AR/VR 헤드셋이 주변 사람을 이해하려면, 단순히 화면 안의 skeleton을 맞추는 것만으로는 부족하다.
착용자는 계속 고개를 돌리고 이동하며, 대상자는 여러 카메라 사이를 오가거나 부분적으로만 보인다.
카메라가 움직이는지, 사람이 움직이는지, 그리고 그 움직임이 실제 공간의 어느 위치에 있는지를 함께 풀어야 한다.
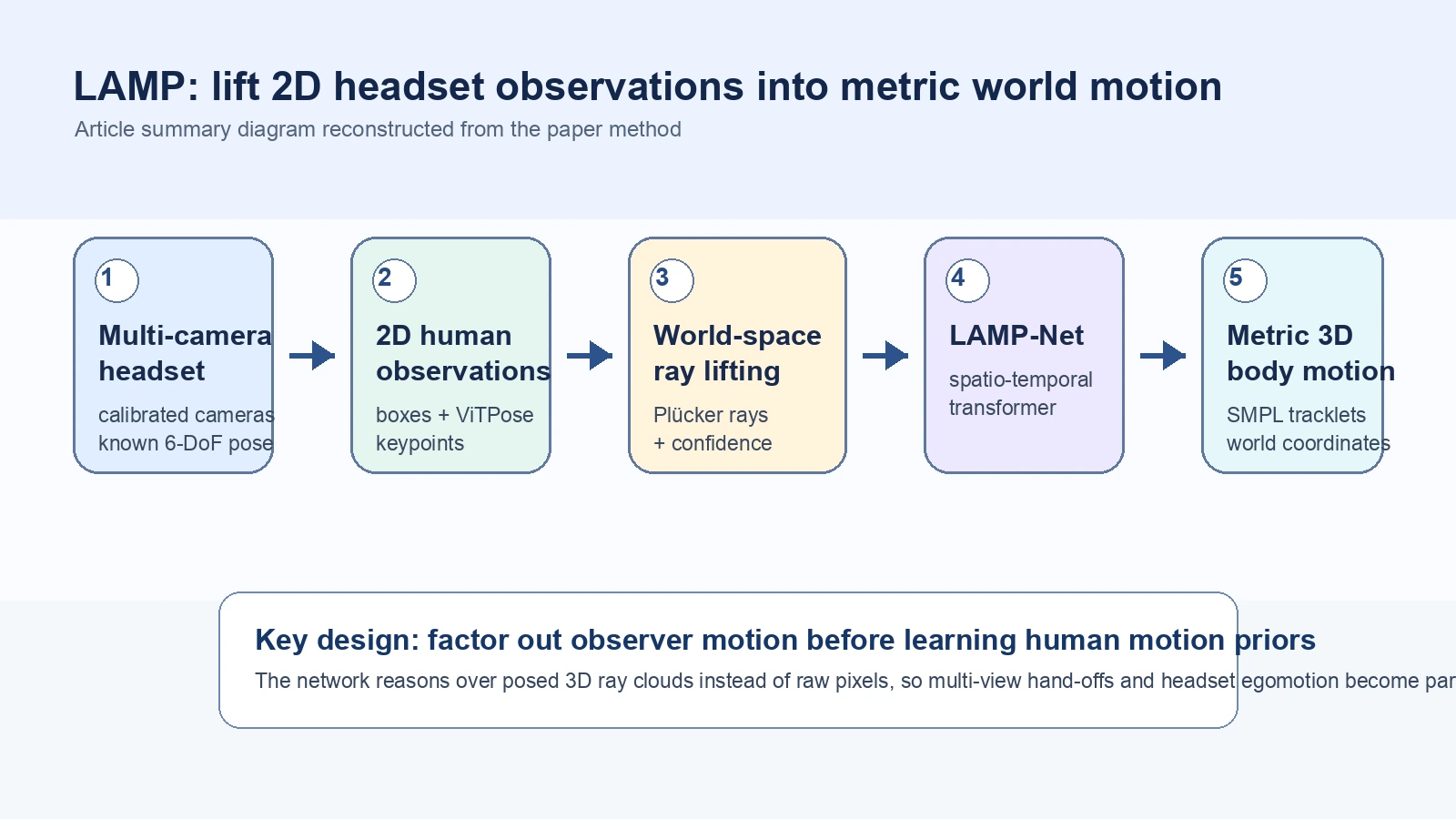
LAMP: Localization Aware Multi-camera People Tracking in Metric 3D World는 이 문제를 “픽셀에서 바로 3D 사람을 맞추기”가 아니라 헤드셋의 위치추정과 카메라 보정을 먼저 활용해 2D 관측을 metric world 좌표의 ray cloud로 올리고, 그 위에서 사람 motion을 맞추는 문제로 바꾼다.
논문은 이를 lift-then-fit 접근이라고 부른다.
중요한 전제는 현대 헤드셋에는 이미 VIO/SLAM 기반 6-DoF device pose와 카메라 calibration이 있다는 점이다.
LAMP는 이 정보를 부수 정보가 아니라 핵심 입력 modality로 사용한다.
그래서 네트워크가 카메라 움직임까지 같이 학습하려고 애쓰기보다, 관측자 motion을 일찍 제거한 뒤 사람 motion prior를 world space에서 학습하게 만든다.
무엇을 해결하려는가
기존 3D human pose / motion 추정은 monocular video나 비교적 안정적인 카메라를 전제로 강해진 경우가 많다.
하지만 헤드셋 기반 egocentric capture에서는 조건이 달라진다.
- 착용자의 head motion이 빠르고 불규칙하다.
- 사람은 한 카메라에 온전히 잡히지 않고, side camera나 다른 timestamp에서 부분적으로만 보일 수 있다.
- 여러 카메라의 관측은 asynchronous하고, camera hand-off가 계속 발생한다.
- 새로운 headset generation마다 camera layout이 달라져, device-specific 3D labeled video를 대규모로 모으기 어렵다.
LAMP의 문제 설정은 그래서 “한 frame의 pose”보다 metric 3D world에서 사람 tracklet을 얼마나 안정적으로 유지하느냐에 가깝다.
AR assistant, social presence, 주변 사람 motion understanding 같은 응용에서는 pelvis 기준으로 정렬한 local pose error만 낮아서는 충분하지 않다.
실제 공간에서 대상자가 어디에 있고, observer가 움직여도 그 위치가 얼마나 일관되는지가 중요하다.
핵심 아이디어 / 구조 / 동작 방식
LAMP pipeline은 크게 네 단계로 읽을 수 있다.
| 단계 | 역할 | 실무적으로 읽히는 의미 |
|---|---|---|
| 2D detection / keypoint | 각 카메라 frame에서 사람 box와 MSCOCO 17개 keypoint를 찾는다. 논문 구현은 ViTPose를 사용한다. | 사람 인식은 기존 2D perception stack에 맡긴다. |
| Tracklet association | camera/time을 넘어 같은 사람 관측을 묶는다. world-coordinate tracklet과 Hungarian matching을 사용한다. | headset motion을 보정한 예상 위치로 camera hand-off를 처리한다. |
| World-aligned ray lifting | 2D keypoint를 calibrated unprojection으로 3D ray로 바꾸고, camera pose로 gravity-aligned local world frame에 놓는다. | 픽셀 좌표 대신 “이 사람 keypoint가 이 ray 위 어딘가에 있다”는 geometric evidence를 만든다. |
| LAMP-Net fitting | spatio-temporal transformer가 ray cloud를 받아 SMPL body pose, shape, orientation, translation을 추정한다. | raw image feature보다 multi-view geometry와 temporal motion prior를 결합한다. |
LAMP-Net은 4초 temporal window를 입력으로 받는다.
논문 설정에서는 30Hz video 기준 120 frames이며, 512 hidden dimension의 transformer encoder-decoder block 3개로 구성된다.
입력 tensor는 시간, 카메라, joint 차원을 갖고, 각 keypoint는 6차원 Plücker ray와 confidence를 포함한다.
관측이 없는 keypoint는 0으로 채운다.
이 구조가 흥미로운 이유는 훈련 데이터 구성 방식까지 바꾼다는 점이다.
LAMP는 raw pixel video를 직접 학습하지 않기 때문에, ground-truth 3D motion dataset을 임의의 virtual camera layout에 projection해 2D keypoint observation을 시뮬레이션할 수 있다.
논문은 Nymeria dataset의 Aria Gen1 기반 motion을 사용해 학습하고, camera configuration이 크게 바뀐 Aria Gen2 real-world demo에서도 generalization을 보인다.

공개된 근거에서 확인되는 점
정량 결과는 두 층으로 봐야 한다.
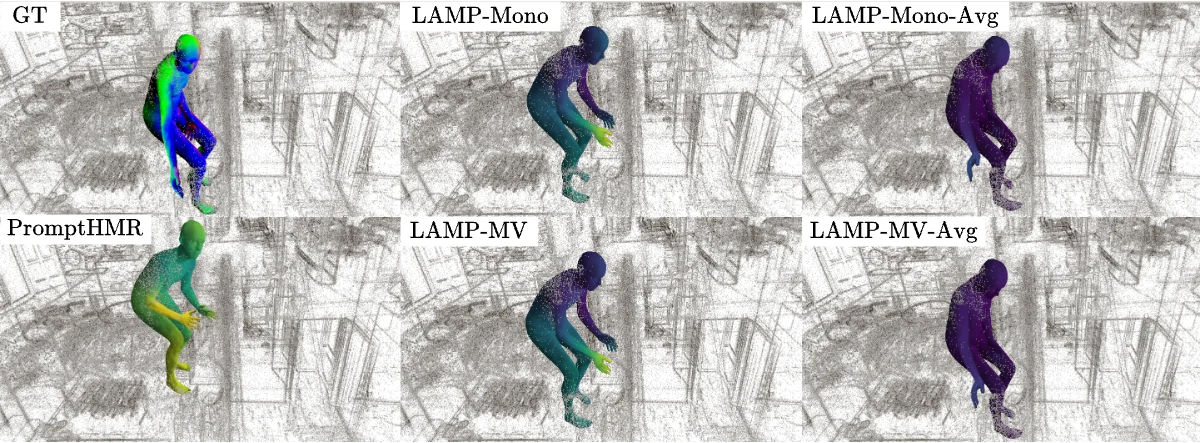
EMDB처럼 카메라가 상대적으로 느리게 움직이고 참가자를 따라가는 monocular benchmark에서는 LAMP가 local pose similarity 계열 지표에서는 항상 최고가 아니다.
예를 들어 EMDB에서 PromptHMR은 MPJPE 68.1mm, LAMP-mono는 82.3mm로 LAMP가 더 나쁘다.
논문도 raw image를 early stage에서 3D rays로 접는 설계가 local pose detail에는 손해가 될 수 있다고 설명한다.
대신 LAMP가 겨냥한 지표는 world-space grounding이다.
같은 EMDB에서 LAMP-mono는 W-MPJPE 165.1mm로 PromptHMR의 278.1mm보다 낮고, jitter도 4.6으로 PromptHMR의 16.3보다 작다.
즉 “관절 모양을 frame별로 얼마나 닮았는가”와 “metric world에서 motion이 얼마나 안정적인가”가 서로 다른 질문임을 보여 준다.
Nymeria처럼 긴 sequence, 자연스러운 head motion, egocentric camera rotation이 있는 setting에서는 차이가 더 뚜렷하다.
| 설정 | Dataset | MPJPE ↓ | W-MPJPE ↓ | RTE ↓ | Jitter ↓ | 읽을 점 |
|---|---|---|---|---|---|---|
| PromptHMR | Nymeria | 109.2 | 246.0 | 0.11 | 114.1 | monocular baseline을 camera pose와 함께 adaptation |
| LAMP-mono | Nymeria | 92.3 | 203.4 | 0.09 | 23.8 | 단일 camera에서도 world-space 안정성이 크게 개선 |
| LAMP-mv | Nymeria | 54.8 | 113.3 | 0.05 | 21.8 | multi-view ray cloud가 local/global accuracy를 함께 끌어올림 |
Ablation도 LAMP의 중심 가설을 지지한다.
Nymeria에서 camera pose를 쓰지 않고 moving observer frame에 ray를 두는 variant는 W-MPJPE 296.3, jitter 93.1이다.
Posed ray lifting을 넣으면 W-MPJPE가 209.6까지 내려가고, sliding-window averaging까지 더하면 jitter가 23.8까지 줄어든다.
여기에 multi-view observed keypoint를 쓰는 설정은 MPJPE 54.8, W-MPJPE 113.3까지 내려간다.
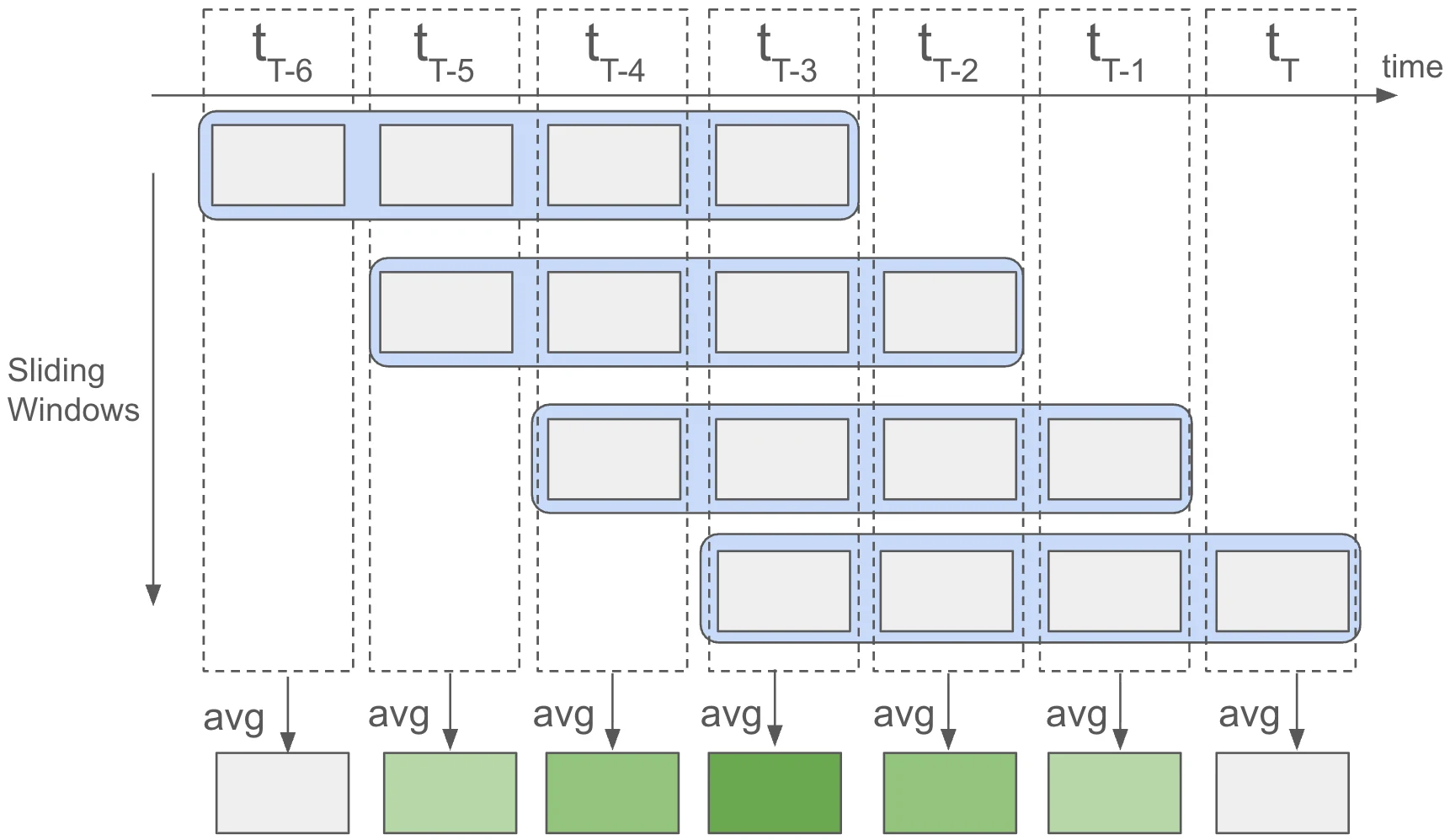
Sliding window와 latency trade-off
LAMP는 4초 window를 사용하기 때문에, 같은 timestamp에 대한 pose 추정이 여러 overlapping window에서 반복해서 나온다.
논문은 이를 버리지 않고 같은 timestamp의 여러 예측을 평균해 motion을 더 안정화하는 non-causal smoothing 전략을 사용한다.
네트워크 inference 자체를 더 돌리는 것이 아니라, 이미 계산된 overlapping predictions를 평균하는 방식이다.
다만 이 선택은 latency와 맞바꾼다.
최대 smoothing을 쓰면 출력이 최대 T-1 timestamp만큼 늦어질 수 있다.
실시간 AR 시스템에서는 이 지점을 조절 변수로 봐야 한다.
즉 LAMP는 “정확도 최고”와 “즉시 반응” 사이의 runtime knob을 노출하는 구조다.
논문 구현 세부도 실무적으로 볼 만하다.
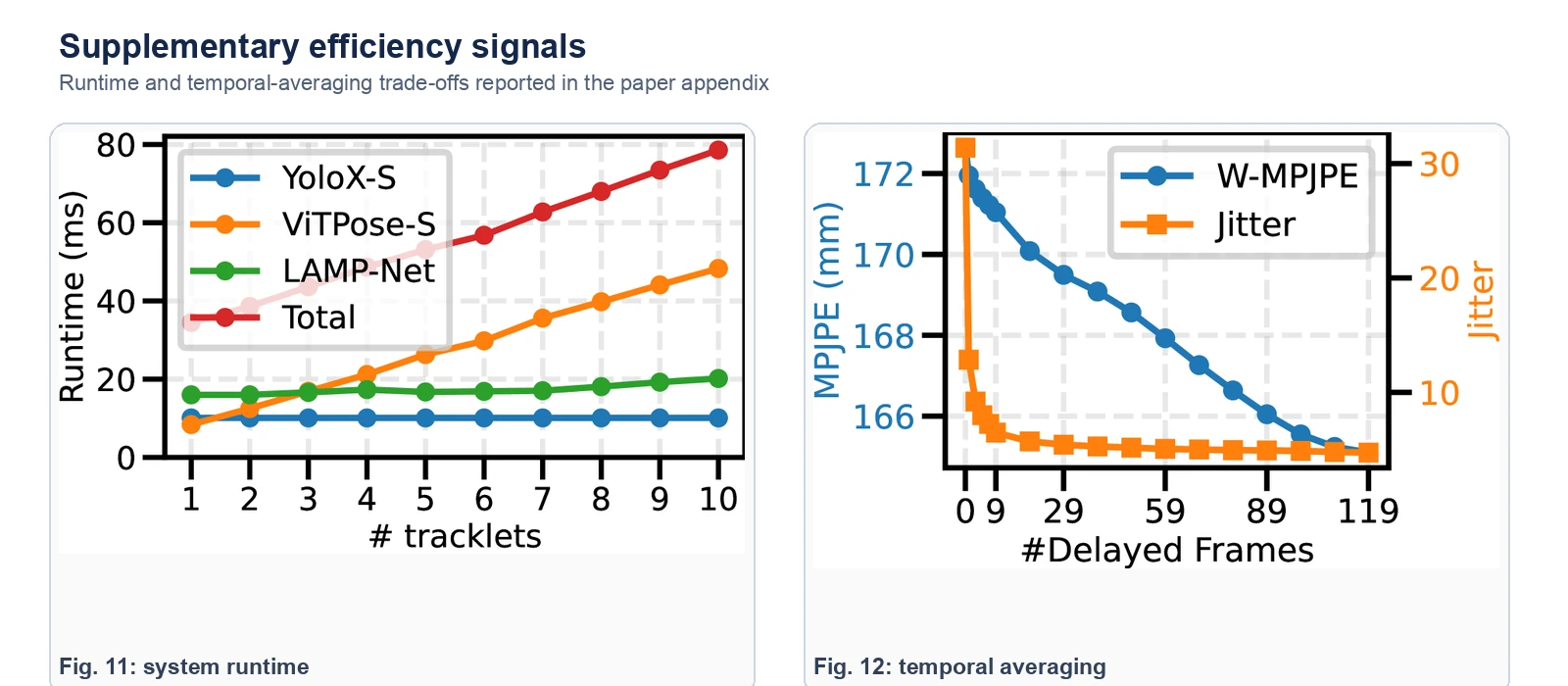
LAMP-Net은 Nymeria의 300시간 이상 in-the-wild human motion 데이터에서 학습되고, 4개 노드의 NVIDIA H100 GPU로 약 19시간 학습했다고 보고한다. inference와 evaluation은 단일 RTX 4090에서 real-time으로 수행된다.
보조 실험에서는 system runtime과 temporal averaging의 영향도 따로 제시한다.
공개 상태와 라이선스는 조심해서 읽어야 한다
공식 project page는 arXiv, video, GitHub code 링크를 제공한다.
다만 GitHub 저장소 facebookresearch/LAMP의 README에는 확인 시점 기준으로 Code release coming soon — please stay tuned!라고 되어 있고, repository에는 README, license, teaser resource 정도만 공개되어 있다.
GitHub API 기준 별도 release나 tag도 확인되지 않았다.
따라서 현재 LAMP는 바로 재현 가능한 library라기보다 논문, project page, demo video, teaser asset이 먼저 공개된 연구 결과로 보는 편이 안전하다.
라이선스도 표면별로 다르다. arXiv paper는 CC BY 4.0로 표시되지만, GitHub 저장소의 LICENSE는 CC BY-NC 4.0이며 README도 LAMP가 CC-BY-NC licensed라고 명시한다.
연구 검토나 비상업적 재사용 관점에서는 열려 있지만, 상업 제품에 바로 넣는 release로 읽으면 안 된다.
실무 관점에서의 해석
LAMP의 메시지는 “더 큰 video model을 만들자”보다 “이미 headset이 알고 있는 geometry를 먼저 써야 한다”에 가깝다.
AR/VR 장치에서는 camera pose와 calibration이 센서 스택의 기본 산출물이다.
이 정보를 네트워크가 암묵적으로 다시 추론하게 하는 대신, 입력 표현 자체를 world coordinate로 바꾸면 multi-view fusion과 temporal tracking이 훨씬 자연스러워진다.
특히 실무적으로 중요한 점은 세 가지다.
첫째, LAMP는 camera rig 변화에 비교적 유연한 방향을 제시한다. raw pixel 모델은 camera placement와 optics가 바뀌면 domain shift가 크지만, ray lifting 표현은 “어떤 camera에서 온 keypoint인가”를 world-space geometry로 정규화한다.
이 덕분에 Aria Gen1 데이터로 학습하고 Aria Gen2 camera layout을 시뮬레이션하거나 real-world demo에 적용하는 흐름이 가능해진다.
둘째, 평가 지표를 바꿔 보게 만든다.
일반 3D pose benchmark에서 많이 쓰는 MPJPE/PA-MPJPE는 local pose shape에 민감하지만, AR headset에서 정말 중요한 것은 world-grounded trajectory stability일 수 있다.
논문이 W-MPJPE, RTE, jitter, foot skating 같은 지표를 함께 보고하는 이유도 여기에 있다.
셋째, 아직 release maturity는 제한적이다. code가 공개되면 training simulation, keypoint detector 연결, camera pose noise robustness, real-time pipeline 구성 같은 부분을 더 검증할 수 있겠지만, 현재 공개 자료만으로는 제품 적용 가능성을 단정하기 어렵다.
논문이 직접 밝힌 한계처럼 LAMP는 정확한 6-DoF tracking에 의존하고, multi-view input이 있을 때 가장 큰 이득을 낸다.
일반 스마트폰 monocular video나 인터넷 영상에는 같은 방식으로 강하게 적용하기 어렵다.
정리
LAMP는 egocentric people tracking을 image-only perception 문제가 아니라 localized multi-camera sensing 문제로 재정의한다.
2D keypoint를 world-space rays로 올리고, spatio-temporal transformer가 그 ray cloud에 맞는 SMPL motion을 찾게 만드는 구조는 단순하지만 AR/VR 헤드셋의 실제 센서 조건과 잘 맞는다.
가장 큰 기여는 세 가지로 압축된다.
- observer motion과 target motion을 early stage에서 분리해, 네트워크가 human motion prior에 집중하게 만든다.
- multi-camera, partial visibility, camera hand-off를 하나의 metric 3D ray cloud로 통합한다.
- Nymeria와 Aria Gen2 demo setting에서 monocular baseline보다 world-space tracking과 coverage를 크게 개선한다.
반대로 지금 당장 “쓸 수 있는 오픈소스 추적기”로 읽기에는 이르다.
저장소는 열렸지만 code release는 아직 예고 상태이고, 라이선스도 non-commercial 조건을 포함한다.
그럼에도 AR/VR perception stack을 설계하는 관점에서는 꽤 선명한 교훈을 준다. headset이 이미 알고 있는 위치추정과 calibration을 모델 밖에 방치하지 말고, 입력 표현의 첫 단계부터 world coordinate로 끌어올리라는 것이다.