LLM에게 “이 명세를 Verilog로 작성해줘”라고 한 번 묻는 방식은 RTL 설계에서 금방 한계에 부딪힌다.
문법적으로 그럴듯한 모듈을 만드는 것과, reset convention, bit width, FSM transition, ready-valid protocol, memory behavior, simulation trace까지 통과하는 설계를 만드는 것은 다른 문제이기 때문이다.
NVIDIA Research의 Agentic Hardware Design as Repository-Level Code Evolution는 이 문제를 코드 생성이 아니라 저장소 단위의 진화 문제로 다시 잡는다.
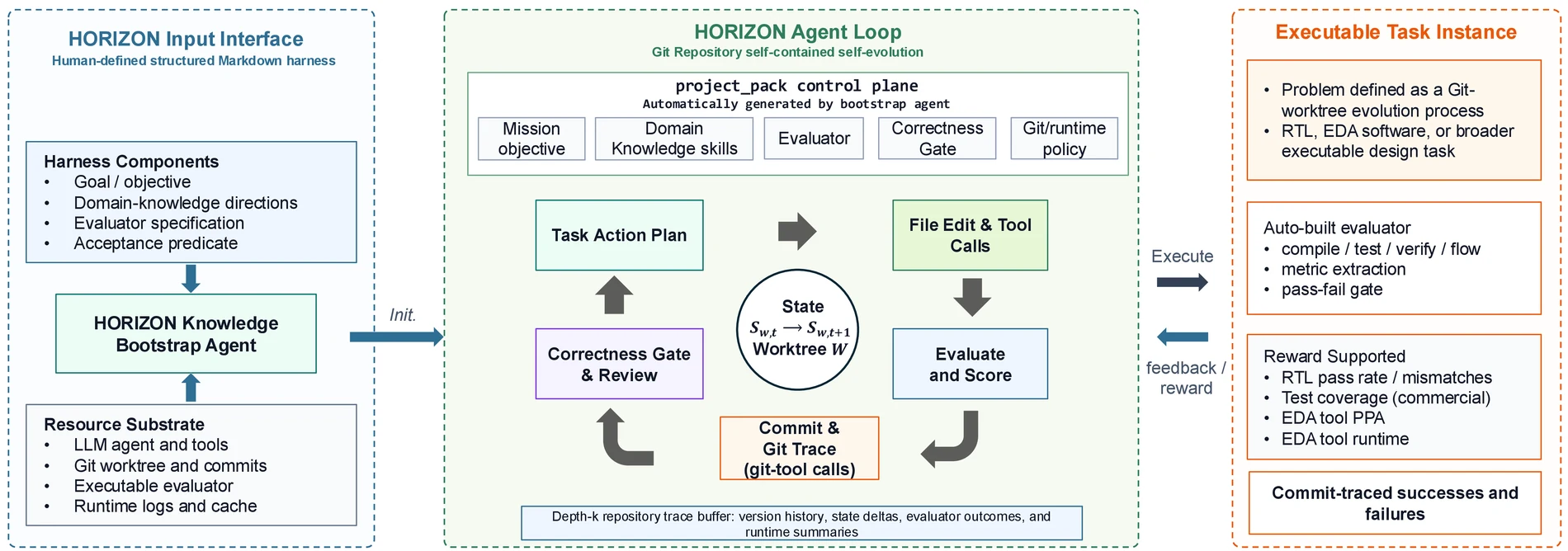
논문이 제안하는 HORIZON은 Markdown으로 적은 harness를 project pack으로 바꾸고, agent가 격리된 Git worktree 안에서 RTL과 testbench, verification artifact를 수정하고 평가하며, 통과한 상태만 commit으로 남기는 구조다.
무엇을 해결하려는가
기존 RTL LLM 연구는 크게 두 흐름으로 나뉜다.
하나는 더 나은 생성 모델과 데이터셋을 만드는 방향이다.
VeriGen, RTLCoder, ChipNeMo, ScaleRTL 같은 작업은 first-attempt generation 정확도를 끌어올린다.
다른 하나는 AutoChip, RTLFixer, VerilogCoder, MAGE, ACE-RTL처럼 compile-simulate-repair loop를 붙이는 방향이다.
HORIZON은 후자에 가깝지만 초점을 조금 다르게 둔다.
논문의 관심사는 “어떤 backbone model이 첫 시도에 RTL을 잘 쓰는가”보다, 하드웨어 설계 문제 전체를 어떤 실행 가능한 작업 공간으로 포장해야 agent가 길게 고칠 수 있는가에 있다.
그래서 핵심 단위가 prompt가 아니라 repository다.
이 framing은 AlphaEvolve, SATLUTION, ABCEvo 같은 repository-level self-evolution 계열과 닮아 있다.
다만 그 작업들이 주로 알고리즘 kernel, SAT solver, ABC logic synthesis system처럼 “엔지니어가 실행하는 소프트웨어”를 진화시켰다면, HORIZON은 엔지니어가 만들어야 하는 hardware artifact 자체를 진화 대상으로 삼는다.
핵심 아이디어 / 구조 / 동작 방식
HORIZON의 시작 입력은 구조화된 Markdown harness다.
이 harness에는 목표, 도메인 지식, repository context, evaluator, acceptance predicate, artifact policy 같은 정보가 들어갈 수 있다.
Bootstrap agent는 이를 project pack으로 컴파일한다.
| 구성 요소 | HORIZON에서의 역할 | 실무적 의미 |
|---|---|---|
π_agent |
agent policy prompt와 tool contract | agent가 어떤 도구와 규칙으로 움직일지 고정 |
E_p |
executable evaluator / harness | compile, simulation, coverage, assertion check 등 실행 피드백 제공 |
A_p |
acceptance predicate | 어떤 결과를 “통과”로 볼지 결정 |
Γ_p |
version-control / artifact policy | diff, commit, log, note 등 Git 운영 규칙 정의 |
Ω_p |
domain skills와 repository instructions | RTL convention, failure mode, tool convention 같은 도메인 지식 주입 |
이후 agent loop는 격리된 Git worktree에서 반복된다.
한 cycle에서 agent는 파일을 수정하고, evaluator를 실행하고, 실패 로그를 해석하고, 다시 수정한다. acceptance predicate가 통과하면 그 상태는 commit으로 남고, 실패하면 reject log로 기록된다.
논문은 Git을 단순한 bookkeeping이 아니라 trace substrate로 본다. diff는 상태 변화를 보여주고, commit은 accepted checkpoint가 되며, log와 note는 evaluator evidence를 붙이는 공간이 된다.
이 구조의 장점은 agent의 탐색 과정을 재현 가능한 history로 남긴다는 점이다.
“마지막 답만 맞았다”가 아니라 어떤 중간 시도가 실패했고, 어떤 수정이 통과했고, 어떤 evaluator evidence가 있었는지를 repository history로 복기할 수 있다.
논문은 이 trace를 나중에 policy analysis, reward modeling, curriculum construction, offline agent-RL training에 활용할 수 있는 경험 버퍼로 본다.
공개된 근거에서 확인되는 점
논문은 HORIZON을 ChipBench, RTLLM-2.0, Verilog-Eval v2, 그리고 CVDP의 9개 코드·검증 생성 category에서 평가했다.
모든 실험은 단일 agent mode로 진행되며, backbone은 GPT-5.3으로 고정했다고 적는다.
CID 012–014는 commercial simulator가 필요한 category로 표시되어 있고, 나머지는 open-source EDA flow로 평가된다.
요약하면 final pass rate는 모든 suite에서 100%다.
다만 이 숫자만 보면 중요한 차이를 놓친다.
RTLLM-2.0과 Verilog-Eval v2는 2 iteration 안에 끝나지만, CVDP의 일부 category는 훨씬 긴 수리 과정을 요구한다.
| Suite / category | 평가 초점 | Iter. 0 pass | 수렴 iteration | HORIZON final |
|---|---|---|---|---|
| ChipBench | mixed RTL generation | 20.0% | 5 | 100.0% |
| RTLLM-2.0 | natural-language spec to RTL | 78.0% | 2 | 100.0% |
| Verilog-Eval v2 | HDLBits-style Verilog generation | 86.2% | 2 | 100.0% |
| CVDP CID 002 | RTL code completion | 3.2% | 82 | 100.0% |
| CVDP CID 003 | natural-language spec to RTL | 19.2% | 24 | 100.0% |
| CVDP CID 004 | RTL code modification | 10.9% | 36 | 100.0% |
| CVDP CID 012 | test-plan to stimulus generation | 47.8% | 32 | 100.0% |
| CVDP CID 013 | test-plan to checker generation | 3.8% | 19 | 100.0% |
| CVDP CID 014 | test-plan to assertion generation | 79.1% | 1 | 100.0% |
| CVDP CID 016 | debugging and bug fixing | 25.7% | 13 | 100.0% |
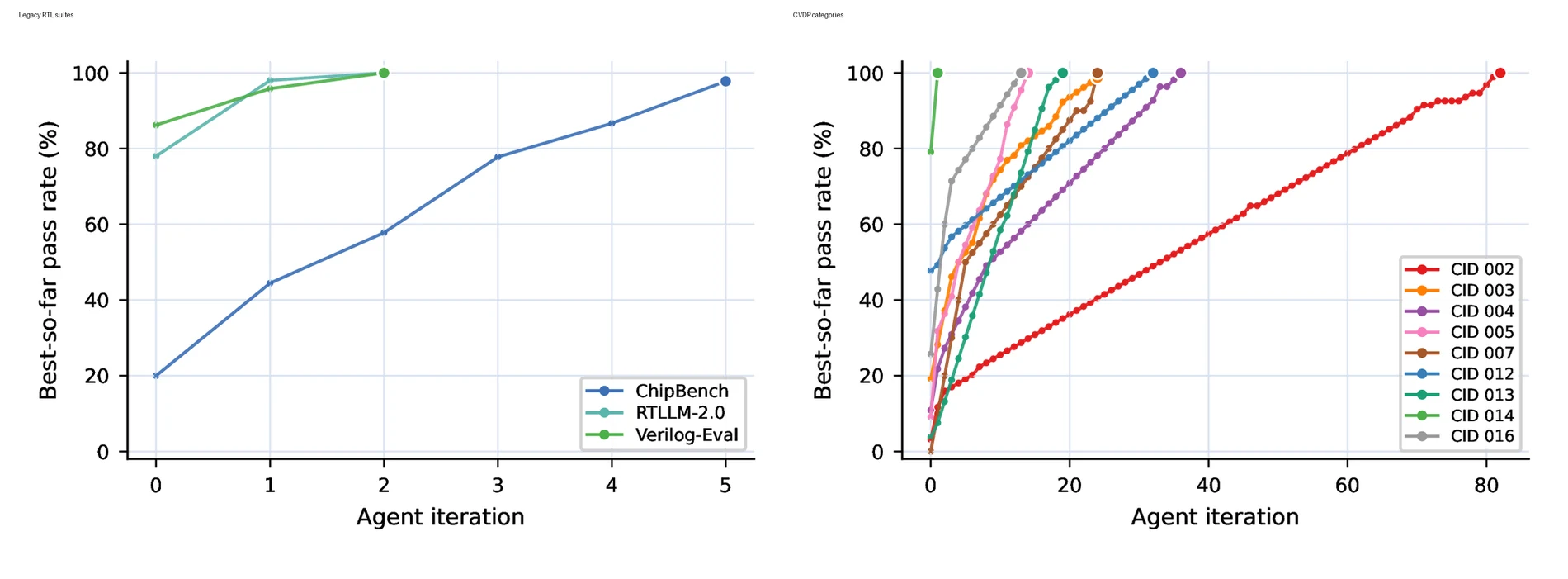
논문이 스스로 강조하듯 Iter.
0은 standalone LLM Pass@1이 아니다.
같은 agentic workflow의 첫 번째 외부 step 이후 repository 상태를 뜻한다.
따라서 이 결과는 “첫 답이 얼마나 맞았는가”보다, 실행 피드백을 가진 agent loop가 실패한 설계를 얼마나 끝까지 수리할 수 있는가를 보여주는 지표에 가깝다.
ChipBench의 경우 표에는 100%로 정리되어 있지만, footnote가 중요하다.
원래 harness 기준으로는 남는 non-passing task가 하나 있고, 논문은 이를 agent 실패가 아니라 원 benchmark의 specification-harness mismatch로 추적했다고 설명한다.
즉 이 논문의 100% 주장은 “모든 controlled benchmark task를 hands-free loop로 완료했다”는 의미이지, 실제 chip design 문제가 해결됐다는 의미는 아니다.
비용과 병목: pass rate보다 convergence cost
HORIZON 결과에서 더 실무적인 신호는 token consumption이다.
논문은 earliest-best iteration까지 누적 token을 보고하며, 전체 209.9M token 중 97.1%가 CVDP 9개 category에서 나온다고 설명한다.
세 legacy suite는 합쳐 6.0M token에 그치지만, CVDP CID 002만 56.0M token을 쓴다.
| Suite / category | 수렴 iteration | Tokens | 전체 share |
|---|---|---|---|
| ChipBench | 5 | 2.8M | 1.3% |
| RTLLM-2.0 | 2 | 1.3M | 0.6% |
| Verilog-Eval v2 | 2 | 2.0M | 1.0% |
| CVDP CID 002 | 82 | 56.0M | 26.7% |
| CVDP CID 003 | 24 | 38.0M | 18.1% |
| CVDP CID 012 | 32 | 32.2M | 15.3% |
| CVDP CID 004 | 36 | 23.7M | 11.3% |
| 전체 | - | 209.9M | 100.0% |
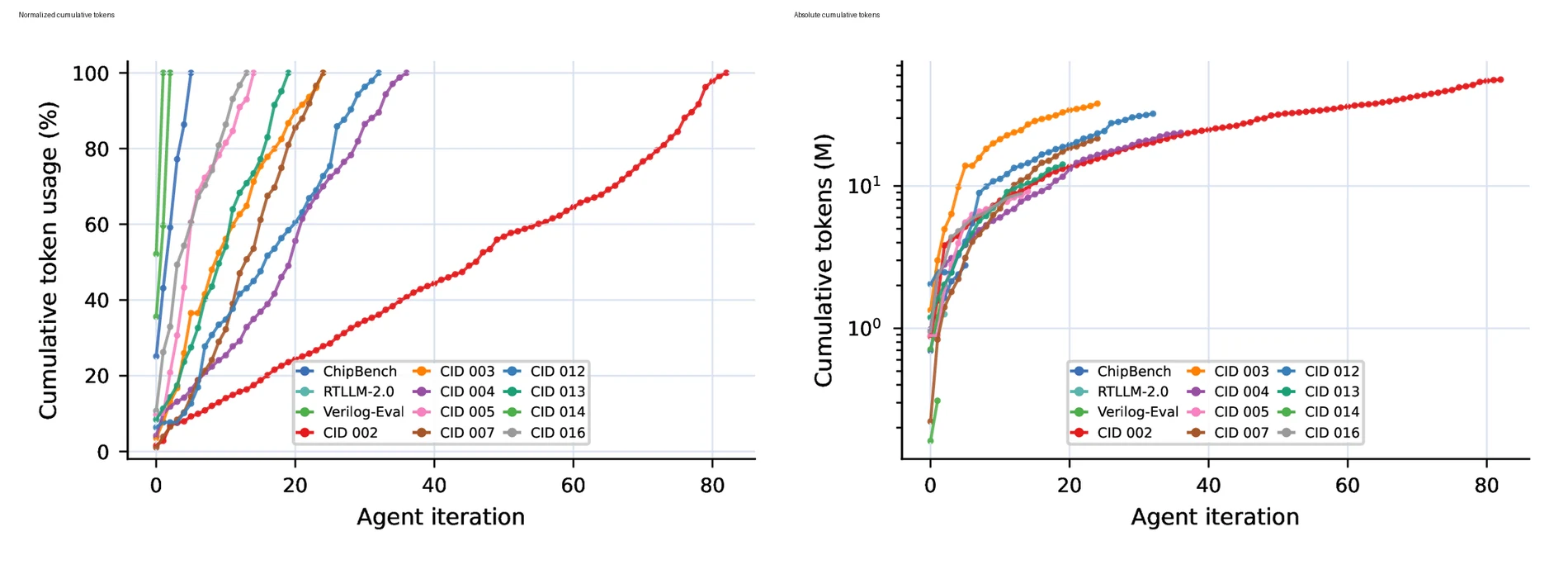
흥미로운 점은 논문이 약 91%의 token을 cached input token으로 보고한다는 것이다.
긴 campaign에서 harness, project pack, 안정적인 source context를 계속 prompt cache로 재사용하고, 새로 과금되는 부분은 현재 diff와 evaluator output, agent response 중심으로 제한하려는 설계다.
그래서 HORIZON의 비용 논의는 단순히 “token을 많이 썼다”가 아니라, 긴 수리 루프를 운영할 때 어떤 context를 cache 가능한 안정 자산으로 만들 것인가라는 시스템 설계 문제로 이어진다.
검증 생성에서는 coverage가 목표가 아니라 관찰 신호다
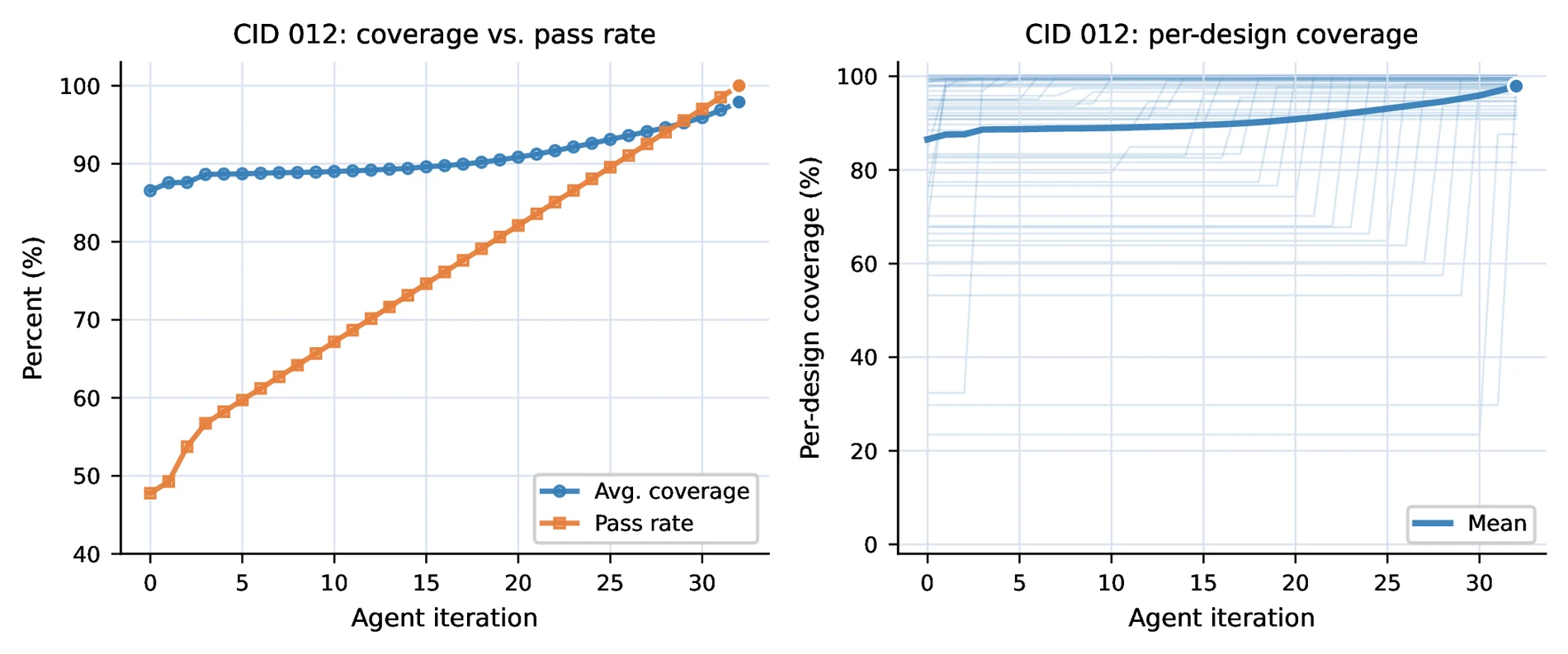
논문은 CVDP의 verification-generation category 중 CID 012 stimulus generation과 CID 014 assertion generation에 대해 coverage도 보고한다.
여기서 중요한 점은 HORIZON의 acceptance gate가 coverage maximization이 아니라 CVDP pass condition이라는 점이다.
즉 design이 harness를 통과하면 loop는 멈춘다.
CID 012는 iteration 0에서 pass 47.8%, average coverage 86.5%로 시작해 iteration 32에서 pass 100.0%, average coverage 97.9%에 도달한다.
반면 CID 014는 iteration 1에서 pass 100.0%, coverage 100.0%로 포화된다.
논문은 CID 012에서 낮은 coverage tail이 위로 끌어올려지는 모습을 보여주지만, coverage를 100%까지 직접 최적화한 것은 아니라고 선을 긋는다.
이 부분은 실무적으로 꽤 중요하다.
Hardware verification에서 “테스트가 통과했다”와 “충분히 검증했다”는 다르다.
HORIZON은 통과 가능한 설계를 만드는 데 강한 evidence를 보여주지만, 어떤 verification objective를 gate로 두느냐에 따라 결과의 의미가 달라진다.
실무 관점에서의 해석
내가 보기에 HORIZON의 핵심은 RTL agent를 “잘 prompt하면 Verilog를 써주는 모델”에서 “evaluator와 Git trace를 끼고 설계를 진화시키는 시스템”으로 옮겨 놓은 것이다.
이 관점은 하드웨어뿐 아니라 agentic software engineering, test generation, simulation-heavy workflow에도 그대로 적용된다.
중요한 것은 agent가 자유롭게 말하는 것이 아니라, 수정 가능한 workspace, 실행 가능한 evaluator, 명시적인 acceptance gate, 되감기 가능한 trace를 갖는 것이다.
다만 결과를 과대평가하면 안 된다.
논문도 agentic AI for hardware design이 solved라고 말하지 않는다.
현재 benchmark는 controlled proxy이고, 실제 chip project에는 불완전한 spec, changing constraint, downstream integration, human review, PPA trade-off, signoff-quality validation이 들어간다.
특히 논문이 지적하는 reward-hacking 위험은 크다. agent가 반복 평가 중 simulator message, failure trace, evaluator log를 볼 수 있다면, 의도한 설계 의미를 구현하기보다 visible harness의 idiosyncrasy에 맞춰 over-solving할 수 있다.
그래서 다음 세대 RTL agent benchmark는 SWE-bench처럼 repair-time feedback과 final hidden scoring을 분리할 필요가 있다.
논문이 제안하듯 hidden randomized test, independent reference model, formal equivalence check, held-out simulator configuration, property suite가 함께 들어가야 “harness를 통과했다”와 “설계를 robust하게 고쳤다”를 구분할 수 있다.
또 하나의 현실 병목은 feedback turnaround다.
이 논문의 RTL benchmark들은 반복 repair가 가능한 속도로 평가된다.
하지만 PPA optimization이나 physical design, full regression, signoff-level timing/power analysis로 내려가면 reward 하나가 hours, days, weeks 단위가 될 수 있다.
그때는 단순 edit-evaluate-repair loop보다 multi-fidelity evaluation, proxy model, asynchronous branch exploration, expensive run budget scheduling이 필요해진다.
공개 surface도 보수적으로 읽어야 한다. arXiv abs/html/PDF와 TeX source를 확인한 범위에서는 HORIZON 자체의 공식 GitHub repository나 runnable release link가 직접 노출되어 있지 않았다.
따라서 현재 독자가 바로 내려받아 돌릴 수 있는 오픈소스 tool이라기보다, repository-traced agentic hardware design을 어떻게 구성하고 평가했는지 보여주는 연구 논문으로 보는 편이 정확하다.
그럼에도 방향성은 선명하다.
Pass rate가 포화되는 영역에서는 “더 강한 모델”보다 “더 좋은 harness, 더 싼 convergence, 더 안전한 hidden evaluation, 더 재사용 가능한 trace”가 중요해진다.
HORIZON은 hardware design agent 논의를 이 시스템 설계 문제로 끌어올렸다는 점에서 꽤 중요한 신호다.