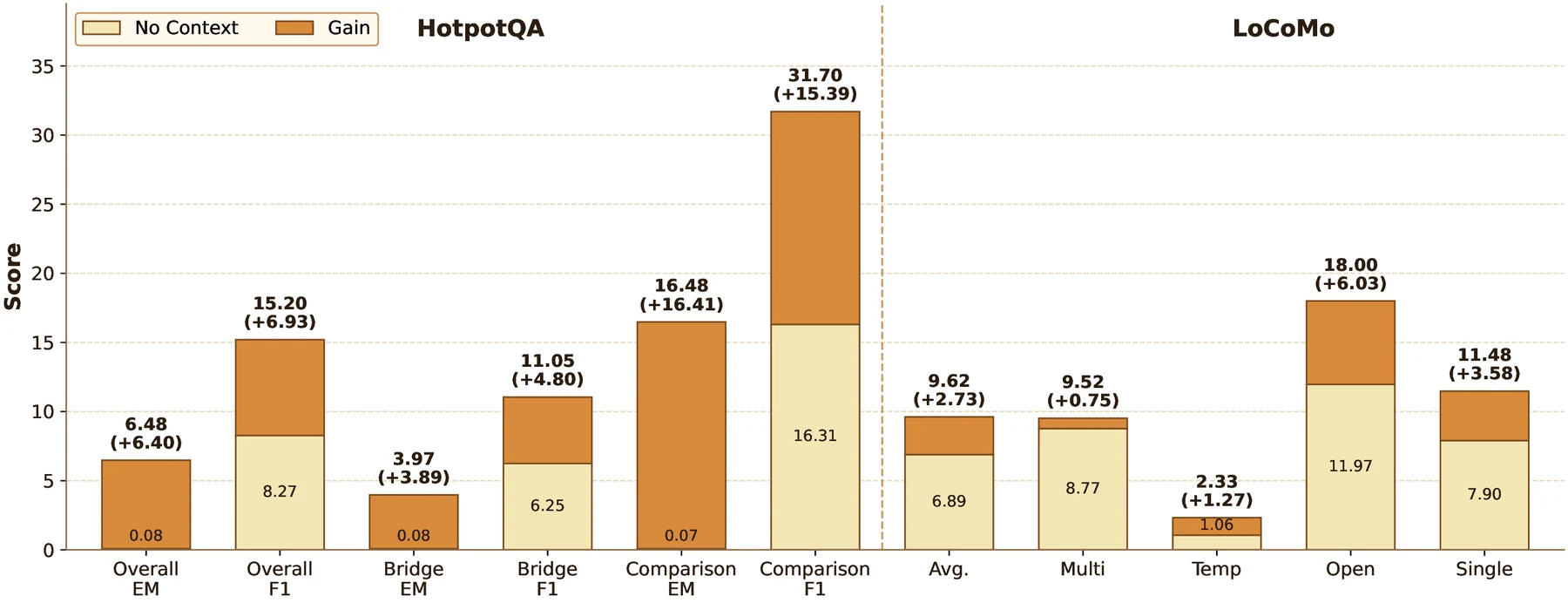
HotpotQA와 LoCoMo에서 explicit context를 제거한 뒤 온라인 상태만으로 회복되는 성능.
절대 성능은 제한적이지만, 상태 기반 보정이 완전한 no-context보다 일관되게 낫다는 점이 핵심이다.
backbone을 바꿔도 패턴은 유지된다.
Qwen3-8B는 평균 47.20에서 δ-mem SSW 기준 50.86으로 오른다.
SmolLM3-3B는 더 극적으로, baseline 26.08에서 δ-mem MSW 36.96까지 올라간다.
저자들은 큰 모델에서는 segment-level write가 noise를 줄이는 쪽으로, 작은 모델에서는 multi-state 분리가 interference를 줄이는 쪽으로 더 유리하다고 해석한다.
효율성 쪽에서는 장점과 비용이 같이 보인다. δ-mem TSW의 trainable parameter는 4.87M, backbone 대비 0.12%다.
Context2LoRA의 5.90M보다도 작고, MemGen의 46.20M이나 MLP Memory의 3,078M과는 규모가 크게 다르다.
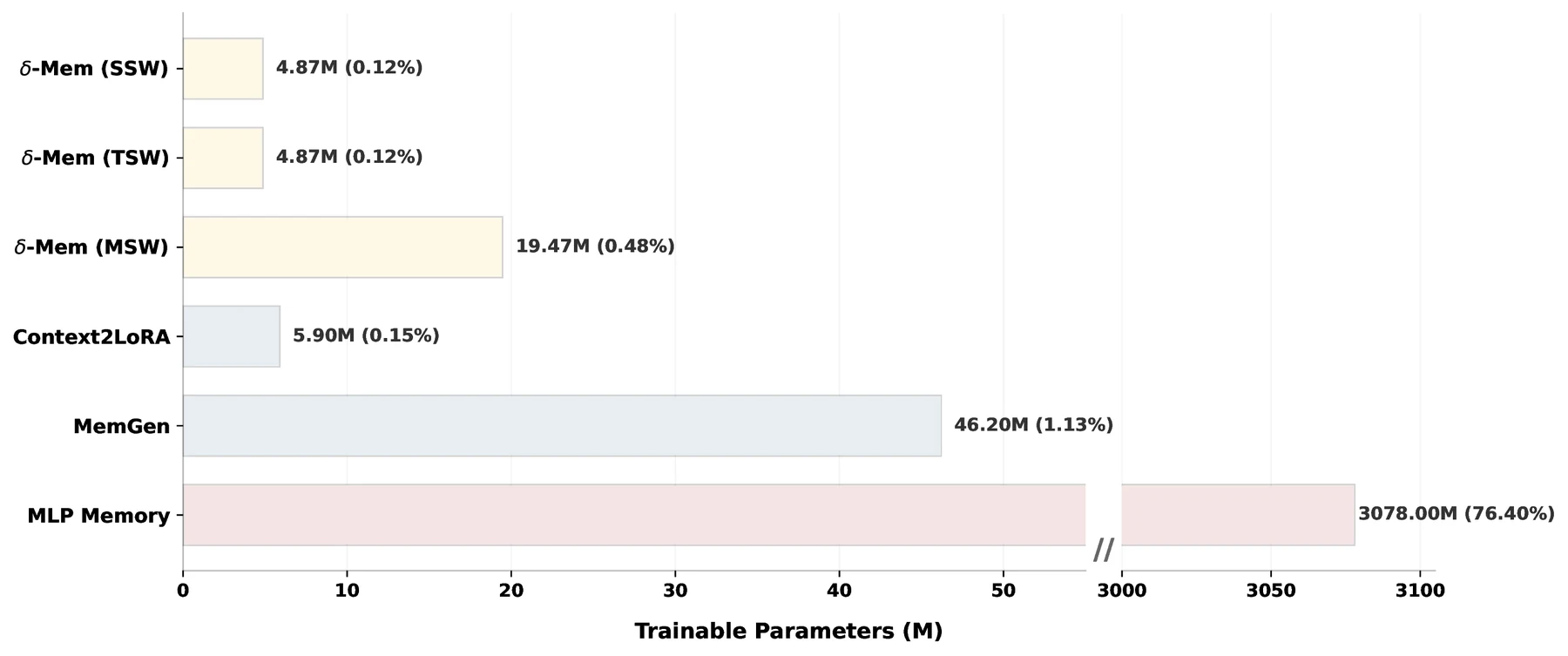
rank-8 설정의 trainable parameter 비교. δ-mem SSW/TSW는 4.87M으로, 논문이 비교한 메모리 보강 방법들 중 매우 작은 쪽에 놓인다.
GPU memory 사용량도 Vanilla와 Context2LoRA에 거의 붙어 있다.
예를 들어 32k prompt / 256 decode 설정에서 Vanilla는 21.43GB, Context2LoRA는 21.45GB, δ-mem TSW는 21.46GB로 제시된다.
다만 decoding throughput은 공짜가 아니다.
같은 32k/256 설정에서 Vanilla 22.50 TPS, Context2LoRA 16.40 TPS, δ-mem TSW 14.11 TPS다.
즉 δ-mem은 memory footprint는 작지만, 매 step마다 상태를 읽고 쓰는 recurrent 경로 때문에 throughput 비용은 남는다.
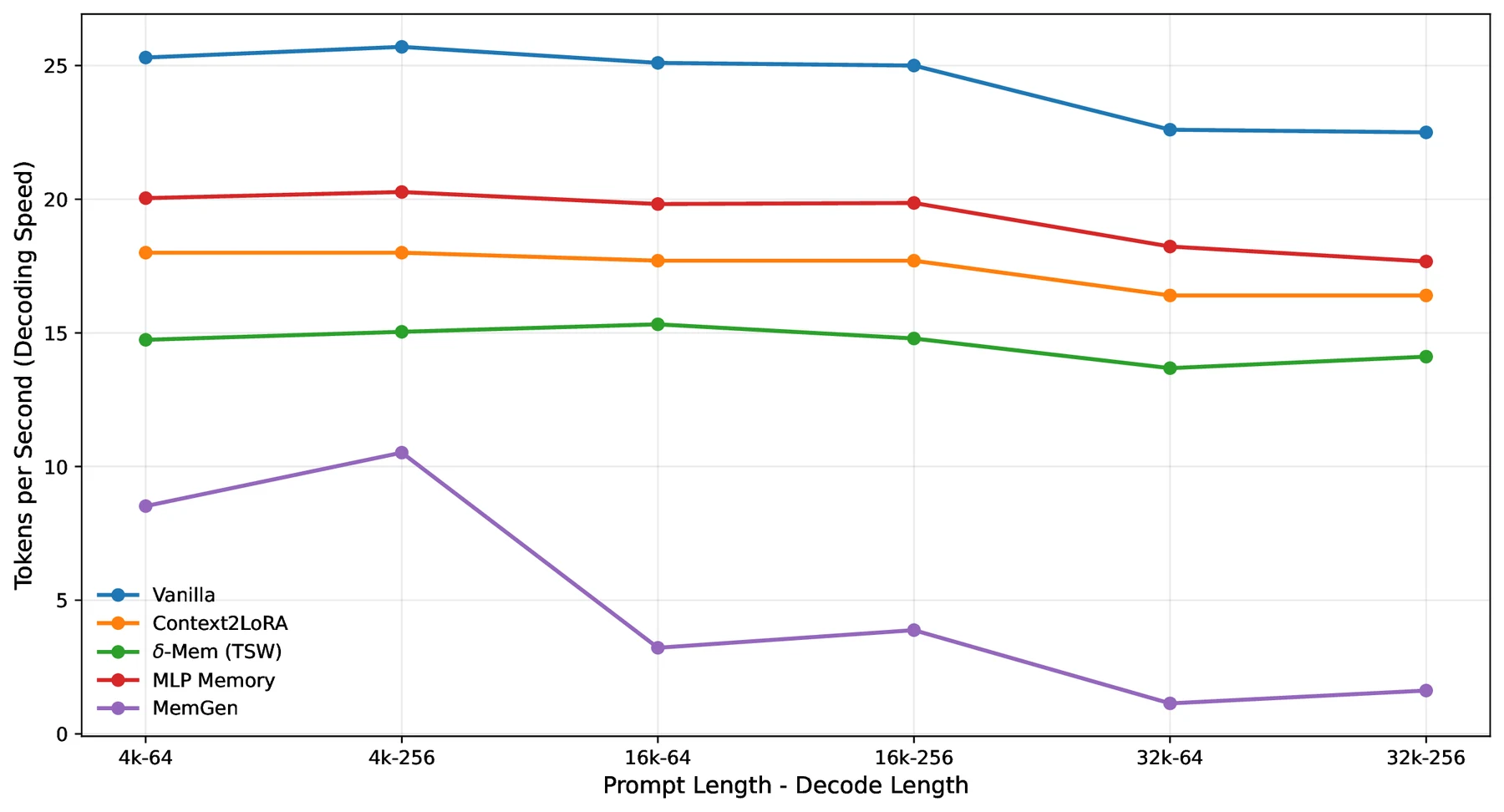
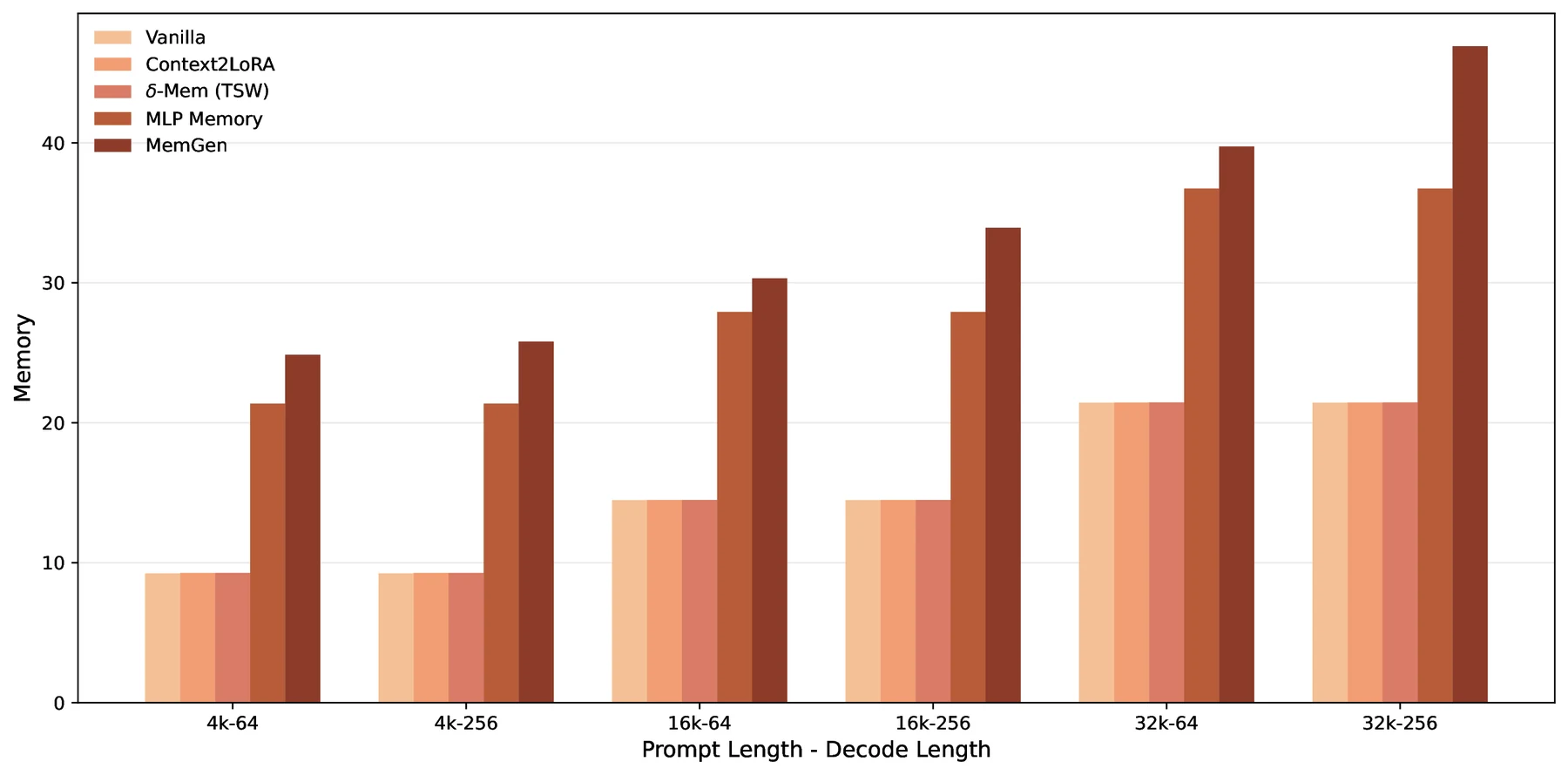
논문 source figure 기준 decoding throughput과 GPU memory 사용량. δ-mem은 memory usage에서는 Vanilla/Context2LoRA와 거의 비슷하지만, decoding speed는 상태 read/write 비용 때문에 더 느리다.
릴리스 표면도 꽤 구체적이다. arXiv source의 메타데이터는 declare-lab/delta-Mem과 MindLab-Research/delta-Mem 두 GitHub 링크를 노출하고, 현재 더 큰 공개 표면은 declare-lab/delta-Mem 쪽이다.
2026-05-24 조회 기준 이 저장소는 Python 중심 코드, training/evaluation scripts, interactive chat demo, runtime, tests, benchmark scripts를 포함한다.
GitHub API 기준 stars 158, forks 9이며, formal release와 tag는 아직 없다.
Hugging Face에는 declare-lab/delta-mem_qwen3_4b-instruct adapter가 공개되어 있다.
모델 카드와 config에 따르면 base model은 Qwen/Qwen3-4B-Instruct-2507, adapter rank는 8, delta heads는 q와 o, write granularity는 token, write length는 8,192다.
중요한 caveat는 이 adapter가 표준 PEFT LoRA가 아니라는 점이다.PeftModel로 바로 로드하거나 merge_and_unload()로 base model에 병합하는 방식이 아니라, δ-mem codebase의 runtime memory read/write path를 붙여야 한다.
| 공개 표면 | 확인되는 내용 | 실무 해석 |
|---|---|---|
| arXiv paper/source | 방법, 수식, benchmark table, 공식 figure | 논문 주장과 실험 수치의 1차 근거 |
GitHub declare-lab/delta-Mem |
구현, training/eval scripts, demo, tests, requirements | 단순 placeholder가 아니라 연구 artifact 형태의 코드 공개 |
| GitHub release/tags | formal release 없음, tag 없음 | 아직 패키지 안정성은 초기 단계로 봐야 함 |
| Hugging Face adapter | Qwen3-4B-Instruct용 TSW adapter, 약 11MB, CC-BY-4.0 card | 바로 merge 가능한 LoRA가 아니라 전용 runtime이 필요한 adapter |
| 라이선스 표면 | README/HF card는 CC-BY-4.0을 표시하지만 GitHub API license는 null, checked-in LICENSE 파일은 없음 | 사용 전 라이선스 파일과 배포 조건을 별도로 확인하는 편이 안전 |
실무 관점에서의 해석
δ-mem의 실용적 가치는 “컨텍스트를 줄여도 모든 기억 문제가 해결된다”가 아니다.
오히려 좋은 질문을 하나 더 만든다.
장기 assistant나 agent가 매번 모든 과거를 검색해 prompt에 붙일 필요가 있을까, 아니면 일부 history-dependent signal은 모델 내부의 작은 상태로 유지하고 attention 계산에 직접 반영할 수 있을까.
이 관점은 외부 memory store와 경쟁한다기보다 보완에 가깝다.
실제 제품에서는 여전히 원문 문서, tool result, audit log, user preference를 검색 가능한 저장소에 남겨야 한다.
하지만 매 토큰 생성마다 필요한 것은 원문 전체가 아니라 현재 reasoning에 영향을 줄 compact signal일 수 있다. δ-mem은 그 compact signal을 online associative state로 다루자는 모델 레벨의 답변이다.
agent memory 관점에서도 흥미롭다.
기존 agent memory는 대체로 “무엇을 저장할 것인가”와 “어떻게 검색할 것인가”에 집중한다. δ-mem은 한 단계 아래에서 “검색된 텍스트를 넣지 않아도 history가 현재 attention을 어떻게 바꾸는가”를 묻는다.
이것이 잘 작동한다면 장기 대화, 반복 작업, 개인화 assistant에서 prompt-level memory와 model-internal memory가 분업하는 구조가 가능해진다.
다만 도입 관점에서는 아직 조심해야 한다.
첫째, 공개 adapter는 Qwen3-4B-Instruct TSW 중심이고, 논문에 나온 모든 variant와 backbone 결과가 동일한 maturity로 패키징된 것은 아니다.
둘째, standard LoRA가 아니므로 serving stack에 전용 attach/load/runtime 경로를 넣어야 한다.
셋째, decoding throughput은 vanilla보다 낮다.
넷째, formal release/tag와 명시적인 GitHub LICENSE 파일이 아직 없기 때문에 production dependency로 보기에는 더 검증이 필요하다.
그래도 이 논문은 현재 LLM 메모리 논의에서 꽤 중요한 방향을 찌른다.
더 긴 컨텍스트, 더 큰 vector store, 더 똑똑한 retriever만으로는 agent의 장기 기억을 설명하기 어렵다.
앞으로는 컨텍스트 밖의 메모리뿐 아니라, frozen backbone 안으로 들어가는 작은 online state와 attention 보정 경로도 memory system 설계의 후보가 될 가능성이 크다. δ-mem은 그 가능성을 8×8 상태라는 극단적으로 작은 예시로 보여 준다.