문서 AI 파이프라인은 오래전부터 두 갈래로 쪼개져 있었다.
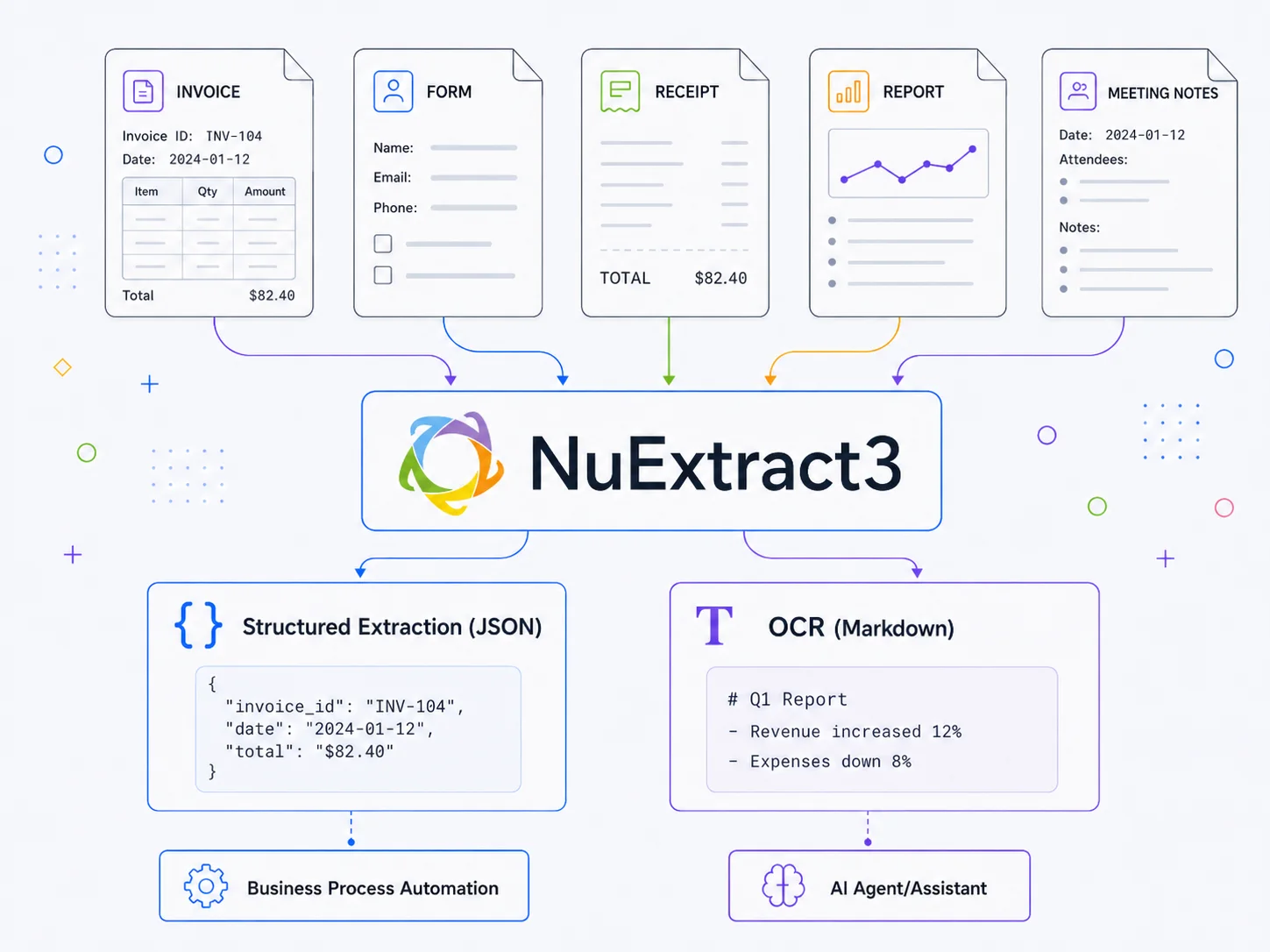
하나는 문서에서 특정 필드만 뽑아 JSON으로 만드는 structured extraction이고, 다른 하나는 문서 전체를 Markdown이나 텍스트로 바꾸는 content extraction, 즉 OCR 계열 작업이다.
전자는 은행, 보험, 헬스케어, 물류 같은 업무 시스템의 데이터 입력을 자동화하고, 후자는 RAG나 에이전트가 문서를 읽을 수 있게 만드는 전처리 단계가 된다.
NuExtract3는 이 둘을 별도 모델과 별도 파이프라인으로 보지 않는다.
NuMind의 공식 릴리스 글과 Hugging Face 모델 카드를 종합하면, NuExtract3는 Qwen3.5-4B를 기반으로 한 약 4.54B 파라미터 규모의 vision-language model이며, 문서 이미지를 보고 JSON 템플릿에 맞춘 구조화 출력과 Markdown/OCR 출력을 모두 수행하도록 학습됐다.
모델 가중치는 Apache 2.0 라이선스로 공개됐고, GitHub inference/fine-tuning 스크립트 저장소는 MIT 라이선스다.
흥미로운 지점은 단순히 “OCR도 되고 JSON도 된다”가 아니다.
NuExtract3의 핵심 메시지는 문서 추출을 하나의 문서 이해 문제로 다시 정의한다는 데 있다.
문서를 제대로 이해하면 특정 필드도 뽑을 수 있고, 전체 내용을 AI가 읽기 좋은 Markdown으로도 복원할 수 있다.
반대로 이 두 작업을 따로 최적화하면 배포는 복잡해지고, 같은 문서를 두 번 처리하며, 실패 모드도 분리된다.
무엇을 해결하려는가
문서 추출의 병목은 글자를 읽는 것만이 아니다.
실제 업무 문서는 표가 쪼개져 있고, 헤더가 반복되지 않으며, 셀 내용이 옆 셀로 넘치고, 여러 페이지에 걸쳐 같은 구조가 이어진다.
깨끗한 스캔 문서라면 전통적 OCR과 규칙 기반 후처리도 어느 정도 통하지만, 영수증, 청구서, 급여명세서, 계약서, 손글씨가 섞인 양식, 복잡한 테이블이 나오면 단순 문자 인식 정확도만으로는 품질을 설명하기 어렵다.
NuMind는 이 문제를 structured extraction과 content extraction의 공통 기반인 document understanding으로 본다.
JSON 추출은 문서의 특정 leaf 값을 정확히 찾아야 하고, Markdown/OCR은 후속 LLM이 다시 읽을 수 있을 만큼 정보와 레이아웃을 보존해야 한다.
둘 다 문서 구조, 표의 의미, 주변 맥락, 필드의 타입 제약을 함께 다뤄야 한다.
공식 글에서 특히 강조하는 난점은 복잡한 표다.
여러 표가 나란히 있거나, 행과 열이 나뉘거나, 셀이 서로 겹쳐 보이는 경우 범용 VLM도 자주 흔들린다.
이런 케이스에서는 모델이 바로 답을 쓰기보다 문서 구조를 먼저 해석하고 잠재적 함정을 점검하는 reasoning이 도움이 된다.
핵심 아이디어 / 구조 / 동작 방식
NuExtract3의 설계는 세 가지 축으로 읽을 수 있다.
첫째, 출력 모드를 통합한다. structured extraction에서는 입력 문서와 JSON 템플릿을 함께 넣고, 모델이 같은 구조의 JSON 값을 채운다. content extraction에서는 템플릿 없이 문서를 Markdown으로 변환한다.
Hugging Face 모델 카드의 예시를 보면 입력은 텍스트, 이미지, 또는 text+image가 될 수 있고, 여러 페이지 PDF는 페이지별 이미지로 렌더링한 뒤 순서대로 전달하는 방식을 안내한다.
둘째, reasoning을 운영 옵션으로 만든다.
NuExtract3는 non-thinking mode와 thinking mode를 모두 지원한다.
모델 카드 기준으로 빠르고 결정적인 추출이나 Markdown 변환에는 enable_thinking=false를 쓰고, 복잡한 레이아웃·모호한 필드·어려운 문서 구조에는 enable_thinking=true를 켜는 식이다.
즉 reasoning은 항상 켜져 있는 마케팅 기능이 아니라, 품질이 필요한 샘플에서만 비용을 지불하는 선택지가 된다.
셋째, 템플릿 제어면을 넓힌다.
NuExtract 2.0의 typed template 개념을 이어받아 verbatim-string, date, currency, country, iban, bic, unit-code, region:KR 같은 타입 제약을 제공한다.
여기에 자연어 instruction, in-context example, template generation이 붙는다.
실무적으로는 “필드 이름을 길게 늘려 힌트를 주는 template engineering” 대신, 스키마·타입·추가 지시·예시를 분리해서 관리할 수 있다는 뜻이다.

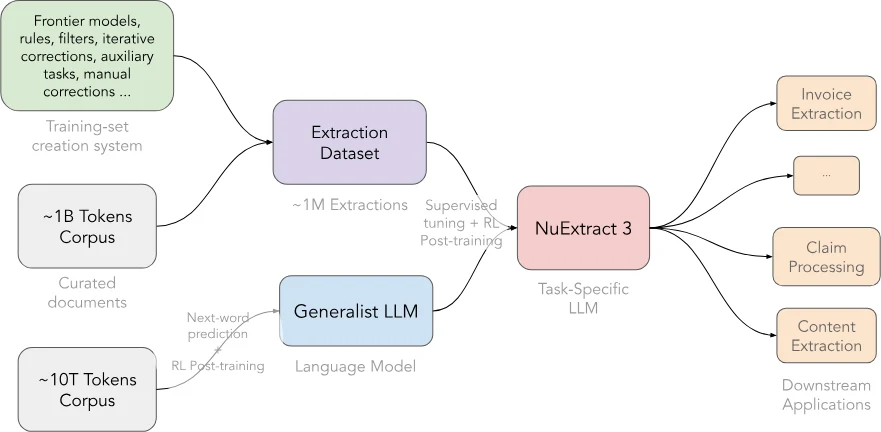
학습 절차도 이 관점과 맞물린다.
공식 글은 실제 문서 데이터로 Fine-PDF를 사용하고, LLM annotator/judge, 반복 교정, programmatic filtering을 통해 자동 주석을 만든다고 설명한다.
여기에 완전히 주석이 가능한 복잡한 synthetic document를 더해 난도를 확보한다.
이후 Qwen3.5-4B를 기반으로 supervised fine-tuning을 먼저 수행하고, template adherence와 reasoning 능력을 강화하기 위해 reinforcement learning을 추가한다.
| 설계 축 | NuExtract3에서의 의미 | 실무적 함의 |
|---|---|---|
| 출력 통합 | JSON 구조화 추출과 Markdown/OCR을 같은 모델이 처리 | OCR 모델, IE 모델, 후처리 모델을 따로 운영하는 복잡도를 줄일 수 있음 |
| 선택적 reasoning | 어려운 문서에서만 thinking mode를 켜는 방식 | latency와 품질 사이의 운영 knob가 생김 |
| typed template | leaf 값에 타입 제약을 부여 | 후처리와 값 정규화 비용을 줄일 수 있음 |
| instruction / ICL | 템플릿 외 추가 설명과 예시를 제공 | 애매한 업무 규칙을 field name에 억지로 밀어 넣지 않아도 됨 |
| vLLM / Transformers 표면 | OpenAI-compatible API 또는 직접 transformers 실행 |
실험과 제품 배포 사이의 이식성이 좋아짐 |
공개된 근거에서 확인되는 점
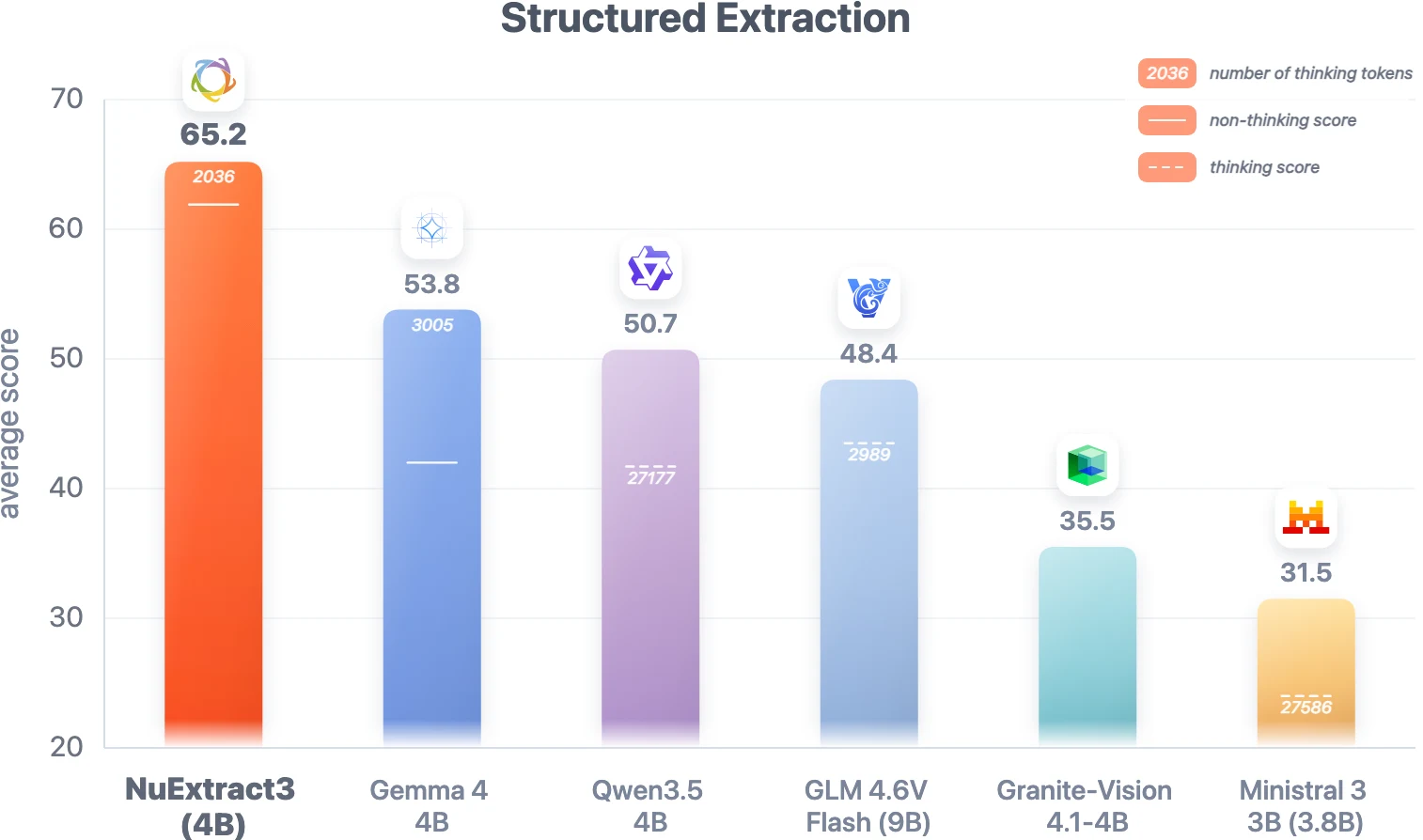
structured extraction 평가에서 NuMind는 약 600개 challenging extraction과 15개 문제를 포함한 내부 벤치마크를 사용한다.
출력 JSON을 tree로 보고 leaf 값을 ground truth와 비교하는 EXTRA metric을 쓰며, 문자열 계열에는 indel distance, 그 외 타입에는 exact match를 적용한다고 설명한다.
공식 글은 이 벤치마크와 metric에 대한 논문을 준비 중이라고 밝힌다.
공식 figure 기준으로 NuExtract3는 structured extraction에서 평균 65.2점을 기록하며, 비슷한 크기의 Gemma 4 4B 53.8, Qwen3.5 4B 50.7, GLM 4.6V Flash 48.4 등을 앞선다.
Hugging Face 모델 카드의 표도 NuExtract3.4_4B-RL이 0.651 ± 0.019를 기록했고, JSON deserialization 실패 수가 27개였다고 보고한다.
이 숫자는 closed benchmark이므로 독립 재현 가능한 공개 리더보드와는 구분해야 하지만, 적어도 NuMind가 모델을 어떤 품질 기준으로 최적화했는지는 분명하다.
OCR/Markdown 평가 쪽이 더 흥미롭다.
NuMind는 단순 OCRBench류의 문자 인식이나 layout preservation만으로는 후속 AI 사용성을 잘 측정하기 어렵다고 본다.
그래서 두 가지 평가를 제시한다.
하나는 150개 복잡한 문서에서 Markdown 결과를 LLM judge로 비교하는 “OCR battle”이고, 다른 하나는 structured extraction benchmark를 역으로 활용하는 방식이다.
두 번째 방식은 특히 문서 AI 제품 관점에서 설득력이 있다.
각 OCR 모델이 600개 문서를 Markdown으로 바꾸고, 별도의 Qwen3.6 27B가 그 Markdown에서 다시 구조화 정보를 추출한다.
그런 다음 약 100k leaf value를 ground truth와 비교한다.
즉 Markdown이 예쁘게 보이는지가 아니라, 후속 LLM이 실제로 쓸 수 있는 정보가 보존됐는지를 본다.
공식 figure 기준 NuExtract3는 thinking mode에서 70.1점을 기록하며, Chandra OCR 2 66.5, Qwen3.5 4B 66.2, GLM 4.6V Flash 63.8보다 높다.
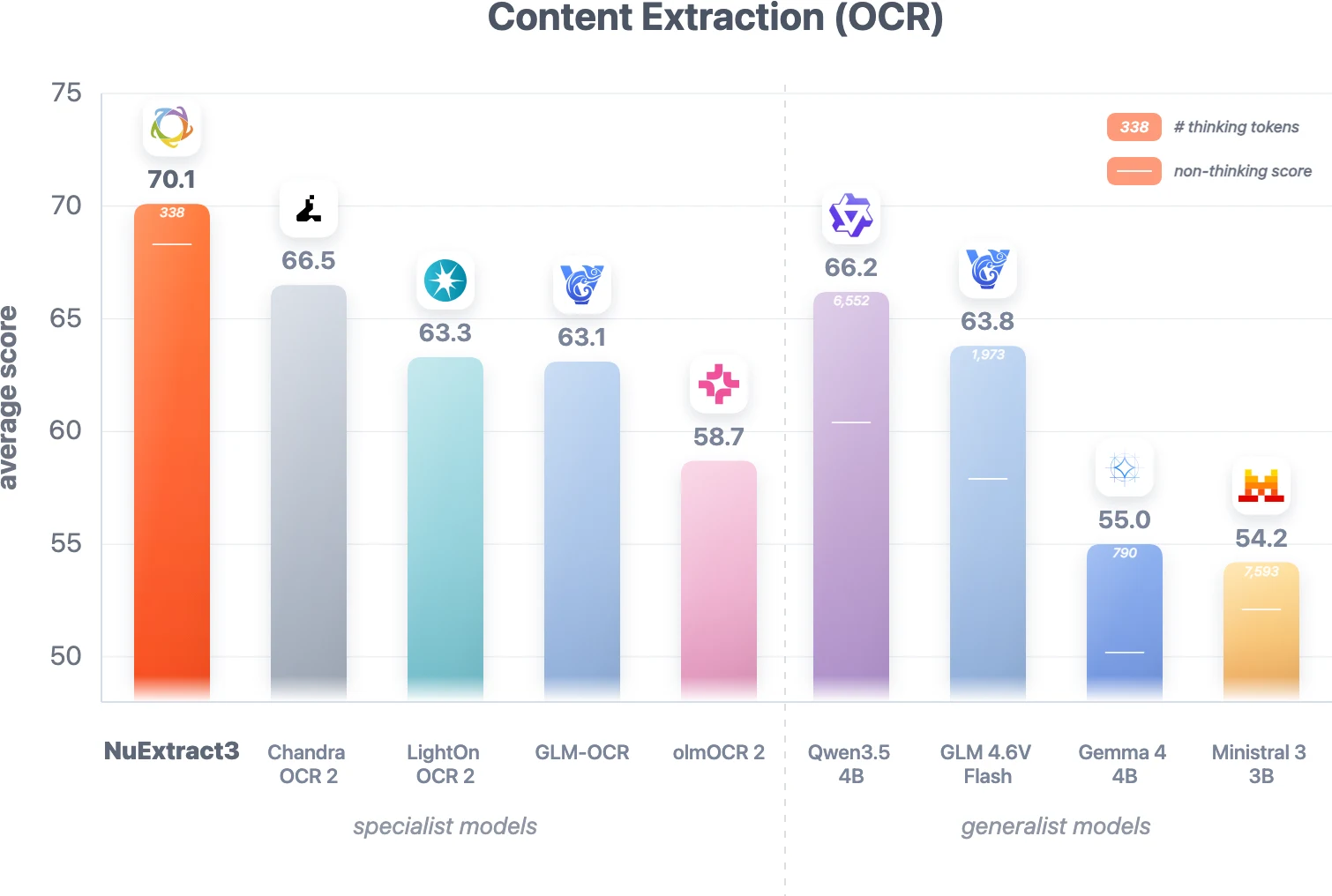
reasoning 비용도 중요한 신호다.
공식 글은 generalist thinking model이 output token보다 훨씬 많은 thinking token을 생성해 비용과 latency를 크게 키우는 문제를 지적한다.
NuExtract3는 thinking token 수를 output token과 비슷한 규모로 쓰도록 학습됐고, content extraction 평가에서는 평균 338개 thinking token으로 동작했다고 보고한다.
같은 figure에서 Qwen3.5 4B는 6,552개, GLM 4.6V Flash는 1,973개의 thinking token을 쓴다.
이것은 reasoning을 많이 하는 모델이 아니라, 문서 추출에 필요한 만큼만 생각하도록 훈련한 모델이라는 포지셔닝에 가깝다.
배포 표면도 비교적 실용적으로 정리돼 있다.
Hugging Face API 조회 시점 기준 numind/NuExtract3는 public/gated false 상태이고, transformers, safetensors, image-to-text, document-understanding, structured-extraction, ocr, rag, reasoning, multilingual 태그를 갖는다. safetensors metadata는 BF16 파라미터 약 4.54B, 저장 크기 약 9.34GB를 보고한다.
모델 카드는 vLLM으로 OpenAI-compatible API를 띄우는 명령을 제공하며, --max-model-len 131072, multi-image prompt 제한, speculative decoding용 MTP 설정도 함께 제시한다.
GitHub 저장소 numindai/nuextract는 inference와 fine-tuning 스크립트, README, asset, NuExtract2 관련 디렉터리를 포함한다.
조회 시점 기준 stars 128, forks 17, open issues 7이고, 최신 release/tag는 별도로 보이지 않았다.
따라서 현재 공개 표면은 “완성된 엔터프라이즈 제품 전체”라기보다, Hugging Face 모델 카드와 vLLM/Transformers 예시, 그리고 NuExtract Platform/API·Enterprise 배포 표면이 결합된 release bundle로 보는 편이 정확하다.
실무 관점에서의 해석
내가 보기에 NuExtract3의 가장 중요한 메시지는 OCR과 정보 추출을 더 이상 별도 시장으로 나누지 않는다는 점이다.
RAG 팀은 보통 OCR 품질을 “텍스트가 얼마나 잘 나왔는가”로 보고, 업무 자동화 팀은 JSON 필드 정확도를 별도로 본다.
하지만 실제 운영에서는 두 문제가 서로 이어져 있다.
OCR Markdown이 후속 LLM에게 쓸모없으면 RAG가 흔들리고, 구조화 추출이 schema/type 제약을 지키지 못하면 업무 시스템에 넣기 전에 다시 사람이 고쳐야 한다.
NuExtract3는 이 연결을 모델 자체와 평가 방식에 반영한다. content extraction을 평가할 때 Markdown 결과의 스타일이 아니라 후속 structured extraction 성능을 본다는 점이 특히 좋다.
문서 AI에서 중요한 것은 완벽한 시각 복원이 아니라, 정보가 손실 없이 다음 시스템으로 넘어가는가다.
이 관점은 문서 전처리를 LLM/RAG/agent pipeline의 하위 공정으로 보는 팀에게 유용하다.
동시에 이 release를 과대해석하면 안 된다. structured extraction benchmark는 아직 내부 벤치마크이고, OCR battle에는 LLM judge 편향이 남아 있다.
모델 카드와 공식 글은 수치와 예시를 꽤 많이 제공하지만, 공개 벤치마크·논문·leaderboard가 더 열려야 독립 비교가 쉬워진다.
또한 실무 도입에서는 confidence score, bounding box, field-level provenance, human review UI 같은 주변 시스템이 여전히 필요하다.
NuMind도 릴리스 글 마지막에서 NuExtract4 우선순위 후보로 model confidence, bounding boxes, content extraction instruction을 언급한다.
그럼에도 NuExtract3는 문서 AI 제품 설계에서 참고할 만한 방향을 제시한다.
하나의 4B급 VLM으로 JSON과 Markdown을 모두 다루고, reasoning을 always-on이 아니라 selective compute로 다루며, OCR 품질을 후속 LLM 사용성으로 평가하는 방식이다.
문서가 단순 텍스트 저장소가 아니라 ERP, CRM, 데이터베이스, RAG, 에이전트로 흘러 들어가는 운영 자산이라면, 이런 통합형 document extractor는 별도 OCR 엔진과 별도 IE 모델을 이어 붙이는 기존 파이프라인보다 관리 가능한 추상화가 될 수 있다.