오픈 언어 모델의 추론 병목은 이제 단순히 “모델이 큰가 작은가”만으로 설명되지 않는다.
실제 서비스에서는 batch size가 낮거나 사용자별 응답 지연이 중요한 구간에서, 오토리그레시브 모델의 token-by-token 생성이 GPU를 충분히 활용하지 못하는 문제가 계속 남는다.
그래서 speculative decoding, MTP, diffusion language model처럼 한 번의 forward에서 여러 토큰을 얻으려는 시도가 빠르게 늘고 있다.
NVIDIA의 Nemotron-Labs-Diffusion은 이 흐름을 하나의 모델 패밀리로 묶어 보려는 릴리스다.
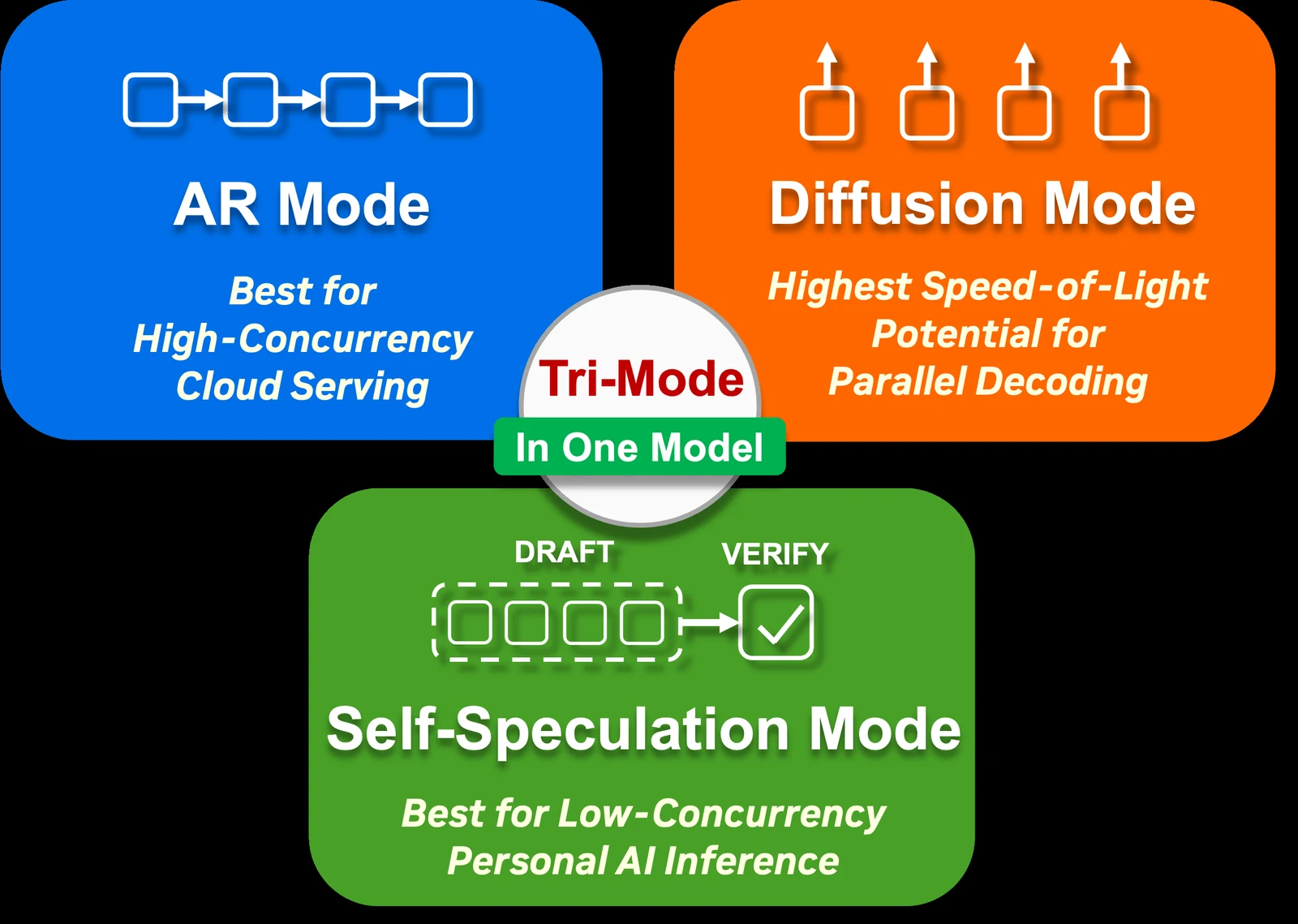
기술 보고서 제목 그대로 이 모델은 Autoregressive, Diffusion, Self-Speculation 세 가지 디코딩 모드를 하나의 아키텍처 안에서 통합한다.
핵심은 별도 draft model을 붙이는 대신, 동일한 모델이 attention pattern과 decoding procedure를 바꿔 가며 AR 모드, diffusion 모드, diffusion draft + AR verify 모드로 동작한다는 점이다.
Hugging Face collection 기준 공개 패키지는 3B·8B·14B 텍스트 모델, base/instruct 변형, 그리고 8B VLM 확장까지 포함한다.
따라서 이 릴리스는 “디퓨전 LM이 품질을 따라잡을 수 있는가”라는 논문 질문과 “저동시성 personal AI inference에서 실제 throughput을 얼마나 올릴 수 있는가”라는 시스템 질문을 동시에 다룬다.
무엇을 해결하려는가
기존 AR LLM의 강점은 명확하다.
자연어의 left-to-right prior와 instruction following, coding, math reasoning 같은 워크로드에서 검증된 학습 효율을 가진다.
문제는 생성이 엄격히 순차적이라는 점이다.
한 토큰을 만든 뒤에야 다음 토큰을 만들 수 있으므로, 단일 사용자 또는 낮은 동시성 환경에서는 메모리 대역폭과 GPU 연산 자원을 충분히 쓰지 못한다.
Diffusion LM은 반대 방향의 가능성을 보여 준다.
여러 토큰을 병렬적으로 복원하거나 denoising하면서 한 번의 forward에서 더 많은 후보 토큰을 만들 수 있다.
하지만 공개된 많은 diffusion LM은 AR 모델보다 정확도와 학습 효율에서 뒤처졌고, 실무적인 가속 기법으로는 MTP나 Eagle류 speculative decoding이 더 직관적인 선택지처럼 보였다.
Nemotron-Labs-Diffusion이 겨냥하는 지점은 이 둘을 경쟁 관계로 놓지 않는 것이다.
기술 보고서는 AR objective와 diffusion objective가 상호 보완적이라고 주장한다.
AR은 언어의 좌→우 prior를 제공하고, diffusion 학습은 미래 토큰을 미리 계획하는 능력을 강화한다.
그 결과 한 모델이 정확도가 중요한 구간에서는 AR처럼, 병렬성이 중요한 구간에서는 diffusion처럼, 실무 가속이 필요한 구간에서는 self-speculation처럼 움직일 수 있다는 것이 이 릴리스의 중심 메시지다.
핵심 아이디어 / 구조 / 동작 방식
Nemotron-Labs-Diffusion의 가장 중요한 설계는 mode-specific model을 따로 두지 않는 tri-mode decoding이다.
모델 카드와 기술 보고서를 종합하면 세 모드는 다음처럼 구분된다.
| 모드 | 동작 방식 | 적합한 구간 | 실무적 의미 |
|---|---|---|---|
| AR mode | causal attention으로 left-to-right 생성 | 고동시성 cloud serving, 기존 AR pipeline | 정확도와 호환성을 보존하는 기본 경로 |
| Diffusion mode | block-wise denoising으로 여러 토큰을 병렬 복원 | throughput/accuracy trade-off를 조정해야 하는 구간 | denoising threshold와 block size로 속도-품질 곡선을 움직임 |
| Self-Speculation mode | diffusion이 multi-token draft를 만들고 AR이 prefix를 검증 | 낮은 동시성, 개인 AI inference, batch size 1 | 별도 draft model 없이 동일 모델 내부에서 speculative decoding 수행 |
훈련도 이 구조에 맞춰 설계된다.
보고서에 따르면 base 모델은 Ministral3 base 계열에서 시작해 1T token의 pure AR continuous pretraining을 거친 뒤, 300B token의 joint AR-diffusion training을 수행한다.
이후 instruct 모델은 45B token의 SFT 데이터로 joint AR-diffusion objective를 유지한 채 학습된다.
보고서는 이때 diffusion loss weight α=0.3이 AR과 diffusion 양쪽에서 균형이 좋았다고 분석한다.
Self-speculation은 이 모델의 실무적 차별점이다.
일반적인 speculative decoding은 별도 작은 draft model이나 auxiliary head가 미래 토큰을 제안하고 큰 AR 모델이 검증한다.
Nemotron-Labs-Diffusion은 같은 모델의 diffusion mode가 block 단위 draft를 만들고, 같은 모델의 AR mode가 이를 검증한다.
모델 카드에는 linear_spec_lora adapter도 포함되어 있어 diffusion drafter와 AR verifier의 정렬을 가볍게 보정하는 경로가 제공된다.
VLM 확장도 같은 원리를 따른다.Nemotron-Labs-Diffusion-VLM-8B는 8B tri-mode 언어 백본에 Pixtral-style vision encoder와 multimodal projector를 붙인 형태다.
이미지 토큰은 bidirectional context window에 놓이고, 텍스트 생성은 같은 block-wise unmasking과 AR verification 경로를 따른다.
보고서는 vision token을 noisy half에 중복으로 싣지 않는 asymmetric dual-stream layout을 사용해, VLM에서 diffusion objective를 적용할 때의 불필요한 FLOPs를 줄였다고 설명한다.
공개된 근거에서 확인되는 점
Hugging Face collection API 기준 Nemotron-Labs-Diffusion collection은 7개 model item으로 구성되어 있고, collection 설명은 “Set of models of internal diffusion models”로 되어 있다.
API 조회 시점의 collection lastUpdated는 2026-05-19T18:45:01Z, upvotes는 34개다.
각 모델은 모두 public이며 gated: false로 표시된다.
| 모델 | API 기준 파라미터 | 태스크 | downloads | likes | 라이선스 표기 |
|---|---|---|---|---|---|
| Nemotron-Labs-Diffusion-3B | 3.83B | text-generation | 15,720 | 23 | NVIDIA Nemotron Open Model License |
| Nemotron-Labs-Diffusion-8B | 8.49B | text-generation | 27,346 | 21 | NVIDIA Nemotron Open Model License |
| Nemotron-Labs-Diffusion-14B | 13.51B | text-generation | 4,071 | 84 | NVIDIA Nemotron Open Model License |
| Nemotron-Labs-Diffusion-3B-Base | 3.83B | text-generation | 14,245 | 8 | NVIDIA Nemotron Open Model License |
| Nemotron-Labs-Diffusion-8B-Base | 8.49B | text-generation | 231,284 | 4 | NVIDIA Nemotron Open Model License |
| Nemotron-Labs-Diffusion-14B-Base | 13.51B | text-generation | 1,433 | 5 | NVIDIA Nemotron Open Model License |
| Nemotron-Labs-Diffusion-VLM-8B | 8.92B | image-text-to-text | 658 | 13 | NSCLv1 |
이 표에서 중요한 것은 단순 다운로드 수보다 패키징의 형태다.
모델 저장소에는 config.json, chat_template.jinja, tokenizer 파일, custom modeling_nemotron_labs_diffusion.py, configuration_nemotron_labs_diffusion.py, 그리고 safety/privacy/bias/explainability model card가 포함된다.
즉 표준 Transformers 인터페이스를 쓰되 trust_remote_code=True를 요구하는 공개 checkpoint bundle에 가깝다.
또한 텍스트 모델은 NVIDIA Nemotron Open Model License, VLM은 NSCLv1로 표시되어 있어 Apache/MIT류 범용 오픈소스 라이선스로 단순화해서 해석하면 안 된다.
성능 근거는 두 층으로 나뉜다.
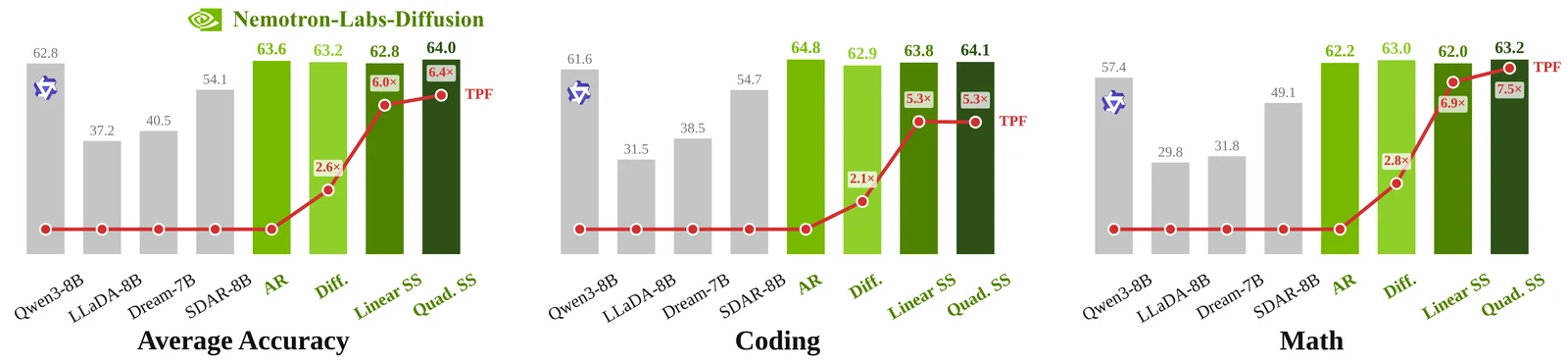
첫째, 8B instruct 모델은 공개 보고서의 10개 텍스트 benchmark 평균에서 AR mode 63.61, diffusion mode 63.18, linear self-speculation 62.81, quadratic self-speculation 64.04를 보고한다.
같은 표에서 Qwen3-8B 평균은 62.75다.
TPF(tokens per forward)는 AR mode 1.00, diffusion 2.57, linear self-speculation 5.99, quadratic self-speculation 6.38로 제시된다.
둘째, 실제 장비 throughput에서 self-speculation의 의미가 더 선명해진다.
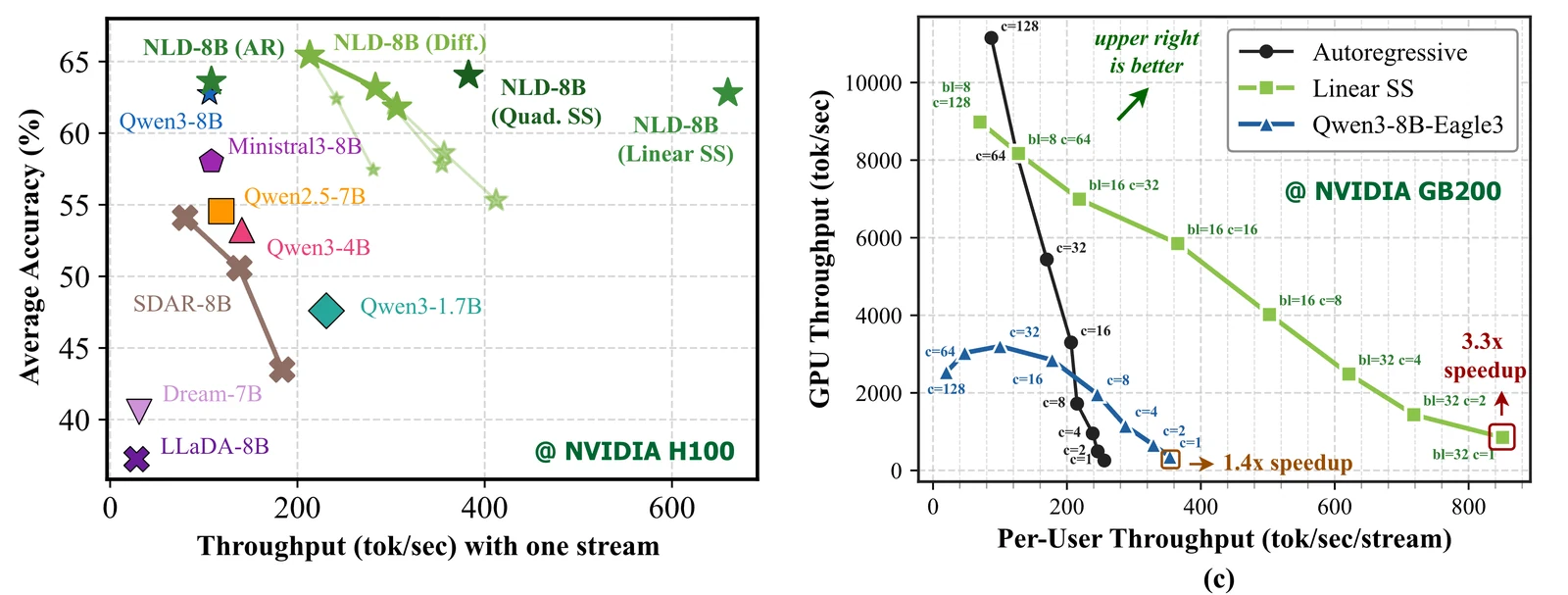
모델 카드와 보고서는 GB200에서 8B 모델의 linear self-speculation이 AR 대비 3.3배 speed-up을 보였고, custom CUDA kernel에서는 1015 tok/sec, 약 4배 speed-up까지 보고했다고 설명한다.
DGX Spark에서도 8B, concurrency 1 기준 w4a16에서 AR 41.8 tok/sec 대비 112 tok/sec로 2.7배 빠르다고 제시한다.
VLM 결과도 단순한 부록은 아니다.
보고서의 VLM benchmark 표는 AI2D, ChartQA, DocVQA, MMMU, MMMU-Pro, MathVista, RealWorldQA 등에서 diffusion VLM들과 비교한다.
Nemotron-Labs-Diffusion-VLM-8B는 AR mode 평균 59.5, linear self-speculation 평균 59.4로 거의 같은 정확도를 유지하면서, 응답 길이가 200 token을 넘는 샘플에서는 7.45× TPF를 보고한다.
이는 tri-mode 아이디어가 텍스트 전용 모델에만 닫혀 있지 않다는 근거다.
실무 관점에서의 해석
내가 보기에 이 릴리스의 핵심은 “디퓨전 LM이 AR을 대체한다”가 아니라 한 모델 안에서 AR과 diffusion을 운영 정책으로 선택할 수 있게 만든다는 점이다.
품질이 가장 중요한 구간에서는 AR로 두고, latency나 per-user throughput이 더 중요한 구간에서는 self-speculation을 켜며, 더 공격적인 병렬 decoding 연구는 diffusion mode에서 이어갈 수 있다.
이 구도는 모델 아키텍처와 서빙 정책을 분리하지 않고 함께 설계한다는 점에서 NVIDIA다운 접근이다.
특히 self-speculation은 MTP류 기법과 비교할 만한 실무적 포인트가 있다.
Eagle3나 MTP는 보통 별도 draft path의 capacity와 recursive proposal 비용에 묶인다.
Nemotron-Labs-Diffusion은 diffusion draft가 더 긴 acceptance length를 만들 수 있다고 주장하고, SPEED-Bench category 평균에서도 LoRA 보정 후 6.82 acceptance length, 네 개 핵심 category 평균 8.69를 보고한다.
같은 표에서 Qwen3-8B-Eagle3는 평균 2.75, Qwen3-9B-MTP는 4.24다.
다만 바로 “범용 배포형 완성품”으로 읽기에는 조심해야 한다.
첫째, 모델 카드의 inference 예제는 transformers>=5.0.0과 trust_remote_code=True를 요구한다.
운영 환경에서는 custom modeling code, attention mask, LoRA drafter, SGLang/커스텀 CUDA kernel 경로를 함께 검토해야 한다.
둘째, 보고서의 가장 강한 throughput 수치는 특정 하드웨어와 특정 serving stack, 특히 GB200·RTX Pro 6000·DGX Spark 및 SGLang/optimized kernel 조건에서 측정된 값이다.
셋째, 라이선스는 모델별로 NVIDIA custom license 계층이므로 상업적 재사용이나 재배포 정책을 별도로 확인해야 한다.
그럼에도 방향성은 중요하다.
최근 오픈 모델 릴리스는 모델 품질, long context, quantization, serving stack을 별도 항목으로 나열하는 경우가 많았다.
Nemotron-Labs-Diffusion은 여기에 decoding mode 자체를 모델 패밀리의 공개 surface로 만든다.
AR 정확도를 버리지 않으면서 diffusion의 병렬성을 가져오고, 그 중간 지점에서 self-speculation을 실무 가속기로 쓰려는 시도다.
앞으로 관찰할 지점은 세 가지다.
첫째, 보고서가 말한 “diffusion speed-of-light”와 실제 sampler 사이의 간극이 얼마나 줄어드는가.
둘째, SGLang·Transformers·Megatron Bridge 쪽 통합이 연구 코드 수준을 넘어 얼마나 안정적인 배포 경로로 굳어지는가.
셋째, VLM처럼 vision token이 섞인 환경에서도 self-speculation의 장점이 긴 reasoning 응답뿐 아니라 실제 멀티모달 제품 워크로드에서 유지되는가다.
요약하면 Nemotron-Labs-Diffusion은 또 하나의 NVIDIA 모델 카드라기보다, 언어 모델 디코딩을 AR 단일 경로에서 tri-mode 운영 문제로 확장한 실험적 공개 패키지에 가깝다.
정확도만 보면 incremental하게 보일 수 있지만, 동일 백본에서 AR 호환성, diffusion 병렬성, self-speculation 가속을 동시에 제공하려는 구조는 추론 시스템 관점에서 꽤 큰 신호다.
Sources:
- Hugging Face collection: https://huggingface.co/collections/nvidia/nemotron-labs-diffusion
- Technical report PDF: https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron_Diffusion_Tech_Report_v1.pdf?VersionId=db8_EMO8B.vmU26.jr7Le9pN3MqcUDNL
- Model card: https://huggingface.co/nvidia/Nemotron-Labs-Diffusion-8B
- VLM model card: https://huggingface.co/nvidia/Nemotron-Labs-Diffusion-VLM-8B
- NVIDIA Nemotron Open Model License: https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-nemotron-open-model-license/