컴퓨터 사용 에이전트(computer-use agent)는 “브라우저를 대신 조작한다”는 말만 들으면 단순한 자동화처럼 보인다.
하지만 실제로는 두 가지 병목이 동시에 있다.
하나는 모델이 화면을 이해하고 여러 단계의 웹 작업을 안정적으로 수행할 만큼 강해야 한다는 점이고, 다른 하나는 예약, 결제, 계정 관리, 내부 업무처럼 민감한 화면을 클라우드 모델에 계속 보내도 되는가라는 문제다.
Hugging Face에 공개된 Microsoft Research의 Fara-7B가 흥미로운 이유는 이 두 병목을 하나의 방향으로 묶기 때문이다.
Fara-7B는 70억 파라미터 규모의 agentic small language model이며, 웹페이지의 접근성 트리나 별도 화면 파서 없이 스크린샷을 보고 클릭 좌표·타이핑·스크롤 같은 행동을 직접 예측한다.
Microsoft는 이를 Hugging Face와 Azure AI Foundry에 MIT 라이선스의 open-weight 모델로 공개했고, 연구용 웹 에이전트 인터페이스인 Magentic-UI 및 별도 microsoft/fara 저장소와 연결해 실험할 수 있게 했다.
중요한 것은 “7B가 GPT-4o를 이겼다”라는 자극적인 문장만이 아니다.
공개 자료를 함께 보면 더 정확한 해석은 이렇다.
Fara-7B는 모든 frontier 모델을 대체하는 범용 에이전트가 아니라, 컴퓨터 사용 에이전트의 단가와 프라이버시 경계를 7B·온디바이스·검증 가능한 행동 궤적 문제로 낮추려는 실험이다.
무엇을 해결하려는가
웹 에이전트가 어려운 이유는 웹이 정적인 API가 아니기 때문이다.
같은 버튼도 사이트 개편, 로그인 상태, 팝업, 지역 설정, 쿠키 배너, 봇 차단 정책에 따라 위치와 흐름이 바뀐다.
기존 접근은 대체로 두 방향이었다.
첫째, GPT-4o나 o3 같은 큰 모델에게 접근성 트리, DOM, 스크린샷, 도구 설명을 많이 넣어 reasoning하게 한다.
둘째, UI-TARS류처럼 화면 기반 computer-use 모델을 만들되, 충분한 행동 궤적 데이터와 안전 제어를 확보해야 한다.
Fara-7B가 겨냥하는 지점은 이 둘 사이의 빈칸이다.
모델은 작아야 로컬 또는 저비용 self-hosted 환경에서 많이 돌릴 수 있고, 입력은 스크린샷 중심이어야 실제 사람이 보는 화면과 같은 modality로 작동할 수 있다.
동시에 결제, 예약, 이메일 발송, 개인 정보 입력처럼 되돌리기 어려운 행동 앞에서는 자동으로 멈춰야 한다.
Microsoft가 Fara-7B를 “experimental release”로 두면서도 Copilot+ PC 같은 온디바이스 시나리오와 Magentic-UI 통합을 강조하는 이유가 여기에 있다.
이 문제는 단순히 성능표 싸움이 아니다.
고객 계정, 결제 화면, 내부 SaaS, HR 폼, 금융 데이터 같은 작업은 “성공률이 몇 퍼센트인가”와 함께 “입력이 어디에 남는가”, “누가 승인하는가”, “실패했을 때 어떤 궤적을 검토할 수 있는가”를 같이 물어야 한다.
Fara-7B는 이 질문을 모델 크기, synthetic trajectory, 안전한 stop point, 실행 하네스의 조합으로 다룬다.
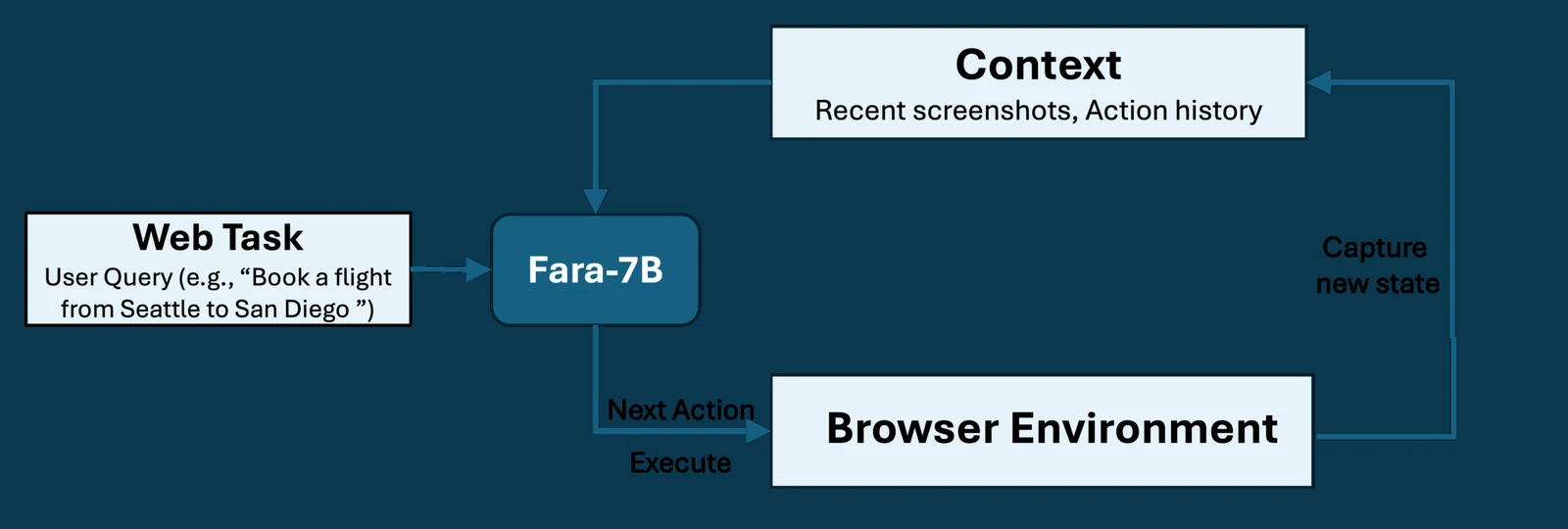
핵심 아이디어: 스크린샷에서 바로 행동을 예측한다
Fara-7B의 기본 동작은 비교적 단순하게 설명된다.
입력은 사용자 목표, 과거 action history, 최근 스크린샷들이다.
모델은 다음에 무엇을 해야 하는지에 대한 reasoning message를 만들고, 이어서 click(x, y), type(), scroll, browser macro-action 같은 도구 호출을 출력한다.
즉 브라우저 환경에 대한 다음 원자 행동을 한 단계씩 예측하고, 이 루프를 반복해 작업을 진행한다.
여기서 중요한 설계 선택은 접근성 트리나 별도 UI 파서를 전제로 하지 않는다는 점이다.
Microsoft 블로그와 기술 보고서는 Fara-7B가 웹페이지를 “사람처럼” 스크린샷으로 지각한다고 설명한다.
물론 실제 구현은 사람과 같지 않다.
모델은 Qwen2.5-VL 계열의 multimodal decoder-only 모델을 기반으로 하며, Hugging Face config에서도 Qwen2_5_VLForConditionalGeneration, 128k max position embeddings, 이미지·비디오 토큰 경로가 확인된다.
다만 에이전트 인터페이스 관점에서는 DOM 구조가 아니라 픽셀 입력과 행동 좌표가 주 인터페이스가 된다.
이 구조의 장점은 배포 경로가 상대적으로 단순해진다는 것이다.
접근성 트리 품질, 사이트별 DOM 해석기, 별도 vision parser가 없어도 브라우저 화면만 있으면 같은 action interface를 쓸 수 있다.
반대로 단점도 명확하다.
좌표 행동은 해상도, 스크롤 상태, 동적 레이아웃 변화에 민감하고, 모델이 잘못 본 화면에서 자신 있게 행동할 수 있다.
따라서 Fara-7B의 가치는 모델 단독보다, 이를 감시하고 멈추게 하는 Magentic-UI, Browserbase 평가 환경, WebTailBench 같은 하네스와 함께 읽어야 한다.
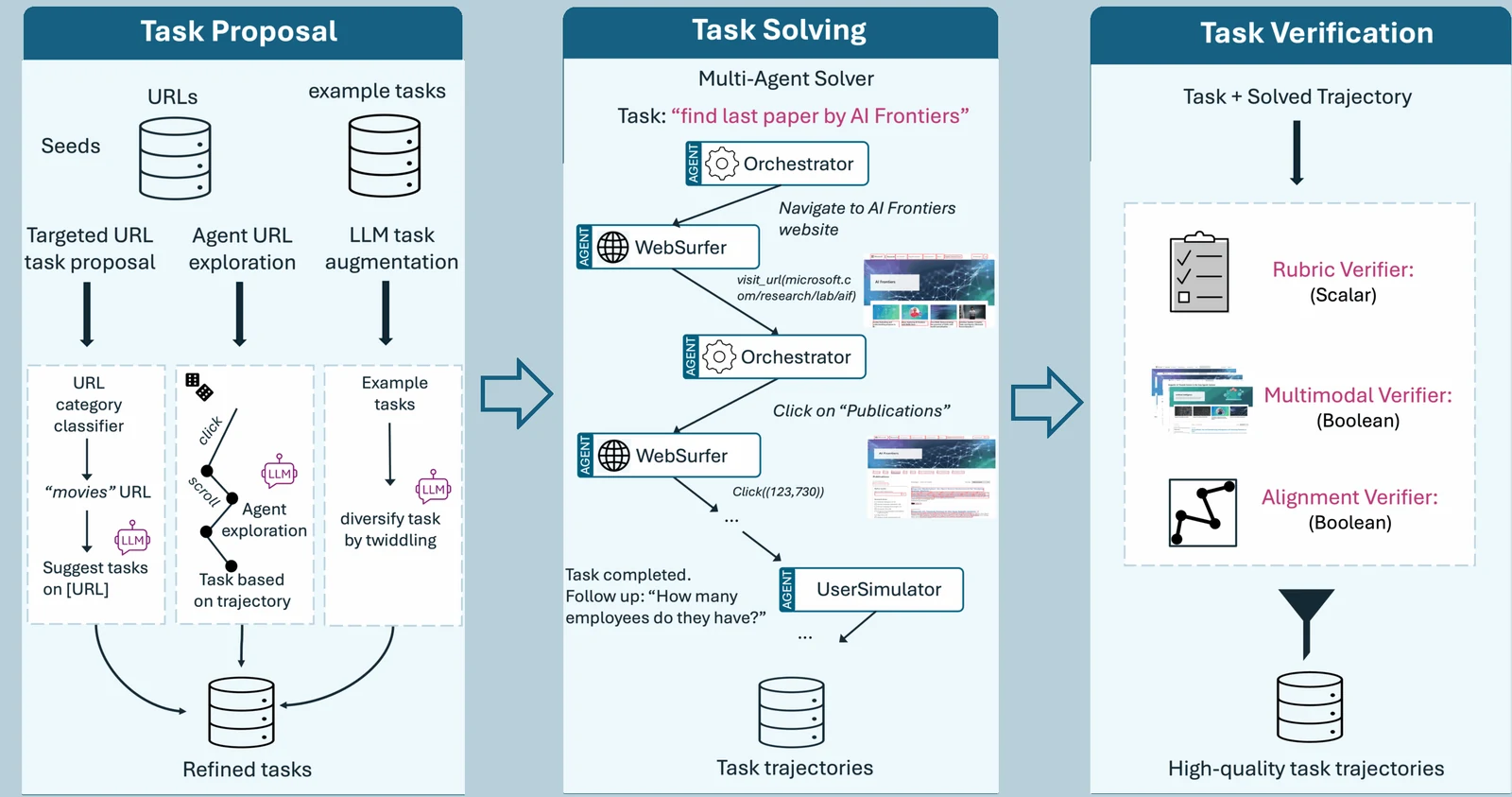
FaraGen: 멀티 에이전트 시스템의 궤적을 7B 모델에 증류한다
작은 computer-use 모델의 병목은 데이터다.
웹 작업 하나는 수십 단계의 관찰, 클릭, 입력, 스크롤, 검증으로 구성된다.
사람이 이를 대규모로 라벨링하면 비용이 너무 크고, 단순 scripted task만 쓰면 실제 웹의 다양성을 담기 어렵다.
Microsoft가 Fara-7B와 함께 제시한 핵심 시스템이 FaraGen인 이유다.
FaraGen은 크게 세 단계로 구성된다.
먼저 public URL과 task seed를 바탕으로 쇼핑, 여행, 식당, 구직, 가격 비교 같은 웹 작업을 제안한다.
다음으로 Magentic-One 기반의 멀티 에이전트 시스템이 작업을 실제로 풀어 본다.
Orchestrator가 계획을 세우고, WebSurfer가 브라우저 행동을 수행하며, 필요하면 UserSimulator가 사용자 입력을 대신 제공한다.
마지막으로 Alignment Verifier, Rubric Verifier, Multimodal Verifier가 궤적이 의도와 맞는지, 완료 기준을 만족하는지, 스크린샷 증거가 성공을 뒷받침하는지를 걸러낸다.
공개 보고서의 숫자는 꽤 구체적이다.
Fara-7B는 최종적으로 14만 5천 개의 검증된 trajectory와 약 100만 step으로 훈련되었고, UI element localization을 위한 grounding, captioning, visual question answering 같은 보조 데이터도 포함한다.
Microsoft는 verified trajectory 생성 비용을 대략 trajectory당 1달러 수준으로 설명한다.
이는 웹 에이전트 학습에서 중요한 신호다.
사람 라벨러가 모든 click step을 쓰는 방식이 아니라, 강한 멀티 에이전트 solver와 verifier를 이용해 행동 데이터를 확장하고, 그 복잡한 solver의 행동을 단일 7B 모델로 증류하는 접근이기 때문이다.
이 관점에서 Fara-7B는 “작은 모델 하나가 갑자기 똑똑해졌다”보다 “큰 solver·검증 시스템이 만든 궤적을 작은 native CUA 모델에 압축했다”에 가깝다.
실무적으로는 이 차이가 중요하다.
좋은 에이전트 모델을 만들려면 base model 크기만 키우는 것이 아니라, 작업 제안, 실행, 검증, 실패 필터링, 안전 중단 데이터를 생산하는 파이프라인이 필요하다는 뜻이기 때문이다.
공개된 근거에서 확인되는 점
성능표를 보면 Fara-7B의 강점과 한계가 함께 보인다.
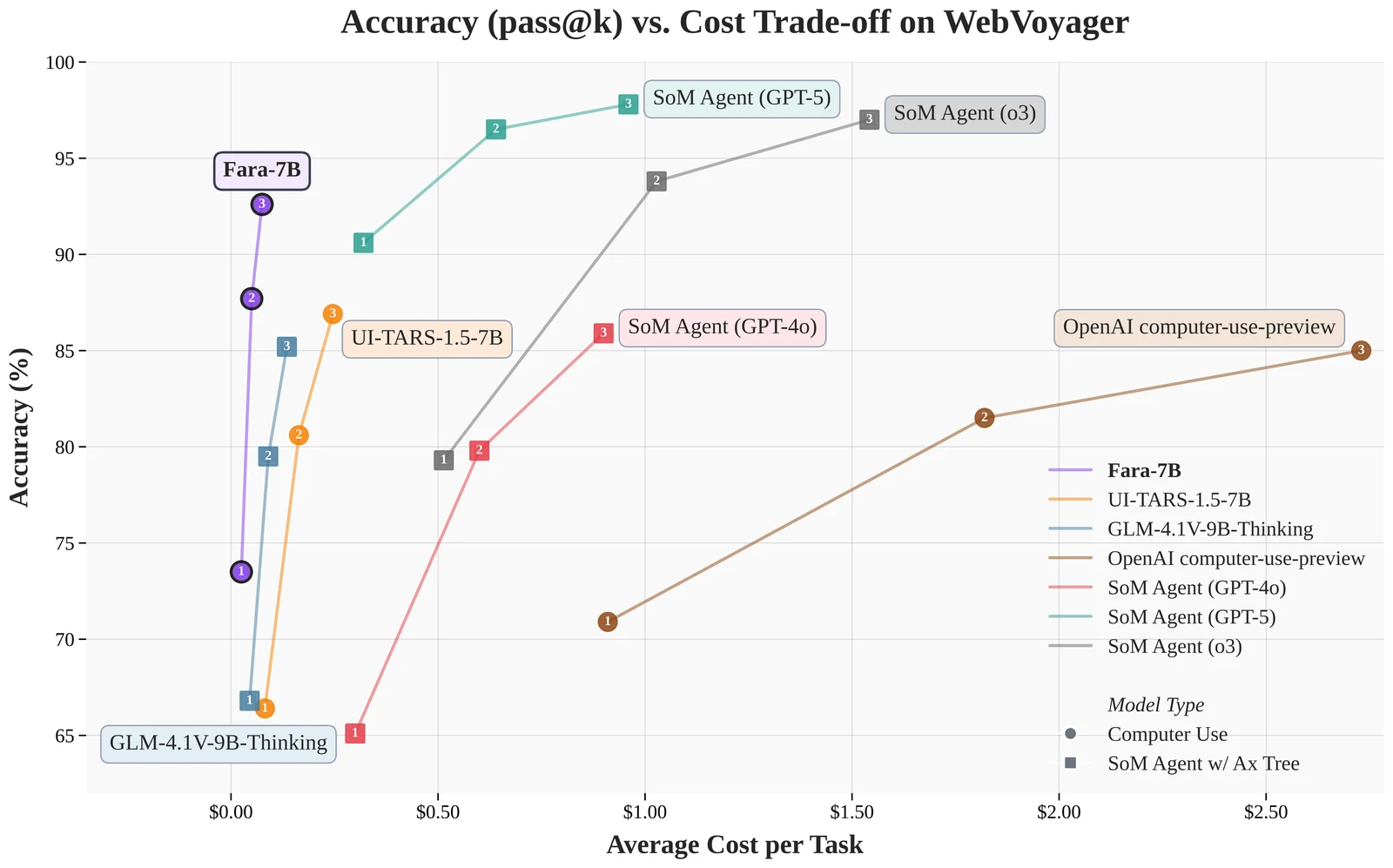
Microsoft 블로그와 Hugging Face 모델 카드는 WebVoyager, Online-Mind2Web, DeepShop, WebTailBench에서의 task success rate를 공개한다.
아래 표는 실무적으로 비교가 필요한 항목만 추린 것이다.
| 모델 / 방식 | 규모 | WebVoyager | Online-Mind2Web | DeepShop | WebTailBench | 해석 |
|---|---|---|---|---|---|---|
| SoM Agent (GPT-4o) | - | 65.1 | 34.6 | 16.0 | 30.8 | 큰 VLM에 Set-of-Marks/도구 프롬프트를 붙인 기준선 |
| OpenAI computer-use-preview | - | 70.9 | 42.9 | 24.7 | 25.7 | 전용 CUA 계열 폐쇄 모델 기준선 |
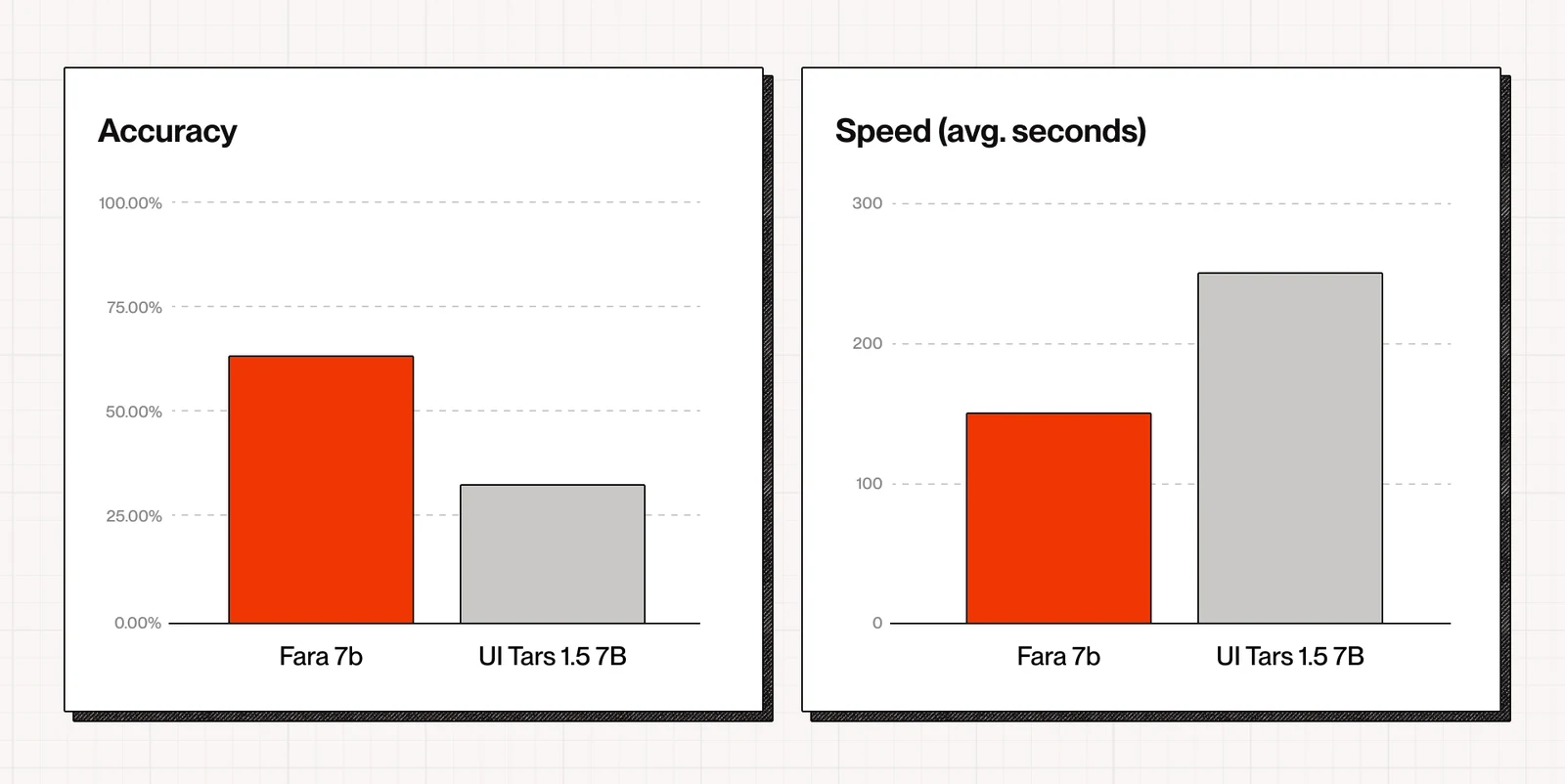
| UI-TARS-1.5-7B | 7B | 66.4 | 31.3 | 11.6 | 19.5 | 같은 7B 체급의 native CUA 비교 대상 |
| Fara-7B | 7B | 73.5 | 34.1 | 26.2 | 38.4 | 7B native CUA 중 강한 결과, 특히 WebVoyager·WebTailBench에서 비용 효율이 큼 |
이 표는 “Fara-7B가 GPT-4o보다 항상 좋다”는 의미가 아니다.
예를 들어 Online-Mind2Web에서는 GPT-4o SoM과 OpenAI computer-use-preview가 각각 34.6, 42.9로 Fara-7B의 34.1보다 높다.
Hugging Face 모델 카드에는 GPT-5/o3 기반 SoM agent 결과도 추가되어 있으며, 이들은 여러 지표에서 Fara-7B보다 높다.
더 정확한 메시지는 Fara-7B가 7B native computer-use 모델로서 WebVoyager와 WebTailBench에서 강한 효율-성능 frontier를 만든다는 것이다.
Browserbase의 독립 평가도 이 맥락에서 유용하다.
Browserbase는 Microsoft와 협력해 595-task WebVoyager 평가를 deterministic browser infrastructure에서 수행했고, pass@1 with up to 5 retries, human-verified scoring, screenshots·trajectory·final state 검토를 기준으로 삼았다고 설명한다.
Microsoft 블로그는 이 평가에서 Fara-7B가 WebVoyager 62%를 기록했다고 언급한다.
수치 자체보다 중요한 점은 live web benchmark에서 LLM judge만으로 success를 판정하기 어렵고, 사람 검토와 실행 로그가 평가의 일부가 되어야 한다는 사실이다.
릴리스 패키징도 비교적 실험하기 쉬운 편이다.
2026년 5월 26일 KST에 확인한 Hugging Face API 기준 모델은 non-gated이며 transformers, safetensors, image-text-to-text, qwen2_5_vl, license:mit 태그를 갖는다.
API가 반환한 현재 값은 downloads 16,172, likes 598, lastModified 2026-05-19이고, safetensors 메타데이터에는 BF16 파라미터 8,292,166,656개와 약 16.6GB 저장소 사용량이 잡힌다.
모델 카드는 제품 포지셔닝을 7B로 설명하므로, Hub의 8B급 메타데이터는 Qwen2.5-VL 기반 전체 체크포인트 구성까지 포함한 값으로 읽는 편이 안전하다.
저장소에는 네 개의 safetensors shard, tokenizer, chat_template.jinja, preprocessor_config.json, config.json 등이 포함된다. microsoft/fara GitHub 저장소는 MIT 라이선스의 Python 패키지로, fara-cli, Playwright, vLLM serving, Browserbase 관련 의존성을 제공한다.
GitHub API 기준 저장소는 stars 5,269, forks 505 수준까지 커졌지만, 여전히 latest release는 404이고 tag 목록도 비어 있어 main-branch 중심의 연구 릴리스라는 점은 운영 도입 전에 확인해야 할 부분이다.
또 하나 눈에 띄는 것은 WebTailBench다.
Microsoft는 기존 벤치마크가 잘 다루지 못하는 영화·이벤트 티켓 예약, 식당 예약, 가격 비교, 구직 신청, 부동산 탐색 같은 11개 실전 작업 유형을 담기 위해 WebTailBench를 만들었다.
Hugging Face dataset API 기준 microsoft/WebTailBench는 MIT 라이선스, 609-task 규모의 test_v2 split, 기존 test와 refusals split을 함께 제공한다.
Fara repo README에는 2026-05-12에 V2 task string과 rubric을 갱신했다는 기록도 있다. live web benchmark에서는 날짜와 예약 가능성이 빠르게 낡기 때문에, 이런 갱신 기록 자체가 중요하다.
안전장치: Critical Point는 기능이 아니라 제품 경계다
웹 에이전트에서 안전은 별도 부록이 아니다.
브라우저를 조작하는 모델은 구매, 예약, 이메일, 전화, 지원서 제출, 로그인, 개인 정보 입력을 실제로 건드릴 수 있다.
Fara-7B 모델 카드가 Critical Point를 강조하는 이유도 여기에 있다.
Critical Point는 사용자의 허가나 개인·민감 정보가 필요한 시점, 또는 거래·예약·가입·커뮤니케이션처럼 되돌리기 어려운 행동 직전의 stop point다.
이 설계는 모델 성능을 일부러 제한한다.
에이전트가 “끝까지 자동 완료”하지 않고 사용자의 승인을 요구해야 하기 때문이다.
하지만 제품 관점에서는 이 제한이 오히려 필수다.
결제 직전, 이메일 발송 직전, 지원서 제출 직전, 전화 연결 직전에서 멈추지 않는 computer-use agent는 개인 비서가 아니라 위험한 자동 클릭러가 된다.
Microsoft와 Hugging Face 모델 카드는 human-in-the-loop monitoring, sandboxed environment, 민감 데이터 사용 회피, allow-list/block-list 기반 인터넷 접근 제한, commercial·high-stakes·regulated domain 회피를 권장한다.
즉 Fara-7B는 “로컬에서 돌 수 있으니 안전하다”가 아니라, 로컬 실행과 안전 중단 데이터를 결합해 위험 표면을 줄이려는 모델이다.
온디바이스 배포는 프라이버시를 돕지만, 잘못된 행동을 자동으로 안전하게 만들지는 않는다.
실무 관점에서의 해석
Fara-7B의 가장 큰 의미는 웹 에이전트의 단가 구조를 바꿀 가능성이다.
대형 폐쇄 모델을 매 step 호출하는 방식은 간단하지만, 멀티 step 웹 작업에서는 비용과 latency가 빠르게 누적된다.
Fara-7B가 평균 step 수를 줄이고, 7B self-hosted 또는 온디바이스 경로를 제공한다면, 여러 에이전트를 병렬로 돌리거나 반복 시도를 허용하는 운영 설계가 현실적으로 가까워진다.
두 번째 의미는 데이터 생성 시스템의 중요성이다.
Fara-7B 자체보다 오래 남을 수 있는 자산은 FaraGen 같은 task proposal·solving·verification 파이프라인이다.
앞으로 더 좋은 7B 또는 14B VLM이 나오더라도, 웹 작업을 제안하고, solver가 풀고, verifier가 성공 궤적을 거르고, Critical Point와 refusal 데이터를 만드는 시스템은 계속 필요하다.
이는 최근 agent 시스템에서 반복해서 보이는 패턴과 같다.
모델이 제품이 아니라, 모델을 훈련·평가·감시하는 하네스가 제품에 가깝다.
세 번째 의미는 평가다.
WebVoyager, Online-Mind2Web, DeepShop, WebTailBench 수치는 유용하지만, live web task는 정답지가 고정된 QA benchmark와 다르다.
사이트가 바뀌고, 봇 차단이 걸리고, 예약 날짜가 만료되고, LLM judge가 불완전한 성공을 통과시킬 수 있다.
Browserbase 평가와 WebTailBench V2 갱신은 이 문제를 잘 보여 준다. computer-use agent 성능을 보려면 모델 점수뿐 아니라 브라우저 인프라, 재시도 정책, 사람 검토, rubric 갱신, trajectory 공개 여부까지 봐야 한다.
한계도 분명하다.
Fara-7B는 experimental release이고, Microsoft도 sandbox와 monitoring을 권장한다.
영어 중심 모델이며, high-stakes domain에는 적합하지 않다.
좌표 기반 action은 화면 변화에 민감하고, 복잡한 작업에서는 지시 오해와 hallucination이 생길 수 있다.
또한 “온디바이스 가능”은 모든 일반 노트북에서 즉시 매끄럽게 돈다는 뜻이 아니다. vLLM serving, GPU 메모리, WSL2/Playwright, Magentic-UI 통합 같은 실제 실행 표면은 여전히 엔지니어링이 필요하다.
그럼에도 Fara-7B는 computer-use agent 경쟁의 좋은 기준점을 제시한다.
앞으로 이 영역의 핵심 질문은 “가장 큰 모델이 브라우저를 얼마나 잘 조작하는가”만이 아닐 것이다.
더 중요한 질문은 “어느 정도 작은 모델이, 어떤 데이터 생성 파이프라인과 평가 하네스 위에서, 민감한 화면을 어디까지 로컬에 남긴 채, 언제 사용자에게 제어를 돌려주는가”다.
Fara-7B는 그 질문에 대한 Microsoft Research의 첫 번째 공개 답변에 가깝다.