텍스트 모델의 세계에서 토큰은 너무 자연스러운 단위다.
문장을 토큰 시퀀스로 바꾸고, 모델은 그 이산 기호 위에서 예측한다.
반면 이미지는 대개 CLIP, SigLIP, DINOv2, InternViT 같은 비전 인코더가 만든 연속 고차원 특징으로 들어간다.
멀티모달 LLM은 결국 텍스트는 discrete token, 이미지는 continuous feature라는 두 표현 체계를 한 모델 안에서 이어 붙여야 한다.
ViQ: Text-Aligned Visual Quantized Representations at Any Resolution는 이 간극을 줄이려는 논문이다.
핵심은 이미지를 텍스트처럼 이산 코드로 바꾸되, 기존 visual tokenizer처럼 픽셀 재구성만 잘하거나, 반대로 semantic encoder처럼 의미만 남기고 세부를 잃는 쪽으로 치우치지 않게 만드는 것이다.
저자들은 이를 위해 텍스트 정렬 pre-training, proximal representation learning, position-aware head-wise FSQ quantization을 결합한다.
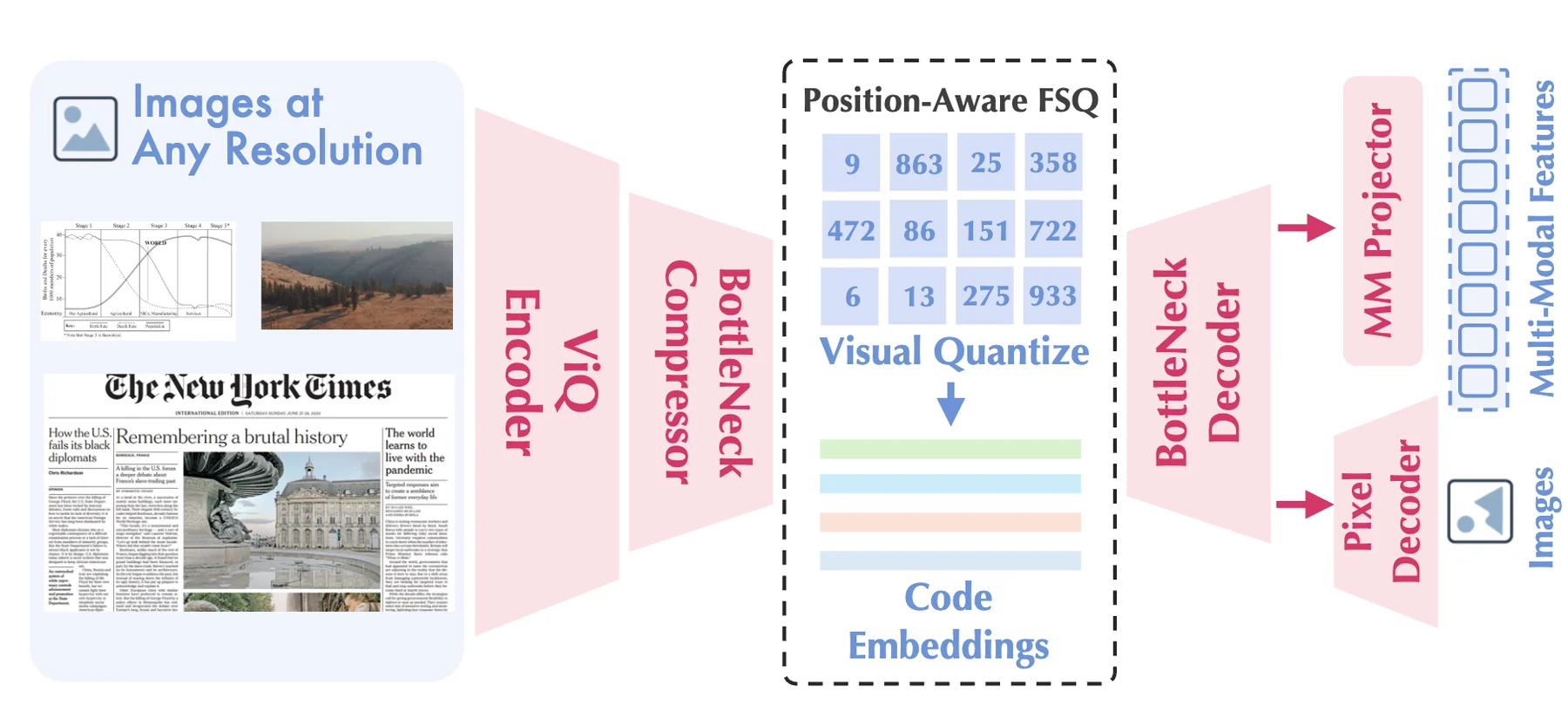
흥미로운 점은 ViQ가 단순한 압축 포맷도, 단순한 VLM encoder도 아니라는 데 있다.
이미지를 이산 코드로 저장하고 다시 복원할 수 있어야 하지만, 동시에 Qwen2.5 계열 LLM이 그 코드를 받아 문서·OCR·차트·VQA 문제를 풀 수 있어야 한다.
즉 ViQ의 질문은 “이미지를 얼마나 작게 저장할 수 있는가”보다 이미지 표현을 언어 모델의 토큰 세계에 얼마나 손실 적게 들여올 수 있는가에 가깝다.
무엇을 해결하려는가
기존 멀티모달 학습에서 연속 비전 특징은 강력하지만 비싸다.
이미지를 매번 비전 인코더에 통과시켜 고차원 feature를 만들고, 이를 LLM 입력 공간에 projection해야 한다.
긴 시퀀스, 많은 이미지, 대규모 SFT에서는 이 인코더 forward pass가 훈련 비용의 의미 있는 부분을 차지한다.
그렇다고 이미지를 바로 이산 코드로 바꾸면 다른 문제가 생긴다. reconstruction-oriented tokenizer는 픽셀과 질감은 잘 보존하지만 semantic alignment가 약할 수 있다.
반대로 QLIP, UniTok처럼 이해 쪽을 노린 tokenizer도 OCR, 문서, 차트, 세부 시각 정보가 필요한 과제에서는 continuous encoder와 큰 차이를 보일 수 있다.
ViQ가 겨냥하는 병목은 이 세 가지다.
| 병목 | 기존 접근의 문제 | ViQ의 방향 |
|---|---|---|
| 표현 불일치 | 텍스트는 token, 이미지는 continuous feature | 이미지를 이산 visual code sequence로 만든다 |
| 세부-의미 trade-off | 재구성 tokenizer는 의미가 약하고, semantic feature는 양자화 시 세부 손실이 큼 | 텍스트 supervision과 재구성 loss를 함께 쓴다 |
| 해상도 제약 | 많은 encoder/tokenizer가 고정 해상도에 묶임 | NaViT/OryxViT식 native-resolution 처리를 붙인다 |
| 학습 비용 | 매 step마다 무거운 visual encoder forward가 필요 | visual code를 offline precompute해 재사용한다 |
이런 이유로 ViQ는 foundation model 자체라기보다, 멀티모달 모델을 만드는 시각 토큰 기반 표현 계층에 가깝다.
좋은 visual tokenizer가 있으면 이미지도 텍스트처럼 사전 계산된 토큰으로 캐시하고, LLM 학습 단계에서는 그 토큰을 빠르게 embedding으로 바꿔 넣을 수 있다.
핵심 아이디어 / 구조 / 동작 방식
ViQ는 두 단계로 학습된다.
첫 번째는 continuous visual encoder를 텍스트와 잘 맞추는 단계이고, 두 번째는 그 feature를 이산 코드로 줄이는 단계다.
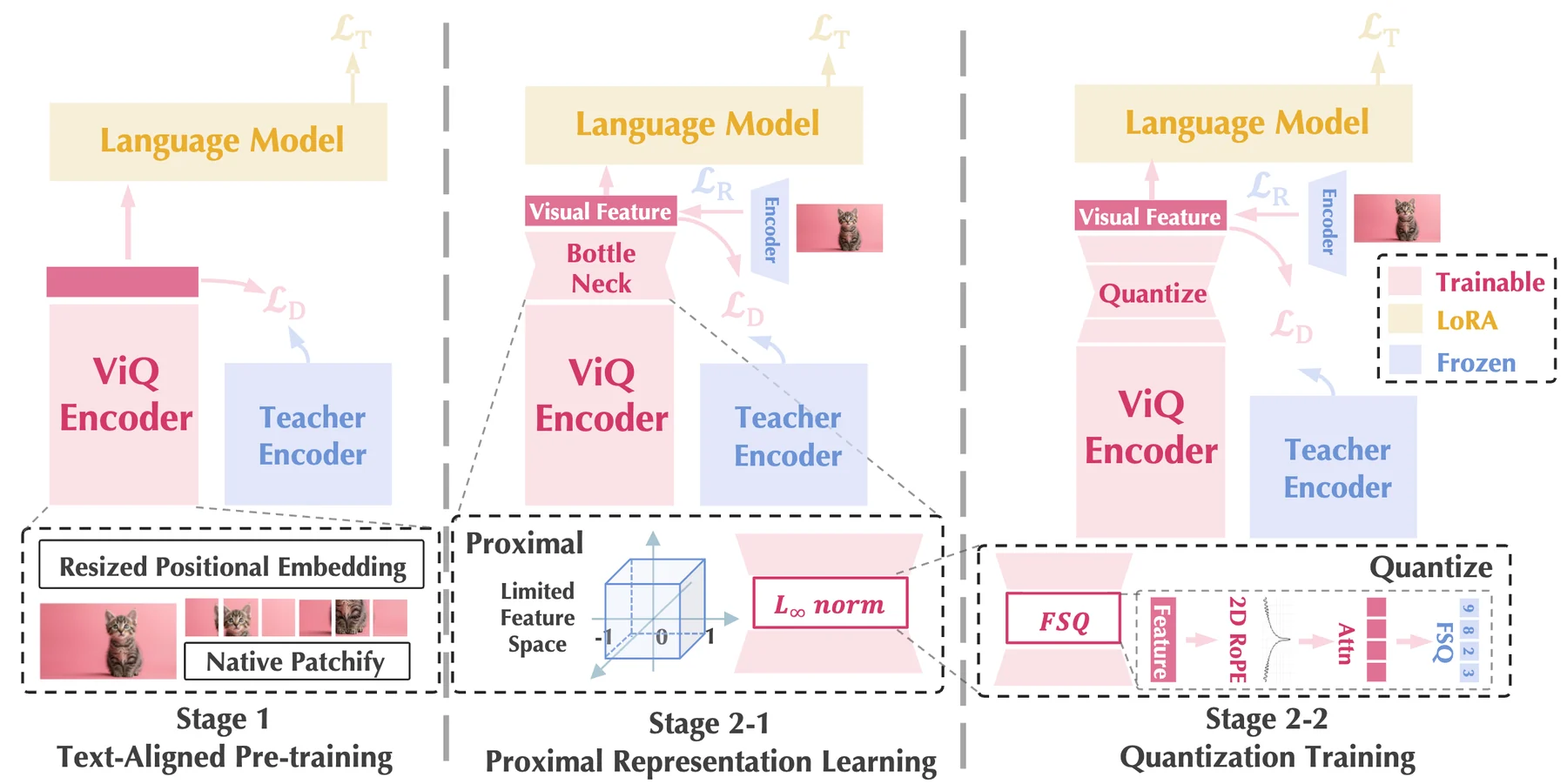
Stage 1은 Text-Aligned Pre-Training at Any Resolution이다.
출발점은 SigLIP2-g visual encoder다.
저자들은 고정 해상도 positional embedding을 임의 해상도에 맞게 바꾸고, NaViT/OryxViT 스타일의 variable-length visual token 처리를 사용한다.
여기에 이미지-질문-답변 triplet을 넣고, 임시 LLM의 answer prediction loss로 visual feature가 언어 모델링 목적에 맞게 정렬되도록 학습한다.
동시에 self-distillation도 쓴다.
원래 fixed-resolution SigLIP2-g를 teacher로 두고, any-resolution student의 semantic token이 teacher의 semantic token과 크게 어긋나지 않도록 cosine loss를 건다.
이는 멀티모달 QA 데이터에 과적합하면서 기존 language-image pretraining에서 얻은 일반 시각 의미가 망가지는 것을 막기 위한 장치다.
Stage 2는 Visual Quantized Representation Learning이다.
여기서 바로 고차원 feature를 codebook에 던지지 않는다.
먼저 1536차원 SigLIP2-g feature를 bottleneck으로 줄이고, L∞ norm constraint를 통해 feature를 hypercube surface 근처로 밀어 넣는다.
논문은 이를 proximal representation이라고 부른다.
요지는 feature space를 점진적으로 양자화하기 쉬운 모양으로 만들면, 직접 quantization할 때보다 정보 손실이 줄어든다는 것이다.
마지막에는 Finite Scalar Quantization, 즉 FSQ를 쓴다.
ViQ의 주 설정은 64,000개 codebook size이며, 구현상 levels는 [8, 8, 8, 5, 5, 5]다.
각 visual patch는 multi-head attention으로 2×2 code로 확장되고, quantization 직전에 2D RoPE가 들어가 위치 정보를 보존한다.
이렇게 하면 arbitrary resolution에서도 각 code가 독립적이고 위치 aware한 visual token으로 동작할 수 있다.
| 구성 요소 | 공개 자료에서 확인되는 내용 | 의미 |
|---|---|---|
| Base visual tower | SigLIP2-g, output dim 1536 | 강한 continuous encoder에서 출발 |
| Any-resolution 처리 | NaViT/OryxViT식 variable token, resized positional embedding | 원본 aspect ratio와 native resolution을 더 자연스럽게 다룸 |
| Proximal representation | bottleneck + L∞ regularization |
quantization 전 feature space를 압축·정렬 |
| Quantization | position-aware head-wise FSQ, 2D RoPE | 임의 해상도 visual code의 위치 정보를 보존 |
| Low-level supervision | Qwen-Image encoder latent reconstruction loss | OCR·차트·세부 질감 손실을 줄이려는 장치 |
공개된 근거에서 확인되는 점
멀티모달 이해 결과에서 ViQ의 위치는 꽤 뚜렷하다.
Qwen2.5-1.5B를 base LLM으로 쓴 실험에서 ViQ는 9개 benchmark 평균 57.2를 보고한다.
이는 같은 조건의 QLIP 29.7, UniTok 33.0보다 훨씬 높고, continuous encoder인 InternViT-2.5 56.5, InternViT-2.5-6B 57.0과 비슷하거나 약간 앞선다.
Qwen2.5-7B 조건에서는 ViQ 평균 63.9로, InternViT-2.5-6B 63.8과 거의 같은 수준이다.
| Base LLM | Visual encoder | AnyRes | Discrete | Avg. | 눈에 띄는 점 |
|---|---|---|---|---|---|
| Qwen2.5-1.5B | QLIP | ✗ | ✓ | 29.7 | 기존 discrete encoder와 큰 격차 |
| Qwen2.5-1.5B | UniTok | ✗ | ✓ | 33.0 | OCR/문서 계열에서 약함 |
| Qwen2.5-1.5B | InternViT-2.5 | ✗ | ✗ | 56.5 | 강한 continuous baseline |
| Qwen2.5-1.5B | ViQ | ✓ | ✓ | 57.2 | discrete이면서 continuous encoder 수준에 접근 |
| Qwen2.5-7B | InternViT-2.5-6B | ✗ | ✗ | 63.8 | 6B급 continuous encoder |
| Qwen2.5-7B | ViQ | ✓ | ✓ | 63.9 | 더 작은 visual representation으로 유사 평균 |
세부 항목을 보면 ViQ의 장점은 특히 문서·텍스트가 있는 시각 과제에서 드러난다.
Qwen2.5-1.5B 조건에서 InfoVQA 41.6, DocVQA 84.2, ChartQA 65.2가 보고되고, Qwen2.5-7B 조건에서는 InfoVQA 55.3, DocVQA 88.9, OCRBench 711.0을 기록한다.
이 수치를 단순히 “모든 continuous encoder를 이겼다”로 읽으면 안 되지만, 기존 discrete visual tokenizer가 세부 텍스트·문서 과제에서 크게 무너졌던 것과 비교하면 차이가 크다.
재구성 실험도 흥미롭다.
ImageNet-1K 256×256 validation에서 ViQ는 16×16 token 기준 PSNR 22.73, SSIM 0.66, rFID 0.62를 보고한다.
PSNR만 보면 UniTok 25.32보다 낮지만, rFID는 Open-MAGVIT2 1.67, QLIP-B 3.21보다 좋고 UniTok 0.37 다음 수준이다.
즉 ViQ는 순수 압축 codec처럼 픽셀 지표를 극대화한 모델이 아니라, 이해 성능과 재구성 품질 사이의 절충점으로 봐야 한다.

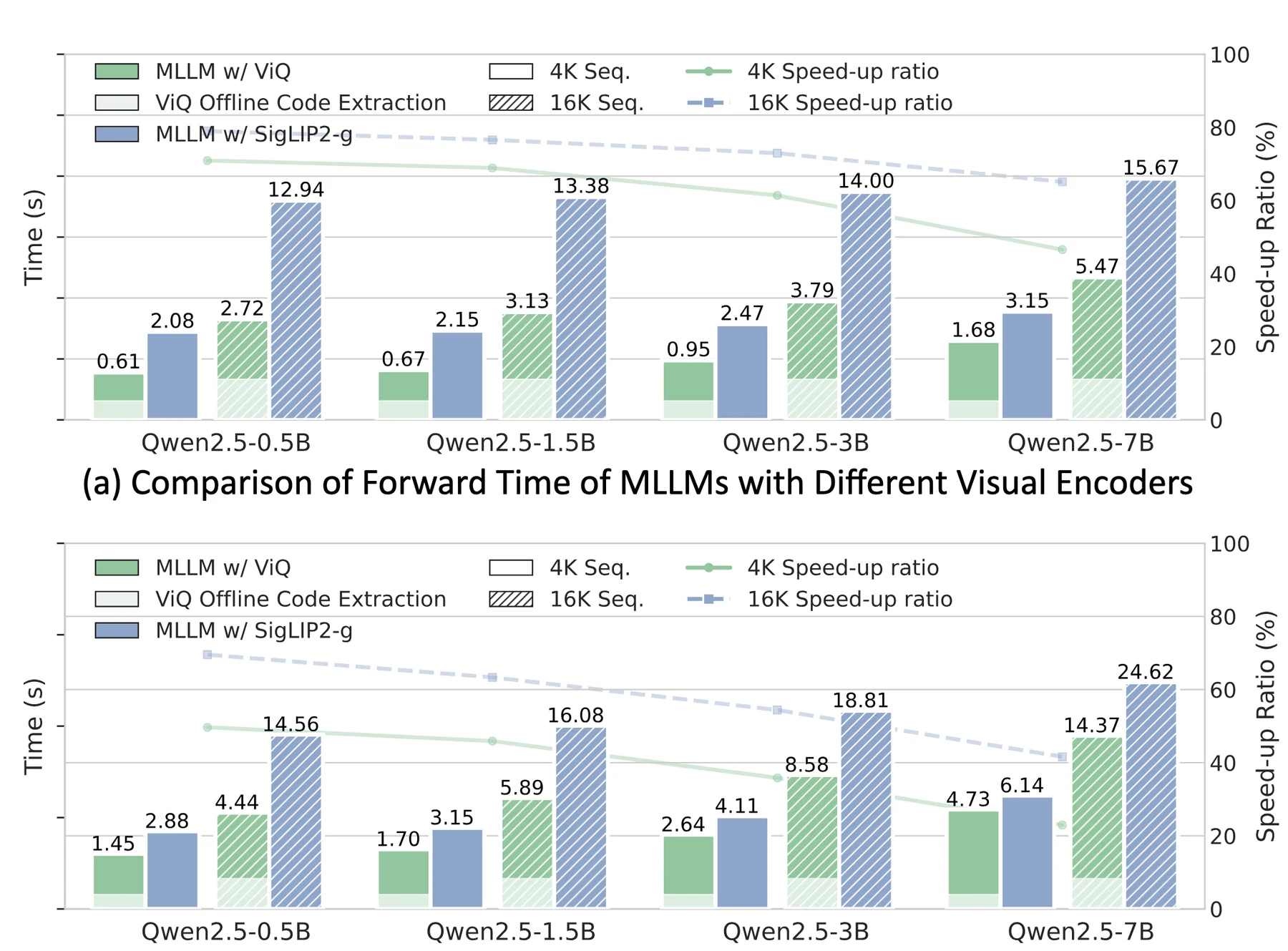
효율 쪽에서는 offline code precompute가 핵심이다.
논문은 ViQ code를 미리 뽑아 두면 VLM SFT 중 raw image를 매번 SigLIP2-g에 통과시키지 않아도 된다고 설명한다.
Qwen2.5 0.5B에서 forward time은 4K setting에서 70%, 16K setting에서 78% 빨라지고, Qwen2.5 7B에서도 forward time 기준 46%, 65% speed-up이 보고된다.
전체 training iteration 기준으로도 4K에서는 20% 이상, 16K에서는 40% 이상 개선된다고 한다.
공개 릴리스 상태도 확인할 만하다.
GitHub yuxumin/ViQ는 Apache-2.0 라이선스로 training code, inference code, converter, example script, assets를 공개한다.
확인 시점 기준 repo는 2026년 6월 12일 생성, 6월 26일 push, 115 stars, 3 forks, tags 0개, latest release 404 상태였다.
따라서 코드가 공개된 연구 repo이긴 하지만, versioned library release라고 보기는 아직 이르다.
Hugging Face XuminYu/ViQ_weights에는 Stage 1 any-resolution ViT weight 두 종류와 Stage 2 ViQ tokenizer weight 다섯 종류가 올라와 있다. anyres_vit/so400m, anyres_vit/giant1b가 continuous stage이고, ViQ/converted_2k, converted_4k, converted_8k, converted_16k, converted_64k가 FSQ codebook size별 discrete tokenizer다.
각 converted folder는 model_viq_fsq_<size>.pth, embedder.pth, index_drawer.pth를 포함한다.
모델 API 기준 public, gated false이며, 모델 카드 YAML metadata는 비어 있다는 warning도 보인다.
다만 README의 roadmap도 같이 봐야 한다. pretrained ViQ checkpoint와 논문은 공개됐지만, lightweight reconstruction decoder와 REPA 기반 training recipe는 future release로 표시되어 있다.
즉 “이산 visual representation을 바로 시험해 볼 수 있는 code/weights”는 공개됐지만, 논문 전체의 재구성 학습 recipe가 완전히 패키징됐다고 말하기에는 이르다.
실무 관점에서의 해석
ViQ의 가장 중요한 의미는 멀티모달 학습의 비용 구조를 바꾸는 데 있다.
지금까지 많은 VLM은 이미지 입력을 매번 vision tower로 처리하고, 그 feature를 LLM에 붙였다.
이 방식은 단순하지만, 대규모 학습에서는 이미지가 텍스트 토큰처럼 캐시되기 어렵다.
ViQ가 충분히 강한 visual code를 제공한다면, 이미지도 텍스트 token ID처럼 offline preprocessing과 cache의 대상이 된다.
특히 작은 LLM과 긴 시퀀스 학습에서 이 방향은 실용적이다.
LLM이 0.5B~1.5B처럼 작을수록 SigLIP2-g 같은 1B급 visual tower의 forward 비용이 상대적으로 크게 보인다.
ViQ의 speed-up 결과가 작은 backbone에서 더 크게 나온 것도 이 때문이다. edge VLM, domain-specific VLM, 대량 이미지 instruction tuning처럼 모델 본체는 작지만 이미지 수가 많은 상황에서는 visual code caching이 꽤 현실적인 절감 수단이 될 수 있다.
또 하나의 함의는 visual tokenizer 평가 방식이다. tokenizer를 압축률이나 rFID만으로 보면 ViQ의 목적을 놓친다.
반대로 VQA 평균만 보면 reconstruction과 storage 쪽 장점이 사라진다.
ViQ는 이해 가능한 visual token과 복원 가능한 visual token을 동시에 노린다.
그래서 평가도 MMStar/MMMU/TextVQA/DocVQA/OCRBench/ChartQA 같은 이해 지표와 PSNR/SSIM/rFID 같은 재구성 지표를 함께 봐야 한다.
한계도 분명하다.
첫째, 논문은 0.5B~7B 규모의 Qwen2.5 LLM에서 효과를 검증했지만, 70B 이상 대형 foundation model과의 상호작용은 future work로 남겼다.
둘째, Stage 1/2 학습은 각각 128/256 NVIDIA A100 GPU를 쓰는 큰 훈련이다.
공개 repo에 single-stage training example이 있더라도, 논문 전체 레시피를 같은 규모로 재현하는 것은 가벼운 작업이 아니다.
셋째, discrete code가 학습 데이터 편향이나 out-of-domain 시각 정보를 어떻게 보존·손실하는지도 실제 도메인별 검증이 필요하다.
그럼에도 ViQ는 좋은 방향을 보여 준다.
멀티모달 모델이 계속 커질수록 “이미지를 어떻게 볼 것인가”만큼 “이미지를 어떤 토큰으로 저장하고 재사용할 것인가”가 중요해진다.
ViQ는 이 질문에 대해 꽤 균형 잡힌 답을 제시한다.
텍스트 정렬로 semantic gap을 줄이고, proximal representation과 FSQ로 quantization loss를 낮추고, reconstruction loss로 low-level detail을 붙잡는다.
실무적으로는 이것을 완성된 범용 VLM보다, 다음 세대 VLM 학습 파이프라인의 visual token cache layer 후보로 읽는 편이 정확하다.