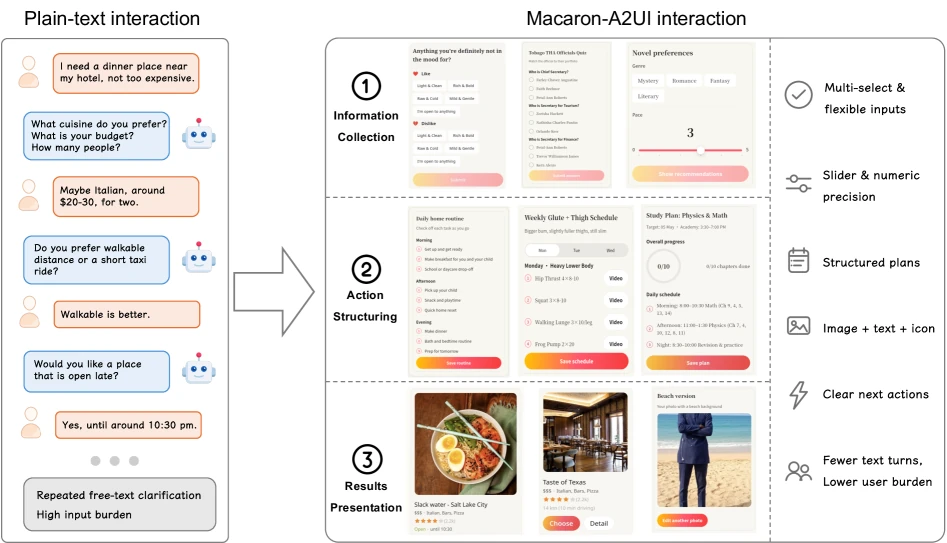
개인 에이전트가 일정 조율, 여행 예약, 상담, 의사결정 보조처럼 여러 상태와 선택지를 다루기 시작하면 순수 텍스트 채팅은 금방 병목이 된다.
사용자는 긴 설명문을 읽고 다시 답을 쓰는 대신, 옵션을 고르고, 조건을 조정하고, 결정을 확인하고, 다음 행동을 명시적으로 넘길 수 있는 작은 인터페이스를 원한다.
Macaron-A2UI: A Model for Generative UI in Personal Agents는 이 문제를 “UI를 예쁘게 생성하는 모델”이 아니라 에이전트 응답 형식 자체를 바꾸는 학습 문제로 다룬다.
모델은 자연어 답변만 내는 것이 아니라, 필요할 때 A2UI라는 선언형 프로토콜의 실행 가능한 UI 메시지를 함께 생성한다.
클라이언트는 이 메시지를 신뢰된 컴포넌트 카탈로그로 렌더링한다.
핵심은 임의 HTML/JavaScript를 모델에게 쓰게 하는 것이 아니다.
논문은 A2UI v0.8이라는 고정된 프로토콜 위에서 text_response와 a2ui를 함께 내는 형태를 잡고, 데이터셋·벤치마크·훈련 레시피를 한 세트로 제시한다.
즉 Generative UI를 데모가 아니라 검증 가능한 agent capability로 끌어내리려는 시도다.
무엇을 해결하려는가
Macaron-A2UI가 겨냥하는 병목은 “모델이 JSON을 못 만든다”보다 넓다.
개인 에이전트의 실제 상호작용에는 세 가지 문제가 동시에 걸린다.
첫째, 언제 UI가 필요한지 판단해야 한다.
모든 답변을 카드나 폼으로 감싸면 오히려 대화가 어색해진다.
상담이나 정서적 지지처럼 공감적 문장이 중요한 순간에는 text-only가 맞을 수 있다.
둘째, 어떤 UI가 필요한지 정해야 한다.
선택지는 selection component가, 강도나 우선순위는 slider류가, 날짜·시간은 DateTimeInput이 자연스럽다.
모델이 단지 “보기 좋은 카드”를 만드는 수준이면 실제 task progression에는 도움이 되지 않는다.
셋째, 실행 가능한 프로토콜을 지켜야 한다.
JSON parse는 성공했지만 컴포넌트 참조가 깨지거나, data model binding이 틀리거나, renderer가 실제로 그릴 수 없는 구조라면 사용자 입장에서는 실패다.
논문이 protocol validity, task construction, user experience를 나누어 평가하는 이유가 여기에 있다.
이 관점에서 A2UI는 HTML 생성보다 제한적이지만, 그 제한이 장점이 된다.
모델은 자유로운 웹 코드를 쓰지 않고 beginRendering, surfaceUpdate, dataModelUpdate, deleteSurface 같은 메시지를 생성한다.
렌더러는 이 메시지를 순서대로 처리해 표면을 만들고, 상태를 업데이트하고, 필요하면 surface를 삭제한다.
안전성·이식성·자동 검증 가능성을 UI 생성의 중심 제약으로 둔 셈이다.
핵심 구조: A2UI 메시지, 코퍼스, 벤치마크
모델의 출력 계약은 단순하다. assistant response는 자연어 필드인 text_response와 선택적 A2UI 메시지 배열인 a2ui를 가진 JSON 객체다.
A2UI v0.8 기준 메시지 종류는 네 가지다.
| 메시지 타입 | 역할 | 실무적 의미 |
|---|---|---|
beginRendering |
새 UI surface 렌더링 시작 | 어떤 surface와 root component를 보여 줄지 선언 |
surfaceUpdate |
component tree 정의 또는 갱신 | Label, Card, SelectionList, Button 같은 UI 구조를 전달 |
dataModelUpdate |
reactive data model 업데이트 | 선택값, 슬롯, 기본값 같은 상태를 UI와 연결 |
deleteSurface |
기존 surface 제거 | 대화 흐름상 더 이상 필요 없는 UI를 정리 |
논문은 이 형식을 학습시키기 위해 네 종류의 대화 코퍼스를 A2UI-grounded corpus로 변환했다.
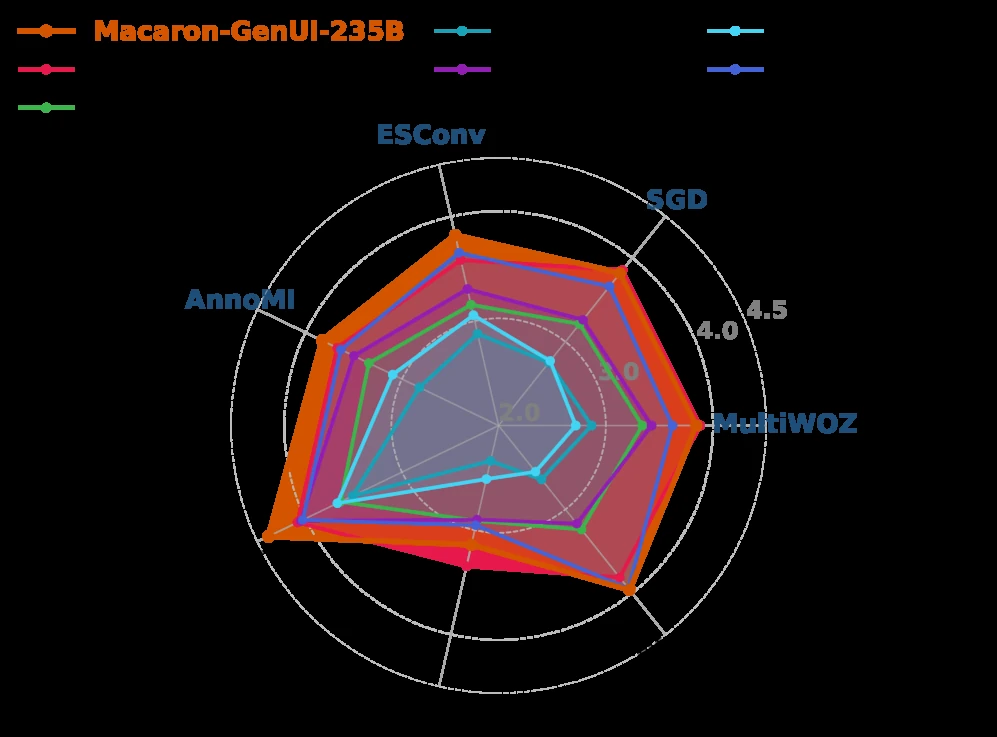
MultiWOZ 2.2와 Schema-Guided Dialogue(SGD)는 task-oriented assistance를, ESConv와 AnnoMI는 emotional support와 motivational interviewing을 담당한다.
저자들은 4,306개 base dialogue에서 14,245개 assistant-turn training sample을 만들었고, 이 중 10,210개는 UI-turn, 4,035개는 text-only turn이라고 보고한다.
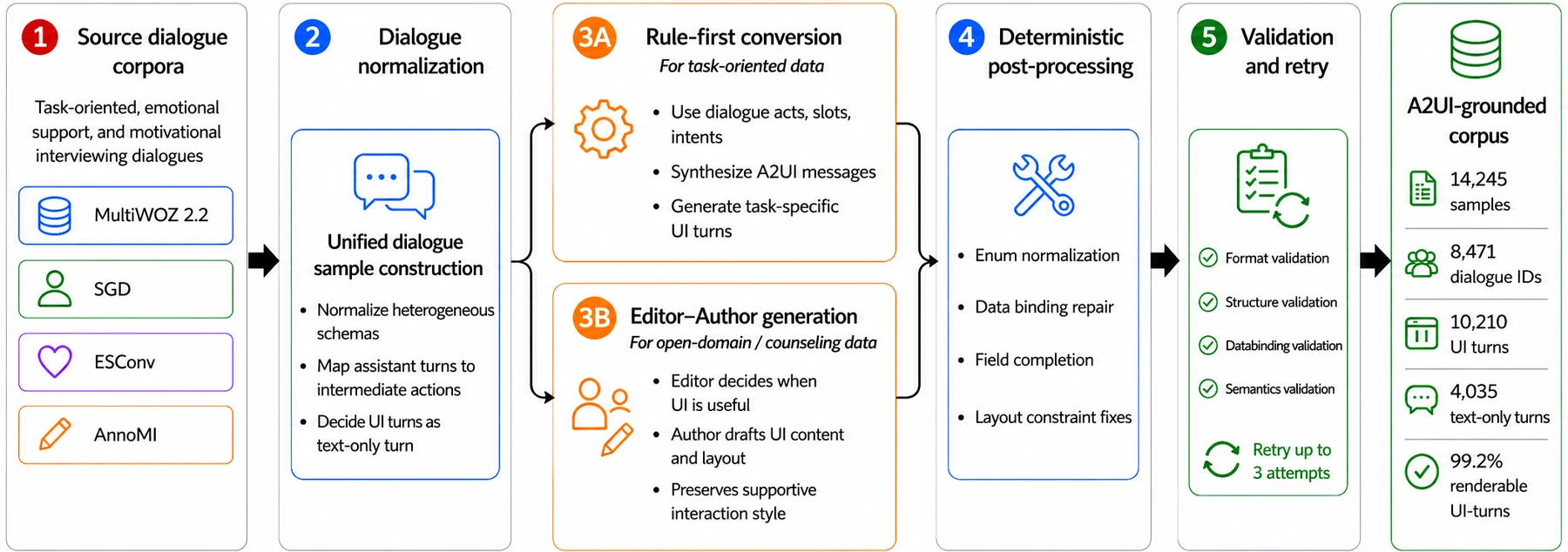
데이터 생성 방식도 흥미롭다.
MultiWOZ와 SGD처럼 intent·slot annotation이 있는 데이터는 rule-driven state machine으로 missing constraints, option presentation, confirmation surface를 만든다.
반대로 ESConv와 AnnoMI처럼 UI decision이 명시되지 않은 대화는 LLM 기반 Editor가 어느 turn에 UI가 필요한지 계획하고, Author가 구체적인 component content를 만든다.
이후 enum normalization, data-binding correction, required-field completion 같은 deterministic repair를 적용한다.
저자들이 보고한 validation 결과는 이 프로젝트의 성격을 잘 보여 준다.
UI-turn은 format, structure, data-binding, semantic validation을 거치며, 첫 시도에서 91.3%가 통과하고 error-feedback retry까지 포함하면 최종 renderability는 99.2%에 이른다.
Generative UI를 “모델 출력 예시”가 아니라 renderable artifact로 다루려는 설계다.
A2UI-Bench는 이 코퍼스와 별도로 평가 목적에 맞춘 300개 task로 구성된다. task 형식은 atomic, depth, width로 나뉜다.
| Task family | 평가하려는 능력 | 실패하면 드러나는 문제 |
|---|---|---|
| Atomic | 단일 turn에서 UI trigger와 component 선택 | UI가 필요할 때 안 나오거나, 불필요한 UI를 생성 |
| Depth | 같은 dialogue 안의 multi-turn consistency | surface 갱신, 상태 유지, 이전 출력 참조 실패 |
| Width | 여러 정보 요구를 한 turn에서 조직 | UI가 조각나거나 cognitive load가 커짐 |
평가 축은 language-side와 visual-side로 분리된다.
L1은 JSON parse, schema compliance, reference integrity, required field, value format 같은 protocol correctness를 본다.
L2는 trigger appropriateness, component-intent alignment, text-UI grounding, data model utilization, action completeness를 본다.
L3는 value-add over text, conversational naturalness, cognitive load를 본다.
별도의 V1–V3 visual evaluation은 실제 renderer screenshot을 VLM judge로 평가해 readability, task alignment, action clarity를 확인한다.
공개된 근거에서 확인되는 점
공개 artifact를 종합하면 Macaron-A2UI는 논문만 있는 아이디어가 아니라, 모델 adapter와 benchmark repo가 함께 나온 release에 가깝다.
다만 production-ready UI framework 전체라기보다는 A2UI v0.8 generative UI generation을 검증하기 위한 연구·평가 bundle로 보는 편이 안전하다.
| 공개 표면 | 확인되는 내용 | 해석 |
|---|---|---|
| arXiv paper | 2026-05-24 제출, cs.HC, CC BY-NC-SA 4.0, 모델·코퍼스·벤치마크·훈련 레시피 설명 | canonical technical source |
| Hugging Face collection | Macaron-A2UI collection에 Tall, Grande, Venti adapter와 paper item 포함 |
모델 공개 표면은 HF 중심 |
| Model cards/API | Tall은 Qwen3-30B-A3B, Grande는 Qwen3-235B-A22B, Venti는 GLM-5.1 기반 LoRA adapter로 표시 | 전체 모델이 아니라 PEFT/LoRA adapter release |
| Model card license | adapter weights는 MIT, base checkpoint license도 별도 준수 필요 | 배포 시 adapter와 foundation checkpoint 조건을 함께 봐야 함 |
| Benchmark repo | Macaron-A2UI-Bench는 JSON-first L1/L2/L3 evaluation이 기본, render/VLM은 optional extension |
공개 benchmark는 기본적으로 renderer 없이도 돌릴 수 있는 평가 경로를 우선함 |
| GitHub API | repo는 Python 중심, tag v0.1.0 확인, GitHub API상 license는 null |
benchmark code의 license posture는 model card의 MIT adapter license와 별도로 확인 필요 |
모델 카드의 문구도 보수적으로 읽어야 한다.
Tall README는 “adapter weights only”라고 명시하고, foundation checkpoint를 먼저 로드한 뒤 PEFT adapter를 붙이라고 설명한다.
또한 출력은 valid JSON, top-level text_response/a2ui, Markdown code fence 없음, A2UI v0.8 message 사용을 계약으로 둔다.
동시에 production rendering 전에 validator를 통과해야 하며, safety-critical 또는 irreversible action에는 user confirmation 없이 쓰지 말라는 한계를 적는다.
벤치마크 repo도 같은 방향이다.
README는 이 저장소가 JSON-first evaluation path를 중심으로 구성되어 있으며, 기본 파이프라인은 evaluate_api_model.py로 model JSON output을 읽고 L1/L2/L3 score를 계산한다고 설명한다. renderer와 VLM 기반 visual scoring은 ENABLE_VISUAL_EVAL=1일 때 추가로 켜는 optional path다.
즉 공개 재현의 기본 단위는 “UI screenshot 품질”보다 “A2UI JSON generation의 구조적·상호작용적 품질”이다.
실험 결과가 말하는 것
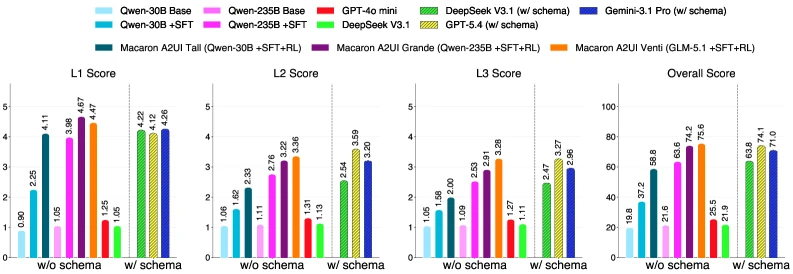
논문의 가장 강한 숫자는 Macaron-A2UI-Venti가 A2UI-Bench overall 75.6을 schema hint 없이 달성했다는 부분이다.
논문은 GPT-5.4 full-schema prompted baseline의 74.1을 비교점으로 둔다.
이 결과는 “큰 frontier model에 긴 schema를 prompt로 넣으면 된다”는 접근과 반대로, UI protocol competence를 훈련으로 internalize할 수 있다는 주장을 뒷받침한다.
훈련 레시피는 두 단계다.
먼저 LoRA 기반 supervised fine-tuning이 text_response와 a2ui를 함께 내는 기본 형식과 text–UI grounding을 안정화한다.
다음으로 GRPO가 여러 candidate response를 sampling하고, A2UI reward로 group-relative advantage를 계산해 executable interaction quality를 밀어 올린다. reward는 malformed JSON, required UI 누락, protocol validation failure, render-critical error를 hard gate로 두고, 통과한 응답에 L1/L2/L3 계열 품질을 가중합한다.
결과 추세는 꽤 일관적이다.
Qwen3-30B 계열은 schema 없는 조건에서 base 19.8에서 SFT 37.2, SFT+RL 58.8로 오른다.
Qwen3-235B 계열은 base 21.6에서 SFT 63.6, RL 후 74.2까지 오른다.
논문은 GLM-5.1 기반 Venti가 같은 recipe에서 가장 강한 language-side 결과인 75.6을 얻었다고 설명한다.
여기서 중요한 점은 L1이 먼저 좋아지고 L2/L3가 그 뒤를 따른다는 해석이다.
논문 Figure 6의 GRPO reward trajectory도 protocol correctness가 가장 빠르게 올라가고, task construction과 user-facing quality는 더 점진적으로 개선된다고 설명한다.
이는 Generative UI에서 “일단 valid JSON을 만든다”와 “사용자가 정말 덜 힘들게 일을 끝낸다” 사이에 꽤 큰 간극이 있음을 보여 준다.
실무 관점에서의 해석
Macaron-A2UI의 실무적 의미는 agent UI를 세 층으로 나누어 볼 수 있게 한다는 데 있다.
첫째는 protocol layer다.
어떤 메시지 타입과 component catalog를 허용할 것인가.
둘째는 model capability layer다.
모델이 schema prompt 없이도 그 protocol을 안정적으로 internalize할 수 있는가.
셋째는 UX evaluation layer다.
생성된 UI가 실제로 사용자의 비용을 줄이는가.
이 분해는 제품팀에 유용하다.
지금 많은 에이전트 제품은 “tool call 결과를 chat bubble에 예쁘게 보여 주자” 수준에서 시작한다.
하지만 복잡한 task로 가면 UI는 presentation이 아니라 state와 action의 계약이 된다.
선택값이 다음 turn의 context로 들어가야 하고, confirmation button은 안전한 action loop를 가져야 하며, 이전 surface는 적절히 업데이트되거나 삭제되어야 한다.
A2UI-Bench의 L1/L2/L3 구조는 바로 이 계약을 테스트하는 체크리스트로 쓸 수 있다.
다만 한계도 명확하다.
A2UI v0.8은 논문에서도 evolving protocol로 언급된다.
모델 카드는 이후 protocol revision과의 호환을 보장하지 않는다고 적는다.
또한 benchmark repo의 기본 공개 경로는 JSON-first evaluation이고, visual evaluation은 optional이다.
실제 제품에서는 renderer 성능, latency, accessibility, host permission, irreversible action confirmation 같은 문제가 추가로 붙는다.
따라서 Macaron-A2UI를 “바로 서비스에 꽂을 UI 생성 모델”로 읽기보다는, 개인 에이전트가 대화 중 동적으로 조작 가능한 UI를 만들려면 무엇을 학습하고 무엇을 평가해야 하는가를 꽤 구체적으로 보여 주는 reference point로 보는 것이 맞다.
모델 adapter, benchmark, renderer/validator 중심의 사고방식까지 함께 공개된 점은 이 분야의 다음 실험을 빠르게 만들 수 있게 한다.
결국 질문은 “채팅창 안에 UI를 넣을 수 있는가”가 아니다.
그 UI가 대화 맥락에서 언제 필요한지, 어떤 상태를 담아야 하는지, 사용자의 다음 행동을 얼마나 덜 힘들게 만드는지까지 모델과 평가가 같이 다뤄야 한다.
Macaron-A2UI는 그 질문을 A2UI라는 구체적 프로토콜 위에 올려놓은 첫 세대 연구 중 하나로 읽힌다.