멀티모달 모델은 한동안 두 개의 스택으로 발전했다.
이미지를 이해할 때는 CLIP이나 SigLIP 계열의 비전 인코더가 이미지를 의미 벡터로 압축하고, 이미지를 생성할 때는 VAE나 latent diffusion 경로가 픽셀을 별도의 잠재 공간으로 보낸다.
이 방식은 강력하지만, 이해용 표현과 생성용 표현이 분리된다.
결국 “이미지를 읽는 모델”과 “이미지를 만드는 모델”을 한 시스템 안에서 이어 붙이는 문제가 남는다.
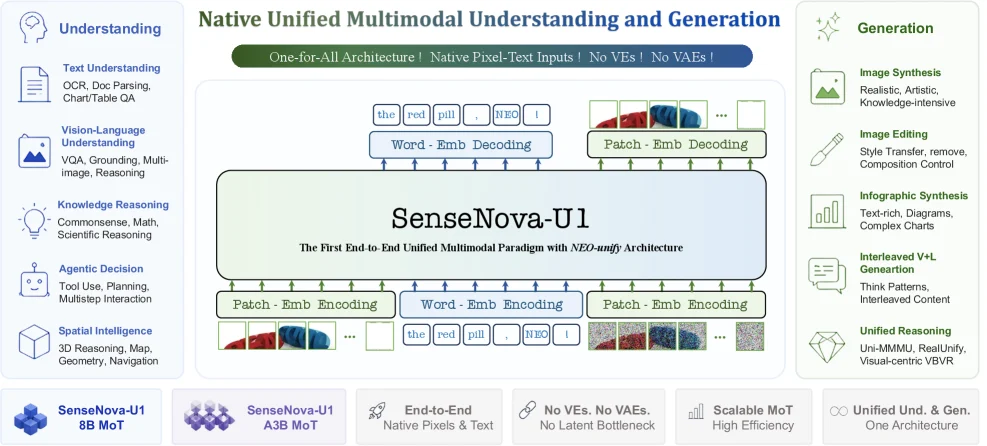
SenseNova-U1은 이 분리를 정면으로 줄이려는 공개 릴리스다. arXiv 기술보고서는 SenseNova-U1을 NEO-unify 기반의 native unified multimodal paradigm으로 설명한다.
핵심은 비전 인코더(VE)와 VAE를 쓰지 않고, 픽셀과 단어를 가벼운 patch interface로 같은 transformer 계열 구조에 넣은 뒤, 언어에는 autoregressive cross-entropy를, 시각 생성에는 pixel-space flow matching을 적용한다는 것이다.
중요한 점은 이것이 단순한 “VLM + 이미지 생성 API” 조합이 아니라는 데 있다.
공개 자료 기준 SenseNova-U1은 8B-MoT와 A3B-MoT 두 계열, SFT/최종 모델, 8-step preview, infographic 특화 모델, LoRA, GitHub 코드, Hugging Face 컬렉션, 데모 페이지까지 함께 공개한 릴리스다.
따라서 논문 아이디어만이 아니라, 통합 멀티모달 모델을 실제 공개 패키지로 어떻게 내놓는지까지 볼 수 있는 사례다.
무엇을 해결하려는가
SenseNova-U1이 겨냥하는 병목은 “모델이 이미지를 이해할 수 있는가”가 아니다.
더 정확히는, 이해와 생성이 같은 시각 세계를 공유할 수 있는가다.
기존 VLM은 이미지 이해에는 강하지만, 생성은 별도 diffusion 모델에 맡기는 경우가 많다.
반대로 이미지 생성 모델은 시각적으로 좋은 결과를 만들 수 있어도, 복잡한 질문, 도구 사용, 공간 추론, 긴 문맥의 텍스트-이미지 인터리브 작업에서는 LLM/VLM의 추론 경로와 다시 연결되어야 한다.
이 분리는 특히 텍스트가 많은 이미지에서 커진다.
인포그래픽, 발표 슬라이드, 포스터, 차트, 설명형 만화, 이력서 같은 산출물은 “예쁜 그림”만으로는 부족하다.
텍스트가 정확해야 하고, 레이아웃이 읽혀야 하며, 모델이 지시문 안의 구조적 제약을 이해해야 한다.
이해 모델과 생성 모델이 서로 다른 표현 공간을 쓰면 이런 작업은 파이프라인이 길어지고 오류 지점도 늘어난다.
SenseNova-U1은 이 문제를 “모듈 연결”이 아니라 “모델 내부 표현”의 문제로 본다.
보고서의 표현을 빌리면, 목표는 modality-specific system들을 연결하는 것이 아니라, 픽셀과 단어가 같은 네이티브 기판에서 함께 진화하는 구조를 만드는 것이다.
핵심 아이디어 / 구조 / 동작 방식
구조의 첫 번째 축은 near-lossless visual interface다.
SenseNova-U1은 이미지를 pretrained vision encoder나 VAE latent로 보내지 않는다.
두 개의 convolution layer와 2D sinusoidal positional encoding으로 이미지를 visual token sequence로 만들고, 각 토큰은 32×32 이미지 패치에 대응한다.
생성 쪽에서도 deep VAE decoder 대신 MLP 계열 patch decoding layer가 픽셀 패치를 직접 예측한다.
즉 시각 입력과 출력이 모두 비교적 얕은 interface를 통과해 transformer 본체와 직접 연결된다.
두 번째 축은 **Native Mixture-of-Transformers(MoT)**다.
논문은 understanding stream과 generation stream을 같은 monolithic framework 안에 두되, token type에 따라 projection, normalization, feed-forward block을 분리한다.
텍스트 토큰은 causal attention을 따르고, 같은 이미지 블록 안의 이미지 토큰은 bidirectional attention을 쓰며, noise token은 clean input에 접근할 수 있지만 clean token이 noise token을 보지는 못하게 attention pattern을 제어한다.
이 설계는 이해와 생성을 한 sequence 안에서 다루면서도, 서로 다른 학습 목표가 직접 충돌하지 않도록 완충 장치를 둔 형태로 읽힌다.
세 번째 축은 학습 목표다.
언어와 이해는 다음 토큰 예측으로 최적화하고, 이미지 생성은 pixel-space flow matching으로 최적화한다.
이후 training recipe는 understanding warmup, generation pre-training, unified mid-training, unified SFT, 그리고 text-to-image post-training으로 이어진다. post-training에서는 Flow-GRPO 계열 RL과 Distribution Matching Distillation을 사용해 텍스트 렌더링, 스타일 추종, aesthetic reward, few-step 생성 효율을 다룬다.
모델 구성은 다음처럼 요약된다.
| 모델 | 공개 자료의 구성 | 해석 |
|---|---|---|
| SenseNova-U1-8B-MoT | understanding / generation 각각 8.2B, 42 layers, dense MoT | 구조가 비교적 단순하고 생성 벤치마크에서 자주 강한 기준선 |
| SenseNova-U1-A3B-MoT | understanding 30.0B, generation 8.2B, 48 layers, stream-wise MoE, token당 8 experts 활성화 | 총 파라미터는 더 크지만 inference active 규모를 줄이는 MoE 계열 |
| HF 8B 계열 | API 기준 약 17.55B parameters, 8B-MoT / SFT / Infographic / 8-step preview / LoRA 공개 | 논문 표의 understanding+generation 구성요소가 Hub에서는 합산되어 보임 |
| HF A3B 계열 | API 기준 약 38.74B parameters, A3B-MoT / A3B-MoT-SFT 공개 | 공개 checkpoint는 있으나 custom code와 대형 파일 구성을 전제 |
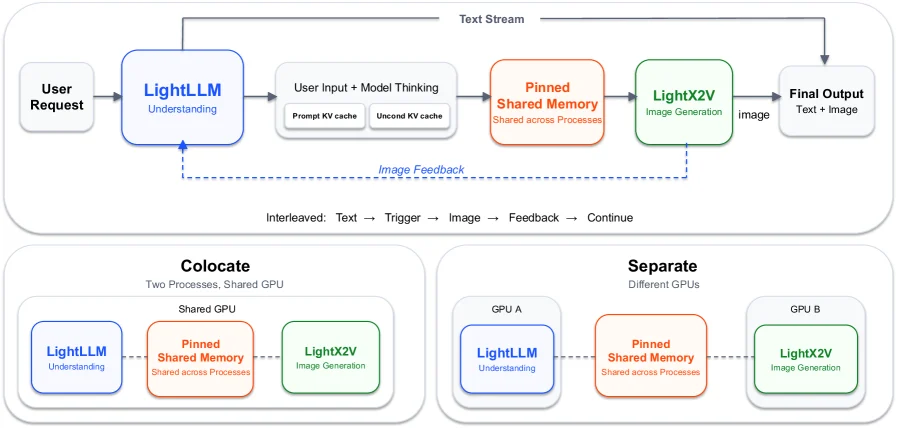
흥미로운 점은 모델은 “unified”를 지향하지만, 서빙은 무작정 단일 엔진으로 밀어붙이지 않는다는 것이다.
보고서는 이해 경로와 이미지 생성 경로의 runtime 특성이 다르기 때문에, LightLLM이 멀티모달 이해·텍스트 스트리밍·제어 흐름을 맡고, LightX2V가 이미지 생성을 맡는 disaggregated inference architecture를 제시한다.
두 엔진은 pinned shared memory로 generation state를 주고받는다.
즉 연구 명제는 내부 표현의 통합이고, 운영 명제는 워크로드별 엔진 분리다.
데이터 구성도 같은 방향을 따른다.
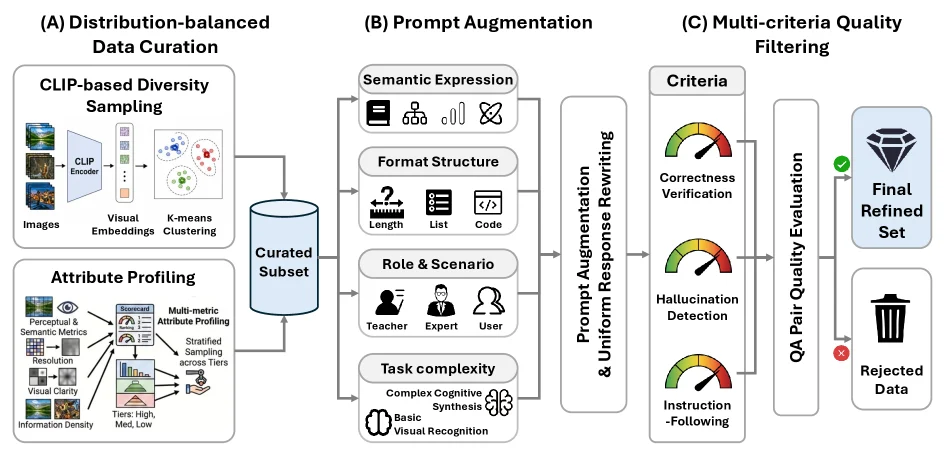
이해 corpus는 10개 vertical domain에서 distribution-balanced sampling, prompt augmentation, multi-criteria filtering을 거친다.
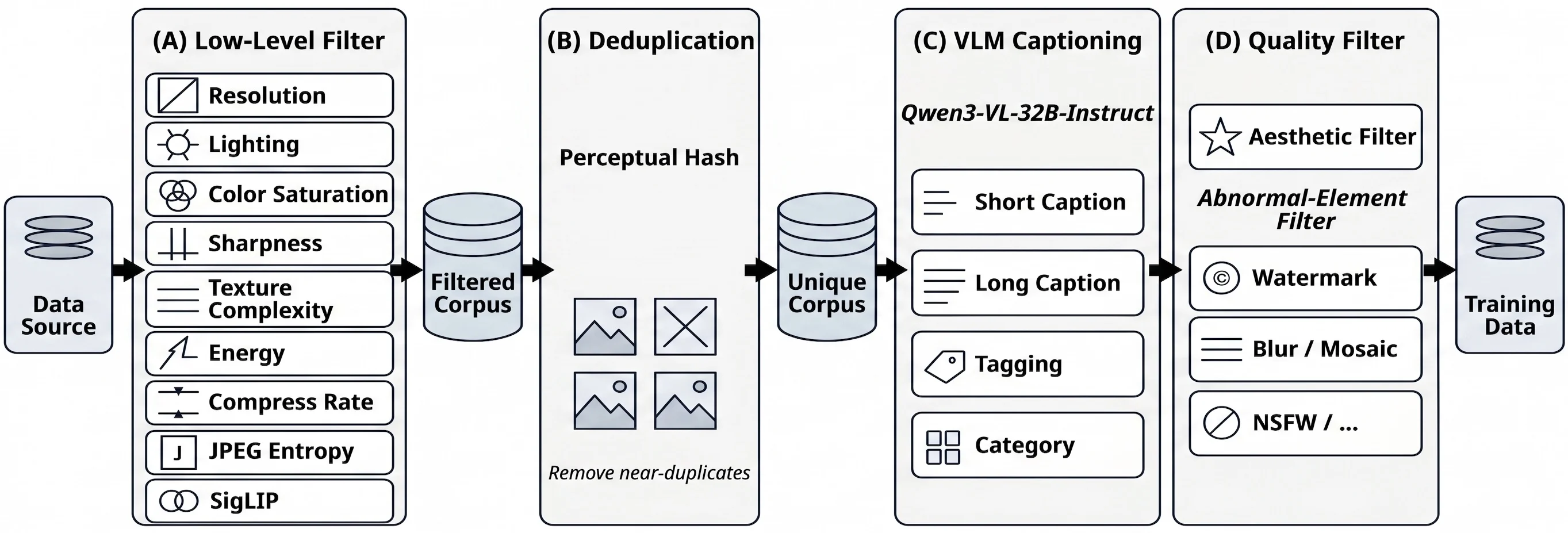
생성 corpus는 자연 이미지, 디자인, 인물, synthetic 데이터를 text-to-image와 image editing에 맞게 수집하고, low-level filtering, deduplication, VLM captioning, quality filtering을 적용한다.
특히 SFT mixture에는 spatial intelligence, general multimodal understanding, reasoning, OCR/document analysis, function calling, long-context conversation, code, multi-turn dialogue가 섞인다.
공개된 근거에서 확인되는 점
이 릴리스의 가장 강한 근거는 성능표가 “이해”와 “생성”을 모두 포함한다는 점이다.
SenseNova-U1-8B-Think는 MMMU 74.78, MMMU-Pro 67.69, MathVista mini 84.20, MathVision 75.82를 제시한다.
같은 표에서 Qwen3VL-8B-Think는 각각 74.10, 60.40, 81.40, 62.70이다.
특히 MMMU-Pro와 MathVision에서 8B급 비교가 꽤 뚜렷하다.
공간 지능 쪽에서도 VSI-Bench 62.66, ViewSpatial 56.19, MindCube-Tiny 62.01, 3DSR-Bench 64.88이 제시되어, 단순 이미지 캡션 모델이 아니라 spatial reasoning까지 평가하려는 의도가 보인다.
다만 모든 지표에서 절대 우위라고 읽으면 안 된다.
예를 들어 OCRBench-v2나 InfoVQA 일부 항목에서는 Qwen3.5 계열이 더 높고, A3B variant도 모든 생성 지표에서 8B를 이기지는 않는다.
보고서 자체도 A3B의 일부 post-training이 더 개선될 여지를 남긴다고 적는다.
따라서 올바른 해석은 “모든 벤치마크를 이긴 모델”이 아니라, encoder-free native 구조가 이해 성능을 크게 희생하지 않으면서 생성까지 끌고 간 사례에 가깝다.
생성 쪽에서는 텍스트와 구조화 이미지가 핵심이다.
GenEval에서 SenseNova-U1 8B와 8BA3B는 모두 overall 0.91을 기록해 Qwen-Image 0.87, BAGEL 0.82보다 높게 제시된다.
DPG-Bench에서는 A3B가 overall 88.14, 8B가 87.78로 Qwen-Image 88.32와 거의 같은 범위다.
LongText-Bench에서는 8B가 EN 0.979, ZH 0.962를 기록하고, CVTG-2K에서는 average 0.940으로 text-region rendering 쪽 강점을 보인다.

복잡한 인포그래픽과 상업용 visual content에서도 공개 표는 의미가 있다.
IGenBench에서는 SenseNova-U1 8B가 open-source 모델 중 가장 높은 Q-ACC 0.51을 제시하고, BizGenEval hard/easy 평균은 39.7 / 61.7로 공개 모델 중 가장 높게 보고된다.
하지만 여기서도 닫힌 모델과의 격차는 크다.
예를 들어 BizGenEval에서 GPT-Image-2는 평균 82.1 / 92.5를 제시한다.
즉 SenseNova-U1은 open-source text-rich generation의 기준선을 크게 끌어올리지만, 전문 문서형 이미지 생성이 완전히 해결됐다고 보기는 어렵다.
편집은 더 보수적으로 봐야 한다.
ImgEdit overall에서 SenseNova-U1 8B와 A3B는 각각 3.90, 3.91로, Qwen-Image-Edit-2511의 4.51보다 낮다.
반면 GEdit-Bench에서는 8B가 G_SC 8.27, G_PQ 7.49, G_O 7.47로 꽤 경쟁력 있는 편이고, reasoning-centric editing인 RISEBench에서는 CoT를 켠 A3B-SFT가 overall 30.0으로 공개 비교군 중 가장 강하게 제시된다.
결론적으로 일반 편집에서는 전문 편집 모델이 여전히 강하고, SenseNova-U1의 차별점은 “이해와 추론을 거친 편집”에서 더 잘 드러난다.

공개 배포 표면은 꽤 넓다.
Hugging Face 컬렉션은 gated가 아니며, 8B-MoT, 8B-MoT-SFT, 8B-MoT-Infographic, 8B-MoT-LoRAs, A3B-MoT-SFT, A3B-MoT, 8step-preview와 논문 항목을 포함한다.
현재 API 기준 8B-MoT는 downloads 14,508, likes 265이고, A3B-MoT는 downloads 188, likes 13이다.
태그에는 Apache-2.0 license, custom_code, any-to-any, text-to-image, image-to-text, image-editing, interleaved-generation이 붙어 있다.
GitHub 쪽도 활발하다.
OpenSenseNova/SenseNova-U1 저장소는 2026년 4월 17일 생성됐고, 현재 API 기준 stars 2,082, forks 135, open issues 18, license Apache-2.0이다. top-level tree에는 apps, docs, evaluation, examples, scripts, src가 있으며 README는 inference code와 weights 공개를 안내한다.
다만 /releases/latest는 404이고, 태그는 comfyui-v0.1.4, comfyui-v0.1.3처럼 ComfyUI 관련 태그 중심이다.
README의 ToDo에도 training code는 아직 미완료로 남아 있다.
즉 가중치와 추론·데모 surface는 공개되어 있지만, 전체 학습 재현 패키지까지 열린 상태는 아니다.
| 표면 | 확인되는 내용 | 실무적 의미 |
|---|---|---|
| arXiv / HF Papers | arXiv:2605.12500v1, NEO-unify 기반 구조·학습·벤치마크 상세 | 아키텍처와 성능 해석의 1차 근거 |
| 공식 데모 | unify.light-ai.top 데모 링크 |
모델이 단순 논문이 아니라 체험 surface를 가짐 |
| Hugging Face collection | 8B/A3B/SFT/Infographic/8-step/LoRA 모델 묶음, gated false | 공개 checkpoint bundle로 해석 가능하지만 custom code 전제 |
| GitHub | Apache-2.0, inference examples, docs/evaluation/apps 포함 | 사용·검토 경로는 있으나 full training code는 아직 ToDo |
| 서빙 구조 | LightLLM + LightX2V disaggregated runtime | unified model이라도 운영은 이해/생성 워크로드를 분리해야 함 |
실무 관점에서의 해석
SenseNova-U1의 가장 큰 의미는 “하나의 모델이 이미지도 이해하고 생성한다”는 문장을 다시 구체화했다는 점이다.
단순히 VLM 뒤에 diffusion 모델을 붙이는 방식이 아니라, 픽셀과 단어를 같은 backbone 안에서 다루고, 이해·생성·편집·인터리브 생성을 한 학습 체계로 묶는다.
특히 dense text, infographic, long-text rendering 결과는 멀티모달 모델이 단순 perception assistant를 넘어 visual document assistant가 될 수 있음을 보여준다.
이 방향은 에이전트 워크플로와도 잘 맞는다.
연구원이나 디자이너가 짧은 지시를 주면, 모델이 이를 이해하고, 필요하면 내부 reasoning을 거쳐, 텍스트가 포함된 시각 자료나 편집 결과를 만들 수 있다.
아래 VLA 예시는 아직 preliminary evidence에 가깝지만, 같은 모델 계열이 perception-generation을 넘어 action/world modeling 방향까지 확장될 수 있다는 연구 로드맵을 보여준다.

하지만 이 릴리스는 동시에 몇 가지 현실적 한계를 분명히 드러낸다.
첫째, unified architecture와 unified product는 다르다.
보고서가 직접 disaggregated inference를 제안한다는 사실은, 운영 단계에서는 이해와 생성의 GPU 메모리, batching, latency, parallelism이 여전히 다르게 최적화되어야 한다는 뜻이다.
둘째, 일반 이미지 편집에서는 Qwen-Image-Edit 계열 같은 전문 편집 모델이 더 강한 지표를 보인다.
셋째, 공개 repo는 활발하지만 full training code가 아직 ToDo로 남아 있어, 논문 전체를 외부에서 완전히 재현하기에는 부족하다.
또 하나의 해석 포인트는 8B와 A3B의 관계다.
A3B는 더 큰 MoE 계열이고 active parameter 효율을 노리지만, 생성 벤치마크에서는 8B가 더 좋은 항목이 적지 않다.
이는 unified multimodal 모델에서 “더 큰 총 파라미터”보다 데이터 mixture, RL post-training, generation branch 수렴, text rendering reward가 더 직접적으로 품질을 좌우할 수 있음을 시사한다.
실무적으로 SenseNova-U1은 지금 당장 모든 조직의 이미지 생성·편집 파이프라인을 대체할 모델이라기보다, 앞으로 오픈 멀티모달 모델이 어떤 방향으로 묶일지를 보여주는 레퍼런스에 가깝다.
특히 다음 세 가지 질문을 남긴다.
비전 인코더와 VAE 없이도 scale을 키우면 지각과 생성이 함께 좋아지는가.
텍스트가 많은 시각 문서를 실제 업무 초안 수준까지 끌어올릴 수 있는가.
그리고 내부 표현은 통합하되 운영 엔진은 분리하는 방식이 멀티모달 서빙의 기본 패턴이 될 것인가.
SenseNova-U1의 답은 아직 완성형이라기보다 강한 중간 결과다.
그렇지만 공개 checkpoint bundle, 논문 수준의 학습 세부사항, 인포그래픽·long-text generation 성능, 그리고 이해/생성 서빙 구조까지 함께 제시했다는 점에서 의미가 크다.
멀티모달 모델의 다음 경쟁은 “이미지를 볼 수 있는 LLM”과 “그림을 그리는 diffusion”의 조합을 넘어, 픽셀과 단어가 같은 내부 세계를 공유하는지로 옮겨가고 있다.