온디바이스 AI 경쟁은 이제 “작은 모델도 꽤 잘한다”는 주장만으로는 부족하다.
휴대폰, 노트북, 자동차, 로봇, 센서가 붙은 엣지 장비에서 실제로 쓰려면 첫 토큰 지연, 1-token decode latency, 메모리 피크, 배터리, 오프라인성, 개인정보 경계가 함께 맞아야 한다.
클라우드 GPU에서 좋은 점수를 내는 모델과, 배치 1의 CPU·SoC에서 안정적으로 반응하는 모델은 같은 문제가 아니다.
Liquid AI의 LFM2 Technical Report는 이 문제를 정면으로 다룬다.
보고서는 LFM2를 두 번째 세대 Liquid Foundation Models로 소개하며, 350M, 700M, 1.2B, 2.6B dense 언어 모델과 8.3B total / 1.5B active MoE 모델, LFM2-VL, LFM2-Audio, LFM2-ColBERT, 그리고 task-specific LFM2-Nanos를 하나의 패밀리로 묶는다.
핵심은 단일 최고 점수 모델이 아니라, 엣지 배포를 기준으로 아키텍처·학습·post-training·런타임 패키징을 함께 조정한 모델 포트폴리오다.
공식 보고서와 Hugging Face 모델 카드가 반복해서 강조하는 단어도 “edge”다.
LFM2는 모든 주요 언어 모델을 32K 컨텍스트로 공개하고, Transformers, llama.cpp, ExecuTorch, vLLM 및 GGUF 계열 배포 경로를 함께 둔다.
이 글은 LFM2가 무엇을 새로 제안했는지, 성능표가 실제로 무엇을 말하는지, 그리고 실무적으로 어떤 배포·라이선스 해석이 필요한지 정리한다.

무엇을 해결하려는가
LFM2가 풀려는 첫 번째 문제는 small model의 실제 배포 비용이다.
작은 파라미터 수는 필요조건일 뿐이다.
실제 단말에서는 prompt prefill이 얼마나 빨리 끝나는지, 4K·32K context에서 resident memory가 튀지 않는지, decode가 일정하게 유지되는지, CPU·NPU·모바일 SoC에서 런타임이 준비되어 있는지가 더 직접적인 병목이 된다.
보고서는 Time-to-first-token, p50/p95 decode latency, prefill throughput, peak RSS를 품질과 함께 architecture search의 목표로 둔다.
두 번째 문제는 “Transformer를 얼마나 줄일 것인가”가 아니라 어떤 연산을 엣지 하드웨어에서 실제로 이득으로 볼 것인가다.
최근 효율 모델은 SSM, linear attention, sliding-window attention, hybrid architecture를 다양하게 시도한다.
LFM2 보고서의 흥미로운 주장은, 엣지 지연·메모리 예산 아래에서는 복잡한 SSM/linear-attention 연산을 더 얹기보다 대부분의 층을 input-aware gated short convolution으로 두고, 소수의 grouped-query attention만 섞는 단순한 hybrid가 반복적으로 Pareto frontier에 오른다는 점이다.
세 번째 문제는 모델 릴리스의 범위다.
LFM2는 텍스트 언어 모델만 공개하지 않는다.
같은 백본을 비전 입력, 오디오 입출력, ColBERT식 late-interaction retrieval, 도메인별 Nano 모델까지 확장한다.
따라서 이 보고서는 “새 small LM 하나”보다 “엣지 모델 패밀리를 어떻게 제품 surface까지 묶을 것인가”에 가까운 문서다.
핵심 아이디어 / 구조 / 동작 방식
LFM2의 백본은 decoder-only 구조지만, 모든 층을 attention으로 채우지 않는다.
보고서의 Table 1 기준 dense 모델은 16층 또는 30층 구성이고, 그중 attention block은 6개 또는 8개뿐이다.
나머지 주요 블록은 gated short convolution과 SwiGLU MLP로 구성된다.
MoE 모델인 LFM2-8B-A1B는 24층, 32 experts, top-4 routing, 8.3B total / 1.5B active 구성이다.
| 모델 | 총/활성 파라미터 | 층 수 | Attention blocks | 특징 |
|---|---|---|---|---|
| LFM2-350M | 350M / — | 16 | 6 | 가장 작은 dense LM, 32K context |
| LFM2-700M | 700M / — | 16 | 6 | 0.6B~1B급 엣지 모델 축 |
| LFM2-1.2B | 1.2B / — | 16 | 6 | 1B급 품질·속도 균형점 |
| LFM2-2.6B | 2.6B / — | 30 | 8 | 작은 공개 LM 중 품질을 끌어올린 dense 축 |
| LFM2-8B-A1B | 8.3B / 1.5B | 24 | 6 | 32 experts, top-4 routing MoE |
이 설계는 “attention을 버렸다”가 아니다.
오히려 긴 의존성과 global context가 필요한 구간에는 GQA를 남기고, 나머지 많은 층은 짧은 convolution으로 비용을 줄인다.
보고서는 hardware-in-the-loop search에서 gated short convolution, sliding-window attention, linear attention, S4/S5/Mamba 계열 SSM, Liquid-time-constant 변형, MoE FFN 등 여러 후보를 실제 디바이스 지표와 함께 비교했다고 설명한다.
그 결과 소수 GQA + 다수 gated short convolution 조합이 품질·latency·memory trade-off에서 반복적으로 선택됐다는 것이 핵심이다.
학습 파이프라인도 작은 모델에 맞춰 설계되어 있다.
LFM2는 10–12T tokens 규모의 pre-training과 1T token long-context mid-training을 거치고, tempered decoupled Top-K knowledge distillation을 사용한다.
보고서가 강조하는 포인트는 단순 Top-K distillation이 teacher distribution의 잘린 support와 temperature 적용 때문에 불안정해질 수 있다는 점이다.
이를 decoupled objective로 다루어 작은 student가 teacher의 유용한 분포를 더 안정적으로 받도록 만든다.
Post-training은 세 단계다.
첫째 supervised fine-tuning, 둘째 length-normalized direct alignment, 셋째 model merging이다.
특히 작은 모델에서는 instruction following, 수학, 다국어, long context, tool use 같은 능력이 서로 충돌하기 쉽다.
보고서는 difficulty-ordered curriculum, preference dataset, 여러 checkpoint 병합을 통해 작은 모델의 robustness를 끌어올리려 한다.
즉 LFM2의 핵심은 “새 블록 하나”보다 엣지 하드웨어에 맞춘 백본과 작은 모델 학습 레시피를 함께 묶은 co-design으로 보는 편이 맞다.
공개된 근거에서 확인되는 점
가장 직접적인 근거는 CPU throughput 표다.
Samsung Galaxy S25의 Snapdragon 8 Elite SoC에서 batch size 1로 측정한 보고서 Table 2를 보면, LFM2-350M은 1K/4K prompt prefill에서 1,067 / 657 tokens/s를 기록한다.
같은 표의 Granite-4.0-350M은 528 / 210 tokens/s다.
Decode 역시 LFM2-350M은 1K/4K prefix에서 194.1 / 143.8 tokens/s이고, Granite-4.0-350M은 132.9 / 70.7 tokens/s다.
LFM2-2.6B도 비슷한 패턴을 보인다.
Galaxy S25 표에서 LFM2-2.6B의 prefill은 143 / 116 tokens/s, decode는 33.8 / 30.0 tokens/s다.
Llama-3.2-3B는 같은 표에서 prefill 79 / 51, decode 24.2 / 15.8이다.
HX 370 CPU 표에서도 LFM2-2.6B는 1K/4K prefill 1,335 / 1,171 tokens/s, decode 50.3 / 46.8 tokens/s를 보이며, Llama-3.2-3B의 1,179 / 916 prefill, 38.3 / 28.2 decode보다 유리하게 나온다.
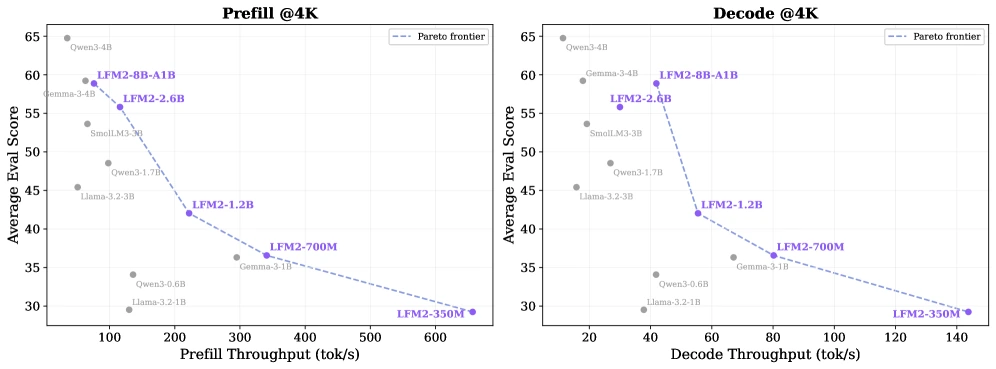
하지만 성능표를 “LFM2가 모든 모델을 이긴다”로 읽으면 안 된다.
작은 언어 모델 벤치마크 Table 7에서 LFM2-2.6B는 IFEval 79.56, GSM8K 82.41, MATH 500 63.60을 기록한다.
LFM2-8B-A1B는 GSM8K 84.38, MATH 500 74.20으로 더 올라간다.
반면 Qwen3-4B는 MMLU 72.25, IFEval 85.62, MATH 500 85.60으로 여러 절대 품질 항목에서 더 높다.
따라서 LFM2의 강점은 단순 최고점이 아니라 비슷한 체급 또는 낮은 활성 파라미터와 CPU 지연 조건에서 얻는 품질-속도 균형이다.
Multimodal 확장도 중요한 근거다.
LFM2-VL은 SigLIP2 vision encoder와 lightweight connector를 붙이고, 작은 이미지는 native resolution으로, 큰 이미지는 512×512 tile과 thumbnail을 함께 쓰는 방식으로 처리한다.
보고서는 untiled image에서는 128–256 vision tokens, heavily tiled input에서는 약 2,800 tokens까지 조절할 수 있다고 설명한다.
즉 LFM2-VL의 포인트는 “비전도 된다”가 아니라, 이미지 token budget을 통해 정확도와 지연을 조절할 수 있다는 데 있다.
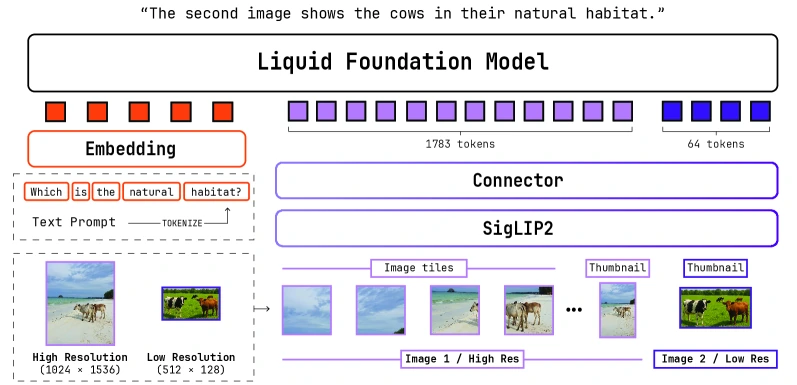
VLM 결과는 꽤 넓다.
Table 9에서 LFM2-VL-3B는 MMBench(dev) 79.81, RealWorldQA 71.37, OCRBench 822, MM-IFEval 51.83을 기록한다.
Multilingual MMBench 평균은 75.84, MMMB 평균은 81.52로 제시된다.
다만 Qwen2.5-VL-3B가 InfoVQA 76.12, OCRBench 824처럼 앞서는 항목도 있고, InternVL3.5-2B가 MMMU 51.78, MME 2,129처럼 높은 항목도 있다.
여기서도 LFM2-VL의 메시지는 “모든 VLM을 이긴다”보다, 3B급 모델이 다국어·OCR·reasoning·instruction following을 꽤 넓게 커버하면서 token budget을 조절할 수 있다는 쪽이다.
Audio 쪽은 LFM2-Audio-1.5B가 담당한다.
보고서는 LFM2 backbone이 text token과 audio embedding을 하나의 sequence에서 다루고, audio output은 discrete RVQ code sequence로 생성한 뒤 detokenizer를 통해 waveform으로 되돌리는 구조를 제시한다.
학습 데이터 표에는 transcription, TTS, language classification, audio chat instruction tuning, text chat instruction tuning이 함께 들어가며, 총 input audio 146,021 hours, output audio 325,790 hours가 적혀 있다.
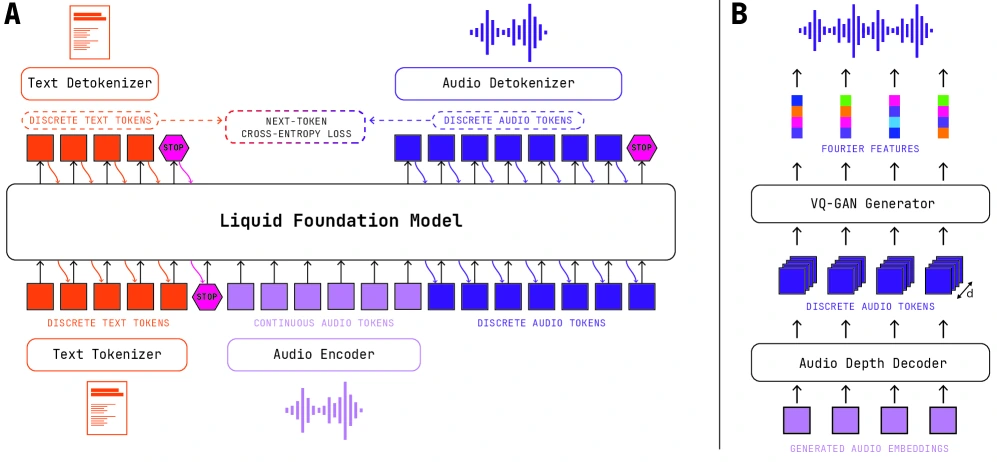
Audio 성능도 균형형으로 읽어야 한다.
VoiceBench에서 LFM2-Audio-1.5B는 AlpacaEval 3.78, CommonEval 3.48, WildVoice 3.12를 기록하고, ASR 표에서는 LibriSpeech Clean WER 2.03으로 Qwen2.5-Omni-3B 2.14와 Whisper-large-v3-turbo 2.10보다 낮다.
반면 Earnings22, SPGISpeech, Voxpopuli 같은 항목에서는 Qwen2.5-Omni 또는 Whisper가 더 낮은 WER를 보인다.
즉 LFM2-Audio는 1.5B 체급의 speech-to-speech 모델로 강한 신호를 보여 주지만, 전문 ASR 또는 더 큰 omni 모델을 모든 항목에서 대체한다고 말하기에는 이르다.
Retrieval 쪽에서는 LFM2-ColBERT-350M이 별도 모델로 나온다.
이 모델은 ColBERT식 late interaction을 사용해 query와 document를 각각 인코딩하고 max-similarity 연산으로 점수를 계산한다.
NanoBEIR multilingual extension 표에서 LFM2-ColBERT-350M은 평균 query-language 기준 English 50.32, Korean 40.78, Japanese 44.62를 보인다.
같은 표의 GTE-ModernColBERT-v1은 English 39.76, Korean 9.38, Japanese 16.50이다.
특히 한국어·일본어·아랍어처럼 cross-lingual retrieval이 흔히 약해지는 축에서 차이가 크다.
릴리스 표면도 확인된다.
Hugging Face API 기준 LFM2-2.6B, LFM2-8B-A1B, LFM2-VL-3B, LFM2-Audio-1.5B, LFM2-ColBERT-350M은 모두 public이며 gated가 아니다.
모델 카드들은 LFM Open License v1.0을 가리키고, 언어 모델 카드에는 Transformers, vLLM, llama.cpp/GGUF 경로가 정리되어 있다.
LFM2-2.6B 모델 repo에는 model.safetensors, config.json, chat_template.jinja, tokenizer 파일들이 있고, LFM2-8B-A1B는 4개 shard의 safetensors와 index 파일을 제공한다.
VL 모델에는 processor/preprocessor config가, ColBERT 모델에는 sentence-transformers/PyLate 관련 파일들이 함께 들어 있다.
다만 “open weights”를 곧바로 Apache-2.0식 오픈소스와 같은 의미로 읽으면 안 된다.
모델 카드의 license tag는 other이고, 실제 LICENSE는 LFM Open License v1.0이다.
이 라이선스는 상업적 사용에 대해 연매출 1,000만 달러 threshold를 두며, threshold를 초과하는 법인의 commercial use는 해당 계약 아래 라이선스되지 않는다고 적는다.
연구·비상업·소규모 상업 사용과 대기업 제품 탑재는 라이선스 검토의 무게가 다르다.
실무 관점에서의 해석
내가 보기에 LFM2의 가장 큰 의미는 작은 모델 경쟁의 기준을 “파라미터 수”에서 “배치 1 엣지 실행성”으로 옮긴다는 데 있다.
많은 모델 카드가 1B, 3B, 7B 같은 크기를 강조하지만, 사용자가 실제로 체감하는 것은 첫 토큰까지 걸리는 시간과 decode 안정성이다.
LFM2 보고서는 이 지표를 architecture search의 목적 함수로 넣고, Samsung Galaxy S25와 HX 370 같은 현실적인 CPU 경로에서 수치를 제시한다.
이 점은 서버용 benchmark 중심 릴리스와 다르다.
두 번째 의미는 hybrid architecture에 대한 실용적 결론이다.
SSM이나 linear attention이 이론적으로 매력적이어도, 실제 edge runtime에서 커널·메모리·캐시·양자화까지 고려하면 “복잡한 subquadratic block을 더 넣는 것”이 항상 이득은 아니다.
LFM2가 제시하는 결론은 다소 절제되어 있다.
대부분의 이득은 짧은 convolution과 소수 attention의 조합으로 얻고, 나머지는 학습·post-training·런타임 패키징으로 밀어붙인다는 것이다.
이 방향은 연구적으로도 실무적으로도 중요하다.
세 번째 의미는 모델 패밀리 운영 방식이다.
LFM2는 dense LM, sparse MoE, VL, Audio, ColBERT, Nanos를 하나의 포트폴리오로 제시한다.
제품 팀 관점에서는 이 구성이 흥미롭다.
로컬 assistant는 텍스트 LM만 필요하지 않다.
화면·사진 이해, 음성 입력과 출력, 로컬 문서 검색, tool/function calling, RAG가 모두 붙어야 한다.
LFM2는 각 기능을 하나의 거대 모델에 다 밀어 넣기보다, 같은 철학의 작은 모델 묶음으로 나누어 배포하려는 쪽에 가깝다.
그렇다고 LFM2를 “온디바이스 AI의 최종 답”처럼 읽어서는 안 된다.
보고서의 다수 평가는 내부 harness 또는 공식 프로토콜에 기반한다.
Qwen3-4B, Qwen2.5-VL-3B, InternVL3.5-2B, Whisper 같은 비교 모델이 특정 품질 항목에서 앞서는 영역도 분명히 있다.
또한 실제 앱에서는 모델 파일 크기, quantization별 품질 저하, NPU 지원 여부, thermal throttling, streaming UX, 개인정보 처리, 업데이트 경로가 별도 검증 대상이다.
라이선스도 실무적으로는 큰 변수다.
LFM2는 공개 가중치와 배포 가이드를 제공하지만, LFM Open License v1.0의 commercial threshold 때문에 대기업이나 매출이 큰 제품 팀은 별도 계약 또는 법무 검토 없이 “자유롭게 상용 탑재 가능한 오픈 모델”로 취급하기 어렵다.
특히 edge device에 모델을 내장하거나 파생 모델을 배포하는 경우에는 모델 카드의 open weights 문구보다 LICENSE 본문을 먼저 읽어야 한다.
그럼에도 LFM2 Technical Report는 볼 가치가 크다.
이 보고서는 small LM, edge inference, multimodal extension, retrieval model, audio interaction을 한 문서 안에서 연결한다.
앞으로 온디바이스 AI의 경쟁은 “작은 모델이 얼마나 큰 모델을 따라잡았는가”보다, “작은 모델 패밀리가 실제 단말에서 어떤 latency-memory-quality envelope을 만들고, 그 envelope을 제품 기능으로 어떻게 나눠 담는가”로 이동할 가능성이 높다.
LFM2는 그 질문에 대한 꽤 구체적인 공개 답안이다.