멀티모달 모델은 깨끗한 이미지에서는 꽤 강하지만, 실제 서비스 입력은 늘 깨끗하지 않다.
저조도, JPEG 압축, 블러, 노이즈, 날씨, 센서 artifact가 섞이면 모델은 장면을 제대로 보지 못하고도 그럴듯한 답을 만든다.
기존 robustness 접근은 크게 두 갈래였다.
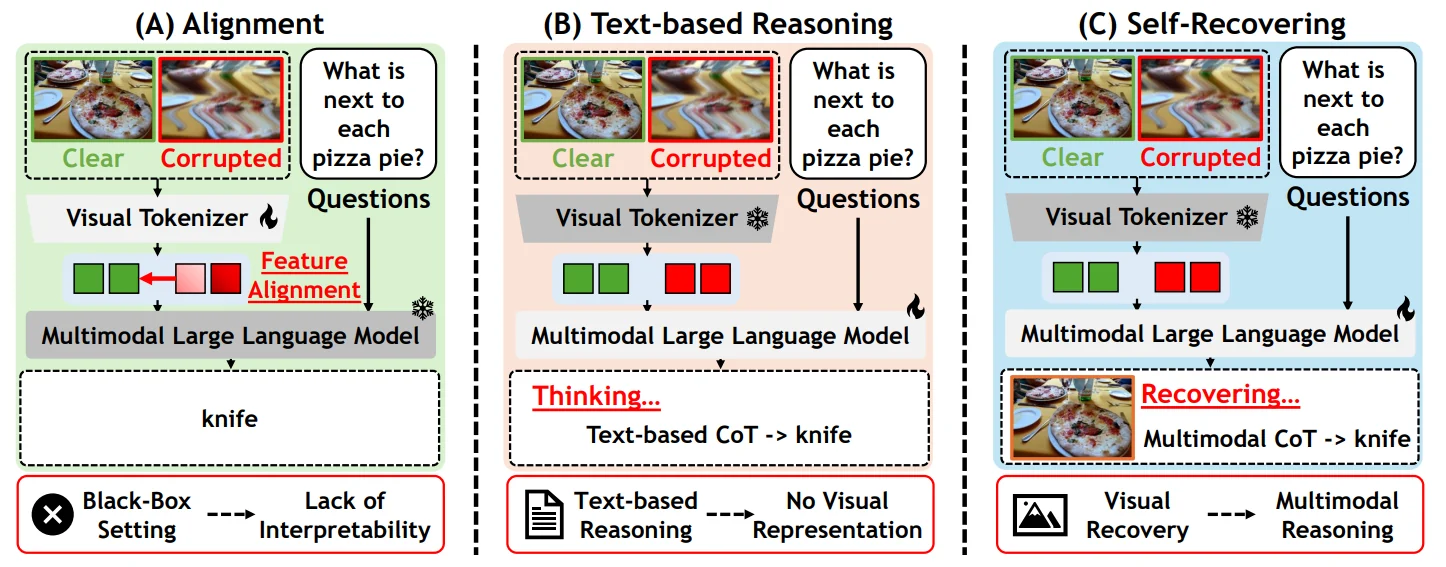
하나는 visual encoder 내부 feature를 맞추는 black-box alignment이고, 다른 하나는 “이미지가 어둡고 압축이 심하므로 이런 점을 조심해야 한다”처럼 손상 영향을 텍스트 reasoning으로 설명하는 방식이다.
Robust-U1: Can MLLMs Self-Recover Corrupted Visual Content for Robust Understanding?는 이 두 접근이 놓친 지점을 찌른다.
손상으로 잃어버린 픽셀 수준 정보는 텍스트 설명만으로 되살아나지 않는다.
그래서 Robust-U1은 MLLM이 먼저 손상 이미지를 직접 복원하고, 그 복원본과 원래 손상본을 함께 보면서 답하게 만든다.
요약하면 robustness를 “손상을 더 잘 견디는 feature” 문제가 아니라, 모델 안에서 복원 가능한 시각 증거를 다시 만드는 문제로 바꾼다.
논문과 공식 저장소 기준으로 Robust-U1은 ICML 2026에 채택되었고, 2026년 6월 11일 코드, pretrained models, Hugging Face demo가 공개되었다.
공개 artifact도 paper-only가 아니다.
GitHub jqtangust/Robust-U1에는 app.py, demo.py, modeling, inference, rewards가 있고, Hugging Face에는 final Jiaqi-hkust/Robust-U1, Stage-I Robust-U1-SFT, Stage-II Robust-U1-RL checkpoint와 Gradio Space가 올라와 있다.
무엇을 해결하려는가
논문이 보는 병목은 단순히 “corruption에 약하다”가 아니다.
약한 이유가 서로 다르다.
첫째, black-box feature alignment는 성능을 올릴 수 있지만 모델이 무엇을 잃었고 무엇을 복구했는지 사람이 확인하기 어렵다.
Feature space에서 깨끗한 이미지와 손상 이미지를 가깝게 만드는 것은 interpretable한 복원 과정이 아니다.
둘째, text-based reasoning은 더 해석 가능하지만, 픽셀을 되살리지는 못한다.
예를 들어 차량 방향, 신호등 색, 버스 개수처럼 작은 시각 단서가 손상되면 “이미지가 흐리니 조심하자”는 텍스트 설명만으로는 실제 단서를 다시 만들 수 없다.
셋째, 일반 image restoration module을 MLLM 앞에 붙이는 방식도 완전한 답은 아니다.
어떤 손상인지 탐지하고 외부 복원기를 선택한 뒤 다시 MLLM에 넣는 detect-then-recover 파이프라인은 복원과 이해가 분리되어 있다.
Robust-U1의 질문은 더 직접적이다.
이해와 생성을 모두 할 수 있는 unified MLLM이라면, 손상된 입력을 스스로 복원하고 그 복원본을 근거로 답할 수 있지 않을까?
핵심 구조: 복원하고, 보정하고, 같이 본다
Robust-U1은 BAGEL 기반 unified MLLM을 출발점으로 삼는다.
BAGEL은 multimodal understanding과 generation을 모두 지원하므로, 저자들은 이 모델을 “손상 이미지를 깨끗한 이미지로 되돌리는” self-recovery module로 특화한다.
전체 학습은 세 단계다.
-
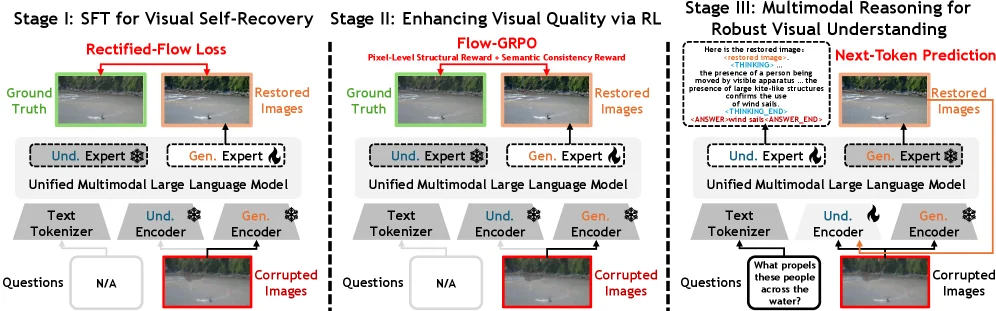
Stage I: Visual Self-Recovery SFT ImageNet-C 기반 corrupted-clean image pair로 모델을 학습한다.
입력은 손상 이미지이고, 목표는 깨끗한 이미지를 복원하는 것이다.
논문은 rectified-flow formulation을 사용해 clean latent를 denoise하도록 학습한다고 설명한다. -
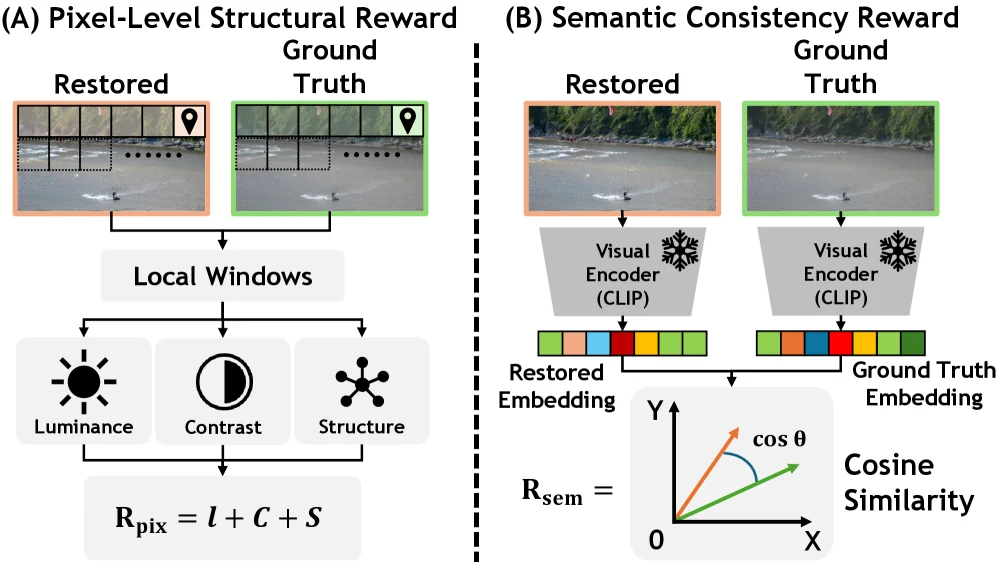
Stage II: Visual Quality Alignment RL SFT만으로는 복원본이 구조적으로 맞아도 의미가 틀리거나, 의미는 맞아도 픽셀 구조가 흐릴 수 있다.
그래서 Flow-GRPO로 두 보상을 결합한다.
하나는 SSIM 기반 pixel-level structural reward이고, 다른 하나는 frozen TinyCLIP embedding의 cosine similarity를 쓰는 semantic consistency reward다. -
Stage III: Multimodal Reasoning 마지막에는 손상 이미지
Ic, 복원 이미지Ir, 질문Q를 함께 넣고 답하도록 학습한다.
여기서 중요한 점은 복원본만 보지 않는다는 것이다.
복원본은 주요 content를 되살리는 역할을 하고, 손상본은 복원 hallucination이나 애매한 부분을 교차 확인하는 anchor로 남는다.
이 설계의 장점은 복원 품질과 downstream reasoning을 분리해서 보지 않는다는 데 있다.
단순히 예쁜 이미지를 만드는 image restoration이 아니라, 질문에 답하는 데 필요한 visual evidence를 회복하는 것이 목표다.
숫자로 보면: R-Bench에서 복원과 추론이 같이 오른다
R-Bench 결과가 이 논문의 핵심 신호다.
Table 1에서 Robust-U1은 R-Bench Overall 0.7398을 기록한다.
같은 BAGEL baseline은 0.5770이고, text-based robust MLLM인 Robust-R1은 0.5017이다.
도구로 계산하면 BAGEL 대비 절대 +0.1628, 상대 약 +28.2%이고, Robust-R1 대비 절대 +0.2381, 상대 약 +47.5%다.
| 모델 | MCQ high | VQA high | CAP high | R-Bench Overall |
|---|---|---|---|---|
| BAGEL | 0.5793 | 0.6150 | 0.4288 | 0.5770 |
| Robust-R1 | 0.6097 | 0.4980 | 0.3484 | 0.5017 |
| Robust-U1 | 0.6768 | 0.6934 | 0.7640 | 0.7398 |
특히 CAP 쪽 차이가 크다.
손상된 이미지를 설명하는 captioning은 장면 세부 정보가 많이 필요하므로, 텍스트로 “어떤 손상이 있다”고 설명하는 것보다 실제 복원본을 만들어 보는 접근이 더 직접적으로 먹힌다.
표준 VQA benchmark에 인위적 degradation을 넣은 Table 3에서도 Robust-U1은 높은 손상 강도에서 버틴다.
100% intensity 기준으로 MMMB는 Robust-U1 83.18, BAGEL 78.48이고, MMStar는 63.87 대 59.60, RealWorldQA는 67.46 대 63.14다. clean에서 100% intensity까지의 하락폭도 MMMB에서 Robust-U1은 1.57점, BAGEL은 3.44점으로 더 작다.
MMStar에서도 Robust-U1 하락폭은 3.33점, BAGEL은 6.53점이다.
복원 품질 자체도 개선된다.
Robust-R1 validation set에서 BAGEL 복원은 PSNR 14.37, SSIM 0.4722, LPIPS 0.5092인데, Robust-U1은 PSNR 21.49, SSIM 0.6314, LPIPS 0.3223이다.
이전 계산 기준 PSNR은 +7.12, SSIM은 +0.1592, LPIPS는 0.1869 낮아진다.

Ablation도 꽤 중요하다.
Full Robust-U1은 R-Bench Overall 0.7398이다.
여기서 multimodal reasoning을 빼고 SFT+RL 복원만 쓰면 0.6623으로 떨어진다.
즉 복원 품질만 올리는 것보다, 손상본과 복원본을 함께 보고 답하도록 학습하는 단계가 약 +0.0775의 절대 기여를 한다.
반대로 pixel reward나 semantic reward 하나만 빼도 full보다 낮아진다.
논문의 메시지는 “복원만 하면 된다”가 아니라, 복원 품질 정렬과 reasoning supervision이 같이 필요하다에 가깝다.
공개 artifact 관점: 모델은 열렸지만 실행 비용은 가볍지 않다
공식 README는 세 가지 checkpoint를 나눠 공개한다.Robust-U1-SFT는 Stage-I 복원 SFT 모델, Robust-U1-RL은 Stage-II RL 모델, Robust-U1은 최종 visual self-recovery + multimodal reasoning 모델이다.
Hugging Face API 기준 세 모델은 gated가 아니고, transformers, safetensors, bagel, custom_code, license:mit, arxiv:2606.08063 태그를 갖는다.
Demo는 Hugging Face Space의 Gradio 앱으로 공개되어 있다.
다만 이것을 “가벼운 robustness patch”로 읽으면 곤란하다.
Appendix의 training cost table에 따르면 Stage I SFT는 L20 64장으로 약 30시간, 1,920 GPU-hours를 쓴다.
Stage II RL은 L20 8장으로 약 20시간, 160 GPU-hours이고, Stage III reasoning은 L20 8장으로 약 8시간, 64 GPU-hours다.
Peak memory도 41~43GB 수준이다.
즉 재현과 추가 학습은 명확히 대규모 연구/인프라 작업이다.
Inference도 공짜가 아니다.
Appendix Table 9에서 Standard MLLM은 latency 1.8초, R-Bench 0.6204다.
Detect-then-Recover는 24.6초, 0.7082다.
Robust-U1은 55.0초, 0.7398이다.
이전 계산으로 보면 detect-then-recover 대비 R-Bench는 +0.0316 오르지만 latency는 약 30.4초 더 길고, 비율로는 약 2.24배다.
이 점 때문에 Robust-U1은 low-latency interactive product에 그대로 꽂기보다, 정확도와 robustness가 지연보다 중요한 시나리오에서 먼저 의미가 있다.
실무 관점에서의 해석
내가 보기에 Robust-U1의 가장 좋은 점은 MLLM robustness를 더 구체적인 인터페이스 문제로 바꾼다는 데 있다.
이전에는 “손상에 강한 encoder를 만들자”나 “모델에게 손상 유형을 말하게 하자”가 중심이었다.
Robust-U1은 여기서 한 단계 더 나아가, 모델이 답하기 전에 자기 자신에게 더 나은 시각 입력을 만들어 주는 구조를 제안한다.
이 접근은 여러 제품형 시스템에도 힌트를 준다.
- 차량, 로봇, CCTV, 현장 점검처럼 입력 품질이 들쭉날쭉한 시스템에서는 손상본을 그냥 VLM에 던지는 대신 recovery view를 중간 evidence로 둘 수 있다.
- 단일 복원기를 외부 preprocessing으로 붙이는 방식보다, downstream 질문에 맞게 복원본을 reasoning에 통합하는 방식이 더 강할 수 있다.
- 하지만 복원 branch는 hallucination 위험을 만든다. 논문도 recovery hallucination taxonomy를 따로 제시하고, Robust-U1의 harmful rate가 4.1%라고 보고한다. BAGEL의 15.6%보다 낮지만 0은 아니다.
- 따라서 실무에서는 복원본만 신뢰하기보다, 원본 손상 이미지와 복원 이미지를 함께 보게 하는 현재 설계가 중요하다.
특히 Table 12가 이 균형을 잘 보여 준다.
Clean input에서는 recovery를 켜도 R-Bench Overall이 0.7821에서 0.7865로 거의 유지된다.
반면 corrupted input에서는 recovery off 0.5605에서 recovery on 0.7398로 크게 오른다.
이 결과만 보면 always-on recovery가 좋아 보이지만, latency와 hallucination cost까지 고려하면 실제 제품에서는 corruption detector, confidence, task criticality에 따라 recovery를 켜는 정책이 필요할 수 있다.
결론: “보이는 척”이 아니라 “다시 보게 만드는” MLLM
Robust-U1은 MLLM robustness에서 중요한 관점 전환을 보여 준다.
모델이 손상된 이미지를 보고도 답을 잘하게 하려면, 단순히 텍스트로 손상 요인을 설명하게 하는 것만으로는 부족할 수 있다.
손상으로 사라진 세부 정보는 다시 시각 증거로 만들어져야 하고, 그 복원본은 원본 손상 입력과 함께 reasoning에 들어가야 한다.
물론 비용은 크다.
학습은 대규모 GPU를 요구하고, inference latency도 표준 MLLM이나 detect-then-recover보다 길다.
복원 branch가 완전히 hallucination-free인 것도 아니다.
하지만 논문이 제시하는 방향은 선명하다.
앞으로 robust MLLM은 “나쁜 이미지를 보고도 그럴듯하게 말하는 모델”이 아니라, 필요한 경우 자기 입력을 복원하고, 복원 결과를 검증하며, 그 위에서 답하는 모델로 발전할 가능성이 있다.
Robust-U1은 그 방향을 꽤 직접적으로 보여 주는 연구다.