스마트폰에서 LLM을 돌린다는 이야기는 더 이상 “작은 모델을 어떻게든 올려 봤다”는 데모만으로는 충분하지 않다.
실제 제품 관점에서는 세 가지가 함께 맞아야 한다.
첫째, 모델을 특정 용도에 맞게 학습하거나 파인튜닝할 수 있어야 한다.
둘째, 모바일 메모리와 저장공간에 맞도록 양자화되어야 한다.
셋째, iOS와 Android 앱이 이해하는 런타임 포맷으로 내려가야 한다.
이 세 단계 중 하나라도 끊기면 로컬 LLM은 연구 노트북이나 CLI 실험에 머문다.
Unsloth의 “How to Run and Deploy LLMs on your iOS or Android Phone” 문서는 이 끊긴 고리를 하나의 절차로 묶는다.
Unsloth로 Qwen3-0.6B를 파인튜닝하고, TorchAO 기반 QAT로 모바일용 양자화 노이즈를 학습 중에 반영한 뒤, ExecuTorch의 .pte 파일로 export해 iPhone과 Android 기기의 데모 앱에 올리는 흐름이다.
문서의 headline은 Qwen3-0.6B를 Pixel 8과 iPhone 15 Pro급 기기에서 약 40 tokens/s로 실행하는 데모이고, 더 큰 Qwen3-4B가 iPhone에서 도는 예시도 함께 보여 준다.
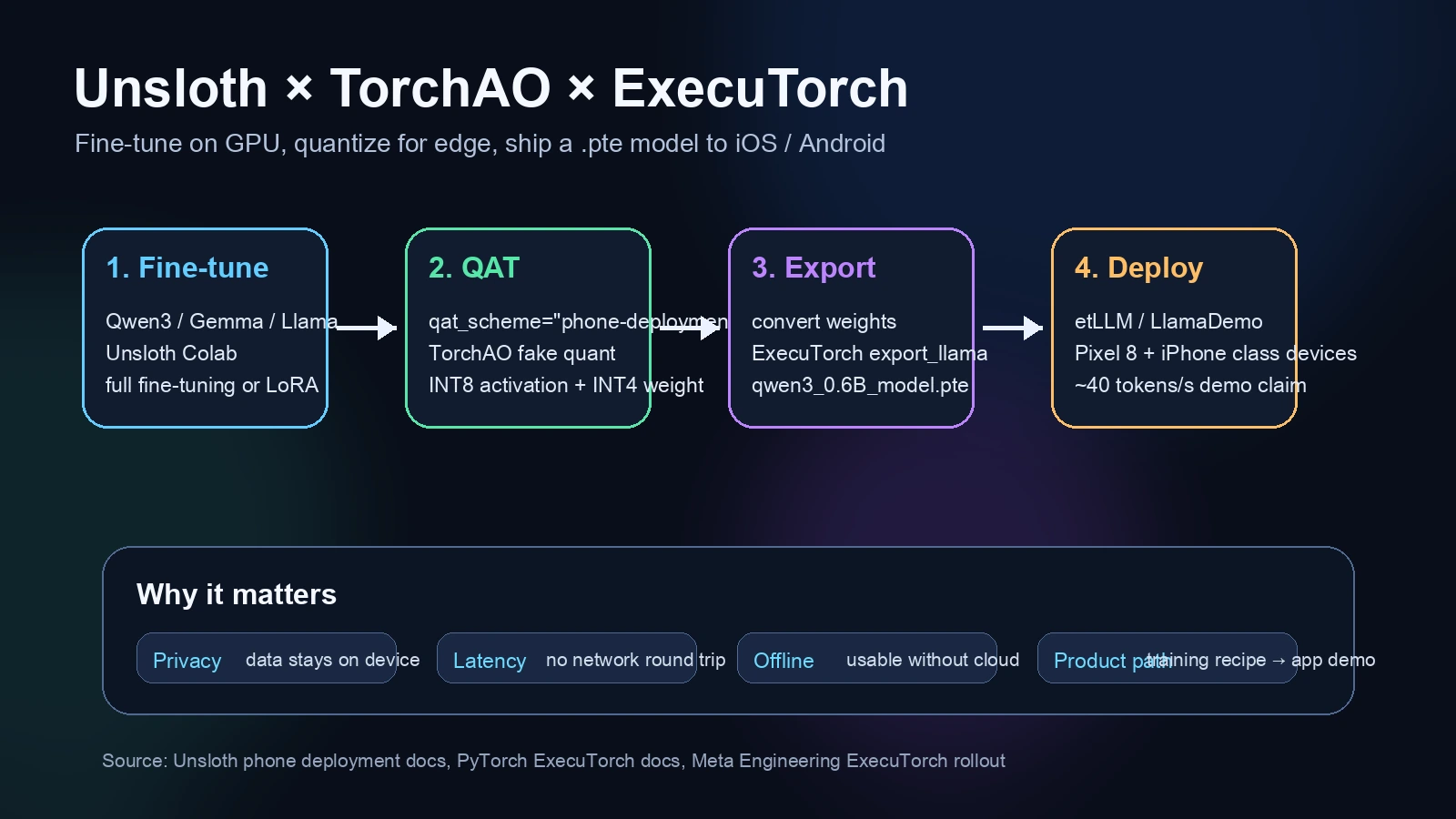
무엇이 새롭나: 모델 파일 하나가 아니라 배포 경로를 제시한다
이 문서가 흥미로운 이유는 Unsloth가 단순히 “Qwen3가 휴대폰에서 돌아간다”고 말하지 않기 때문이다.
공개된 절차는 학습 단계부터 앱 실행까지 이어진다.
무료 Colab notebook에서 FastLanguageModel.from_pretrained를 호출할 때 qat_scheme = "phone-deployment"를 지정하고, 학습이 끝난 뒤 ExecuTorch가 기대하는 weight key로 변환한 다음 export_llama로 .pte 모델을 만든다.
문서 예시의 qwen3_0.6B_model.pte는 약 472MB라고 설명된다.
핵심은 phone-deployment라는 단어가 실제로는 TorchAO 쪽 int8-int4 QAT 경로를 감싼다는 점이다.
문서에 따르면 이 설정은 Linear layer에 대해 activation은 INT8 dynamic quantization, weight는 INT4 quantization이 적용될 상황을 학습 중 fake quantization으로 시뮬레이션한다.
계산 자체는 16-bit 경로에 남아 있지만, 모델은 양자화될 때 생기는 오차를 미리 경험한다.
학습 이후에는 실제 quantized model로 변환되어 모바일에서 더 작은 모델로 동작한다.
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen3-0.6B",
max_seq_length = 1024,
full_finetuning = True,
qat_scheme = "phone-deployment",
)
Unsloth의 별도 QAT 글은 이 접근을 “post-training quantization보다 정확도 손실을 줄이는 훈련 가능한 양자화”로 설명한다.
문서의 표현을 그대로 빌리면 QAT는 quantization으로 잃은 정확도의 최대 70%를 회복할 수 있고, 추론 시 추가 오버헤드 없이 같은 disk/memory footprint를 목표로 한다.
이 수치는 모델과 task에 따라 달라지는 headline으로 읽어야 하지만, 모바일 배포에서는 방향성이 중요하다.
0.6B급 작은 모델이라도 용도별 fine-tuning과 QAT를 거치면 “그냥 줄인 모델”보다 훨씬 제품화하기 쉬워진다.
| 단계 | 도구 | 산출물 | 모바일 배포에서의 의미 |
|---|---|---|---|
| Fine-tuning | Unsloth Colab / FastLanguageModel |
목적에 맞게 조정된 Qwen3 계열 모델 | 작은 모델의 범용 한계를 task-specific 품질로 보완 |
| QAT | TorchAO, qat_scheme="phone-deployment" |
INT8 activation + INT4 weight 경로를 견딘 model | PTQ보다 양자화 후 품질 손실을 줄이는 방향 |
| Export | ExecuTorch convert_weights, export_llama |
.pte 모델 파일과 tokenizer |
PyTorch 모델을 모바일 edge runtime이 읽는 포맷으로 변환 |
| App deploy | iOS etLLM, Android LlamaDemo | 기기 안에서 로드되는 로컬 LLM | 개인정보, 지연시간, 오프라인 사용성을 제품 기능으로 전환 |
40 tokens/s의 의미: “서버 없이 쓸 만한 체감 속도”
문서가 전면에 둔 숫자는 Qwen3-0.6B가 Pixel 8과 iPhone 15 Pro에서 약 40 tokens/s로 돈다는 주장이다.
이 숫자는 범용 benchmark라기보다 특정 모델, context length, export option, 앱 경로에서의 데모 수치로 보는 것이 맞다.
그래도 사용자 경험 관점에서는 충분히 의미가 있다.
대화형 UI에서 40 tokens/s는 “천천히 찍히는 실험”이 아니라, 짧은 답변과 command-style assistant에는 꽤 자연스러운 속도다.
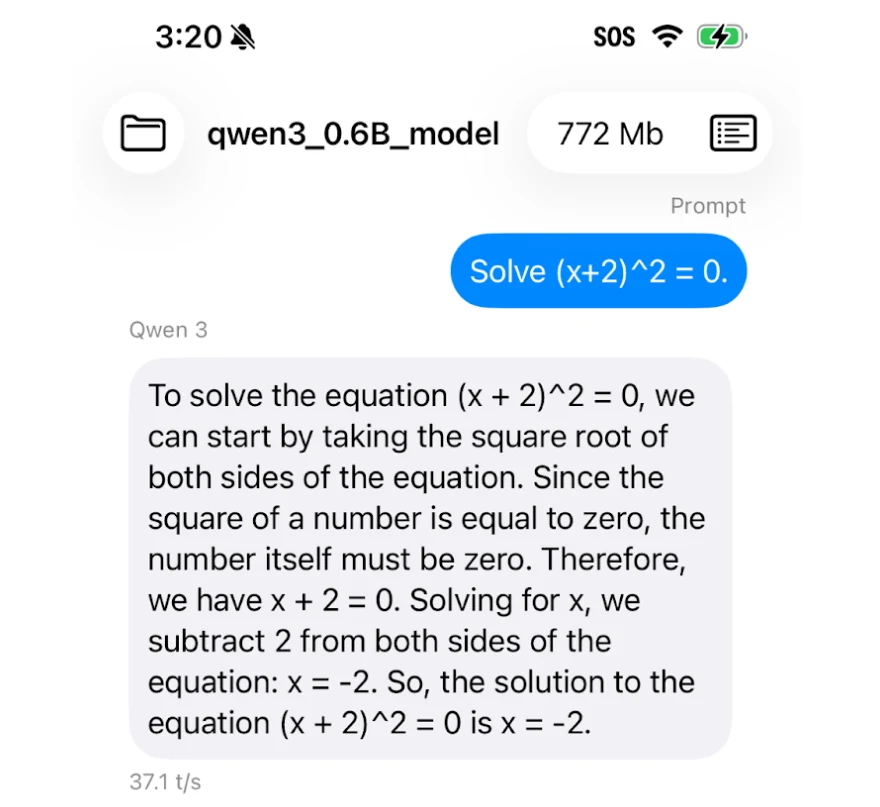
다만 이 데모를 “스마트폰이 곧바로 서버급 LLM을 대체한다”로 읽으면 안 된다.
Qwen3-0.6B는 작은 모델이고, 문서의 export 예시는 --max_context_length 1024, --max_seq_length 128, --dtype fp32, -kv, --use_sdpa_with_kv_cache, --xnnpack-extended-ops 같은 매우 구체적인 선택 위에 있다.
즉 성능은 모델 크기, context, tokenizer, backend, temperature, prompt length, 기기 발열 상태에 민감하다.
오히려 이 글의 메시지는 “작은 모델도 이제 학습과 배포 경로가 연결되면 제품 기능으로 쓸 수 있다”에 가깝다.
서버 호출이 필요 없으면 privacy-sensitive task, 오프라인 assistant, device-local automation, 현장 장비용 대화 UI 같은 영역이 열린다.
반대로 거대한 reasoning, 긴 문서 분석, 다중 도구 호출, 최신 지식 검색은 여전히 cloud 또는 더 큰 로컬 기기의 몫으로 남는다.
iOS 경로: Xcode 앱에 .pte와 tokenizer를 넣는 방식
Unsloth 문서의 iOS 경로는 Meta/PyTorch의 executorch-examples에 있는 Apple LLM 예제 앱을 사용한다.
개발자는 executorch-examples-main/llm/apple을 받아 apple/etLLM.xcodeproj를 Xcode에서 열고, simulator 또는 physical iPhone 대상으로 빌드한다.
Simulator만 쓴다면 Apple Developer Program 가입이 필요 없지만, 실제 iPhone 배포에서는 signing과 capability 문제가 바로 등장한다.
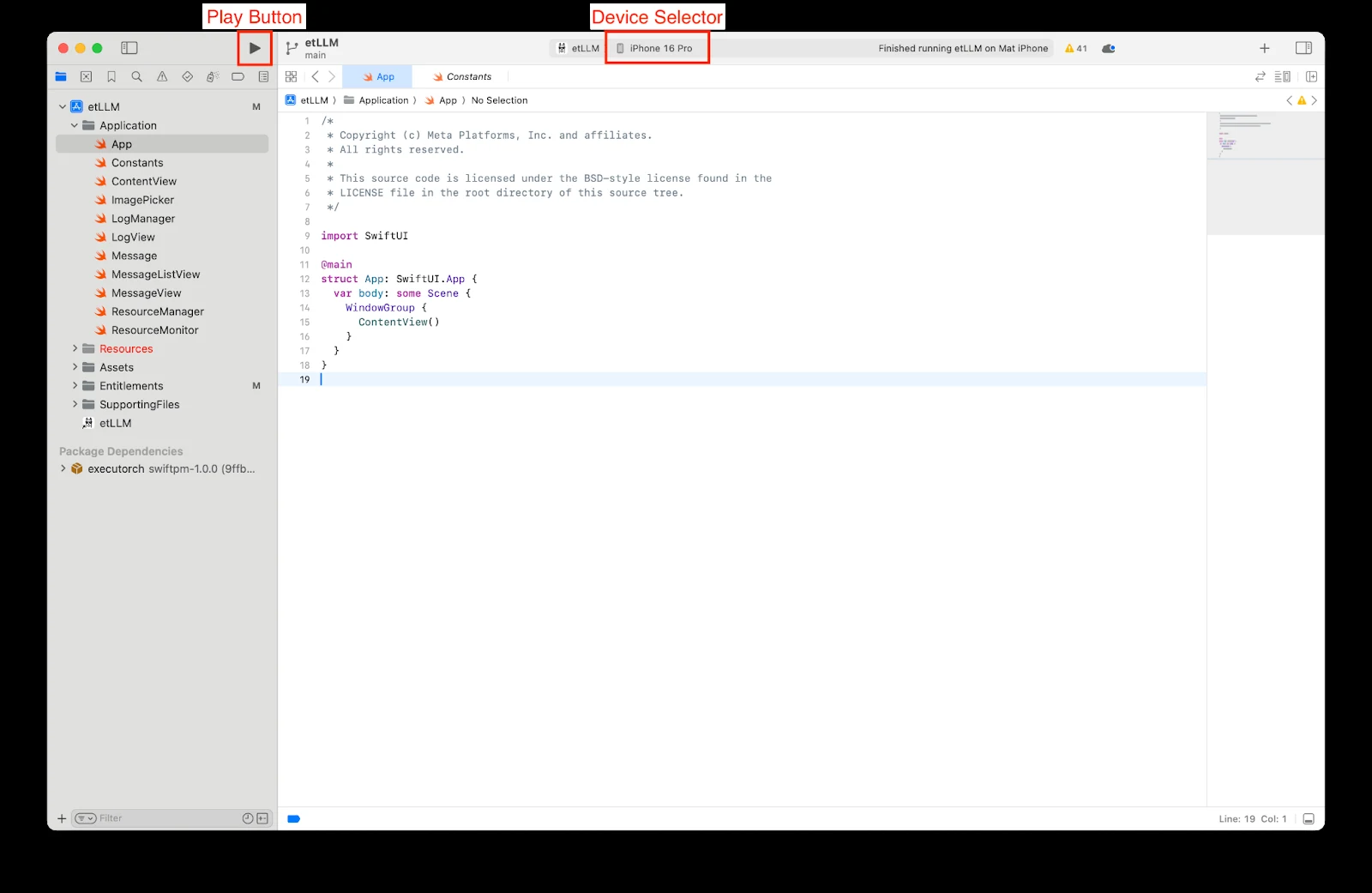
문서가 특히 강조하는 부분은 physical iPhone에서 increased-memory-limit capability가 필요하다는 점이다.
이 capability 때문에 paid Apple Developer account가 요구된다고 설명한다.
또한 bundle identifier를 고유하게 바꾸는 것이 provisioning profile 오류의 대부분을 해결한다고 적는다.
모바일 LLM 배포에서 “모델이 돌아가느냐”만큼 중요한 것이 이런 플랫폼 권한과 배포 마찰이다.
파일 전달 방식도 simulator와 physical device가 다르다.
Simulator에서는 Files app 안에 Qwen3test 같은 공유 폴더를 만들고, macOS의 CoreSimulator directory를 찾아 tokenizer.json과 qwen3_model.pte를 복사한다.
실제 iPhone에서는 Finder의 Files 탭에서 etLLM app container에 .pte와 tokenizer 파일을 drag-and-drop한다.
즉 iOS 예제는 App Store 배포용 완성 제품이라기보다, “ExecuTorch 앱이 모델 파일을 읽고 대화까지 가는 최소 경로”에 가깝다.

Android 경로: Android Studio 없이도 LlamaDemo APK를 만든다
Android 쪽은 command-line 중심이다.
문서는 Java 17, Git, wget/curl, Android command-line tools, adb를 요구하고, SDK 34와 NDK 25.0.8775105를 설치하는 절차를 제시한다.
전체 Android Studio를 설치하지 않아도 executorch-examples의 llm/android/LlamaDemo를 Gradle로 build해 debug APK를 만들 수 있다는 점을 장점으로 둔다.
절차는 다음처럼 정리된다.ANDROID_HOME과 ANDROID_NDK를 잡고, sdkmanager로 platform-tools/build-tools/NDK를 설치한 뒤, ./gradlew :app:assembleDebug로 APK를 만든다.
그 다음 adb install -r app/build/outputs/apk/debug/app-debug.apk로 설치한다.
문서에는 Java 버전이 17이어야 한다는 점, SDK location 문제는 local.properties로 잡는다는 점, 일부 deprecated method 오류는 patch할 수 있다는 troubleshooting도 들어 있다.
모델 파일은 Android의 일반 file manager로 접근하기 어려운 directory에 넣는 흐름이다.
문서는 adb shell mkdir -p /data/local/tmp/llama와 chmod 777으로 directory를 만들고, adb push로 .pte와 tokenizer.json을 복사한 뒤, 앱 settings에서 model과 tokenizer를 각각 선택하라고 안내한다.
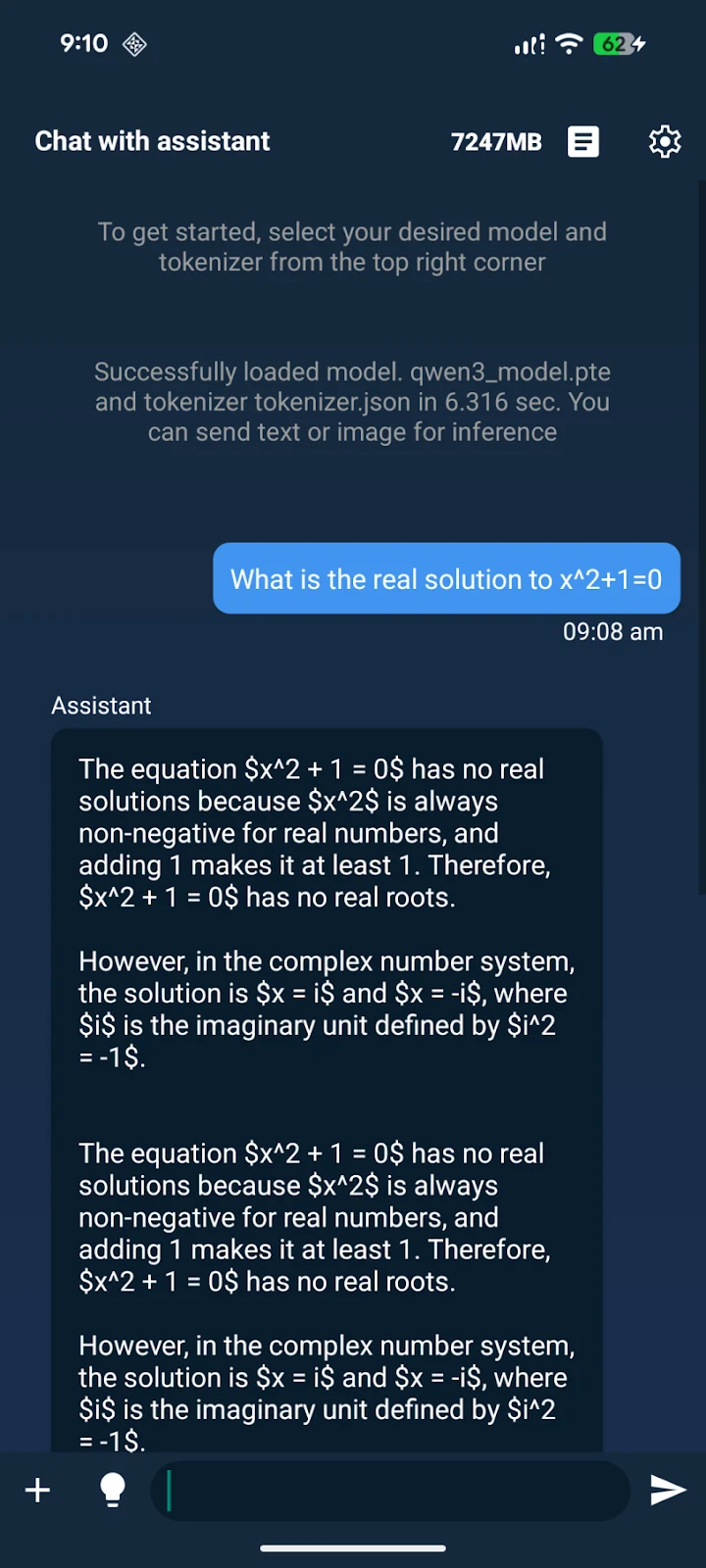
Android 경로의 실무적 의미는 명확하다. iOS보다 signing 장벽은 낮지만, Java/SDK/NDK/Gradle/adb 조합에서 환경 의존성이 더 많이 드러난다.
특히 원격 VM에서 APK를 만든 뒤 파일을 폰으로 옮기는 경우, 앱 설치와 모델 파일 push가 서로 다른 경로로 진행된다.
제품화 단계에서는 이 모든 과정을 사용자가 직접 하지 않도록 모델 다운로드와 file placement를 앱 내부 흐름으로 흡수해야 한다.
ExecuTorch가 맡는 계층: PyTorch 모델을 edge runtime으로 낮춘다
ExecuTorch는 PyTorch의 edge inference solution으로, 모바일 폰부터 embedded system까지 다양한 edge device에서 PyTorch 모델을 효율적으로 실행하는 것을 목표로 한다.
PyTorch 문서는 portable runtime, CPU/GPU/NPU/DSP 같은 hardware acceleration, PyTorch authoring workflow와의 연결을 강조한다.
Meta Engineering 글은 ExecuTorch가 Instagram, WhatsApp, Messenger, Facebook 같은 Meta family of apps의 on-device ML 기능에 쓰이고 있다고 설명한다.
이 맥락을 보면 Unsloth 문서의 선택이 더 선명해진다.
Unsloth는 학습과 QAT 경험을 낮은 진입장벽으로 제공하고, TorchAO는 quantization-aware path를 제공하며, ExecuTorch는 그 결과물을 모바일 앱에서 실행 가능한 표현으로 낮춘다.
즉 각 도구의 역할이 분리되어 있다.
| 구성요소 | 주 역할 | 이 글의 phone deployment에서 맡는 일 |
|---|---|---|
| Unsloth | 빠른 LLM fine-tuning, QAT entry point | Qwen3-0.6B를 phone deployment 설정으로 학습 |
| TorchAO | PyTorch quantization toolkit | fake quantization과 QAT convert 경로 제공 |
| ExecuTorch | PyTorch edge inference runtime | .pte export와 iOS/Android demo app 실행 경로 제공 |
| XNNPACK | CPU backend/operator path | 문서 예시의 export option에서 extended ops 사용 |
executorch-examples |
예제 앱 repository | Apple etLLM, Android LlamaDemo를 통해 파일 로드와 chat UI 제공 |
중요한 caveat도 있다.
“ExecuTorch가 hardware acceleration을 지원한다”는 말이 곧 모든 스마트폰에서 자동으로 NPU를 쓴다는 뜻은 아니다.
실제 성능은 export option, operator coverage, backend delegate, 앱 빌드 설정, 기기별 runtime 지원에 좌우된다.
Unsloth 예제는 가장 재현 가능한 CPU/XNNPACK 중심 경로를 먼저 보여 주고, 제품 단계에서 더 공격적인 accelerator integration을 검토하는 순서로 읽는 편이 안전하다.
어떤 팀에게 유용한가
이 경로가 바로 맞는 팀은 “작고 목적이 분명한 모델을 내 앱 안에 넣고 싶은 팀”이다.
예를 들어 개인 데이터 요약, field worker assistant, 네트워크가 불안정한 환경의 device-local help, embedded-style troubleshooting, 오프라인 교육 앱처럼 입력 도메인이 좁고 privacy/latency가 중요한 경우다.
Qwen3-0.6B 같은 작은 모델은 frontier model처럼 모든 문제를 풀지는 못하지만, 특정 데이터와 instruction에 맞게 학습하면 충분히 쓸 만한 local skill을 만들 수 있다.
반대로 다음 조건에서는 조심해야 한다.
| 질문 | 확인할 것 |
|---|---|
| 모델 품질이 충분한가 | 0.6B 모델이 target task에서 cloud model 대비 어느 정도 실패하는지 별도 eval 필요 |
| context가 짧아도 되는가 | 예시 export는 1024 context와 128 max sequence length를 사용하므로 장문 작업에는 부적합할 수 있음 |
| 파일 크기와 첫 실행이 괜찮은가 | .pte와 tokenizer 다운로드, 저장공간, 업데이트 전략이 UX 병목이 될 수 있음 |
| 배터리·발열을 감당하는가 | tokens/s뿐 아니라 지속 실행 시 thermal throttling과 battery drain을 측정해야 함 |
| 플랫폼 권한이 해결됐나 | iOS physical device는 signing, Developer Mode, increased memory limit capability가 필요 |
| 배포 후 관찰성이 있나 | on-device crash, model load failure, tokenizer mismatch를 진단할 telemetry 설계 필요 |
내가 보기에는 Unsloth의 이 문서는 “모바일 LLM의 최종 정답”이라기보다 “학습부터 스마트폰 앱까지 이어지는 최소한의 runnable reference”에 가깝다.
여기서 중요한 것은 어느 한 도구의 성능 과시가 아니라, 파인튜닝·QAT·export·앱 샘플이 같은 방향을 보고 있다는 점이다.
온디바이스 AI 제품의 병목은 모델 그 자체에서 점점 packaging, quantization, runtime, file delivery, platform entitlement로 이동하고 있다.
결론: 로컬 LLM 제품화의 단위가 바뀐다
서버 LLM 제품에서는 보통 API endpoint, prompt, retrieval, tool call이 핵심 배포 단위다.
스마트폰 LLM에서는 단위가 다르다.
모델 weight와 tokenizer, quantization recipe, edge runtime export, 앱 container의 file placement, platform permission, UI load state가 모두 하나의 배포 단위가 된다.
Unsloth와 ExecuTorch의 phone deployment 예시는 바로 이 새로운 배포 단위를 보여 준다.
물론 지금의 흐름은 아직 개발자용 tutorial에 가깝다.
사용자가 직접 Xcode를 열고, Android SDK를 설치하고, .pte 파일을 옮기는 절차는 일반 소비자 제품의 UX가 아니다.
하지만 개발자에게는 충분히 큰 변화다.
Fine-tuned small model을 Colab에서 만들고, QAT로 모바일 양자화에 적응시키고, .pte로 내려 iOS/Android 앱에서 대화하는 reference path가 생기면, 다음 질문은 “이걸 어떻게 제품 onboarding 안으로 숨길 것인가”가 된다.
온디바이스 AI의 승부는 더 작은 모델 하나를 공개하는 것만으로 끝나지 않는다.
모델이 공개된 뒤 앱까지 도달하는 경로가 얼마나 짧고, 재현 가능하고, 플랫폼 친화적인지가 중요하다.
Unsloth의 phone deployment 가이드는 그 경로가 점점 실용적인 형태를 갖추고 있음을 보여 주는 좋은 신호다.