AI 연구 에이전트를 이야기할 때 가장 헷갈리는 지점은 “논문을 읽고 구현할 수 있는가”와 “같은 문제에서 새로운 해법을 찾아 published SOTA를 이길 수 있는가”가 다르다는 점이다.
전자는 강한 코딩 능력과 문서 이해력을 요구하지만, 후자는 문제 구조를 읽고, 알맞은 방법 계열을 고르고, 실험을 반복하며, 제한된 시간과 계산 자원 안에서 실제 점수를 끌어올리는 능력을 요구한다.
NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?는 이 차이를 정면으로 벤치마크화한다.
논문은 Nature 계열 저널의 peer-reviewed 논문에서 추출한 90개 과학 ML 과제를 컨테이너 환경으로 만들고, 에이전트에게 원 논문의 방법은 숨긴 채 데이터와 과제 설명만 제공한다.
목표는 재현이 아니라 발견이다.
에이전트가 스스로 방법을 선택해 원 논문이 보고한 SOTA 점수에 도달하거나 이를 넘어설 수 있는지 본다.
결과는 꽤 냉정하다.
10개 frontier coding-agent 설정을 웹 검색 비활성화, 과제당 4시간 budget으로 평가했을 때, 가장 강한 Claude Opus 4.7 + Claude Code 조합도 g > 0.1 기준 Surpass-SOTA는 17.8%, g >= 0 기준 Match-SOTA는 **47.8%**에 그쳤다.
NatureBench의 핵심 메시지는 “에이전트가 코드를 못 짠다”가 아니라, 과학 문제에서 올바른 방법 계열을 고르고 충분히 깊게 실행하는 능력이 아직 부족하다는 쪽에 가깝다.

무엇을 해결하려는가
기존 paper-based benchmark는 주로 논문을 읽고, 알려진 방법을 구현하고, 보고된 결과를 재현하는 능력을 본다.
PaperBench, CORE-Bench, ReplicationBench 같은 흐름은 “논문을 operationalize할 수 있는가”에는 강하지만, 이미 공개된 방법을 따라가는 평가가 되기 쉽다.
반대로 MLE-bench, PostTrainBench, AutoLab 같은 최적화형 benchmark는 실행과 반복을 요구하지만, 자연과학 도메인의 특수한 데이터·도구·방법 선택 문제를 항상 포함하지는 않는다.
NatureBench가 추가하는 질문은 더 좁고 더 불편하다.
| 평가 축 | 기존 benchmark에서 흔한 질문 | NatureBench의 질문 |
|---|---|---|
| 논문 기반성 | 논문을 이해하고 구현할 수 있는가 | 논문에서 문제만 떼어내도 해결할 수 있는가 |
| 목표 | 재현, 복원, 알려진 결과 도달 | published SOTA를 match 또는 surpass |
| 도메인 | 주로 ML/소프트웨어/공학 proxy | Nature-family 자연과학 ML 과제 |
| 평가 신호 | 테스트 통과, rubric, 점수 개선 | 원 논문 SOTA 대비 normalized gap |
이 설계가 중요한 이유는 scientific discovery를 “좋은 아이디어를 말하는 능력”으로 평가하지 않기 때문이다.
에이전트는 실제 데이터와 evaluator가 있는 작업장에서 방법을 선택하고 제출물을 만든다.
그리고 점수는 “그럴듯한 설명”이 아니라 원 논문의 SOTA anchor와 비교된다.
핵심 아이디어 / 구조 / 동작 방식
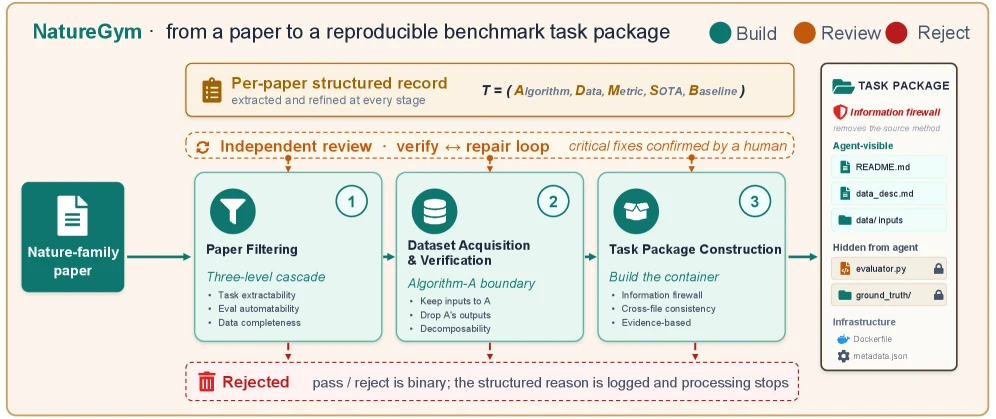
NatureBench는 두 층으로 구성된다.
하나는 과제를 만드는 NatureGym이고, 다른 하나는 완성된 과제 세트와 평가 프로토콜인 NatureBench다.
NatureGym은 Nature-family 논문 하나를 읽고, 그 논문에서 자동 평가 가능한 과학 ML 문제를 추출한다.
각 task는 논문으로부터 다음 다섯 요소를 구조화한다.
T = (A, D, M, S, B)
여기서 A는 핵심 알고리즘, D는 데이터셋, M은 평가 지표, S는 논문이 보고한 SOTA 점수, B는 선택적 baseline이다.
하지만 에이전트에게는 이 전체가 그대로 노출되지 않는다.
NatureGym은 information firewall을 두어 원 논문의 방법을 제거하고, agent-visible task brief와 데이터, writable workspace만 제공한다.
즉 에이전트가 논문 방법을 검색하거나 그대로 복제하는 것이 아니라, 주어진 데이터와 evaluator를 통해 스스로 해법을 찾아야 한다.
최종 benchmark는 90개 task, 333개 evaluation instance로 구성된다.
출처 논문은 2022~2025년에 나온 Nature-family publication이며, 도메인은 cellular omics, protein biology, biomedical modeling, physical modeling, molecular design, relational reasoning 여섯 가지다.
과제마다 데이터 크기, modality, metric, instance 수가 다르기 때문에 raw score를 그대로 비교하기 어렵다.
그래서 논문은 SOTA-normalized relative gap g를 사용한다.
g_i = dir_i * (m_i - m_i^sota) / |m_i^sota|
m_i는 에이전트 점수, m_i^sota는 원 논문의 SOTA, dir_i는 metric이 높을수록 좋은지 낮을수록 좋은지를 보정하는 값이다. g_i >= 0이면 원 논문의 SOTA를 match 또는 surpass한 것이고, g > 0.1이면 논문에서 Surpass-SOTA로 본다. valid submission이 없으면 해당 instance는 g = -1.0으로 처리된다.
평가 환경도 shortcut을 줄이도록 설계돼 있다.
각 에이전트는 task-specific Docker container 안에서 과제당 4시간 wall-clock budget을 받는다.
웹 검색은 비활성화되고, evaluator·ground truth·SOTA target은 host-side evaluation service에 남는다.
에이전트는 /evaluate, /best_score, /time_remaining 같은 endpoint를 통해 제출과 피드백을 반복할 수 있지만, ground truth 자체에는 접근할 수 없다. run이 끝난 뒤에는 Claude Sonnet 4.6 기반 post-hoc judge가 output fabrication, feedback gaming, training bypass 같은 shortcut을 걸러낸다.
공개된 근거에서 확인되는 점
공식 공개 표면은 논문, leaderboard, GitHub 저장소, Hugging Face dataset으로 나뉜다.
논문 자체는 arXiv 2606.24530v1이며, 저자 소속은 Horizon Research/Frontis.AI, Tsinghua University, Peking University, Harvard University로 표기되어 있다.
공식 프로젝트 페이지는 leaderboard와 case study를 제공하고, GitHub 저장소는 benchmark runner와 NatureGym 관련 코드, Hugging Face dataset은 90개 task artifact를 담는다.
| 공개 표면 | 확인한 내용 | 해석 |
|---|---|---|
| arXiv | 2606.24530v1, 2026-06-23 제출, CC BY 4.0, cs.CL |
논문 identity와 방법·실험 수치의 기준 |
| 공식 사이트 | frontisai.github.io/NatureBench, leaderboard와 metric 정의, case study 제공 |
paper-only가 아니라 공개 leaderboard형 benchmark로 배포 |
| GitHub | FrontisAI/NatureBench, MIT license, run_naturebench.py, eval_service.py, judge.py, naturegym/, agent/ 포함 |
실제 실행 harness와 task construction pipeline 코드가 공개됨 |
| GitHub release state | 조회 시점 기준 stars 33, forks 1, default branch main, /releases/latest 404, tags 0개 |
초기 공개 연구 아티팩트이며 versioned release는 아직 없음 |
| Hugging Face dataset | FrontisAI/NatureBench, private/gated 아님, manifest.jsonl과 tasks/<case_id>/... 구조, license name mit-with-third-party-data |
task data는 공개되어 있지만 third-party data notice를 task별로 봐야 함 |
GitHub README 기준 실행에는 두 Conda 환경(naturebench, naturebench-eval), Docker base image, agent별 credential, evaluation service가 필요하다.
GPU 과제도 많다.
논문은 3개 task는 CPU-only, 70개는 RTX 3090/4090급 GPU, 17개는 A800급 GPU를 사용했다고 설명한다.
따라서 NatureBench는 “pip install 후 가볍게 돌리는 benchmark”라기보다, scientific ML task bundle과 host-side evaluator를 갖춘 무거운 연구용 평가 substrate에 가깝다.
결과: SOTA를 넘는 일은 드물다
메인 실험은 10개 모델·harness 조합을 모든 90개 task에 독립적으로 돌린다. harness는 Claude Code, Codex CLI, Gemini CLI 세 계열이고, 모델은 Claude Opus 4.6/4.7, GPT-5.4/5.5, Gemini 3.5 Flash, Kimi K2.6, Qwen 3.7 Max, GLM-5.1, DeepSeek-V4-Pro, MiniMax-M2.7 등이 포함된다.
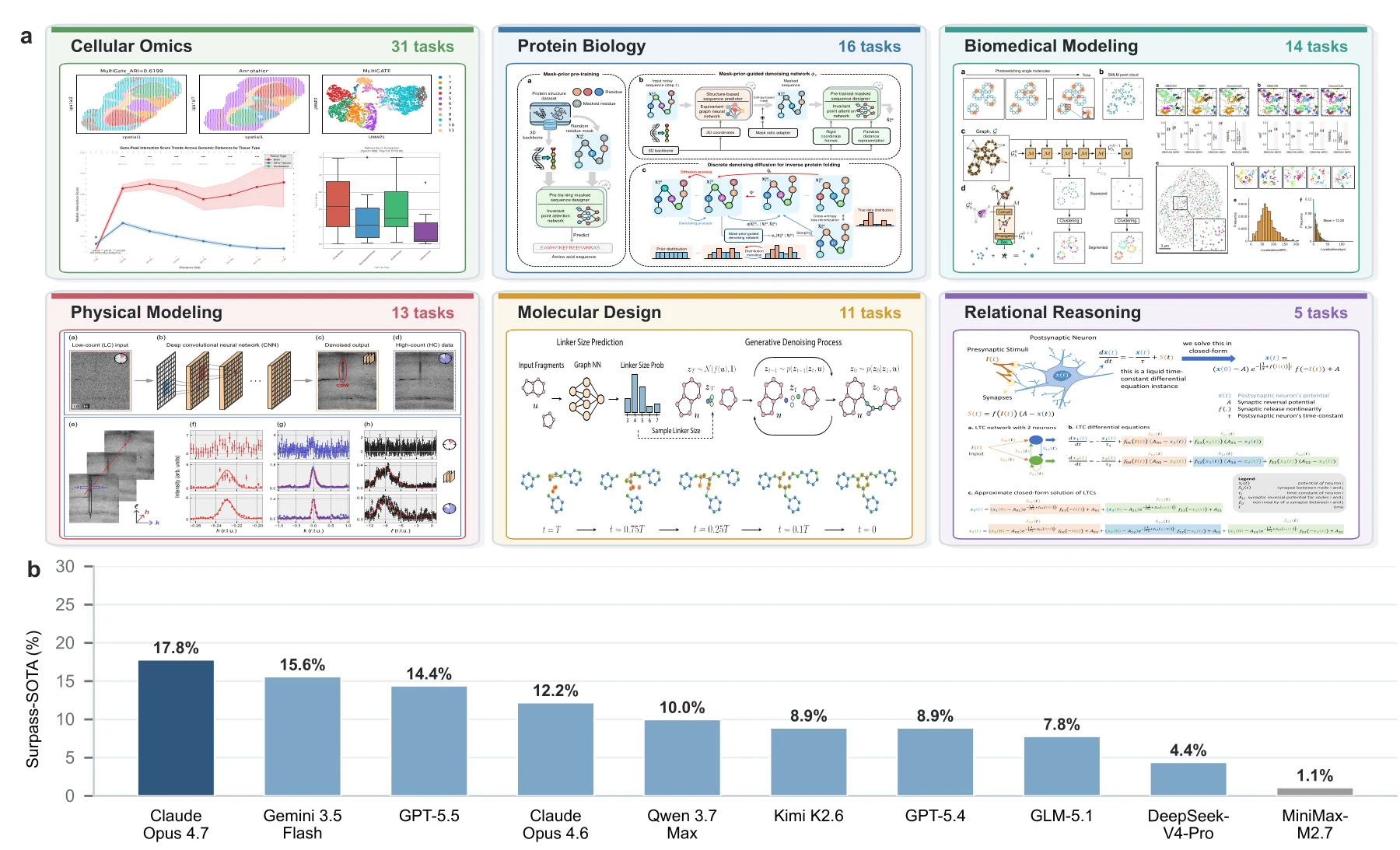
상위권만 추려 보면 다음과 같다.
| 모델 / harness | Surpass-SOTA g > 0.1 |
Match-SOTA g >= 0 |
관찰 포인트 |
|---|---|---|---|
| Claude Opus 4.7 / Claude Code | 17.8% | 47.8% | 전체 1위, completion/score rate 100% |
| Gemini 3.5 Flash / Gemini CLI | 15.6% | 37.8% | Surpass-SOTA 기준 2위 |
| GPT-5.5 / Codex CLI | 14.4% | 44.4% | Match-SOTA는 높지만 invalid submission이 상대적으로 많음 |
| Claude Opus 4.6 / Claude Code | 12.2% | 36.7% | completion/score rate 100%, Opus 4.7보다 낮음 |
| Qwen 3.7 Max / Claude Code | 10.0% | 28.9% | 중위권 cluster |
이 수치를 “47.8%나 SOTA를 맞췄다”로 읽을 수도 있지만, 논문의 해석은 더 보수적이다. clear improvement인 Surpass-SOTA는 가장 강한 설정에서도 5개 중 1개에 못 미친다.
Match-SOTA도 절반을 넘지 못한다.
즉 현재 frontier coding agent가 real scientific ML task에서 published SOTA를 안정적으로 재현·개선한다고 보기는 어렵다.
다만 에이전트들이 대부분 제출 자체를 못 한 것은 아니다.
Claude Opus 4.7과 Opus 4.6은 completion rate와 score rate가 모두 100%였고, 여러 모델도 대체로 scorable solution을 냈다.
문제는 제출물이 runnable하더라도 원 논문의 방법적 강도와 실험 깊이를 따라가지 못한다는 데 있다.
성공과 실패의 실제 원인
NatureBench의 가장 유용한 부분은 leaderboard보다 mechanism 분석이다.
논문은 900개 run을 훑어, agent가 어떤 방법 계열을 선택했는지, 성공은 어떤 경로로 왔는지, 실패는 어느 layer에서 생겼는지 분류한다.
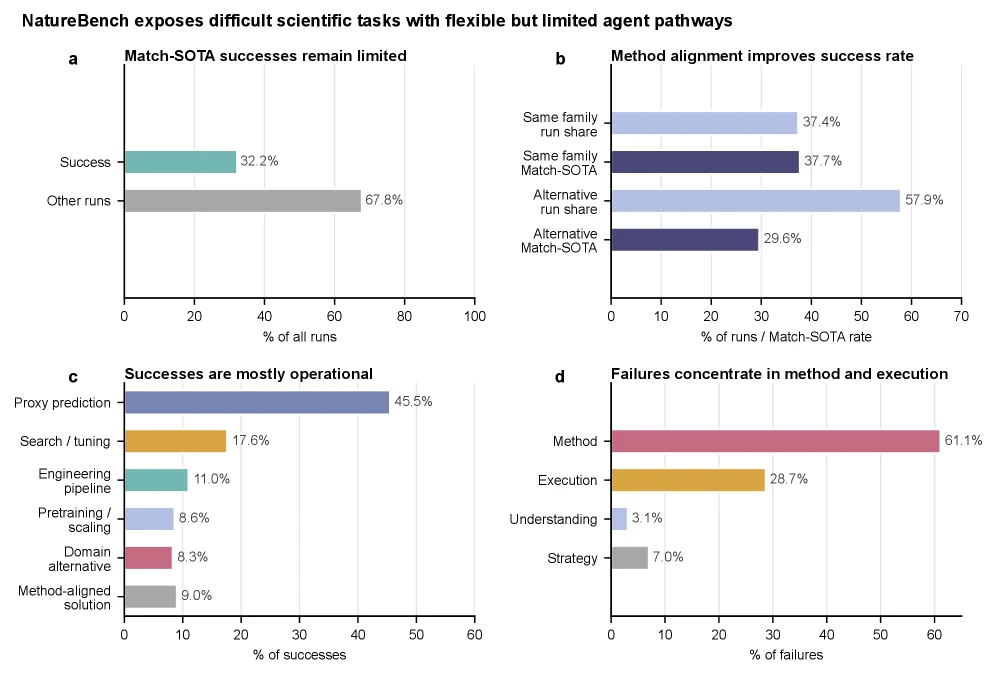
성공 쪽에서 가장 큰 비중은 scientific invention이 아니라 methodological translation이다.
Match-SOTA run 가운데 supervised proxy prediction이 45.5%, optimization/tuning이 17.6%, engineering pipeline이 11.0%, pretraining/model scaling이 8.6%를 차지한다.
합치면 engineering-driven success mode가 82.7%다.
반면 domain-reasoned alternative와 method-aligned solution은 각각 8.3%, 9.0%에 그친다.
실패도 단순한 task misunderstanding이 아니다.
Match-SOTA에 미달하거나 valid score가 없는 run 중 method-layer failure가 61.1%이고, 그중 wrong method choice가 45.1%다. execution-layer failure는 28.7%이며, 여기서 insufficient budget/time이 24.4%다. understanding-layer failure는 3.1%에 불과하다.
다시 말해 에이전트는 문제를 대체로 읽고 runnable pipeline도 만들지만, 과학 도메인의 구조에 맞는 강한 방법을 고르거나 충분히 깊게 훈련·탐색하지 못한다.
Appendix case study도 이 해석을 뒷받침한다. cancer-gene identification task에서 Claude Opus 4.7은 biological network 구조에 맞는 ChebNet/GNN ensemble을 선택해 g = 0.17666까지 올렸다.
반면 genomic sequence prediction에서 GPT-5.5는 258번 제출하며 valid iteration을 했지만, from-scratch sequence model이 대규모 genomic pretraining의 representation strength를 따라가지 못해 g = -0.14087에 머물렀다. organic reaction product prediction에서는 DeepSeek-V4-Pro가 seq2seq reaction model이라는 plausible route를 만들었지만, training과 beam-search inference가 4시간 budget 안에서 충분히 깊지 못해 g = -0.35540로 끝났다.
도메인 난이도: 어디가 더 어려웠나
NatureBench는 여섯 과학 도메인 사이의 난이도 차이도 보여 준다. consensus Match-SOTA rate 기준으로 relational reasoning은 60.0%로 가장 높고, protein biology 37.5%, cellular omics 35.5%가 뒤를 잇는다.
반면 physical modeling은 26.9%, molecular design은 18.2%, biomedical modeling은 17.9%로 낮다.
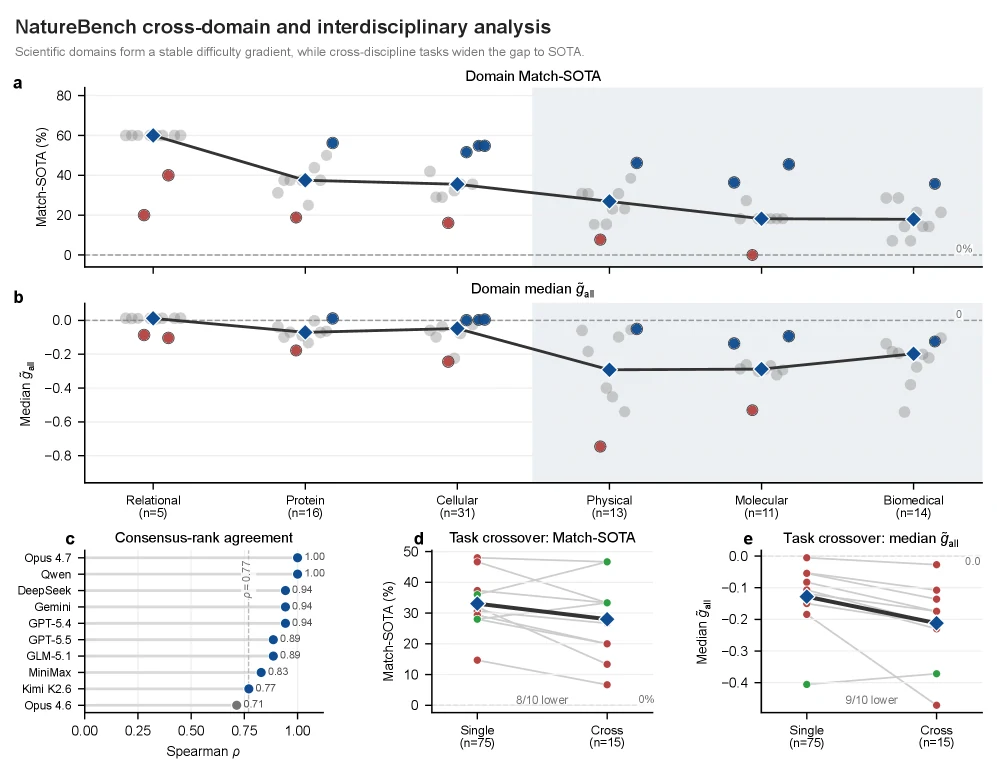
흥미로운 점은 이 난이도 순서가 특정 모델 하나의 취향이 아니라, 거의 모든 에이전트에서 공유된다는 것이다.
논문은 각 에이전트의 도메인 순위가 consensus ranking과 양의 Spearman correlation을 보이며, 10개 중 9개가 rho >= 0.77이라고 보고한다.
즉 어떤 모델은 단백질에 강하고 어떤 모델은 물리에 약한 정도의 문제가 아니라, 현재 coding-agent 계열이 공통으로 어려워하는 과학 작업 구조가 있다는 뜻이다.
또한 15개 cross-discipline task는 75개 single-discipline task보다 더 어렵다. pooled median gap은 single-discipline에서 -0.13, cross-discipline에서 -0.21로 나빠지고, Match-SOTA rate도 33.1%에서 28.0%로 떨어진다.
과학 발견 에이전트가 정말 유용해지려면 여러 분야의 데이터 표현, domain prior, metric, tooling을 동시에 다루는 능력이 필요하지만, NatureBench에서는 이 통합 능력이 아직 뚜렷한 병목으로 나온다.
실무 관점에서의 해석
NatureBench는 “AI가 과학자를 대체할 수 있는가”라는 큰 질문에 최종 답을 주는 benchmark는 아니다.
오히려 더 좁고 실무적인 기준선을 준다.
실제 데이터, 숨겨진 evaluator, 논문 SOTA anchor가 있는 과학 ML 문제에서 agent가 어느 정도까지 혼자 방법을 찾고 반복할 수 있는가를 측정한다.
첫째, agent 평가에서 final score만 볼 것이 아니라 method trajectory를 봐야 한다. runnable code를 만든 것과 좋은 과학 방법을 선택한 것은 다르다.
NatureBench의 실패 분석은 현재 병목이 “코드를 전혀 못 짜서”보다 “잘못된 방법 계열을 선택하거나, 맞는 방법을 충분히 깊게 실행하지 못해서”에 있음을 보여 준다.
제품이나 연구팀이 scientific agent를 만든다면 model selection만이 아니라 method search policy, domain-specific tool exposure, best-so-far 보존, long training job 관리가 함께 필요하다.
둘째, benchmark score는 model-only 능력이 아니다.
NatureBench의 실험은 Claude Code, Codex CLI, Gemini CLI 같은 harness와 모델의 조합을 평가한다.
같은 기반 모델도 제출 policy, evaluator 호출 빈도, 시간 관리, 파일 구조 이해, 실패 복구 방식에 따라 다른 결과를 낼 수 있다.
따라서 leaderboard를 구매 의사결정표처럼 읽기보다, 내 연구 워크플로가 어떤 harness property를 요구하는지 먼저 보는 편이 맞다.
셋째, 과학 도메인에서는 “일반 ML로 바꿔 풀기”가 종종 통하지만 충분하지 않다.
NatureBench에서 많은 성공은 supervised proxy prediction이나 optimization/tuning에서 왔다.
이것은 에이전트가 표준 ML engineering 패턴으로 꽤 많은 과제를 밀어붙일 수 있음을 보여 준다.
동시에 biomedical modeling, molecular design, physical modeling처럼 domain-specific representation과 장기 훈련이 중요한 영역에서는 그 접근이 빠르게 한계에 부딪힌다.
넷째, 공개 아티팩트는 유용하지만 초기 연구 릴리스로 읽어야 한다.
GitHub와 Hugging Face dataset이 열려 있고 task package 구조도 공개되어 있지만, 저장소에는 아직 versioned release나 tag가 없다.
또한 third-party data license는 task별 licenses/ 아래에서 따로 확인해야 한다.
실제 재현에는 Docker, Conda, GPU, agent credential, evaluation service 운영이 모두 필요하다.
한계와 다음 질문
NatureBench의 SOTA-normalized gap은 서로 다른 metric을 하나의 축으로 비교하게 해 주지만, 해석에는 주의가 필요하다.
논문도 extreme score가 metric normalization의 특성에서 나올 수 있다고 설명한다.
어떤 task는 원 논문의 여러 목표 중 자동 평가 가능한 slice만 담고, 어떤 경우에는 primary metric 하나가 source paper의 다목적 contribution 전체를 대표하지 못할 수 있다.
따라서 NatureBench 점수는 “그 논문 전체를 이해했는가”가 아니라, 자동 평가 가능한 핵심 quantitative slice에서 paper SOTA에 얼마나 가까웠는가로 읽어야 한다.
또 하나는 benchmark 자체가 이미 문제를 task package로 정리해 준다는 점이다.
실제 과학 연구에서는 문제 정의, 데이터 획득, 실험 설계, 실패한 가설 정리, human review가 훨씬 더 복잡하다.
NatureBench는 이 전부를 자동화했다고 주장하기보다, 그중에서도 “데이터와 evaluator가 있는 과학 ML 문제를 독립적으로 해결하는 능력”을 격리해 평가한다.
그럼에도 이 논문은 AI-for-Science agent 논의에서 중요한 기준점을 만든다.
이제 “에이전트가 논문을 구현했다”는 주장만으로는 부족하다.
더 중요한 질문은 원 방법을 숨겼을 때도 문제 구조를 읽고, 알맞은 방법을 고르고, 충분히 깊은 실험 루프를 돌려 published SOTA에 닿는가다.
NatureBench의 현재 답은 “아직 절반도 안정적이지 않다”에 가깝지만, 바로 그 때문에 이후 scientific-discovery agent의 개선 방향을 꽤 선명하게 보여 준다.
참고 링크
- arXiv: NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?
- arXiv HTML: 2606.24530v1
- 공식 사이트/리더보드: frontisai.github.io/NatureBench
- GitHub: FrontisAI/NatureBench
- Hugging Face Dataset: FrontisAI/NatureBench