온디바이스 LLM에서 어려운 부분은 모델을 작게 만드는 것만이 아니다.
스마트폰은 서버 GPU처럼 메모리와 전력을 넉넉하게 쓸 수 없고, 사용자는 알림 요약이나 문장 교정 같은 기능이 거의 즉시 반응하기를 기대한다.
그런데 일반적인 LLM decode는 한 번에 한 토큰씩 진행된다.
긴 답변이 아니더라도 매 토큰마다 큰 backbone을 깨워야 하므로 지연 시간, 메모리 대역폭, 배터리 소모가 곧바로 체감 품질이 된다.
Google Research의 Accelerating Gemini Nano models on Pixel with frozen Multi-Token Prediction은 이 병목을 “이미 배포된 모델을 어떻게 더 빠르게 실행할 것인가”라는 관점에서 다룬다.
핵심은 Gemini Nano v3의 기존 backbone weight는 고정한 채, 마지막 hidden state를 이용하는 MTP head를 붙여 여러 미래 토큰 후보를 먼저 만들고, backbone이 이를 병렬로 검증하게 하는 것이다.
별도의 작은 drafter 모델을 추가하는 대신, main model이 이미 계산한 표현과 KV cache를 재사용한다는 점이 중요하다.
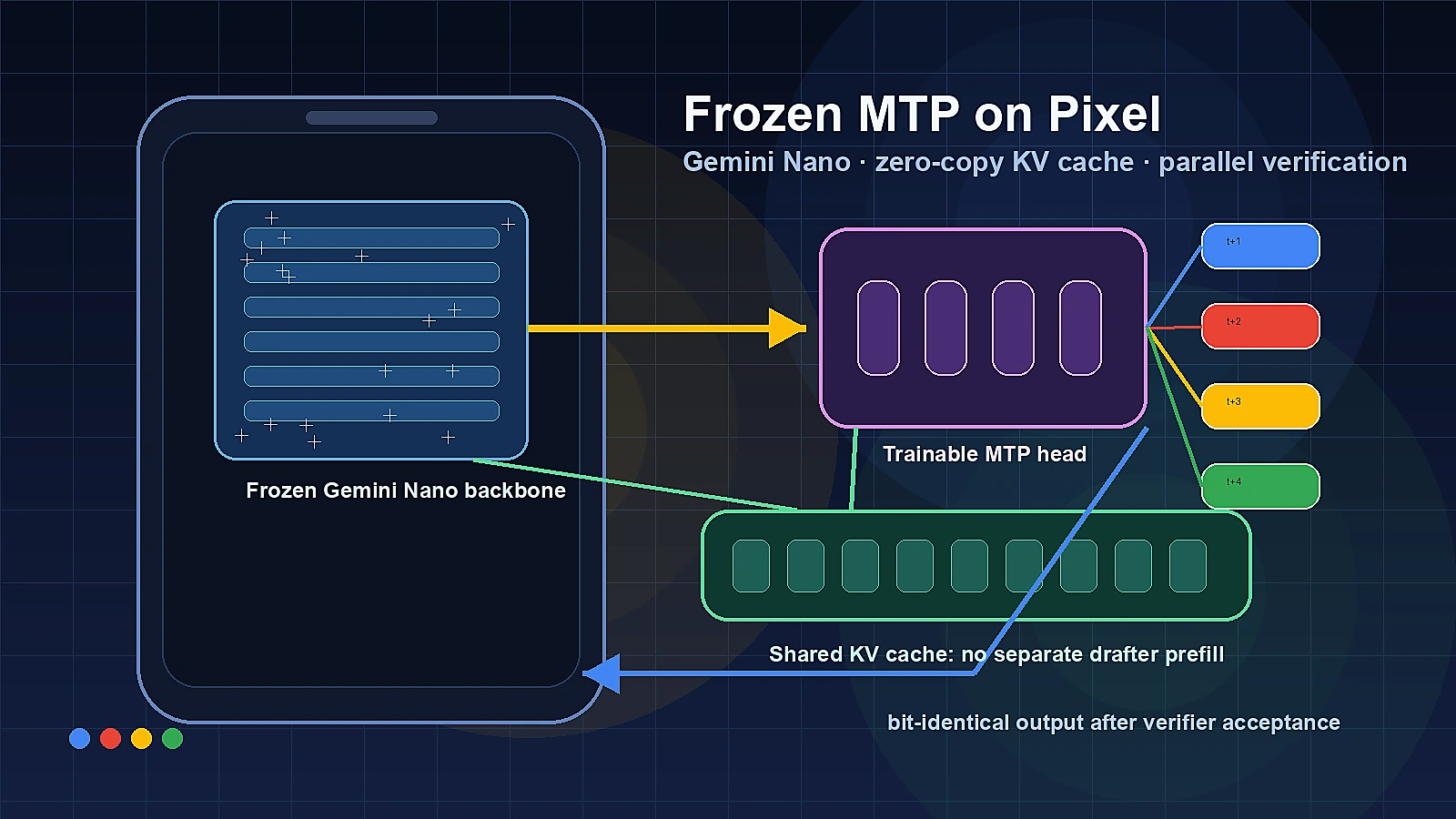
이 접근은 최근 Pixel 9 및 Pixel 10 시리즈에 rollout되었고, Google은 AI Notification Summaries, Proofread 같은 Gemini Nano 기반 온디바이스 텍스트 생성 기능이 더 빠르고 에너지 효율적으로 동작한다고 설명한다.
개발자 관점에서는 “각 앱 기능마다 별도 drafter를 튜닝해서 들고 다니는” 부담을 줄이는 시스템 업데이트에 가깝다.
무엇을 해결하려는가
Speculative decoding의 기본 아이디어는 단순하다.
작은 drafter가 몇 개의 후보 토큰을 먼저 예측하고, 큰 verifier가 그 후보를 한 번에 검증한다.
후보가 verifier의 다음 토큰과 맞으면 여러 토큰을 한 pass에서 받아들이고, 틀리면 처음 어긋난 지점부터 다시 진행한다.
잘 맞는 drafter만 있다면 큰 모델을 매 토큰마다 순차적으로 호출하는 것보다 빠르다.
문제는 모바일이다.
일반적인 standalone drafter는 작더라도 별도의 모델이다.
Google 글은 예시로 128M parameter급 drafter를 언급한다.
이 drafter는 main model과 RAM을 나눠 써야 하고, 자체 embedding·prefill·KV cache를 유지해야 한다.
게다가 drafter는 main model 내부의 풍부한 hidden state를 보지 못한다.
텍스트 history만 보고 다음 토큰을 맞히는 셈이라, 복잡한 요약·rewrite·instruction following에서는 후보 acceptance rate가 떨어질 수 있다.
따라서 Pixel 같은 edge device에서 중요한 질문은 “drafter를 얼마나 작게 만들 수 있는가”보다 더 구체적이다.
이미 main model이 계산한 표현과 cache를 얼마나 재사용하면서, 출력은 기존 모델과 동일하게 유지할 수 있는가다.
Frozen MTP는 이 질문에 대한 Google식 답변이다.
| 병목 | Standalone drafter 방식 | Frozen MTP 방식 |
|---|---|---|
| 메모리 | 별도 model weight, embedding, KV cache가 main model과 경쟁 | MTP head가 main model의 hidden state와 frozen KV cache를 직접 활용 |
| prefill | drafter도 prompt/context를 별도로 처리해야 함 | 기존 cache를 사용해 drafter prefill latency를 제거 |
| 품질 / safety | drafter 후보가 main model 내부 표현을 보지 못함 | verifier가 최종 토큰을 검증하므로 accepted output은 backbone 기준과 동일 |
| 배포 단위 | 앱·task별 drafter tuning과 runtime packaging 부담 | frozen backbone에 head를 retrofit하는 efficiency update |
핵심 아이디어 / 구조 / 동작 방식
Google은 이 구조를 late exit strategy로 설명한다.
완전히 별도의 언어 모델을 drafter로 두는 대신, Gemini Nano v3의 마지막 layer 근처에서 나온 high-dimensional activation을 MTP head에 넘긴다.
MTP head는 dense Transformer stack으로 구성되고, 여러 future token을 autoregressive하게 예측한다.
이 head만 학습하고 backbone weight는 frozen 상태로 둔다.
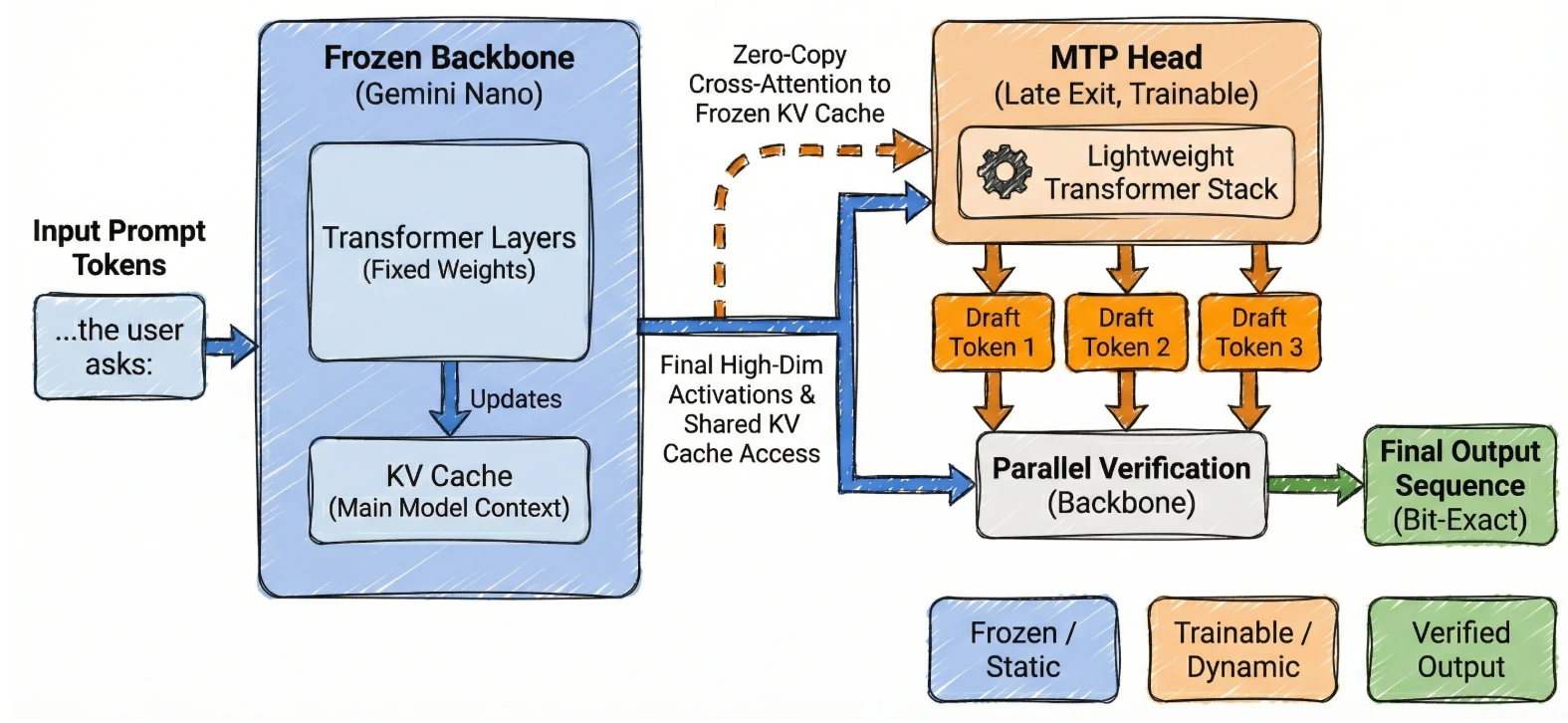
여기서 “frozen”이라는 단어가 중요하다.
Google은 이미 완전히 학습된 Gemini Nano v3를 가져와 weight를 바꾸지 않고, 미래 토큰 예측 오류를 줄이도록 MTP head parameter만 학습한다고 설명한다.
MTP가 base capability나 safety alignment를 바꾸는 학습 업데이트가 아니라, decode 효율을 높이는 runtime optimization으로 제한되는 이유다.
두 번째 핵심은 zero-copy architecture다.
표준 MTP 구현은 embedding weight 같은 static parameter를 공유해 학습 효율을 높일 수 있지만, 온디바이스 추론에서는 dynamic memory가 더 아프다.
Drafter가 context를 독립적으로 처리하면 자체 KV cache를 만들고 유지해야 하므로, 제한된 RAM에서 “double tax”가 생긴다.
Google의 MTP head는 main model의 frozen KV cache에 cross-attend하도록 설계되어, 이미 backbone이 만든 context memory를 query한다.
이 설계의 효과는 두 가지로 정리된다.
첫째, drafter가 prompt를 다시 prefill하지 않아도 된다.
둘째, runtime memory footprint가 줄어든다.
Google은 standalone drafter 대비 drafter embedding lookup table, prefill dot-attention variants, application-specific tuning parameters 등을 줄여 instance당 최대 130MB의 메모리 절감을 관찰했다고 쓴다.
공개된 근거에서 확인되는 점
공개 글에서 확인되는 정량 근거는 세 축이다.
하나는 메모리 절감, 하나는 후보 수용률과 end-to-end latency, 마지막 하나는 실제 Pixel feature rollout이다.
먼저 architecture 관점에서는 shared KV cache가 핵심 근거다.
MTP head가 main model의 hidden state와 KV cache를 활용하기 때문에, 별도 drafter보다 더 풍부한 표현을 보고 후보를 낸다.
Google은 summarization이나 rewriting처럼 constraint가 복잡한 작업에서 MTP가 standalone fine-tuned drafter보다 유리했고, smart replies처럼 구조가 예측 가능한 작업에서는 token acceptance가 최대 55% 개선되었다고 설명한다.
두 번째 근거는 Pixel 9 결과 figure다.
이 figure는 tuned standalone drafter를 기준으로 MTP가 acceptance rate와 E2E latency를 얼마나 개선했는지를 앱/작업별로 보여 준다.
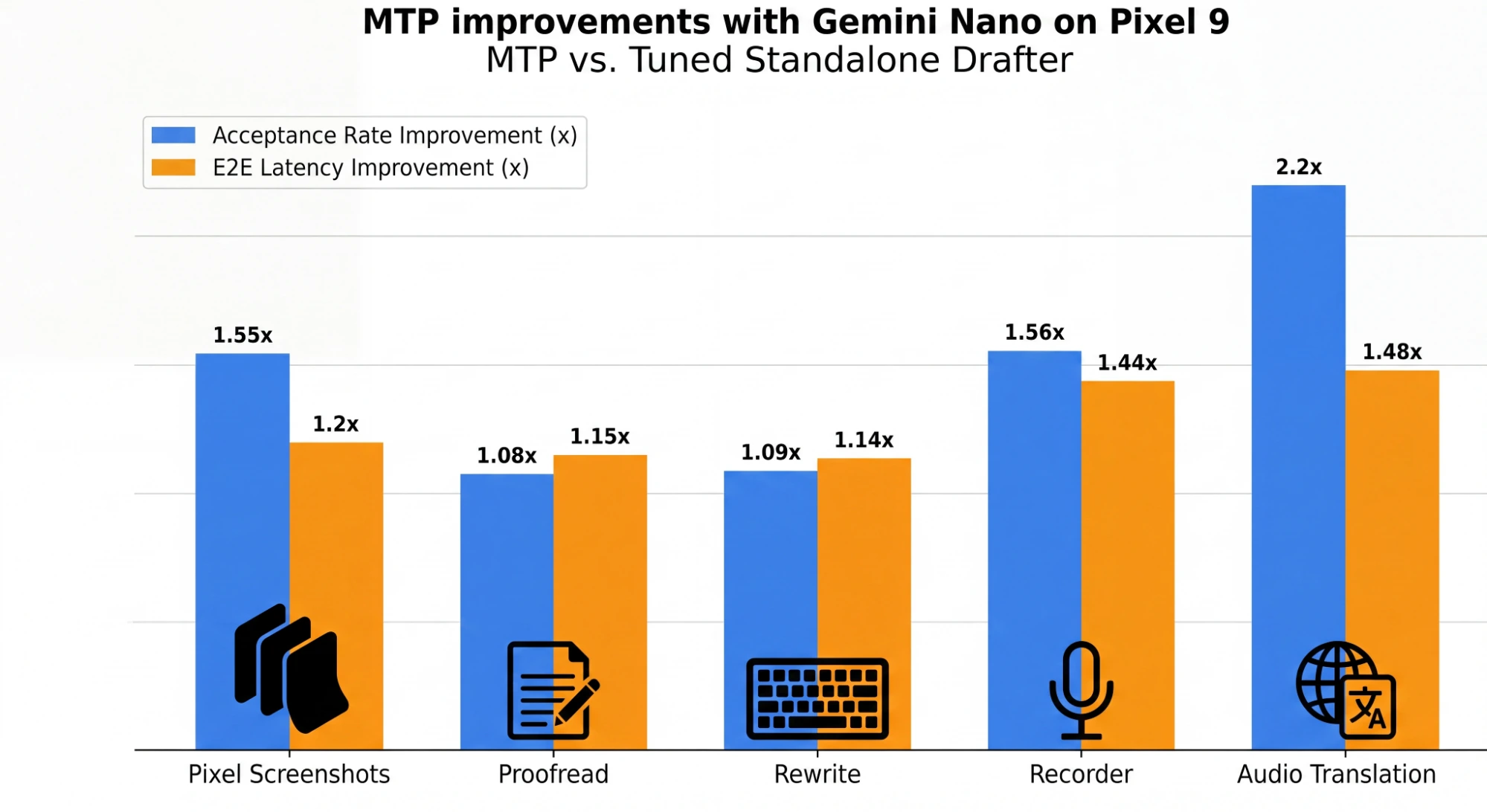
| Pixel 9 작업 | Acceptance rate 개선 | E2E latency 개선 | 해석 |
|---|---|---|---|
| Pixel Screenshots | 1.55x | 1.20x | 후보는 훨씬 잘 맞지만 전체 pipeline latency 개선은 완만하다. |
| Proofread | 1.08x | 1.15x | 텍스트 교정 작업에서는 안정적이지만 작은 폭의 개선이다. |
| Rewrite | 1.09x | 1.14x | rewrite도 Proofread와 비슷하게 점진적 latency 개선을 보인다. |
| Recorder | 1.56x | 1.44x | 음성 기록/요약 계열에서 acceptance와 latency가 함께 크게 개선된다. |
| Audio Translation | 2.20x | 1.48x | 후보 수용률 개선이 가장 크고, E2E latency도 figure 내 최대권이다. |
세 번째 근거는 production workload 관찰이다.
Google은 AI Notification Summaries와 Proofread 같은 실제 workload에서 MTP가 inference pass당 평균적으로 거의 두 개의 additional token을 올바르게 예측한다고 설명한다.
검증 단계가 줄어들면 heavy processor를 깨우는 횟수도 줄어들어, 지연 시간뿐 아니라 에너지와 배터리에도 이점이 생긴다.
실무 관점에서의 해석
이 업데이트의 실무적 의미는 “Gemini Nano가 더 빨라졌다”보다 조금 더 흥미롭다.
Frozen MTP는 온디바이스 LLM 최적화를 모델 재학습 문제가 아니라 배포된 model backbone 위의 execution policy 문제로 바꾼다.
이미 제품 safety와 capability 검증을 통과한 backbone을 건드리지 않고, output은 verifier를 통해 bit-for-bit 동일하게 유지하면서 decode 경로만 빠르게 만드는 방식이다.
앱 팀 입장에서는 이 차이가 크다.
별도 drafter를 기능별로 학습·패키징·검증하면 모델 수, memory footprint, tuning surface, regression test가 모두 늘어난다.
반대로 frozen backbone에 붙는 MTP head가 공통 runtime acceleration layer로 동작하면, 기능별 prompt나 task가 달라도 “후보를 만들고 verifier가 승인한다”는 구조는 재사용할 수 있다.
물론 공개 글 기준으로는 head 크기, training corpus, runtime integration API, 개발자에게 노출되는 제어권까지 모두 공개된 것은 아니다.
따라서 이것은 오픈 배포 recipe라기보다 Pixel 제품 스택 안에서 rollout된 inference-system update로 보는 편이 정확하다.
또 하나의 포인트는 정확도 주장보다 동일 출력 보존이다.
Speculative decoding 계열 최적화는 drafter가 틀릴 수 있다는 사실을 전제로 한다.
중요한 것은 틀린 후보를 버리고 verifier의 토큰으로 돌아오는 검증 규칙이다.
Google이 “incorrect drafts are discarded”와 “bit-for-bit identical”을 강조하는 이유도 여기에 있다.
속도 최적화가 모델 behavior drift로 이어지지 않아야, production mobile feature에 상대적으로 안전하게 들어갈 수 있다.
앞으로의 방향도 이 관점에서 읽을 만하다.
Google은 future Pixel device에 MTP를 더 통합하고, auxiliary head 없이 parallel decoding을 하거나, single best future path 대신 branching possibilities를 병렬로 탐색하는 방법, 그리고 use case별로 verification leniency를 조절하는 방법을 연구한다고 밝혔다.
현재 방식은 strict exact-token match를 유지하므로 보수적이고 안전하지만, 더 공격적인 edge inference optimization은 “얼마나 느슨하게 검증해도 사용자 경험과 품질을 해치지 않는가”라는 제품별 정책 문제로 이어질 수 있다.
결국 Frozen MTP의 핵심은 작은 trick 하나가 아니다.
스마트폰 위 LLM을 빠르게 만들려면 backbone, drafter, KV cache, verifier, 앱 workload, 배터리 예산을 한 시스템으로 봐야 한다는 메시지다.
Pixel 9·10 rollout은 그런 관점이 연구 prototype을 넘어 실제 소비자 기기 기능에 들어가고 있음을 보여 주는 사례다.