멀티모달 LLM이 시각 문제를 풀 때 가장 익숙한 방식은 여전히 텍스트 Chain-of-Thought다.
이미지를 보고, 중간 추론을 문장으로 만들고, 마지막 답을 낸다.
이 방식은 사람이 읽을 수 있다는 장점이 있지만, 이미지 안의 세밀한 위치·형태·상대 관계를 모두 discrete token으로 압축해야 한다.Multimodal Continuous Reasoning via Asymmetric Mutual Variational Learning은 이 병목을 언어 공간 bottleneck으로 보고, 중간 추론을 텍스트가 아니라 연속 latent variable로 다루자는 쪽에 선다.
논문의 핵심은 AMVL, 즉 Asymmetric Mutual Variational Learning이다.
단순히 <latent> 토큰을 넣는 정도가 아니라, 학습 때는 정답을 함께 보는 posterior가 유용한 잠재 추론 상태를 찾고, 추론 때는 정답 없이 입력만 보는 prior가 그 상태를 재현하도록 만든다.
문제는 이 posterior가 정답을 본다는 점이다.
잘못 설계하면 posterior가 이미지 근거를 학습하기보다 정답에서 shortcut을 뽑아내고, prior는 추론 때 사용할 수 없는 그 shortcut까지 따라 하게 된다.
논문은 이를 answer leakage와 prior contamination으로 정식화하고, forward KL과 reverse KL을 비대칭으로 써서 줄이려 한다.
무엇을 해결하려는가
논문이 보는 출발점은 명확하다.
시각 추론은 원래 연속적인 지각 공간 위에서 일어난다.
퍼즐 조각의 배치, 물체의 상대 위치, 미세한 색·형태 차이, 여러 view 사이의 대응 관계는 자연어 문장 하나로 깔끔히 떨어지지 않는다.
그런데 현재 MLLM의 중간 추론은 대체로 텍스트 token sequence로 강제된다.
그러면 모델은 고차원 시각 정보를 언어 token으로 압축하고, 다시 그 token을 바탕으로 답을 내야 한다.
기존 latent reasoning 연구도 이 문제를 알고 있었다.
논문은 LVR, Monet, Mull-Tokens, Coconut류 접근이 discrete reasoning token을 연속 latent state로 바꾸려 했다고 정리한다.
하지만 저자들이 지적하는 약점은, 많은 방법이 reconstruction loss, alignment objective, predefined visual thought target처럼 사람이 정한 supervision에 기대어 latent가 무엇을 담아야 하는지 미리 지정한다는 점이다.
AMVL은 여기서 방향을 조금 바꾼다. latent state를 사람이 설계한 중간 목표가 아니라, 입력과 답 사이를 잇는 관측되지 않은 확률 변수로 놓고 variational inference로 학습한다.
문제는 variational inference를 그대로 가져오면 train-inference mismatch가 생긴다는 데 있다.
학습 때 posterior qφ(Z|x,y)는 입력 x뿐 아니라 정답 y도 본다.
하지만 실제 추론 때 prior pθ(Z|x)는 정답을 볼 수 없다.
표준 ELBO만 쓰면 prior는 posterior를 따라가도록 학습되는데, 그 posterior가 정답 의존 shortcut을 latent에 섞어 놓았다면 prior도 오염된다.
논문의 가장 좋은 질문은 바로 이것이다.
정답을 보고 찾은 좋은 latent reasoning path를 배우되, 정답을 봐서 생긴 leakage는 어떻게 막을 것인가?
핵심 구조: posterior를 배우되, posterior를 너무 믿지 않는다
AMVL은 중간 추론을 연속 latent sequence Z = [z1, ..., zk] ∈ R^{k×d}로 둔다.
조건부 생성은 pθ(y|x,Z)와 pθ(Z|x)를 통해 표현되고, 학습 때는 posterior qφ(Z|x,y)가 들어온다.
이때 두 분포의 역할이 다르다.
- prior
pθ(Z|x): 추론 때 실제로 쓰는 분포다. 정답 없이 입력만 보고 latent reasoning state를 만들어야 한다. - posterior
qφ(Z|x,y): 학습 때만 쓰는 분포다. 정답을 참고해 “이 문제를 맞히는 데 유용했을 법한” latent state를 찾는다. - decoder
pθ(y|x,Z): 입력과 latent state를 조건으로 답을 생성한다.
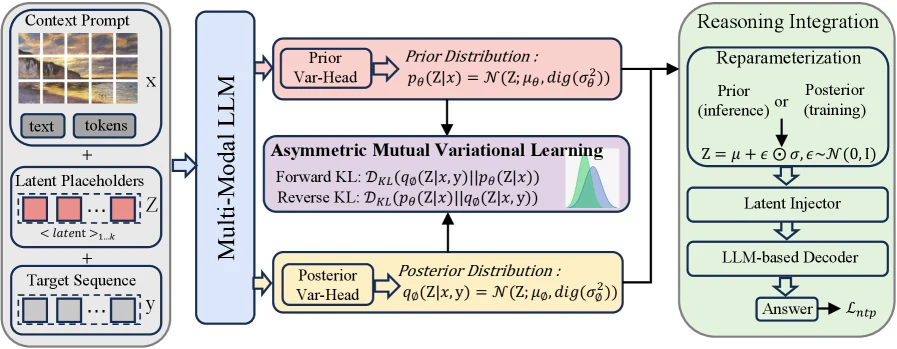
AMVL의 비대칭성은 두 KL loss에서 나온다.
| 항목 | 업데이트 대상 | 역할 | 직관 |
|---|---|---|---|
| Forward prior alignment | prior | `KL(sg[qφ(Z | x,y)] |
| Reverse posterior regularization | posterior | `KL(sg[pθ(Z | x)] |
| Next-token prediction | decoder/model | posterior sample을 조건으로 답 생성 | latent가 실제 answer likelihood에 도움이 되도록 한다 |
여기서 sg는 stop-gradient다.
Forward KL에서는 posterior 쪽 gradient를 끊어 prior만 움직인다.
Reverse KL에서는 prior 쪽 gradient를 끊어 posterior만 규제한다.
즉 AMVL은 posterior를 유용한 teacher로 쓰지만, 그 teacher가 정답을 훔쳐보는 방향으로 과하게 움직이면 reverse KL로 다시 잡아당긴다.
구현은 Qwen2.5-VL-7B-Instruct 위에 비교적 가볍게 얹힌다.
입력 sequence는 [x, <latent>1, ..., <latent>k, y]처럼 구성되고, latent placeholder 위치의 final hidden state가 Gaussian parameter를 만든다. prior와 posterior는 모두 diagonal Gaussian으로 두어 closed-form KL을 계산한다.
기본 설정은 k=8 latent token, latent dimension d=512다.
논문은 vision encoder를 freeze하고 language backbone과 variational module을 함께 최적화한다고 설명한다.
최종 loss는 L_total = L_NTP + β L_fwd + γ L_rev다. β와 γ는 고정값으로만 두지 않고 스케줄링한다.
논문의 설명에 따르면 forward KL weight β를 먼저 warm-up해 prior가 posterior를 어느 정도 따라잡게 한 뒤, reverse KL weight γ를 지연 도입하고 더 약하게 둔다.
초반부터 posterior를 세게 묶어 버리면 아직 약한 prior 때문에 latent가 과하게 억제될 수 있기 때문이다.
숫자로 보면: BLINK에서 평균 +10.83
실험은 세 축으로 구성된다. fine-grained perception은 V*, HRBench4K, HRBench8K에서 보고하고, 복잡한 visual reasoning은 BLINK의 vision-centric task들로 본다.
OOD robustess는 Appendix의 VisualPuzzles로 확인한다.
학습 데이터는 Visual-CoT, ReFocus, CogCoM, Zebra-CoT 같은 멀티모달 reasoning mixture다.
첫 번째 결과는 V*, HRBench4K, HRBench8K다.
같은 Qwen2.5-VL-7B 기반 baseline과 비교하면 AMVL의 Ours-7B는 세 benchmark Overall 평균 74.97을 기록한다.
Qwen2.5-VL-7B baseline의 69.40보다 +5.57이고, Monet의 74.08, DeepEyes의 73.21보다도 높다.
| 모델 | V* Overall | HRBench4K Overall | HRBench8K Overall | 평균 |
|---|---|---|---|---|
| Qwen2.5-VL-7B | 76.44 | 68.00 | 63.75 | 69.40 |
| DeepEyes | 83.25 | 71.25 | 65.13 | 73.21 |
| PixelReasoner | 81.15 | 72.00 | 66.12 | 73.09 |
| Mull-Tokens | 79.06 | 70.25 | 65.75 | 71.69 |
| Monet | 83.25 | 71.00 | 68.00 | 74.08 |
| AMVL Ours-7B | 84.29 | 72.12 | 68.50 | 74.97 |
| Qwen2.5-VL-7B 대비 | +7.85 | +4.12 | +4.75 | +5.57 |
BLINK 쪽 결과가 더 강하다.
AMVL은 평균 66.91로 Qwen2.5-VL-7B의 56.08보다 +10.83 높다.
특히 Jigsaw는 45.33에서 77.33으로 올라 +32.00이다.
Spatial Relation은 Qwen2.5-VL-7B와 같은 88.81이라 모든 항목이 오른 것은 아니지만, IQ Test, Jigsaw, Object Localization, Multi-view Reasoning, Visual Similarity에서 큰 개선이 보인다.
| 모델 | IQ Test | Jigsaw | Object Loc. | M-View | Visual Sim. | BLINK 평균 |
|---|---|---|---|---|---|---|
| Qwen2.5-VL-7B | 20.00 | 45.33 | 49.18 | 41.35 | 82.96 | 56.08 |
| Vision-R1 | 27.33 | 54.67 | 48.36 | 45.86 | 71.85 | 56.23 |
| PixelReasoner | 26.00 | 72.00 | 54.10 | 46.62 | 85.93 | 62.70 |
| PAPO | 22.67 | 66.67 | 56.56 | 49.62 | 85.19 | 62.27 |
| Mull-Tokens | 31.33 | 69.33 | 47.54 | 60.15 | 80.74 | 62.30 |
| AMVL Ours-7B | 32.67 | 77.33 | 54.92 | 55.64 | 88.89 | 66.91 |
| Qwen2.5-VL-7B 대비 | +12.67 | +32.00 | +5.74 | +14.29 | +5.93 | +10.83 |
이 숫자를 “latent가 항상 텍스트 CoT보다 우월하다”로 읽으면 과하다.
하지만 이 논문 안의 비교 프레임에서는 흥미로운 신호가 있다.
PixelReasoner나 DeepEyes처럼 discrete generation 안에 시각 도구·시각 중간 산출물을 섞는 방법도 강하지만, AMVL은 중간 상태를 text/tool trace로 외부화하기보다 latent distribution으로 보정했을 때 복잡한 시각 퍼즐에서 꽤 큰 폭으로 오른다.
Ablation이 보여 주는 것: KL만으로는 안 되고, 양방향 보정이어야 한다
AMVL에서 가장 중요한 ablation은 objective 조합이다.NTP only는 V* 81.15, HRBench4K 70.50, HRBench8K 67.38이다.
여기에 forward KL과 reverse KL을 모두 넣고 forward-first로 최적화하면 V* 84.29, HRBench4K 72.12, HRBench8K 68.50까지 올라간다.
| 학습 objective | V* | HRBench4K | HRBench8K | 해석 |
|---|---|---|---|---|
| NTP only | 81.15 | 70.50 | 67.38 | latent를 쓰지만 prior/posterior mismatch가 남음 |
| Fwd-KL only | 40.84 | 53.37 | 52.00 | 답 생성 objective 없이 KL만 두면 붕괴에 가까움 |
| Rev-KL only | 75.92 | 69.62 | 64.38 | posterior를 묶지만 유용한 answer-conditioned 학습 신호가 약함 |
| NTP + Fwd-KL | 82.72 | 72.12 | 67.75 | prior alignment는 도움이 되지만 leakage를 완전히 막지 못함 |
| NTP + Rev-KL | 82.20 | 71.75 | 67.25 | posterior drift는 줄지만 prior가 posterior의 좋은 경로를 충분히 못 배움 |
| NTP + Fwd + Rev, reverse-first | 80.63 | 72.38 | 68.25 | 순서가 성능에 영향을 줌 |
| NTP + Fwd + Rev, forward-first | 84.29 | 72.12 | 68.50 | 논문의 기본 AMVL 설정 |
이 표에서 중요한 것은 “KL을 추가하면 무조건 좋아진다”가 아니다.
Forward만 있으면 posterior가 여전히 정답 shortcut을 섞을 수 있고, reverse만 있으면 posterior가 너무 보수적으로 묶일 수 있다.
또한 forward-first가 reverse-first보다 V*에서 훨씬 낫다.
논문의 training schedule 설명과 맞춰 보면, 먼저 prior가 posterior를 어느 정도 따라가게 한 뒤 posterior를 규제하는 순서가 안정적인 셈이다.
latent configuration도 비슷한 메시지를 준다. latent token 수는 4개보다 8개가 뚜렷하게 낫고, 16개로 늘린다고 계속 오르지는 않는다.
V* 기준 4 tokens는 76.44, 8 tokens는 84.29, 16 tokens는 81.15다. latent dimension도 d=512가 기본으로 선택되지만, 모든 benchmark에서 항상 최고는 아니다.
즉 AMVL의 성과는 “latent를 크게 만들면 된다”가 아니라, reasoning에 필요한 충분한 latent capacity와 regularization의 균형에서 나온다.
latent가 실제로 뭔가를 보고 있는가
논문은 latent token의 성질도 일부 분석한다.
Figure 3에서는 token-level relevance heatmap을 통해 latent representation이 입력의 시각/텍스트 요소와 어떻게 연결되는지 보이고, Figure 4에서는 latent token 간 cosine similarity와 image/text permutation sensitivity를 분석한다.
저자들의 해석은 AMVL이 단순히 답 token을 암기하는 것이 아니라, 이미지와 텍스트 perturbation에 반응하는 구조화된 latent space를 만든다는 쪽이다.
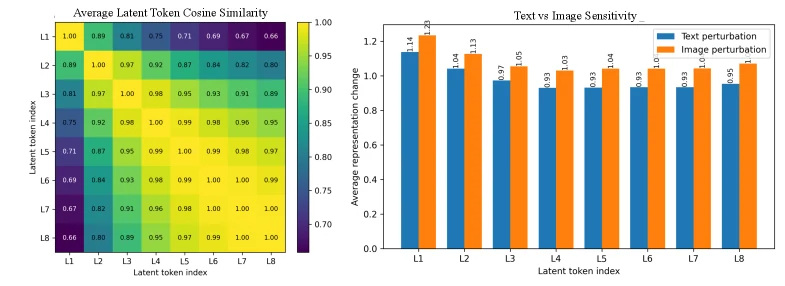
다만 이 부분은 아직 “해석 가능성이 완전히 확보됐다”기보다, latent space가 무작위 압축이나 정답 암기만은 아닐 가능성을 보여 주는 정도로 읽는 게 안전하다.
연속 latent reasoning은 텍스트 CoT보다 사람이 직접 읽기 어렵다.
AMVL이 answer leakage를 줄이는 이론과 empirical signal을 제공하긴 하지만, latent state가 어떤 의미 단위를 담는지까지 투명하게 설명하는 것은 별도의 문제다.
OOD 결과도 비슷하게 조심해서 봐야 한다.
Appendix의 VisualPuzzles에서는 AMVL이 33.90으로 비교군 중 가장 높다고 보고된다. temperature sensitivity 실험에서도 VisualPuzzles는 τ=0.2에서 34.50까지 올라가지만, τ=1.0에서는 32.71로 내려간다.
즉 latent sampling은 어느 정도 robust하지만, sampling temperature에 완전히 무관한 deterministic improvement는 아니다.
공개 artifact 관점
확인 가능한 공식 표면은 현재 Hugging Face Papers 페이지와 arXiv 논문이다. arXiv abstract page의 Code/Data/Media 영역과 제목 기준 웹 검색에서는 별도 공식 GitHub 저장소나 모델 weight 배포를 확인하지 못했다.
따라서 이 글을 쓰는 시점에서 AMVL은 바로 설치해 실험할 수 있는 공개 코드 릴리스라기보다, 방법론과 실험 결과가 공개된 paper-first 연구로 보는 편이 맞다.
이 점은 실무 적용 관점에서 중요하다.
AMVL을 재현하려면 Qwen2.5-VL-7B-Instruct 기반 학습 파이프라인, latent token 확장, variational head, KL schedule, Visual-CoT/ReFocus/CogCoM/Zebra-CoT류 데이터 mixture, 그리고 V*/HRBench/BLINK/VisualPuzzles 평가를 모두 갖춰야 한다.
논문 Appendix는 구현 세부를 많이 설명하지만, 공개 코드 없이 그대로 검증하려면 여전히 상당한 엔지니어링이 필요하다.
또 하나의 한계는 scale이다.
논문 스스로도 empirical validation이 7B parameter scale에 제한되어 있다고 적는다.
70B+급 foundation model에서 AMVL이 같은 비율로 작동하는지, 더 큰 모델에서는 latent reasoning structure가 자연스럽게 emergent해 reverse KL의 역할이 달라지는지, 혹은 더 큰 모델이 오히려 answer leakage를 더 잘 숨기는지는 아직 열린 질문이다.
실무적으로 읽을 포인트
내가 보기에 AMVL의 의미는 “텍스트 CoT를 버리자”가 아니라, 시각 추론의 중간 상태를 꼭 사람이 읽는 문장으로만 둘 필요는 없다는 점을 더 정교하게 보여 준다는 데 있다.
텍스트 CoT는 디버깅과 설명에는 좋지만, 시각 geometry나 dense perception을 담는 매체로는 손실이 크다.
반대로 연속 latent는 표현력은 좋지만, answer leakage와 해석 가능성 문제가 생긴다.
AMVL은 이 trade-off에서 posterior/prior calibration이라는 꽤 깔끔한 해법을 제시한다.
제품·연구 관점에서는 네 가지 질문으로 이어진다.
| 관점 | AMVL이 던지는 질문 | 실무적 해석 |
|---|---|---|
| 멀티모달 reasoning | 중간 생각을 꼭 텍스트로 출력해야 하나 | 내부 latent reasoning과 외부 explanation을 분리하는 구조가 유망할 수 있음 |
| 학습 안정성 | 정답을 보는 posterior를 어디까지 믿을 수 있나 | hindsight supervision은 강력하지만 leakage control이 필요함 |
| 평가 | 평균 점수만 보면 충분한가 | BLINK 세부 task, OOD puzzle, latent sensitivity처럼 failure mode별 확인이 필요함 |
| 배포 | latent reasoning이 inference cost를 줄이나 | 논문은 성능 중심이고, 실제 latency/throughput 이득은 별도 구현 검증이 필요함 |
AMVL이 특히 흥미로운 이유는 latent reasoning을 “mystical hidden thought”처럼 포장하지 않는다는 점이다. prior, posterior, KL, stop-gradient, schedule이라는 익숙한 확률모델링 언어로 문제를 쪼갠다.
그래서 논문이 강한 주장을 하면서도, 어디가 위험한지 비교적 선명하다. posterior는 정답을 본다.
그러니 leakage가 생긴다. prior는 추론 때 정답을 못 본다.
그러니 posterior를 그대로 따라가면 안 된다.
이 단순한 구조화가 AMVL의 장점이다.
결론: “보이는 것을 말하게 하기”보다 “보이는 상태를 보정하게 하기”
AMVL은 멀티모달 reasoning에서 텍스트 CoT 중심 사고를 한 번 더 흔든다.
시각 문제의 중간 상태를 문장으로 모두 풀어내려 하면 표현력이 제한되고, 기존 latent reasoning처럼 사람이 정한 supervision으로만 latent를 잡으면 discovery가 제한된다.
AMVL은 posterior가 정답을 보고 유용한 latent path를 찾게 하되, reverse KL로 그 posterior가 추론 때 도달 불가능한 shortcut으로 도망가지 못하게 한다.
결과는 논문 기준 꽤 설득력 있다.
Qwen2.5-VL-7B 기반에서 V*/HRBench 평균 +5.57, BLINK 평균 +10.83, Jigsaw +32.00은 단순한 noise로 보기는 어렵다.
동시에 공개 코드와 weight가 확인되지 않고, 7B scale 중심이며, latent 해석 가능성은 아직 제한적이다.
따라서 지금의 AMVL은 “바로 가져다 쓰는 모델”보다, 앞으로 MLLM이 복잡한 시각 추론을 할 때 언어 token과 연속 latent를 어떻게 분업시킬지를 보여 주는 중요한 설계 신호에 가깝다.