대형 언어모델이 강해질수록 실무에서 더 자주 부딪히는 질문은 “무엇을 할 수 있는가”보다 “왜 그렇게 동작하는가, 그리고 그 동작을 얼마나 제어할 수 있는가”에 가까워진다.
특히 다국어 출력이 갑자기 섞이거나, 특정 벤치마크가 사실상 같은 능력을 중복 측정하거나, 안전 데이터가 충분해 보여도 롱테일 위험 패턴을 놓치는 문제는 모델 바깥의 프롬프트 조정만으로는 잘 풀리지 않는다.
Qwen 팀이 2026년 4월 30일 공개한 Qwen-Scope는 이 문제를 sparse autoencoder(SAE) 관점에서 다시 다룬다.
공식 기술 보고서와 Hugging Face 모델 카드에 따르면 Qwen-Scope는 Qwen3·Qwen3.5 계열 7개 모델에 걸쳐 14개 그룹의 SAE를 공개하고, 이를 단순 시각화나 feature labeling 도구에 머물지 않고 추론 조종, 벤치마크 분석, 데이터 분류·합성, 사후 훈련 최적화까지 연결한다.
핵심 메시지는 분명하다.
SAE는 더 이상 “모델 안을 들여다보는 현미경”만이 아니라, 모델 개발 파이프라인에서 재사용 가능한 표현 수준 인터페이스가 될 수 있다는 주장이다.
내가 보기에 Qwen-Scope의 흥미로운 지점은 해석 가능성을 안전 연구의 부속품처럼 다루지 않는다는 데 있다.
오히려 Qwen은 sparse feature를 language steering, benchmark de-duplication, safety data coverage, post-training loss 설계에 공통으로 재사용하면서, 해석 가능성을 개발자 도구 체인 안으로 넣으려 한다.
즉 “모델을 설명하는 기술”을 “모델을 운영하고 개선하는 기술”로 밀어 올리는 시도에 가깝다.
무엇을 해결하려는가
Qwen-Scope가 겨냥하는 문제는 LLM 내부 표현이 너무 불투명해서, 오류를 진단하거나 특정 행동을 교정할 때 늘 우회적 수단에 의존해야 한다는 점이다.
예를 들어 코드 전환(code-switching), 무한 반복, 안전 데이터의 커버리지 공백, 혹은 벤치마크 간 능력 중복 같은 문제는 모두 출력 관찰만으로는 원인을 분해하기 어렵다.
모델을 더 많이 돌려 보고 점수를 비교하는 방법은 가능하지만, 왜 그런 현상이 생겼는지를 표현 수준에서 직접 읽어 내는 인터페이스는 드물었다.
기존 SAE 연구도 강한 가능성을 보여 주었지만, 주로 feature discovery와 monosemanticity 논의에 무게가 있었다.
반면 Qwen-Scope는 “발견한 feature를 실제 개발 워크플로에서 어떻게 써먹을 것인가”를 전면으로 끌어온다.
공식 초록이 steering, evaluation analysis, data-centric workflow, post-training optimization의 네 갈래를 첫 페이지에서 바로 내세우는 이유도 여기에 있다.
또 하나 중요한 문제는 비용이다.
벤치마크 간 중복성이나 안전 데이터 부족을 알아내기 위해 매번 여러 모델을 전부 평가하는 것은 비싸다.
Qwen-Scope는 SAE activation 집합을 benchmark fingerprint로 보아, 모델 성능을 반복 측정하기 전에 표현 수준에서 중복성과 겹침을 먼저 진단하려 한다.
이는 해석 가능성을 설명 도구가 아니라 비용 절감형 개발 도구로도 본다는 뜻이다.
핵심 아이디어 / 구조 / 동작 방식
구조적으로 Qwen-Scope는 Qwen3·Qwen3.5 계열의 hidden layer residual stream 위에 layer-wise Top-K SAE를 얹는다.
기술 보고서 첫 페이지와 Hugging Face 컬렉션 설명 기준으로 공개 범위는 7개 모델, 14개 SAE 그룹이며 dense와 mixture-of-experts(MoE) 모델을 모두 포함한다.
대표 모델 카드인 SAE-Res-Qwen3-8B-Base-W64K-L0_50를 보면 base model은 Qwen3-8B, SAE width는 65,536, hidden size는 4,096, Top-K는 50, 레이어 범위는 0~35 전체다.
핵심 메커니즘은 단순하다. residual activation을 과완전(overcomplete) sparse feature 공간으로 사상하고, 그중 상위 K개 feature만 남긴 뒤 다시 원 공간으로 복원한다.
이렇게 하면 매 토큰마다 수만 개 feature 중 극히 일부만 활성화되므로, 특정 언어·개념·행동 패턴과 연결된 방향을 더 추적하기 쉬워진다.
모델 카드의 예제 코드도 실제로 transformer layer hook을 걸고, W_enc와 b_enc를 사용해 residual을 sparse feature activation으로 바꾸는 흐름을 그대로 보여 준다.
Qwen-Scope의 포인트는 여기서 끝나지 않는다.
이 sparse feature를 네 종류의 downstream interface로 재사용한다.
첫째, 특정 feature 방향을 증폭하거나 억제해 추론 시 출력 언어와 스타일을 조정한다.
둘째, benchmark sample이 어떤 feature 집합을 활성화하는지 보고 redundancy와 similarity를 추정한다.
셋째, safety/toxicity 관련 feature를 이용해 rule-based classifier를 만들고, 커버되지 않은 안전 feature를 목표로 데이터를 합성한다.
넷째, post-training 시 feature 억제 보조 손실이나 rare negative augmentation을 구성해 SASFT와 RL 최적화 신호로 사용한다.
| 레이어 | 공개 자료에서 확인되는 구성 | 역할 |
|---|---|---|
| SAE backbone | 7개 모델, 14개 SAE 그룹, dense + MoE 커버 | Qwen 계열 전반에 공통 sparse feature 인터페이스 제공 |
| Feature extraction | residual stream hook, overcomplete sparse dictionary, Top-K 활성화 | 내부 표현을 희소하고 추적 가능한 feature 집합으로 변환 |
| Inference control | feature direction 증폭/억제 | 가중치 수정 없이 언어·개념·스타일 조종 |
| Evaluation analysis | benchmark별 활성 feature fingerprint | 중복성·유사성·coverage를 모델 성능 계산 없이 추정 |
| Data / training loop | toxicity 분류, safety synthesis, SASFT, RL rare negative augmentation | 해석 feature를 데이터 구성과 사후 훈련 신호로 재사용 |
공개된 근거에서 확인되는 점
가장 먼저 확인되는 사실은 Qwen-Scope가 단일 모델 artifact가 아니라 collection 형태의 배포라는 점이다.
Hugging Face 컬렉션 페이지에는 2026-04-30 기준으로 QwenScope Space와 여러 SAE 체크포인트가 묶여 있고, 대표 체크포인트 API 메타데이터를 보면 예를 들어 Qwen/SAE-Res-Qwen3.5-27B-W80K-L0_50는 likes 28, Qwen/SAE-Res-Qwen3-8B-Base-W64K-L0_50는 36개 레이어용 layer*.sae.pt 파일을 포함한다.
즉 Qwen-Scope는 논문만 공개한 것이 아니라, 실제 layer별 가중치와 데모 표면까지 함께 내놓은 릴리스다.
공식 보고서와 커뮤니티 글에서 공통으로 반복되는 핵심 수치도 비교적 선명하다.
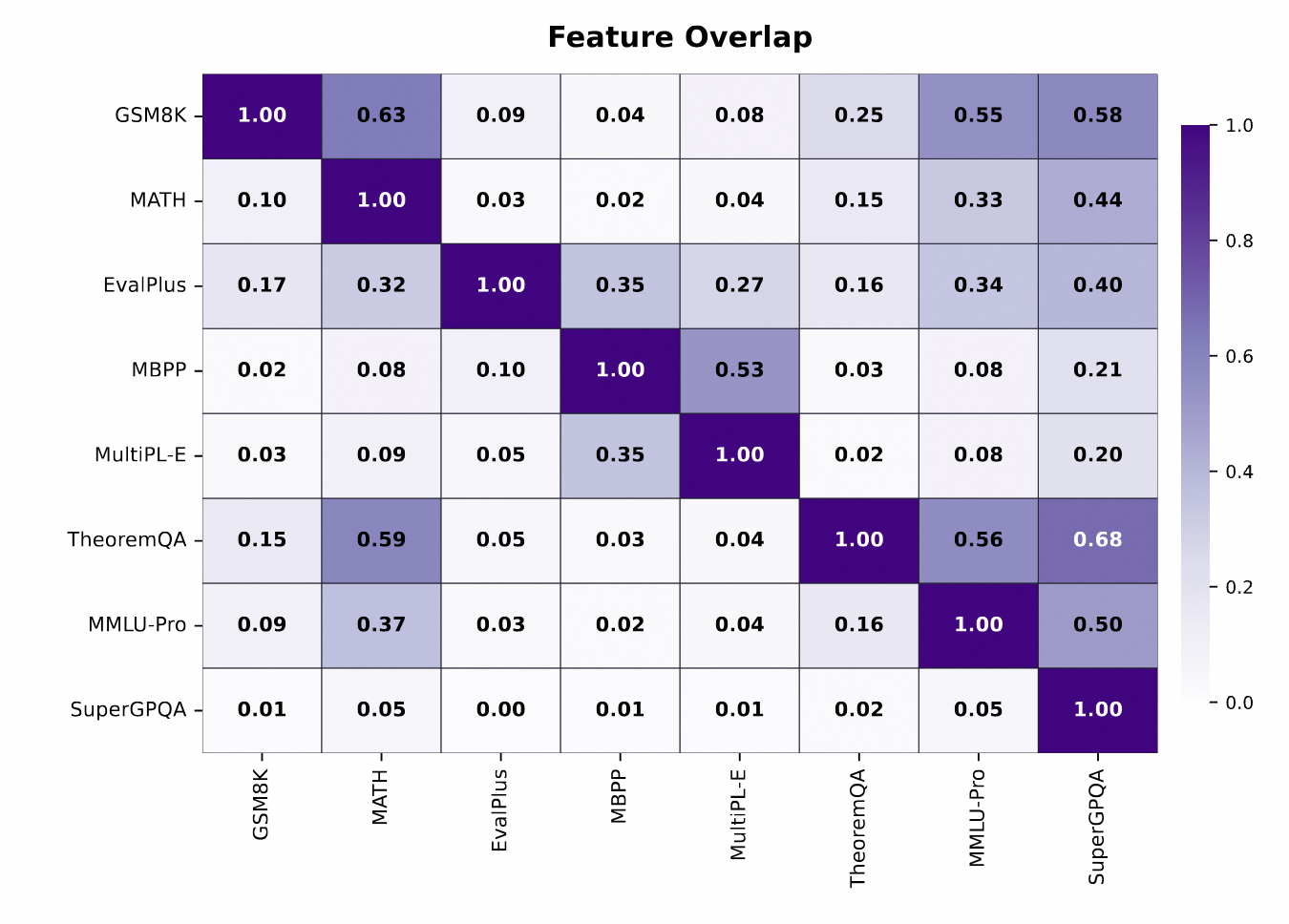
벤치마크 중복성 추정에서는 17개 벤치마크를 대상으로 feature redundancy metric이 성능 기반 redundancy와 스피어만 상관 ρ≈0.85를 보인다고 제시된다.
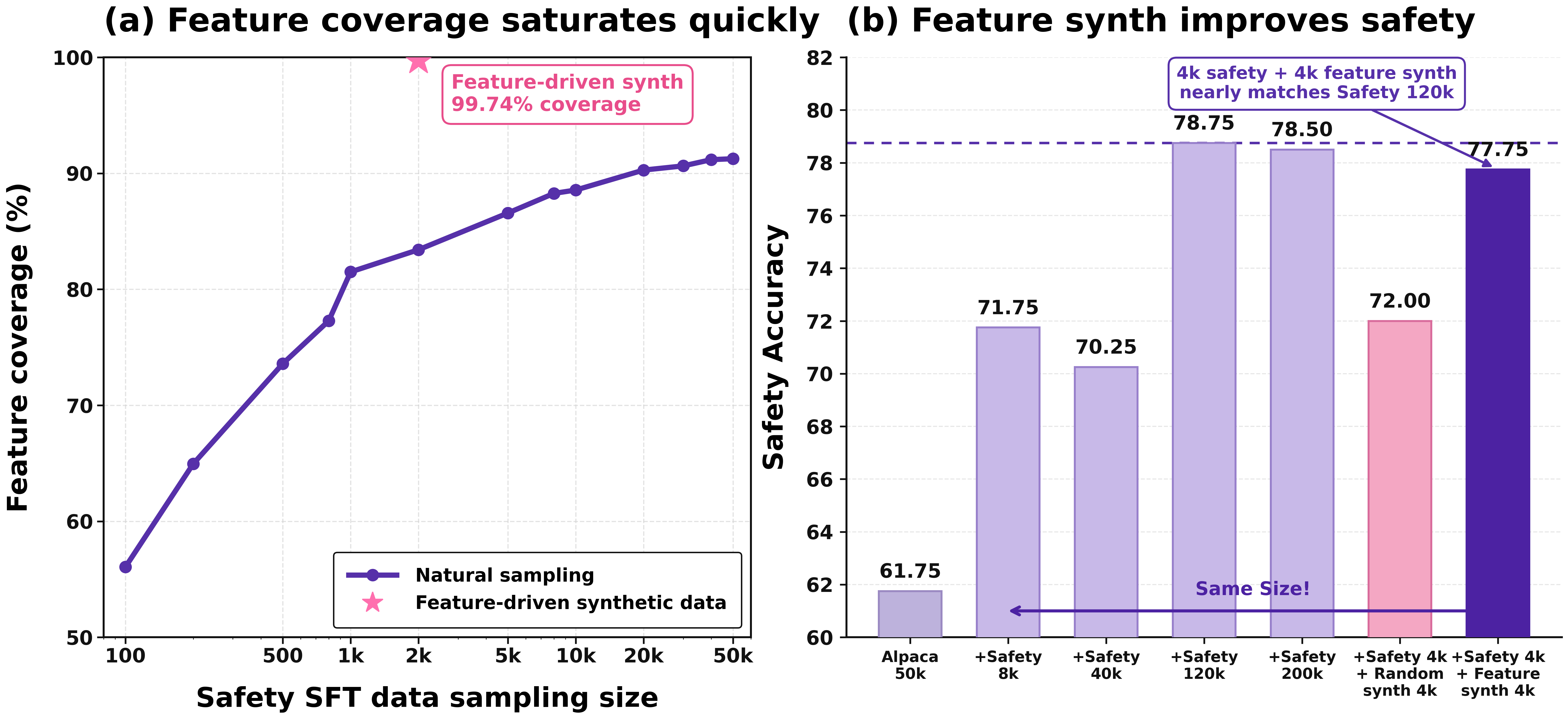
데이터 워크플로에서는 다국어 독성 분류에서 영어 F1 0.90 이상, WildJailbreak 기반 안전 데이터 합성에서는 2,779개 목표 feature 중 99.74% 커버리지를 주장한다. post-training 쪽에서는 SASFT가 다수 설정에서 코드 전환 비율을 50% 이상 줄이고, RL rare negative augmentation이 endless repetition을 더 빠르게 억제한다고 설명한다.
추론 조종 사례도 구체적이다.
보고서 요약과 모델 카드 설명에 따르면 특정 중국어 feature를 억제해 영어 응답에 섞이는 의도치 않은 중국어 출력을 줄이거나, 고전 중국어 문체 feature를 증폭해 스타일을 바꾸는 식의 steering이 가능하다.
이 부분이 중요한 이유는 SAE가 단순히 “어떤 feature가 있었다”를 설명하는 수준이 아니라, 실제 causal intervention 도구로 사용됐다는 점을 보여 주기 때문이다.
라이선스 신호는 조금 더 섬세하게 봐야 한다.
Hugging Face 카드 메타데이터에는 license: other, license_name: qwen으로 표시되지만, 실제 각 모델 저장소의 LICENSE 파일은 Apache 2.0 전문을 담고 있다.
즉 카드 태그만 보면 제한적 라이선스처럼 보이지만, 배포 파일 기준으로는 Apache 2.0에 가깝다.
다만 README 본문에는 interpretability 도구를 harmful content 생성이나 비과학적 간섭 목적으로 쓰지 말라는 별도 caution 문구도 들어 있다.
실무 채택에서는 “법적 라이선스”와 “프로젝트 사용 지침”을 분리해서 읽는 편이 안전하다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| 기술 보고서 1페이지 | 7개 모델, 14개 SAE 그룹, dense + MoE, 네 가지 응용 축 명시 | Qwen-Scope의 메시지는 해석보다 개발 인터페이스화에 있음 |
| HF 모델 카드 | Qwen3-8B 기준 width 65,536, hidden 4,096, Top-K 50, 36개 레이어 가중치 | SAE가 개념 소개가 아니라 실제 사용 가능한 체크포인트로 제공됨 |
| 벤치마크 분석 결과 | 17개 벤치마크에서 redundancy proxy와 성능 기반 redundancy의 ρ≈0.85 | 모델 반복 평가 없이 benchmark 설계를 압축할 가능성 |
| 데이터 워크플로 결과 | 독성 분류 F1>0.90, safety feature 99.74% coverage | feature 기반 분류와 합성이 실용적 수준에 접근했음을 주장 |
| SASFT / RL 설명 | 코드 전환 50%+ 감소, 반복 억제용 rare negative augmentation | SAE를 분석 이후의 학습 신호로 재활용 |
| 라이선스 파일과 카드 메타데이터 | HF 카드엔 other/qwen, 실제 LICENSE는 Apache 2.0 |
메타 태그와 저장소 파일 간 신호 차이를 함께 확인할 필요 |
실무 관점에서의 해석
내가 보기에 Qwen-Scope의 가장 큰 의미는 SAE를 “interpretability artifact”에서 “development primitive”로 재정의했다는 점이다.
많은 해석 가능성 연구가 인상적인 사례와 feature 시각화에서 끝나는 반면, Qwen-Scope는 같은 sparse feature 집합을 steering, benchmark curation, safety dataset design, post-training objective까지 밀어 넣는다.
만약 이 접근이 더 넓게 재현된다면, 앞으로 모델 개발 조직은 hidden representation을 직접 다루는 내부 API를 갖게 되는 셈이다.
특히 평가와 데이터 쪽에서 실무적 가치가 커 보인다.
벤치마크를 더 추가하는 대신 어떤 벤치마크가 이미 같은 능력을 측정하는지 feature overlap으로 먼저 걸러내고, 안전 데이터를 더 많이 쌓는 대신 어떤 feature가 여전히 비어 있는지 보고 합성 타깃을 정하는 방식은 꽤 운영 친화적이다.
이는 “모델을 더 크게 만든다”와 별개로, 기존 모델을 더 싸게 진단하고 더 정교하게 개선하는 도구가 될 수 있다.
물론 한계도 분명하다.
첫째, 공개 수치 상당수는 Qwen 보고서의 자체 실험에 기반하므로 외부 독립 재현이 더 필요하다.
둘째, sparse feature가 실제로 얼마나 monosemantic한지, 혹은 다른 모델 패밀리로 얼마나 잘 이전되는지는 여전히 열린 문제다.
셋째, steering과 training intervention은 유용하지만, 잘못 쓰면 능력 저하나 예상치 못한 부작용을 부를 수도 있다.
즉 Qwen-Scope는 완성된 제어 패널이라기보다, 내부 표현을 다루는 실전형 실험 인터페이스에 더 가깝다.
그럼에도 방향성은 명확하다.
오픈모델 경쟁이 단순 벤치마크 점수에서 에이전트성·지속적 개선·안전 운영으로 이동할수록, SAE 같은 내부 표현 도구는 연구용 사치품이 아니라 개발 생산성 도구가 될 가능성이 높다.
Qwen-Scope는 바로 그 전환을 가장 노골적으로 보여 주는 사례 중 하나다.