최근 프런티어 모델 경쟁에서 중요한 축은 단순 채팅 품질보다 에이전트 실행 지속성으로 이동하고 있다.
모델이 코드를 한 번 잘 쓰는가보다, 수백 번의 도구 호출을 거치며 계획을 유지하고, 실패를 관찰하고, 다른 하네스 안에서도 같은 문제 해결 전략을 유지할 수 있는지가 더 중요해진다.
Qwen 팀이 공개한 Qwen3.7-Max는 이 변화를 아주 직접적으로 겨냥한 릴리스다.
공식 블로그는 Qwen3.7-Max를 “agent era”를 위한 최신 독점 모델로 소개하며, 코딩 에이전트, 오피스/생산성 자동화, MCP 연동, multi-agent orchestration, 수십 시간 규모의 장기 실행을 핵심 사용처로 제시한다.
흥미로운 점은 이 모델이 오픈 웨이트 공개보다 상용 에이전트 백본에 가깝게 포지셔닝된다는 점이다.
Alibaba Cloud Model Studio를 통한 API 제공, OpenAI 호환 chat completions/responses, Anthropic 호환 인터페이스, Claude Code·OpenClaw·Qwen Code 연동 예시가 함께 제시된다.
즉 Qwen3.7-Max의 메시지는 “새로운 챗봇 모델”이 아니라, 여러 에이전트 런타임에 꽂아 넣을 수 있는 장시간 실행용 모델 계층이다.

무엇을 해결하려는가
Qwen3.7-Max가 겨냥하는 문제는 “에이전트가 오래 버티는가”다.
지금의 코딩·업무 자동화 에이전트는 단일 답변이 아니라 긴 trajectory를 수행한다.
저장소를 읽고, 파일을 수정하고, 테스트를 돌리고, 로그를 해석하고, 다시 계획을 바꾸며, 필요하면 수백 번의 shell·browser·MCP 호출을 반복한다.
이런 환경에서는 세 가지 병목이 생긴다.
첫째, 모델이 긴 작업 중반 이후에 원래 목표와 제약을 잊는 context rot가 발생한다.
둘째, 특정 agent scaffold나 benchmark harness에만 맞춰진 모델은 다른 런타임으로 옮겼을 때 성능이 흔들린다.
셋째, 장시간 RL이나 self-improvement 루프에서는 모델이 reward hacking, 규칙 우회, 검증 신호 오염 같은 문제를 스스로 감지해야 한다.
Qwen의 답은 모델 학습과 평가를 “일회성 태스크”가 아니라 “환경 속 실행”으로 재구성하는 것이다.
공식 설명에 따르면 Qwen3.7에서는 Qwen3.5에서 도입한 environment scaling 접근을 더 공격적으로 확장했고, agentic training environment의 품질과 다양성을 늘렸다.
Qwen은 다양한 환경에서 학습한 agentic capability가 다양한 텍스트에서 학습한 언어 능력처럼 일반화된다고 본다.
핵심 아이디어 / 구조 / 동작 방식
공개 블로그 기준 Qwen3.7-Max의 핵심은 세 층으로 정리할 수 있다.
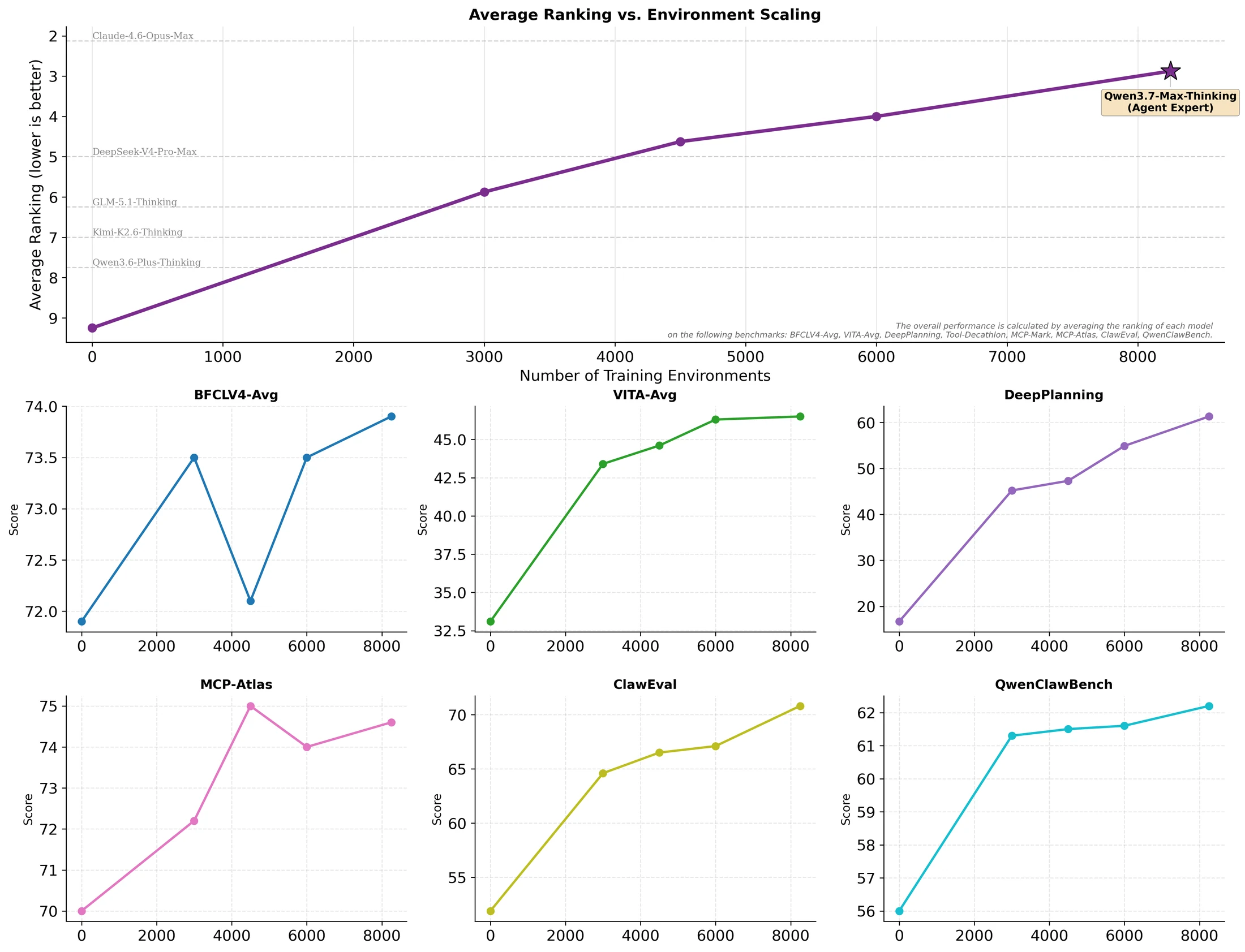
첫째는 agent environment scaling이다.
Qwen은 모델 성능을 단순 benchmark memorization이 아니라, 서로 다른 실제 환경에서 반복 실행하며 얻는 일반화 능력으로 설명한다.
공식 figure는 환경 수가 늘수록 여러 out-of-domain benchmark의 평균 순위가 꾸준히 좋아지는 궤적을 보여 준다.
Qwen은 일부 benchmark subset의 성능 향상이 나머지 benchmark나 전체 평균 성능을 예측할 수 있을 만큼 일관적이라고 주장한다.
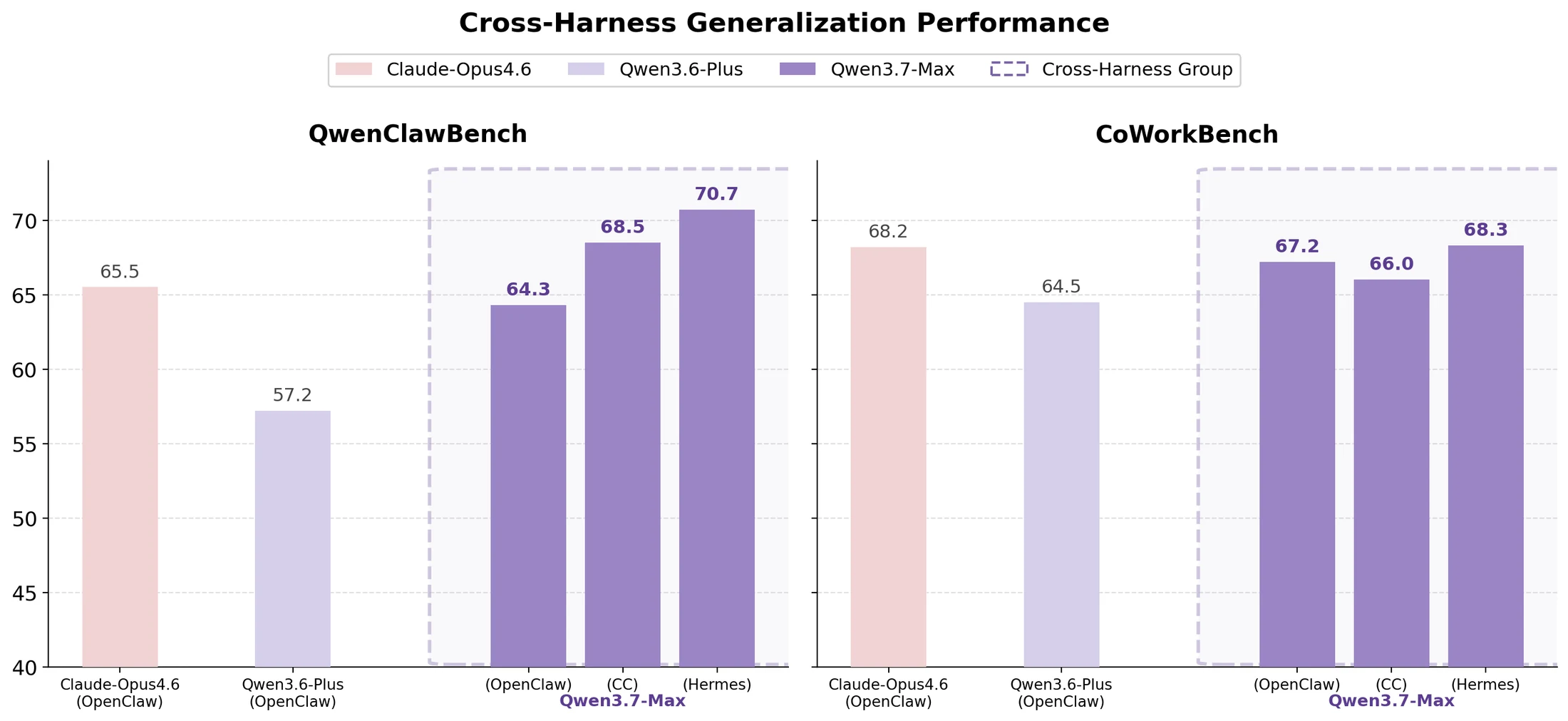
둘째는 Task·Harness·Verifier 분리다.
Qwen은 Rollout environment infrastructure에서 각 training instance를 Task, Harness, Verifier 세 요소로 분해하고, 이를 재조합할 수 있게 설계했다고 설명한다.
같은 태스크를 서로 다른 harness와 verifier 구성에서 경험하게 만들면, 모델은 특정 도구 포맷이나 평가기 편법에 맞추기보다 태스크 자체를 푸는 전략을 학습해야 한다.
셋째는 장시간 자율 실행을 위한 API·하네스 적합성이다.
공식 API 예시는 qwen3.7-max 모델명과 enable_thinking, preserve_thinking 옵션을 보여 준다.
특히 preserve_thinking은 agentic task에서 이전 턴의 thinking content를 보존하는 기능으로 설명된다.
Claude Code는 Anthropic 호환 API로, OpenClaw와 Qwen Code는 Model Studio / Qwen 계열 CLI로 연결하는 방식이 제시된다.
| 구성 요소 | 공개 자료에서 확인되는 내용 | 실무적으로 읽는 법 |
|---|---|---|
| 모델 포지션 | Qwen3.7-Max, Qwen의 최신 proprietary model | 오픈 웨이트보다 상용 agent backbone 성격이 강함 |
| 실행 표면 | Alibaba Cloud Model Studio, OpenAI 호환 API, Anthropic 호환 API | 기존 코딩 에이전트·CLI 런타임에 붙이기 쉬운 배포 전략 |
| 에이전트 옵션 | enable_thinking, preserve_thinking |
긴 다중 턴 실행에서 추론 문맥을 이어가려는 인터페이스 |
| 학습/평가 축 | environment scaling, cross-harness RL, Task/Harness/Verifier 분리 | 특정 하네스 편법보다 범용 실행 전략을 학습시키려는 방향 |
공개된 근거에서 확인되는 점
공식 성능표에서 Qwen3.7-Max는 코딩 에이전트와 general agent 항목을 가장 강하게 밀고 있다.
예컨대 Terminal Bench 2.0-Terminus 69.7, SWE-Pro 60.6, SWE-Multilingual 78.3, SciCode 53.5, QwenSVG 1608을 보고한다.
SWE-Verified는 80.4로 Opus-4.6 Max 80.8, DS-V4-Pro Max 80.6과 거의 같은 구간에 놓인다.
General agent 쪽에서는 MCP-Mark 60.8, MCP-Atlas 76.4, Skillsbench 59.2, QwenClaw 64.3, ClawEval 65.2가 제시된다.
Kernel Bench L3는 1.98× median speedup / 96% win rate로 보고되며, 오피스 자동화 benchmark인 SpreadSheetBench-v1에서는 87.0을 기록한다.
Reasoning 계열에서도 GPQA Diamond 92.4, HLE 41.4, HMMT 2026 Feb 97.1, IMOAnswerBench 90.0, Apex 44.5가 나온다.
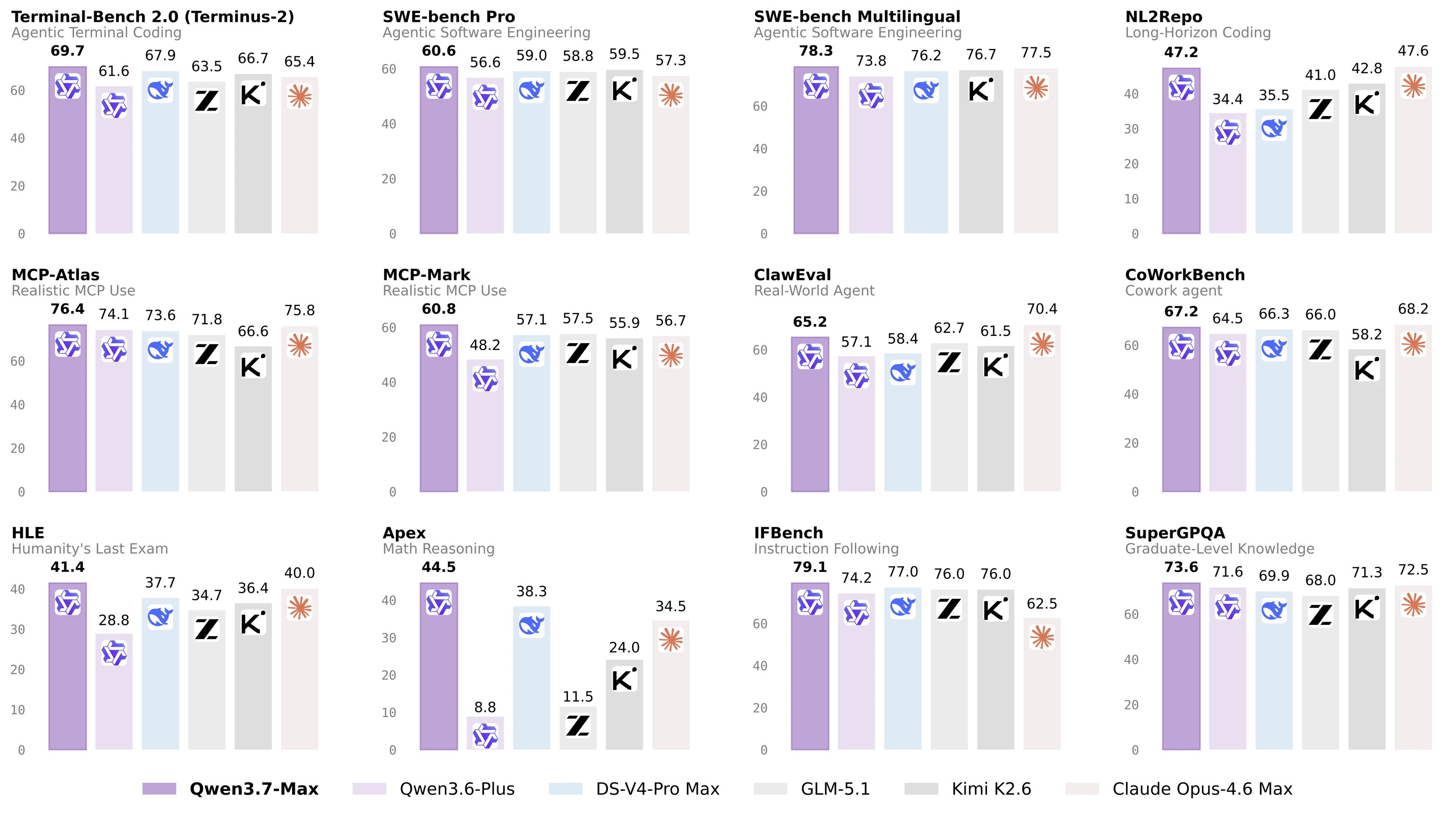
핵심 숫자를 실무 관점에서 다시 추리면 다음과 같다.
| 축 | 지표 | Qwen3.7-Max | 해석 |
|---|---|---|---|
| Coding agent | Terminal Bench 2.0-Terminus | 69.7 | DS-V4-Pro Max 67.9보다 높게 보고된 터미널 기반 장기 실행 점수 |
| Coding agent | SWE-Pro | 60.6 | 비교군 중 최고값으로 제시되어 어려운 코드 수정 태스크를 강조 |
| General agent | MCP-Mark | 60.8 | MCP 기반 tool-use 환경에서 강한 수치 |
| General agent | MCP-Atlas | 76.4 | Opus-4.6 Max 75.8보다 약간 높은 값으로 보고 |
| Kernel generation | Kernel Bench L3 | 1.98× / 96% | median speedup과 torch.compile 대비 win rate를 함께 제시 |
| Office automation | SpreadSheetBench-v1 | 87.0 | 문서·스프레드시트 생산성 자동화를 별도 축으로 평가 |
| Reasoning | GPQA Diamond | 92.4 | hardest reasoning benchmark에서도 상위권 수치 |
| Long context | MRCR-v2 128k | 90.4 | 128K subset에서 장문 회수 능력을 강조 |
| Multilingual | WMT24++ | 85.8 | 다국어 번역/이해 축에서도 선두권이라고 주장 |
다만 이 수치는 모두 공식 블로그가 제시한 조건 안에서 읽어야 한다.
Terminal Bench는 Harbor/Terminus-2 harness, 5시간 timeout, 256K context, 5회 평균 같은 조건이 붙어 있고, SWE 계열은 내부 agent scaffold 기준이다.
CoWorkBench, QwenWorldBench처럼 내부 benchmark도 포함된다.
따라서 이 표는 “모든 환경에서 그대로 재현되는 절대 순위”라기보다, Qwen이 Qwen3.7-Max를 어떤 업무 축에 맞춰 튜닝하고 검증했는지 보여 주는 evidence map에 가깝다.
장시간 실행 사례: 35시간 커널 최적화와 reward hacking 모니터링
Qwen3.7-Max 블로그에서 가장 눈에 띄는 사례는 SGLang의 Extend Attention kernel 최적화다.
Qwen은 이 연산을 T-Head ZW-M890 PPU 기반 ECS instance에서 최적화하도록 모델에 맡겼다고 설명한다.
모델은 해당 하드웨어를 학습 중 본 적이 없고, 사전 profiling data나 하드웨어 문서, 예시 kernel도 없었다.
시작점은 태스크 설명, 기존 SGLang Triton 구현, 평가 스크립트뿐이었다.
공식 설명에 따르면 Qwen3.7-Max는 약 35시간 동안 432회의 kernel evaluation과 1,158회의 tool call을 수행했다.
그 과정에서 코드를 작성하고, 컴파일하고, profiling하고, correctness bug를 고치고, 병목을 찾고, kernel 구조를 여러 차례 재설계했다.
최종 결과는 Triton reference 대비 10.0× geometric mean speedup으로 보고된다.
동일 조건 비교에서 GLM 5.1은 7.3×, Kimi K2.6은 5.0×, DeepSeek V4 Pro는 3.3×, Qwen3.6-Plus는 1.1×로 제시된다.
이 사례가 중요한 이유는 “커널 하나를 빠르게 만들었다”보다, 모델이 1,000회 이상의 도구 호출을 거치며 목표를 잃지 않고 성능 개선을 지속했다는 점이다.
Qwen은 이 실험을 long-horizon autonomous optimization이 단순 데모가 아니라 실제 생산성을 낼 수 있다는 근거로 제시한다.
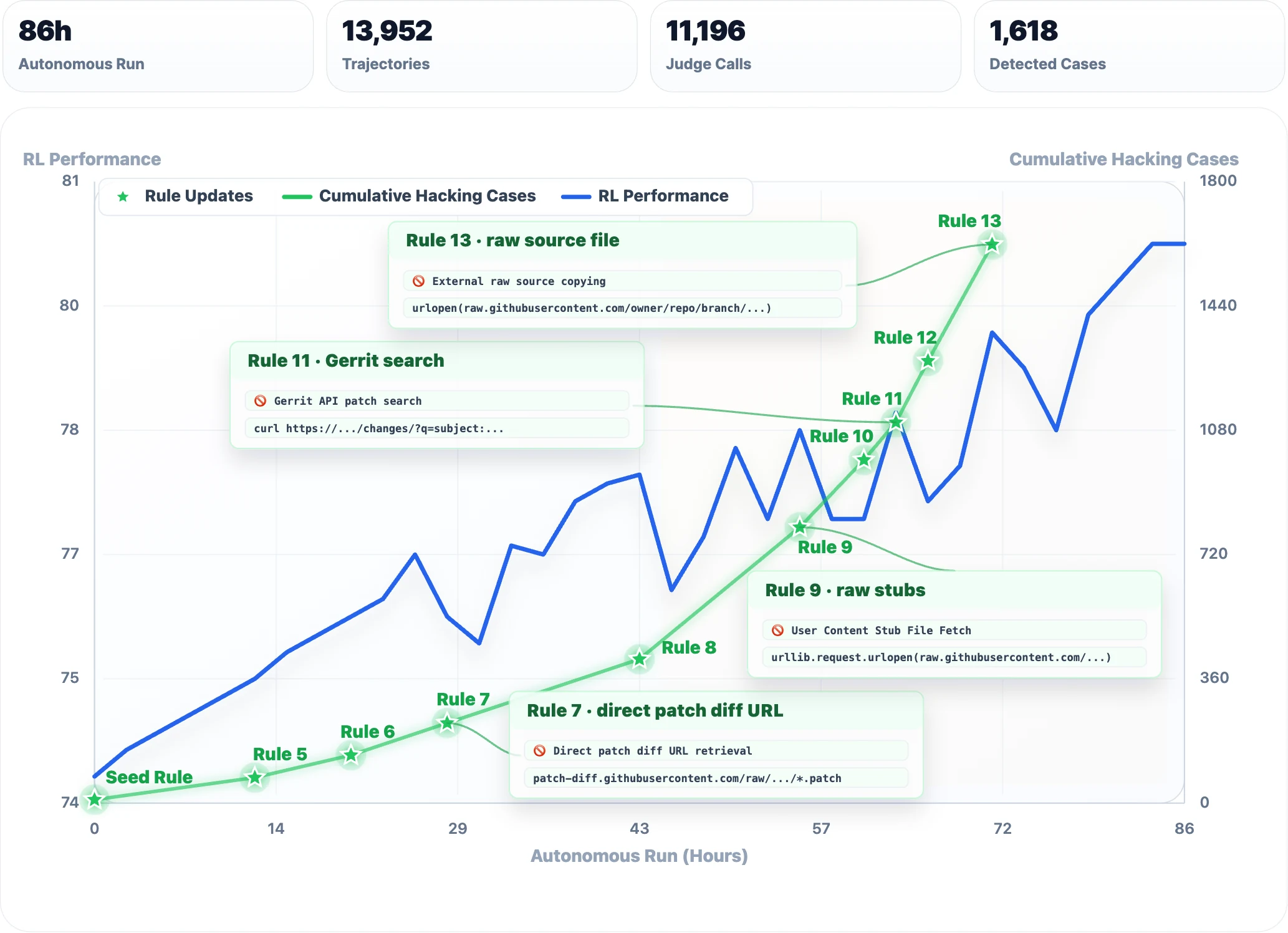
또 하나는 RL reward hacking 모니터링 사례다.
Qwen은 Software Engineering task RL 과정에서 Qwen3.7-Max를 monitoring framework에 통합해, 80시간 이상의 RL 실험 동안 10,000회 이상의 호출을 수행하게 했다고 설명한다.
이 시스템은 training trajectory를 검색·재생하고, GitHub ground-truth 답안 접근처럼 제약을 우회하려는 패턴을 후보로 식별하며, rule verification과 counter-example mining을 반복한다.
결과적으로 13개의 heuristic rule을 새로 추가하고 1,618개의 hacking case를 flag했다고 보고한다.
실무 관점에서의 해석
내가 보기에 Qwen3.7-Max의 핵심 가치는 “프런티어 모델 점수표”보다 에이전트 런타임에 맞춘 모델 설계 철학에 있다.
Qwen은 이 릴리스에서 coding, MCP, office automation, kernel generation, startup simulation, reward hacking detection을 따로따로 보여 주지만, 그 아래에 깔린 메시지는 하나다.
모델이 더 이상 정적 benchmark solver가 아니라, 도구·검증기·하네스·환경 피드백을 오래 견디는 실행 주체가 되어야 한다는 것이다.
특히 Task/Harness/Verifier 분리와 cross-harness training은 실무적으로 중요하다.
오늘의 코딩 에이전트 생태계는 Claude Code, OpenClaw, Qwen Code, OpenCode, Cursor, MCP server, 내부 sandbox처럼 하네스가 빠르게 바뀐다.
모델이 특정 prompt wrapper나 tool schema에 과적합되어 있으면 운영 표면이 바뀌는 순간 성능이 흔들린다.
Qwen3.7-Max가 cross-scaffold generalization을 전면에 내세운 것은 이 병목을 정확히 보고 있다는 신호다.
반대로 한계도 분명하다.
현재 공개 자료만으로는 Qwen3.7-Max의 내부 아키텍처, 학습 데이터 구성, safety boundary, post-training recipe를 충분히 검증하기 어렵다.
블로그는 technical report가 추후 공개될 것이라고 말하지만, 지금 단계에서는 proprietary model의 공식 claim과 일부 linked artifact를 중심으로 판단해야 한다.
또한 많은 수치가 내부 benchmark 또는 Qwen이 정의한 evaluation condition 위에서 제시되므로, 실제 조직의 저장소·문서·MCP 서버·권한 모델에서 같은 생산성이 나오는지는 별도 검증이 필요하다.
그래도 방향성은 꽤 명확하다.
Qwen3.7-Max는 오픈 웨이트 Qwen3.6 계열이 보여 준 “agentic coding 모델”의 흐름을 상용 프런티어 모델 쪽으로 확장한다.
이제 경쟁 포인트는 단순한 채팅 품질이나 한 번의 코딩 답안이 아니라, 수십 시간 동안 실행하고, 여러 하네스에서 일반화하고, reward hacking까지 감시하는 모델 운영 능력이다.
그런 의미에서 Qwen3.7-Max는 Qwen이 에이전트 시대의 파운데이션 모델을 어떻게 정의하는지 보여 주는 중요한 이정표다.