에이전트 시스템이 복잡한 문제를 풀기 시작하면 병목은 단순히 “모델 하나가 더 똑똑한가”에 머물지 않는다.
Planner, Critic, Solver, Tool-Caller 같은 역할을 나눠 협업시키더라도, 그 협업이 결국 긴 텍스트를 주고받는 방식에 머무르면 지연과 토큰 비용이 빠르게 커진다.
한 에이전트가 문장을 다 뱉을 때까지 다음 에이전트가 기다려야 하고, 시스템 전체를 학습하려고 해도 중간 텍스트를 거치는 경로는 gradient propagation에 불리하다.
Recursive Multi-Agent Systems는 이 문제를 꽤 공격적으로 재정의한다.
이 논문이 제안하는 RecursiveMAS는 멀티 에이전트를 단순한 메시지 패싱 구조가 아니라, 하나의 재귀적 계산 그래프로 본다.
각 에이전트는 독립된 채터가 아니라 recursive language model의 layer처럼 동작하고, 중간 협업은 텍스트 대신 latent thought를 주고받는다.
즉 “에이전트를 더 많이 붙이면 좋아지나”가 아니라, “에이전트 협업 자체를 재귀적으로 더 깊게 만들 수 있나”를 묻는 작업이다.
특히 이 작업이 흥미로운 이유는 단지 구조만 새롭기 때문이 아니다.
논문, arXiv HTML, 프로젝트 페이지, 공개 코드 저장소를 함께 보면 RecursiveMAS는 아키텍처, 학습 절차, 효율성 분석, 다양한 collaboration pattern 일반화까지 한 세트로 밀어붙인다.
공개 자료가 제시하는 수치도 비교적 분명하다.
9개 벤치마크 평균에서 강한 baseline 대비 정확도 +8.3%, end-to-end 추론 속도 1.2×–2.4× 향상, 토큰 사용량 34.6%–75.6% 감소를 주장한다.
무엇을 해결하려는가
기존 multi-agent system은 흔히 역할 분업과 토론 구조를 통해 단일 모델보다 더 높은 성능을 노린다.
하지만 공개 논문이 반복해서 지적하듯, 이런 구조가 곧바로 효율적인 것은 아니다.
에이전트 간 상호작용이 텍스트 기반이면 중간 decoding 비용이 계속 발생하고, 협업 라운드가 깊어질수록 latency와 token budget이 함께 커진다.
여기에 시스템 수준 학습을 붙이려 하면 더 까다롭다.
텍스트로 외부화된 중간 상태는 분절적이고, 여러 라운드를 거친 shared credit assignment가 약해지기 쉽다.
RecursiveMAS는 이 문제를 “에이전트 간 대화 품질을 더 좋게 만든다”가 아니라 “대화 자체를 latent-space recurrence로 바꾼다”로 푼다.
핵심 문제 설정은 두 가지다.
첫째, 에이전트 협업을 더 깊게 만들면서도 decoding bottleneck을 줄일 수 있는가.
둘째, 여러 에이전트를 시스템 전체로 묶어 재귀적으로 학습할 때, 중간 상호작용 경로가 안정적인 gradient flow를 유지할 수 있는가.
이 논문은 둘 다 latent-space recursion이 더 낫다고 본다.
핵심 아이디어 / 구조 / 동작 방식
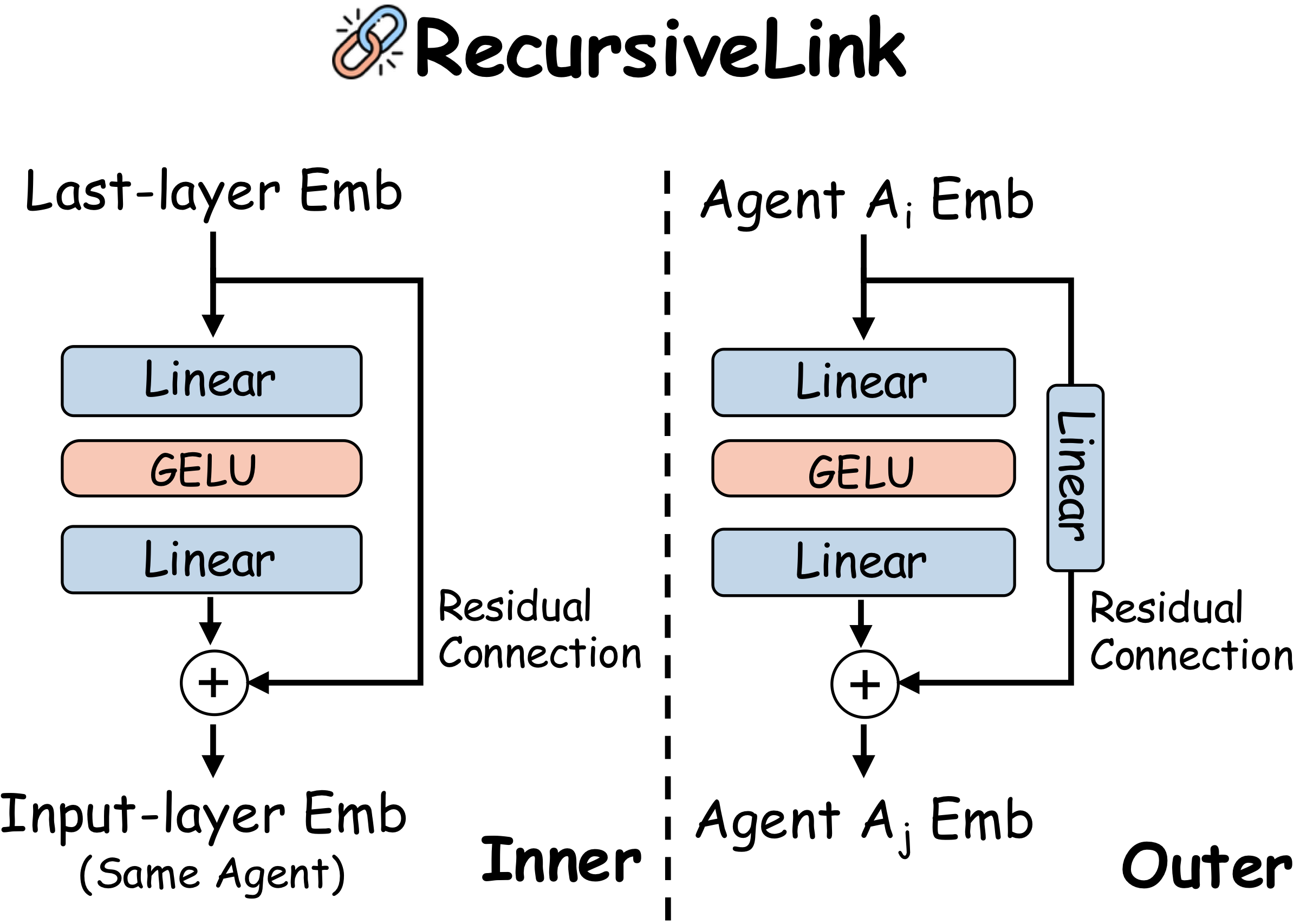
RecursiveMAS의 중심에는 RecursiveLink가 있다.
논문 기준으로 이것은 두 개의 linear layer와 residual branch로 이루어진 경량 모듈이다.
역할은 크게 둘이다.
하나는 각 에이전트 내부에서 마지막 hidden state를 다음 입력 embedding 공간으로 다시 접어 넣는 inner link, 다른 하나는 서로 hidden size가 다를 수 있는 이종 에이전트 사이에서 latent state를 넘겨주는 outer link다.
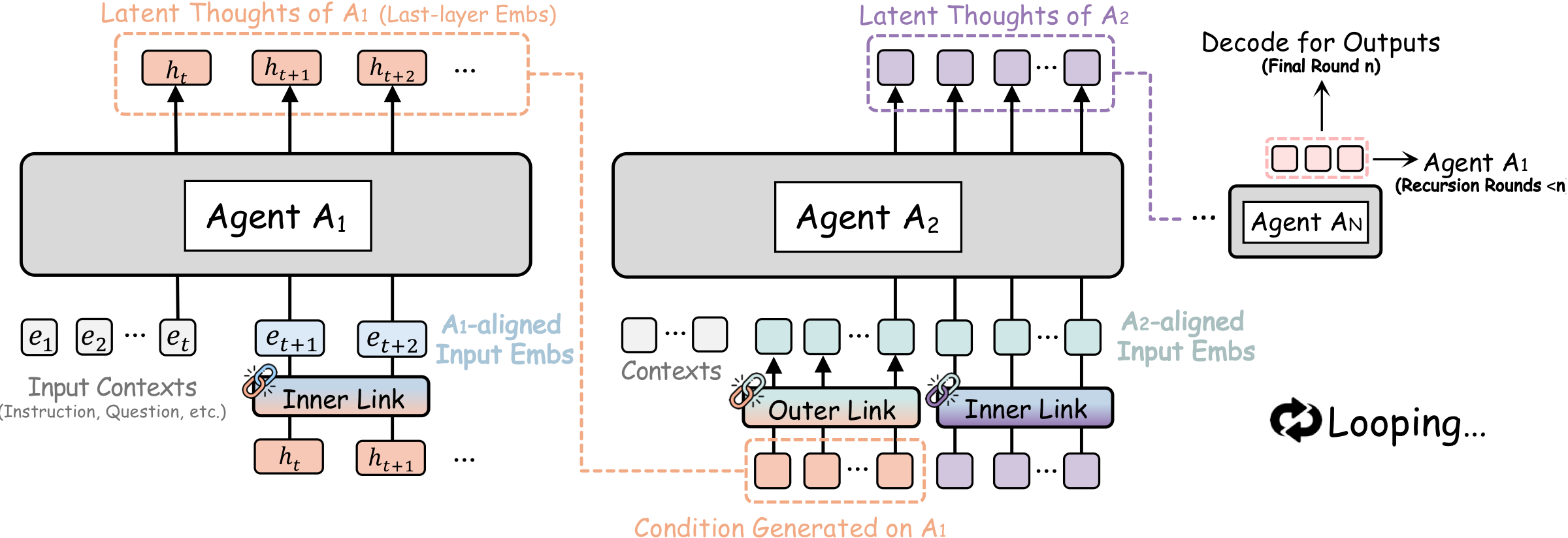
이 구조 덕분에 에이전트는 중간 단계마다 텍스트를 출력하지 않아도 된다.
한 에이전트는 자신의 latent thought를 몇 step 생성한 뒤, 그 상태를 다음 에이전트로 넘긴다.
마지막 에이전트가 만든 latent output은 다시 첫 번째 에이전트로 피드백되어 루프를 닫는다.
최종 recursion round가 끝날 때만 마지막 에이전트가 실제 텍스트를 decoding한다.
논문과 프로젝트 페이지를 종합하면 구조는 다음처럼 읽는 편이 자연스럽다.
| 레이어 | 공개 자료에서 확인되는 구성요소 | 역할 |
|---|---|---|
| Agent layer | Planner, Critic, Solver, Reflector, Tool-Caller 등 역할별 LLM | 개별 전문성 또는 협업 역할 담당 |
| Inner RecursiveLink | 2-layer residual projection | 에이전트 내부 latent thought를 다음 latent step으로 연결 |
| Outer RecursiveLink | hidden-size bridge가 추가된 residual projection | 이종 에이전트 사이 latent state 전달 |
| Recursion loop | 마지막 에이전트 출력이 첫 에이전트로 되돌아감 | 여러 round에 걸친 iterative refinement |
| Final decode | 최종 round에서만 텍스트 생성 | 중간 token emission 최소화 |
학습 절차도 구조와 맞물린다.
프로젝트 페이지와 arXiv HTML은 two-stage inner–outer loop training을 제시한다.
먼저 inner loop에서 각 에이전트의 inner RecursiveLink를 warm-start해 latent thought generation에 맞춘다.
이후 outer loop에서는 전체 시스템을 여러 recursion round로 unroll한 뒤, 최종 textual prediction에 대한 loss를 통해 outer link들을 공동 최적화한다.
이때 base LLM 파라미터는 고정하고, RecursiveLink들만 학습한다는 점이 중요하다.
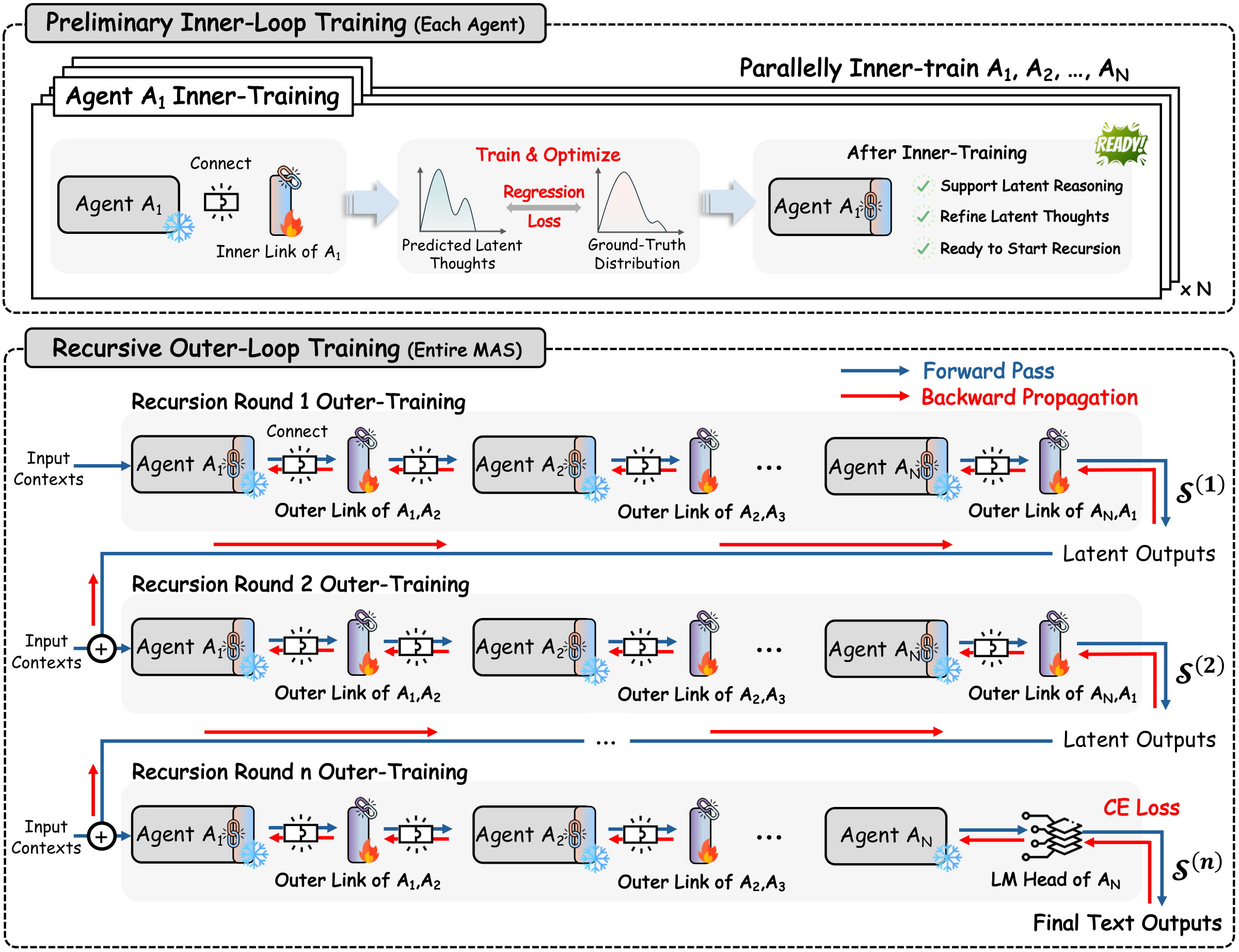
공개 프로젝트 페이지 기준 이 방식의 trainable footprint는 약 13.12M 파라미터, 즉 전체 시스템의 약 0.31% 수준으로 제시된다.
다시 말해 이 논문은 “모든 에이전트를 통째로 다시 학습한다”보다 “작은 latent adapter를 통해 시스템 레벨 recursion을 공동 최적화한다”에 가깝다.
공개된 근거에서 확인되는 점
가장 먼저 확인되는 것은 성능 claim의 범위다. arXiv 초록과 프로젝트 페이지는 RecursiveMAS를 4개 collaboration pattern, 9개 benchmark에 걸쳐 평가했다고 밝힌다.
패턴은 sequential, mixture, distillation, deliberation이고, 과제 범위는 수학, 과학, 의료, 검색, 코드 생성까지 포함한다.
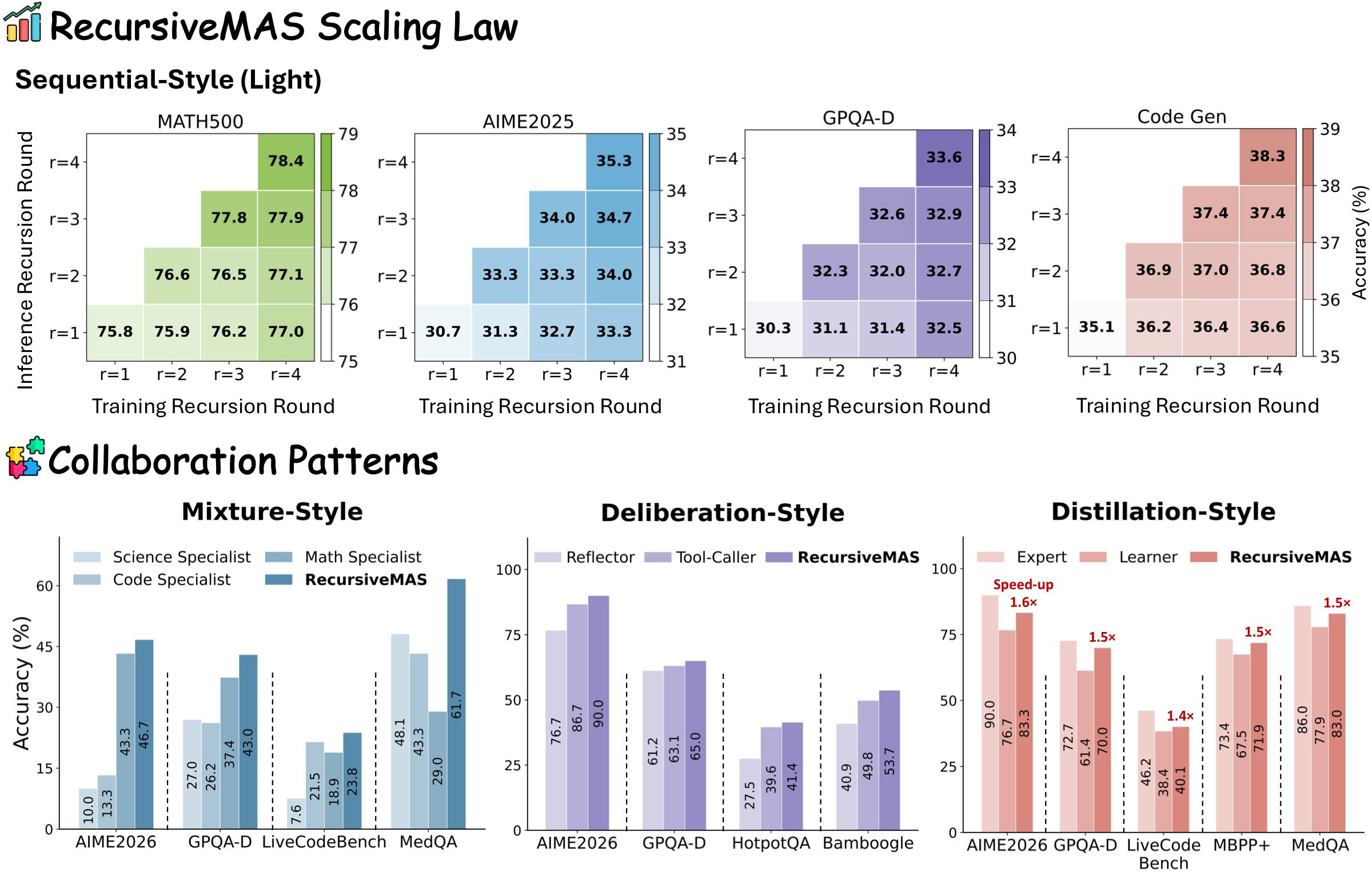
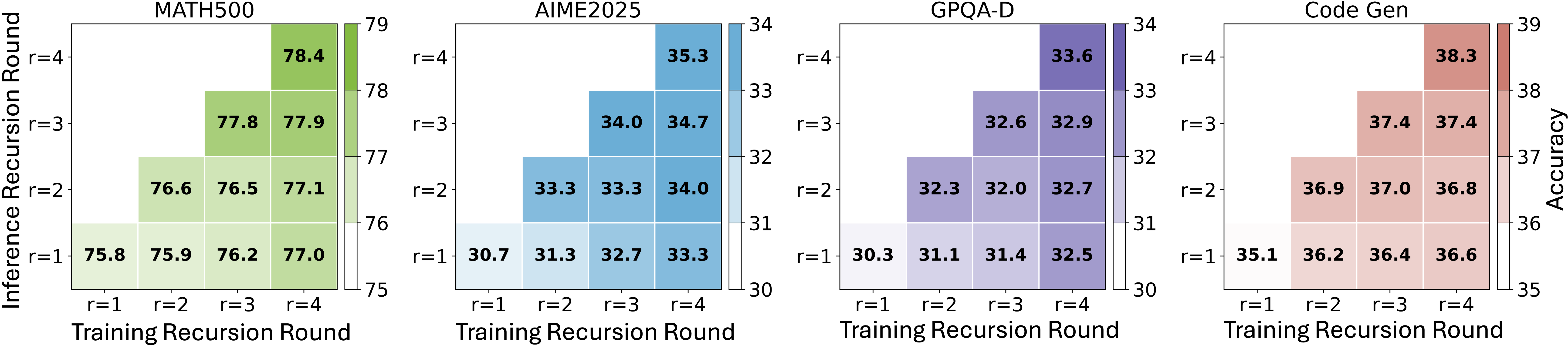
프로젝트 페이지의 대표 표에서 r = 3 기준 RecursiveMAS는 다음 수치를 보인다.
| Method | MATH500 | AIME 2025 | AIME 2026 | GPQA-D | LiveCodeBench | MedQA |
|---|---|---|---|---|---|---|
| Single Agent (LoRA) | 83.1 | 70.0 | 73.3 | 62.0 | 37.4 | 76.1 |
| Single Agent (Full-SFT) | 83.2 | 73.3 | 76.7 | 62.8 | 38.6 | 77.0 |
| MoA | 79.8 | 60.0 | 63.3 | 47.6 | 27.0 | 57.5 |
| TextGrad | 84.9 | 73.3 | 76.7 | 62.5 | 39.8 | 77.2 |
| LoopLM | 84.6 | 66.7 | 63.3 | 48.1 | 24.9 | 56.4 |
| Recursive-TextMAS | 85.8 | 73.3 | 73.3 | 61.6 | 38.7 | 77.0 |
| RecursiveMAS | 88.0 | 86.7 | 86.7 | 66.2 | 42.9 | 79.3 |
이 표를 그대로 받아들이더라도 해석 포인트는 단순 승패보다 더 구조적이다.
RecursiveMAS는 single-agent SFT뿐 아니라 텍스트 기반 recursive MAS보다도 높은 수치를 보이며, 특히 AIME 2025/2026 같은 logic-dense reasoning task에서 격차가 크다.
프로젝트 페이지는 이를 strongest baseline 대비 평균 +8.3% accuracy gain으로 요약한다.
또 하나 중요한 근거는 recursion depth가 깊어질수록 text-based MAS와의 격차가 벌어진다는 점이다.
프로젝트 페이지의 scaling 결과를 보면 sequential setting에서 r=1 → r=2 → r=3으로 갈수록 RecursiveMAS는 정확도를 유지하며 끌어올리지만, Recursive-TextMAS는 plateau 혹은 regression을 보인다.
효율성 쪽 공개 근거도 비교적 선명하다.
프로젝트 페이지와 arXiv 초록 모두 end-to-end speedup과 token reduction을 전면에 둔다.
| 재귀 깊이 | RecursiveMAS 속도 향상 vs Recursive-TextMAS | 토큰 사용량 감소 |
|---|---|---|
| r = 1 | 1.2× | 34.6% |
| r = 2 | 1.9× | 65.5% |
| r = 3 | 2.4× | 75.6% |
왜 이런 차이가 나는지에 대한 이론적 주장도 붙어 있다. arXiv HTML은 text-based recursive MAS가 per-step vocabulary projection 비용을 계속 치르는 반면, RecursiveMAS는 이를 latent-space transformation으로 대체한다고 설명한다.
복잡도 식을 보면 핵심 비교축은 m|V|d_h 대 md_h^2다.
즉 hidden size가 vocabulary size보다 훨씬 작은 현실 설정에서 latent recursion이 구조적으로 더 싸다는 주장이다.
여기에 더해, 텍스트 기반 recursive SFT는 confident token prediction 구간에서 vanishing gradient를 겪기 쉽지만 RecursiveLink는 더 안정적인 gradient norm을 유지한다는 theorem도 제시한다.
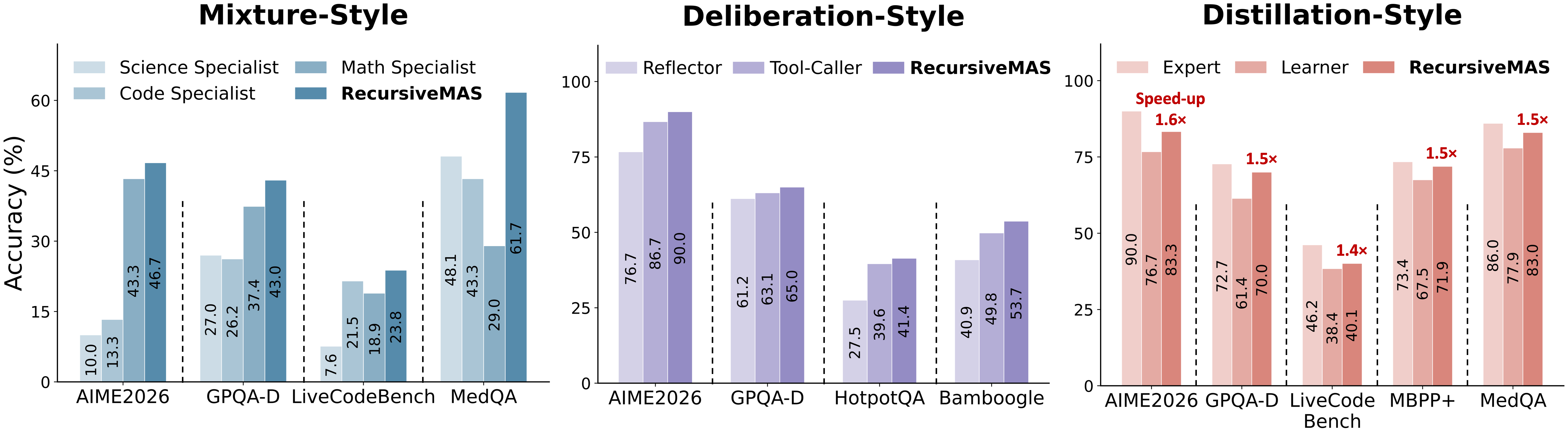
프로젝트 페이지는 generalization claim도 함께 건다. mixture, distillation, deliberation style에서도 strongest standalone agent 대비 각각 +6.2%, +8.0%, +4.8% 개선을 제시한다.
Distillation style에서는 작은 learner를 끌어올리면서도 expert보다 약 1.5× 빠른 추론을 유지한다고 적는다.
구현 공개 범위도 refresh할 만하다.
2026-05-14 기준 GitHub API에서 RecursiveMAS/RecursiveMAS는 stars 354, forks 48, open issues 6인 공식 구현 저장소로 확인된다.
여전히 GitHub release/tag는 없고 /releases/latest는 404를 반환하며, 루트에는 별도 LICENSE 파일이 보이지 않는다.
반면 Hugging Face 조직에는 arXiv ID로 태깅된 공개 모델 저장소 19개가 있고, Sequential/Mixture/Deliberation/Distillation 구성용 agent checkpoint와 outerlink checkpoint가 MIT license 태그로 올라와 있다.
README의 roadmap도 inference demo와 checkpoint 공개는 완료했지만, complete inference pipeline, training data/implementation details, 추가 모델 패밀리/협업 패턴은 체크박스 상태로 남겨둔다.
따라서 핵심 실행 surface는 열렸지만, 안정 버전으로 패키징된 production framework라기보다 빠르게 공개 중인 연구 코드/체크포인트 묶음에 가깝다.
실무 관점에서의 해석
내가 보기엔 RecursiveMAS의 진짜 메시지는 “멀티 에이전트 수를 늘리자”가 아니다.
더 중요한 것은 에이전트 협업을 텍스트 프로토콜이 아니라 differentiable latent protocol로 바꾸자는 제안이다.
지금까지 많은 MAS는 역할 분담과 prompting 설계에 집중했지만, 중간 협업 자체는 결국 자연어 메시지라는 비싼 인터페이스 위에서 이뤄졌다.
RecursiveMAS는 바로 그 인터페이스를 학습 가능한 latent transport layer로 치환하려 한다.
이 관점은 두 가지 점에서 의미가 있다.
첫째, 에이전트 연구를 orchestration 문제에서 system-level computation design 문제로 끌어올린다.
Planner와 Solver를 어떻게 배치할지뿐 아니라, 그 사이를 어떤 representation으로 연결할지가 핵심 설계 변수가 된다.
둘째, 작은 모듈만 학습하면서 전체 협업을 개선한다는 점에서, full fine-tuning보다 더 가벼운 시스템 최적화 경로를 제시한다.
물론 한계도 분명하다.
공개 자료가 보여주는 주요 실험은 잘 설계된 benchmark 환경에서의 성능 비교이며, 실제 production agent처럼 장기 메모리, 외부 API 실패, 비정형 web interaction, safety constraint, long-horizon task recovery까지 포함하는 운영 환경 일반화는 아직 별도 검증이 필요하다.
GitHub 저장소도 활발한 논문 코드에 가깝고, 릴리스 태그나 안정 버전 신호는 아직 없다.
또한 latent-space 협업은 효율적이지만, 중간 reasoning을 사람이 직접 검사하기 어려워지는 trade-off도 생긴다.
그럼에도 RecursiveMAS는 방향성이 강하다.
앞으로 에이전트 시스템이 계속 커진다면, 경쟁력은 단순히 더 강한 generalist 하나를 붙이는 데서 나오지 않을 수 있다.
오히려 여러 에이전트가 어떤 표현 공간에서, 얼마나 깊게, 어떤 학습 신호로 상호작용하느냐가 더 중요해질 수 있다.
그런 의미에서 이 논문은 멀티 에이전트를 “대화하는 모델 집합”이 아니라 “재귀적으로 최적화되는 하나의 계산체”로 다시 본다.