대형 Mixture-of-Experts 모델을 빠르게 서빙하려면 모델 구조만큼이나 어느 GPU rank가 어느 expert traffic을 처리하는가가 중요해진다.
MoE는 token마다 일부 expert만 활성화해 계산량을 줄이지만, 실제 serving에서는 router가 expert를 균등하게 고르지 않는다.
어떤 rank에는 token이 몰리고, 어떤 rank는 비교적 한가하다.
Expert Parallelism(EP) 그룹은 결국 가장 늦은 rank를 기다리기 때문에, 평균 처리량보다 tail rank load가 병목이 된다.
LMSYS의 Improving DeepEP MoE Load Balance in SGLang with Waterfill and LPLB는 이 문제를 dispatch-time 시스템 문제로 다룬다.
SGLang의 DeepEP MoE inference 위에서 두 가지 방법을 넣는다.
하나는 shared expert work를 덜 바쁜 rank로 보내는 Waterfill, 다른 하나는 redundant routed expert replica 사이에서 token traffic을 linear programming으로 나누는 LPLB다.
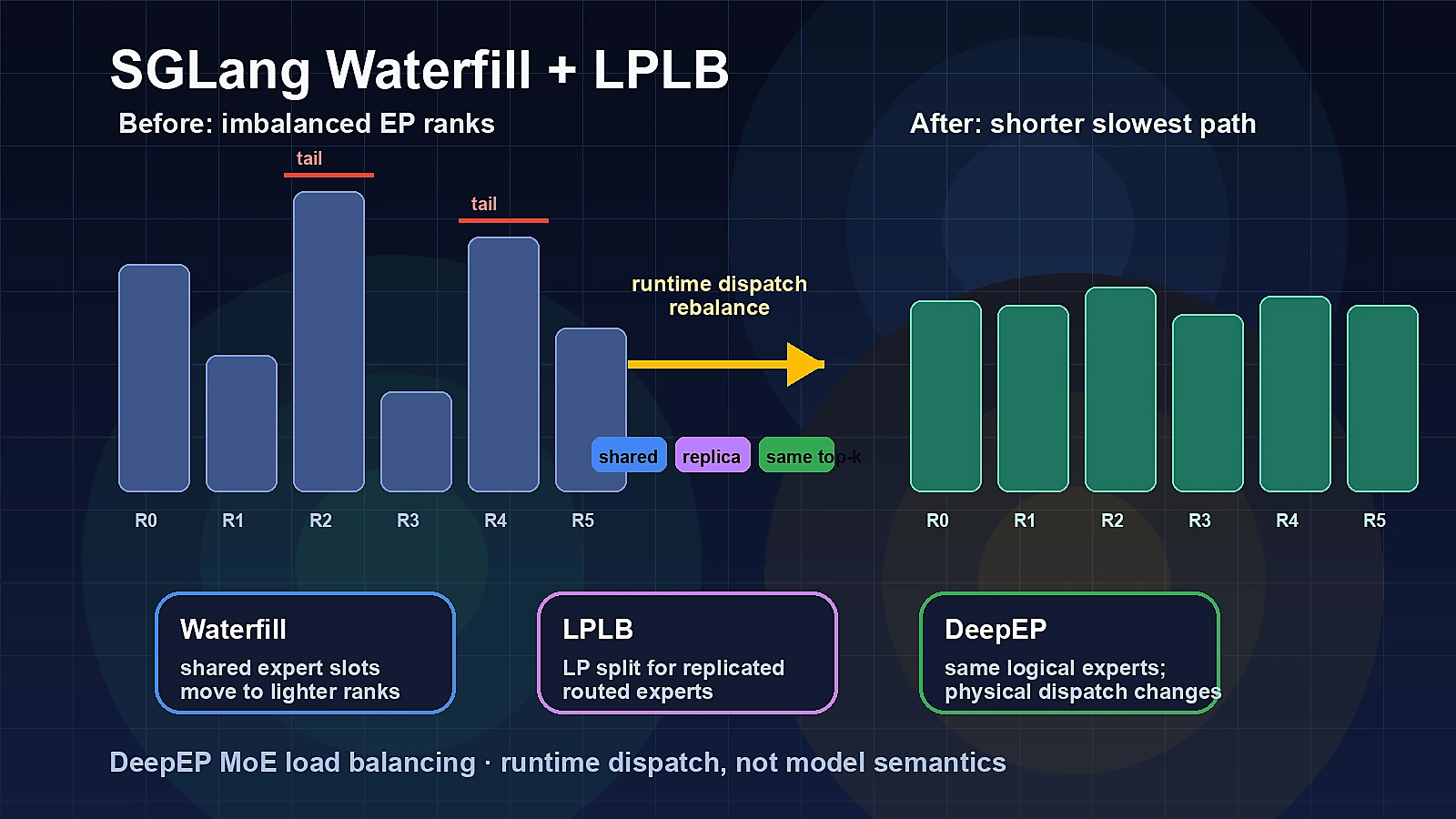
흥미로운 점은 두 방법이 모델의 logical routing을 바꾸지 않는다는 것이다.
Waterfill은 같은 shared expert를 다른 physical rank에서 실행하고, LPLB는 같은 logical expert의 동일 weight replica 중 어떤 physical copy가 token을 처리할지 고른다.
따라서 논문의 중심은 “모델 품질을 바꾸는 새 router”가 아니라, DeepEP all-to-all dispatch와 grouped-GEMM의 slowest path를 짧게 만드는 서빙 시스템 최적화에 가깝다.
무엇을 해결하려는가
DeepSeek-V3/R1이나 DeepSeek V4 같은 대형 MoE 모델은 sparse activation으로 capacity를 키우지만, inference에서는 expert traffic이 균등하지 않다.
Routed expert는 token마다 router 선택에 따라 sparse하게 몰리고, shared expert는 모든 token이 지나가므로 dense한 추가 부하가 된다.
여기에 EPLB-style placement가 hot logical expert의 redundant physical replica를 만들면, runtime에는 “어떤 replica가 이번 batch의 token을 처리할 것인가”라는 선택지가 생긴다.
기존 static placement는 장기 평균에는 도움이 된다.
하지만 실제 batch 하나의 expert distribution은 calibration set과 다를 수 있고, 특정 prompt pool이나 request mix에 따라 특정 rank가 순간적으로 무거워질 수 있다.
Waterfill과 LPLB는 이 남은 runtime imbalance를 줄이려는 접근이다.
| 부하 원천 | 왜 imbalance가 생기나 | 이번 글의 대응 |
|---|---|---|
| Routed experts | router가 token을 expert에 균등하게 보내지 않음 | LPLB가 redundant replica 사이 traffic split을 batch별로 최적화 |
| Shared expert | 모든 token이 shared expert를 필요로 해 이미 무거운 rank를 더 무겁게 만들 수 있음 | Waterfill이 shared-expert slot을 더 가벼운 rank로 이동 |
| Static EPLB placement | offline 분포와 live batch 분포가 다름 | dispatch-time 정책이 현재 batch count를 보고 physical dispatch를 조정 |
| EP group tail | EP는 가장 바쁜 rank가 끝날 때까지 기다림 | peak rank load를 낮춰 grouped-GEMM/communication tail을 줄임 |
핵심 아이디어 / 구조 / 동작 방식
Waterfill: shared expert를 “항상 local”로 두지 않는다
Waterfill은 shared expert path를 겨냥한다. shared expert가 매번 local rank에서 실행되면, routed expert 때문에 이미 무거운 rank도 shared-expert 비용을 그대로 더 부담한다.
Waterfill은 shared expert를 DeepEP dispatchable expert slot처럼 취급하고, routed expert load를 본 뒤 shared-expert work를 상대적으로 덜 바쁜 rank에 배치한다.
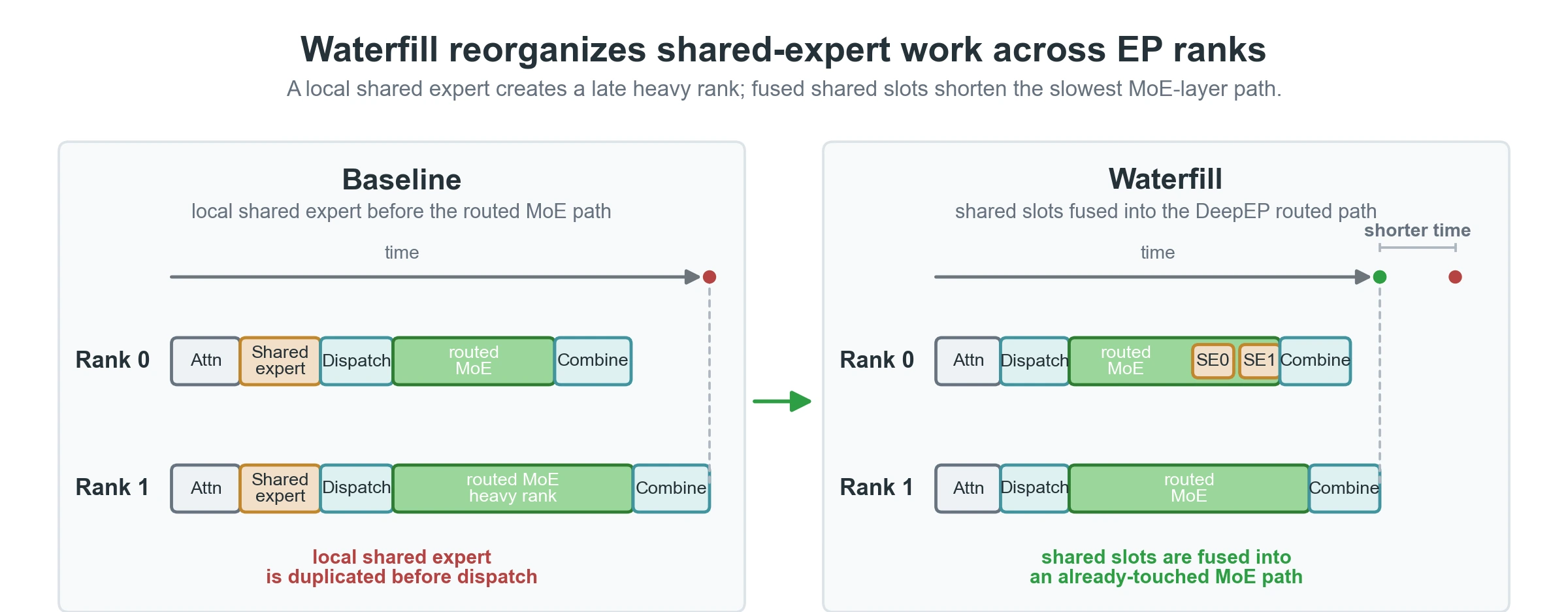
알고리즘은 이름처럼 rank load의 “골짜기”를 채운다.
먼저 rank별 routed expert load L_r를 세고, shared-expert slot 수 N과 EP group size R을 이용해 target waterline을 잡는다.
글에 제시된 핵심 식은 다음과 같다.
H = ceil((sum_r L_r + N) / R)
S_r = max(H - L_r, 0)
각 rank의 slack S_r가 클수록 shared-expert slot을 받을 가능성이 커진다.
다만 모든 token을 아무 rank로나 보내면 all-to-all destination이 늘어 communication cost가 커질 수 있다.
그래서 SGLang은 token이 routed expert 때문에 이미 방문하는 rank들을 candidate set으로 삼는 communication-conservative mode와, 더 자유롭게 모든 rank를 볼 수 있는 all-rank mode를 구분한다.
GPU MoE serving에서는 통신이 extra shared-expert 계산보다 더 비쌀 수 있기 때문에 이 tradeoff가 중요하다.
Waterfill이 가능하려면 shared expert fusion이 먼저 필요하다.
LMSYS 글은 이 부분을 SGLang PR 두 개로 분리해 설명한다. #20089는 shared expert를 EP 아래 MoE dispatch path에 fuse하고, #19290은 그 fixed assignment를 load-aware Waterfill dispatch로 바꾼다.
즉 fusion은 load balancing 자체라기보다, shared-expert work를 DeepEP가 볼 수 있는 같은 layout 위에 올리는 enabling mechanism이다.
LPLB: redundant routed expert replica traffic을 LP로 나눈다
LPLB는 다른 선택지를 쓴다.
EPLB가 hot logical expert의 redundant physical replica를 만들어 두면, 같은 logical expert를 여러 physical copy가 처리할 수 있다.
기본 dynamic policy가 uniform random split에 가깝다면, LPLB는 이번 batch의 실제 per-expert token count를 보고 maximum per-rank load를 최소화하는 min–max linear program을 푼다.
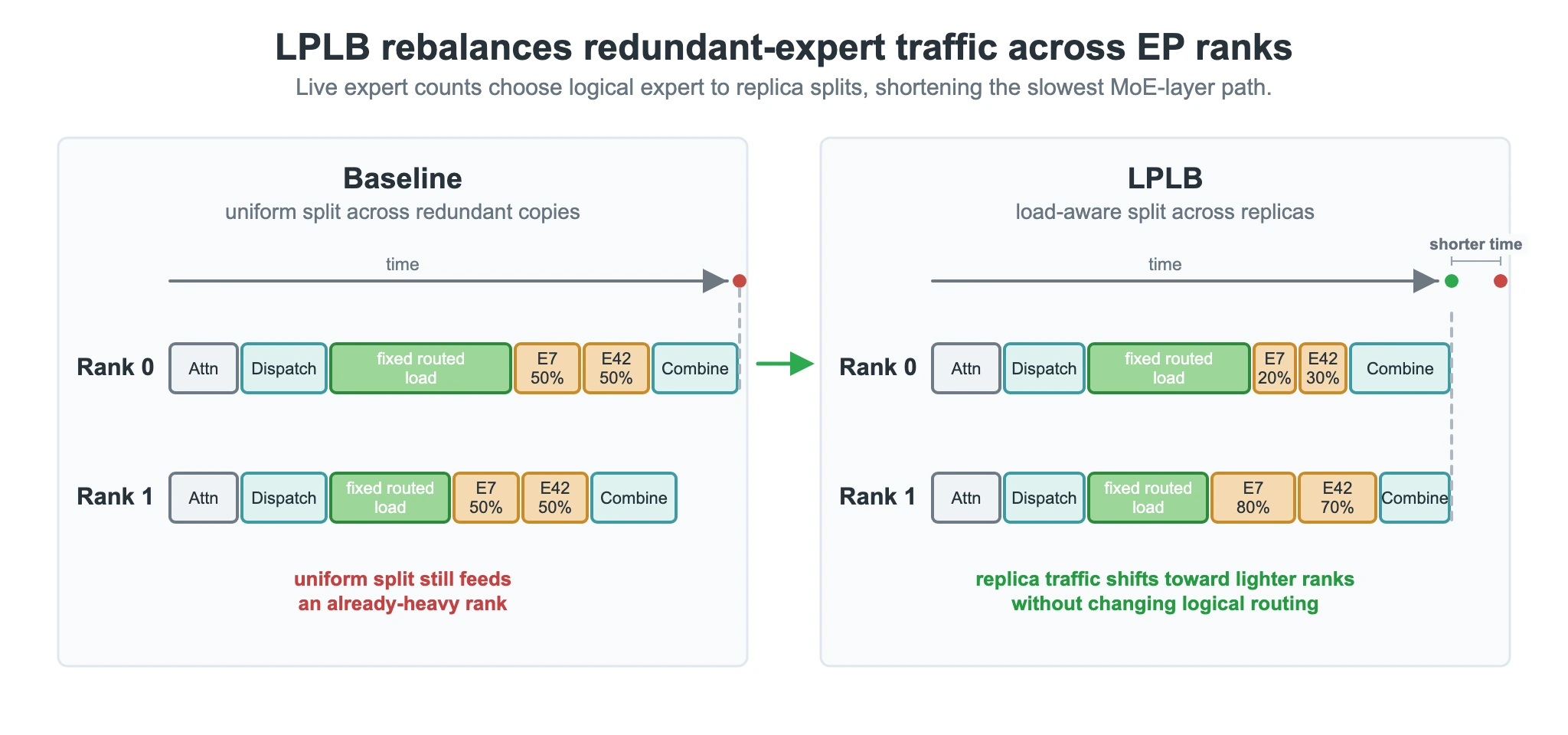
LP의 변수는 replicated expert의 per-copy load, rank별 slack, 그리고 peak load M이다.
목적함수는 M을 최소화하는 것이다.
Single-copy expert load는 fixed input으로 들어가고, replicated logical expert에 대해서는 physical copy load의 합이 observed logical expert load와 같아야 한다.
이 제약 때문에 LPLB는 token을 만들거나 버리지 않고, valid replica 사이에서만 traffic을 재배치한다.
구현 관점의 재미있는 부분은 global count 수집이다.
DP-attention에서는 rank마다 prefill/decode/idle forward mode가 다를 수 있어 한 rank가 전체 token distribution을 보지 못한다.
LPLB는 각 rank가 local token count를 세고, EP group all-reduce로 동일한 global per-expert distribution을 만든다.
그런 다음 모든 rank가 같은 LP를 독립적으로 풀기 때문에 결과를 다시 broadcast할 필요가 없다.
글은 이 LP solve가 cuSOLVERDx/cuBLASDx 기반 fused IPM kernel로 on-GPU 실행되며, per-batch path가 세 개 CUDA kernel launch로 정리된다고 설명한다.
| 구분 | Waterfill | LPLB |
|---|---|---|
| Target | 모든 token에 적용되는 shared expert | EPLB가 복제한 routed expert replica |
| Dispatch decision | token의 shared-expert slot을 어느 rank에서 실행할지 | replicated logical expert의 token을 어떤 physical copy에 나눌지 |
| 방법 | 현재 rank load를 보고 valley-filling heuristic 적용 | per-layer min–max LP를 on-GPU로 solve |
| 필요 조건 | shared expert fusion, DeepEP MoE path | redundant EPLB placement, global per-expert counts |
| 비용 | 매우 낮은 overhead | all-reduce + layer별 LP solve |
| 의미 보존 | same shared expert, physical rank만 변경 | same logical top-k expert, identical-weight replica만 선택 |
공개된 근거에서 확인되는 점
LMSYS 글은 Waterfill과 LPLB 모두 SGLang PR 흐름과 연결해 공개한다.
관련 PR은 모두 merged 상태로 확인된다. #20089는 shared expert fusion, #19290은 Waterfill dispatch balancing, #25391은 DeepSeek V4 HashTopK path에서 Waterfill 지원, #24515는 LPLB integration이다.
LPLB formulation은 DeepSeek가 공개한 deepseek-ai/LPLB 연구 코드에서 영감을 받았다고 밝힌다.
평가는 DeepSeek-V3/R1-style serving workload와 DeepSeek V4 Flash validation으로 나뉜다.
V3/R1-style matrix는 DeepSeek-V3 FP8, two Hopper GPU nodes, 16 GPUs, TP16/DP16/EP16, DP attention, DeepEP normal mode, batch size 1000, concurrency 256, max_tokens=1 조건이다.
Dataset prompt pool은 MMLU, GPQA, GSM8K다.
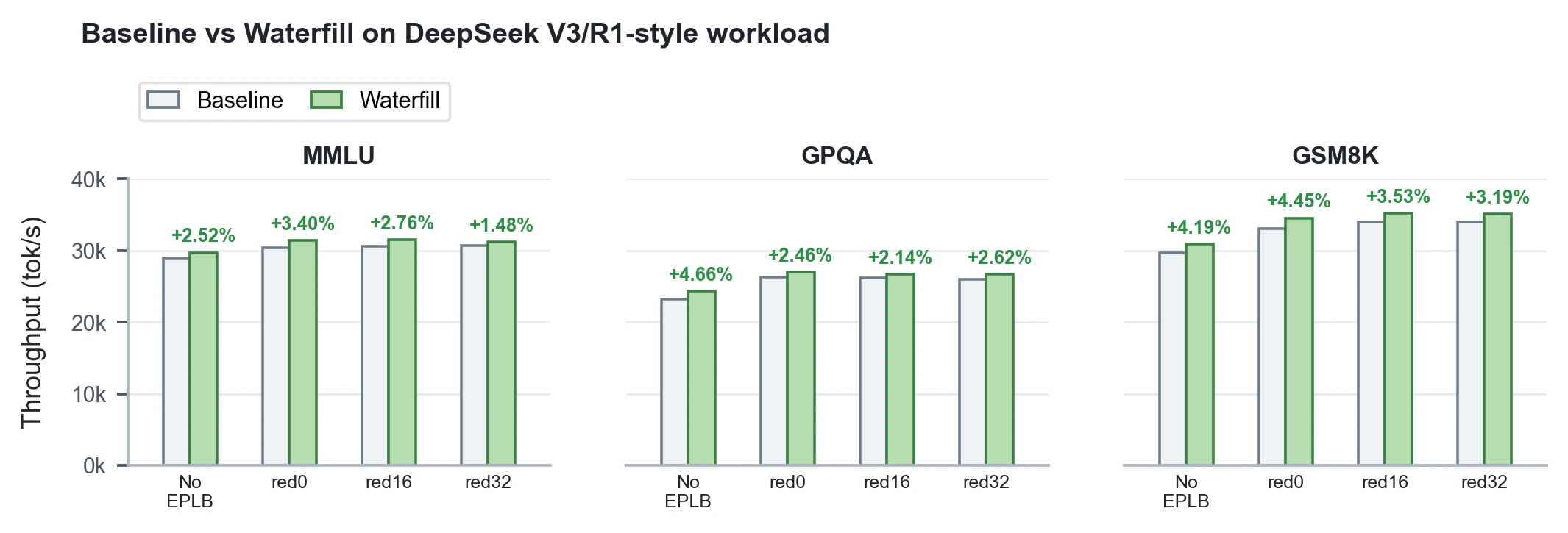
Waterfill은 no-EPLB와 static EPLB 설정 전반에서 baseline보다 높다.
예를 들어 MMLU no-EPLB는 28,968 tok/s에서 29,697 tok/s로 +2.52%, GPQA no-EPLB는 23,201 tok/s에서 24,283 tok/s로 +4.66%, GSM8K no-EPLB는 29,649 tok/s에서 30,892 tok/s로 +4.19%다.
Static EPLB red0/red16/red32에서도 +1.48%~+4.45% 범위의 개선이 보고된다.
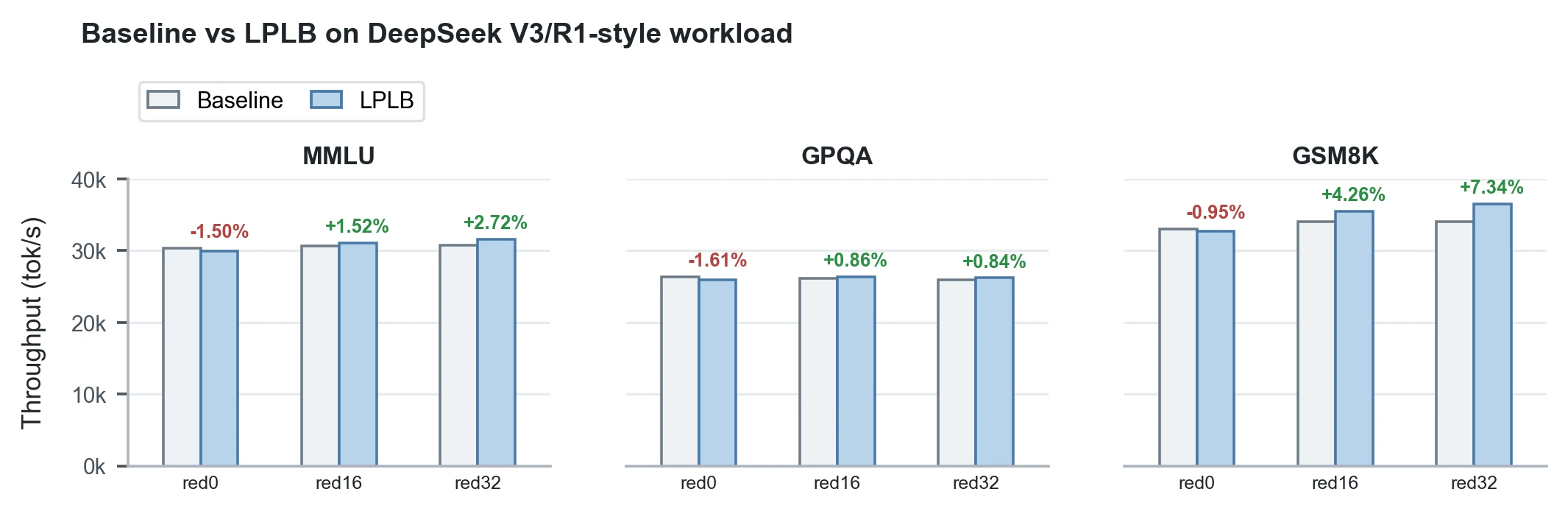
LPLB는 replica가 있을 때 효과가 더 분명하다.
MMLU red16은 +1.52%, red32는 +2.72%이고, GPQA red16/red32는 +0.86%/+0.84%다.
GSM8K에서는 red16 +4.26%, red32 +7.34%로 가장 큰 개선폭이 나온다.
반대로 red0에서는 MMLU -1.50%, GPQA -1.61%, GSM8K -0.95%처럼 손해가 난다.
이는 LPLB가 실제로 balancing할 redundant replica가 없으면 solve path의 overhead만 남는다는 해석과 일치한다.
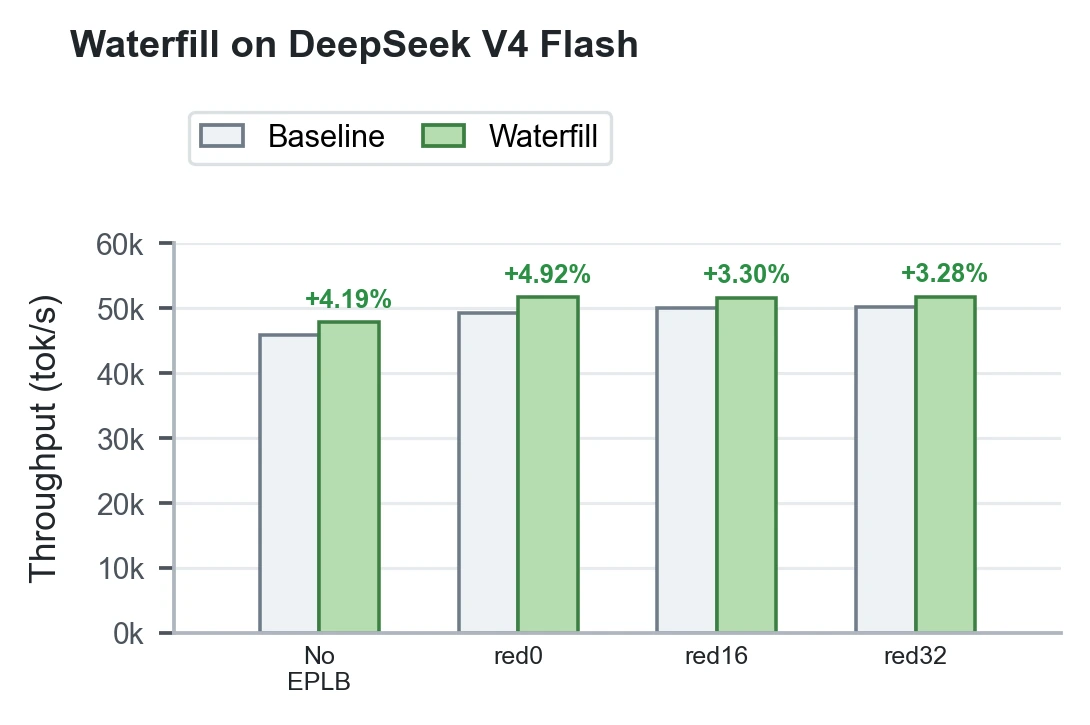
DeepSeek V4 Flash에서는 Waterfill만 별도로 검증된다.
이 run은 14,042-prompt MMLU pool, batch 512, concurrency 128, max_tokens=1, 2 warmup rounds, 4 measured rounds의 trimmed mean total throughput이다.
LMSYS는 이 결과를 V4-specific validation으로 읽어야 하며, V3/R1 matrix와 직접 비교하면 안 된다고 명시한다.
| 평가 축 | 핵심 수치 | 읽는 법 |
|---|---|---|
| Waterfill, V3/R1-style | +1.48%~+4.66% | shared expert를 lighter rank로 보내 slowest path를 줄인 효과 |
| LPLB, V3/R1-style red16/red32 | +0.84%~+7.34% | redundant replica가 있을 때 batch별 LP split이 이득을 냄 |
| LPLB, red0 | -0.95%~-1.61% | replica가 없으면 balancing 자유도가 없어 overhead가 더 큼 |
| Waterfill, DeepSeek V4 Flash | +3.28%~+4.92% | HashTopK path에서도 shared-expert balancing이 방향성 있게 작동 |
실무 관점에서의 해석
Waterfill과 LPLB의 공통 메시지는 MoE serving 최적화가 “좋은 router”만의 문제가 아니라는 것이다.
Router가 고른 logical expert는 그대로 두더라도, serving system은 physical execution placement를 조정할 수 있다.
특히 EP group이 slowest rank를 기다리는 구조에서는 평균 load보다 peak load를 낮추는 것이 직접 throughput으로 이어진다.
두 기법은 서로 대체재라기보다 보완재다.
Waterfill은 dense한 shared expert path를 다루므로 overhead가 낮고 넓게 적용될 수 있다.
LPLB는 replicated routed expert가 있어야 의미가 있지만, live batch distribution이 static EPLB calibration과 다를 때 더 정교한 split을 제공한다.
반대로 traffic이 이미 충분히 다양해 균형적이거나, 아주 좁고 반복적이어서 static placement가 distribution을 잘 맞춘다면 LPLB의 추가 solve 비용이 이득을 압도하지 못할 수 있다.
운영자가 실제로 볼 포인트도 명확하다.
Waterfill은 DeepEP MoE path에서 --enable-deepep-waterfill로 켜는 방향이고, placement metadata가 있으면 --init-expert-location이 함께 쓰인다.
LPLB는 --ep-dispatch-algorithm lp로 dispatch algorithm을 바꾸며, 반드시 --ep-num-redundant-experts로 redundant expert를 만들어야 한다. red0 결과가 보여 주듯, replica 없는 LPLB는 최적화할 선택지가 없다.
내가 보기에 이 글의 가치는 “몇 퍼센트 빨라졌다”보다 시스템 경계가 선명하다는 데 있다.
Waterfill과 LPLB는 모델 semantics를 바꾸지 않고, DeepEP layout·all-reduce count·GPU-side solve·physical replica dispatch를 조합해 runtime tail을 줄인다.
대형 MoE 모델을 실제 서비스에 올리는 팀이라면, 모델 benchmark 점수와 별개로 expert placement, replica count, dispatch policy, communication destination, live traffic drift를 함께 측정해야 한다는 신호로 읽을 만하다.