좋은 모델을 만드는 병목이 항상 모델 자체에 있는 것은 아니다.
실제 팀이 자주 부딪히는 문제는 더 지루하고 더 구조적이다.
어떤 데이터를 봐야 하는지, 누가 어떤 기준으로 피드백을 남기는지, 그 피드백이 다시 데이터셋과 평가 파이프라인으로 어떻게 되돌아가는지 정리되지 않으면 모델 품질 개선은 곧바로 멈춘다.
특히 LLM, RAG, 선호도 정렬, 멀티모달 검수처럼 사람이 직접 결과를 보고 판단해야 하는 업무에서는 이 데이터 루프가 제품 경쟁력에 더 가깝다.
Argilla가 흥미로운 이유는 바로 이 지점을 정면으로 겨냥하기 때문이다.
겉으로 보면 Argilla는 데이터 라벨링이나 주석 작업을 위한 협업 도구처럼 보인다.
하지만 공식 README와 문서를 함께 읽어 보면, 이 프로젝트의 실체는 단순 annotation UI가 아니라 AI 엔지니어와 도메인 전문가가 함께 데이터셋을 만들고, 운영하고, 반복 개선하는 워크벤치에 가깝다.
텍스트 분류 같은 전통적인 NLP 작업부터 RAG, preference tuning, 이미지 기반 멀티모달 피드백까지 하나의 데이터 구조와 UI 흐름으로 다루려는 점이 핵심이다.
또 하나 중요한 맥락은 시장 포지션이다.
최근 데이터 인프라 도구들은 모델 호출 자동화나 synthetic data 생성에 초점이 쏠리기 쉽다.
Argilla는 그 반대편에서, 사람이 실제로 데이터를 보고 판단하는 계층을 중심축으로 놓는다.
그래서 이 프로젝트를 “라벨링 툴” 정도로만 읽으면 절반만 본 셈이다.
더 정확히는 human feedback, dataset management, model evaluation 사이를 이어 주는 운영 표면이라고 보는 편이 맞다.
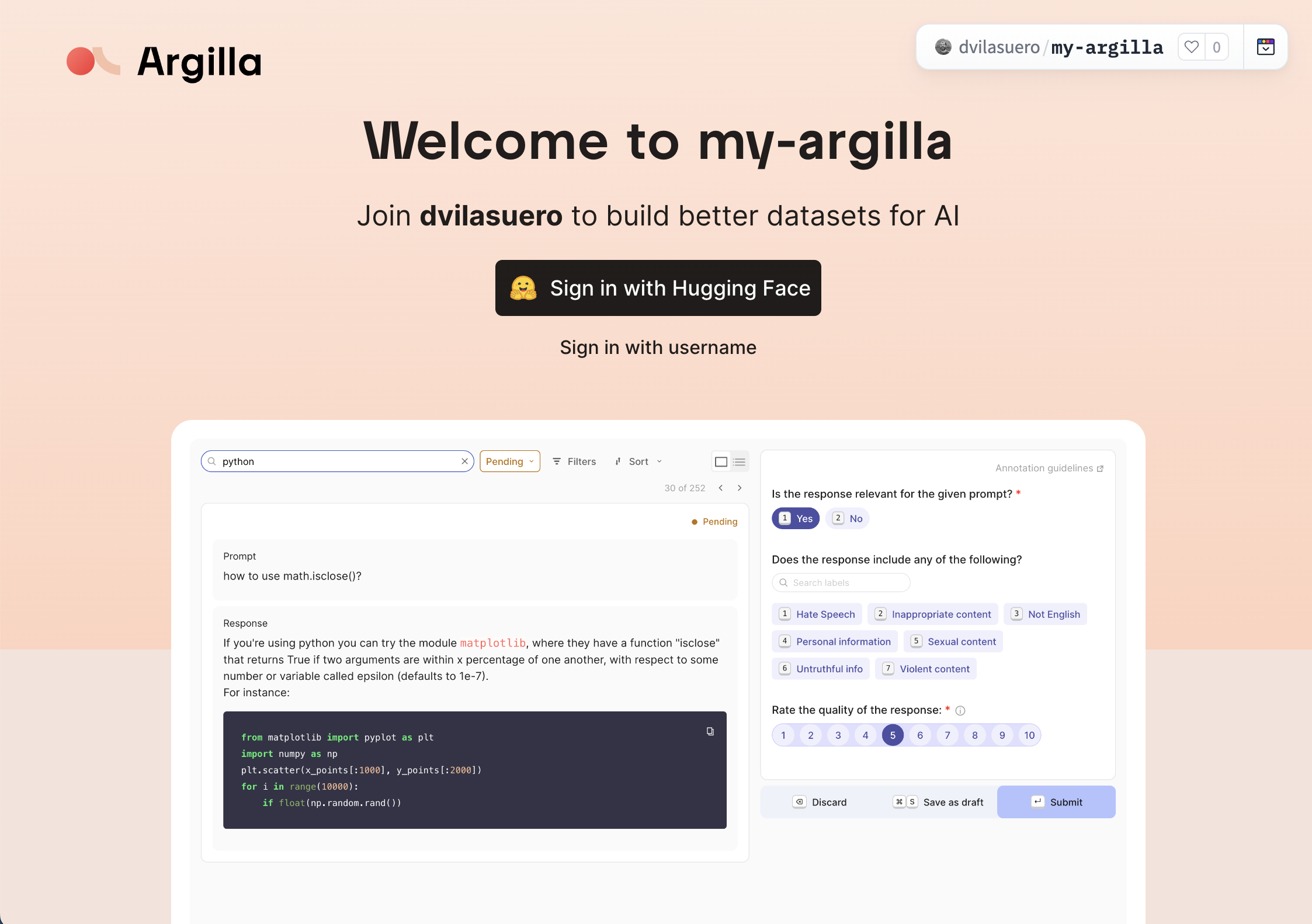
무엇을 해결하려는가
AI 팀이 데이터를 다룰 때 자주 생기는 문제는 세 가지다.
첫째, 데이터셋 스키마와 피드백 방식이 프로젝트마다 제각각이라 품질 기준이 누락되기 쉽다.
둘째, 엔지니어는 Python과 파이프라인으로 일하고 싶어 하지만 실제 검수는 UI에서 사람이 해야 하므로, 코드와 협업 인터페이스가 자주 분리된다.
셋째, 개선 루프가 기록되지 않으면 같은 오류 유형을 계속 다시 라벨링하고, 어떤 데이터가 실제 성능 개선에 기여했는지 설명하기 어려워진다.
Argilla는 이 문제를 데이터셋을 중심으로 다시 묶는다.
공식 문서에서 dataset은 단순 파일이 아니라, records 위에 fields, questions, metadata, vectors, guidelines, distribution 규칙을 얹은 협업 단위로 정의된다.
즉 “샘플 모음”이 아니라, 어떤 입력을 보여줄지, 어떤 판단을 받을지, 어떤 메타데이터와 임베딩을 붙일지, 최소 몇 명이 검토해야 하는지까지 포함한 작업 객체다.
이 설계는 특히 LLM 시대에 더 중요하다.
RAG 답변 검수, preference pair 비교, text classification, NER, 이미지-텍스트 작업은 표면적으로는 달라 보여도 결국은 사람의 판단을 구조화해 다시 모델 개선에 쓰는 문제다.
Argilla는 이런 작업을 태스크별 개별 앱으로 쪼개기보다, 데이터셋과 질문 타입을 조합하는 방식으로 일반화하려 한다.
또한 quickstart와 README가 함께 강조하듯, 이 도구는 black-box SaaS보다는 self-hosted + ownership 철학을 분명히 갖고 있다.
문서가 “당신의 데이터와 모델은 당신이 통제해야 한다”고 반복하는 이유도 여기에 있다.
데이터 품질이 경쟁력인 팀에게는 이 메시지가 단순 브랜드 문구가 아니라 도입 기준이 된다.
핵심 아이디어 / 구조 / 동작 방식
Argilla의 핵심은 데이터 라벨링 화면 하나가 아니라, 세 층이 맞물리는 구조에 있다.
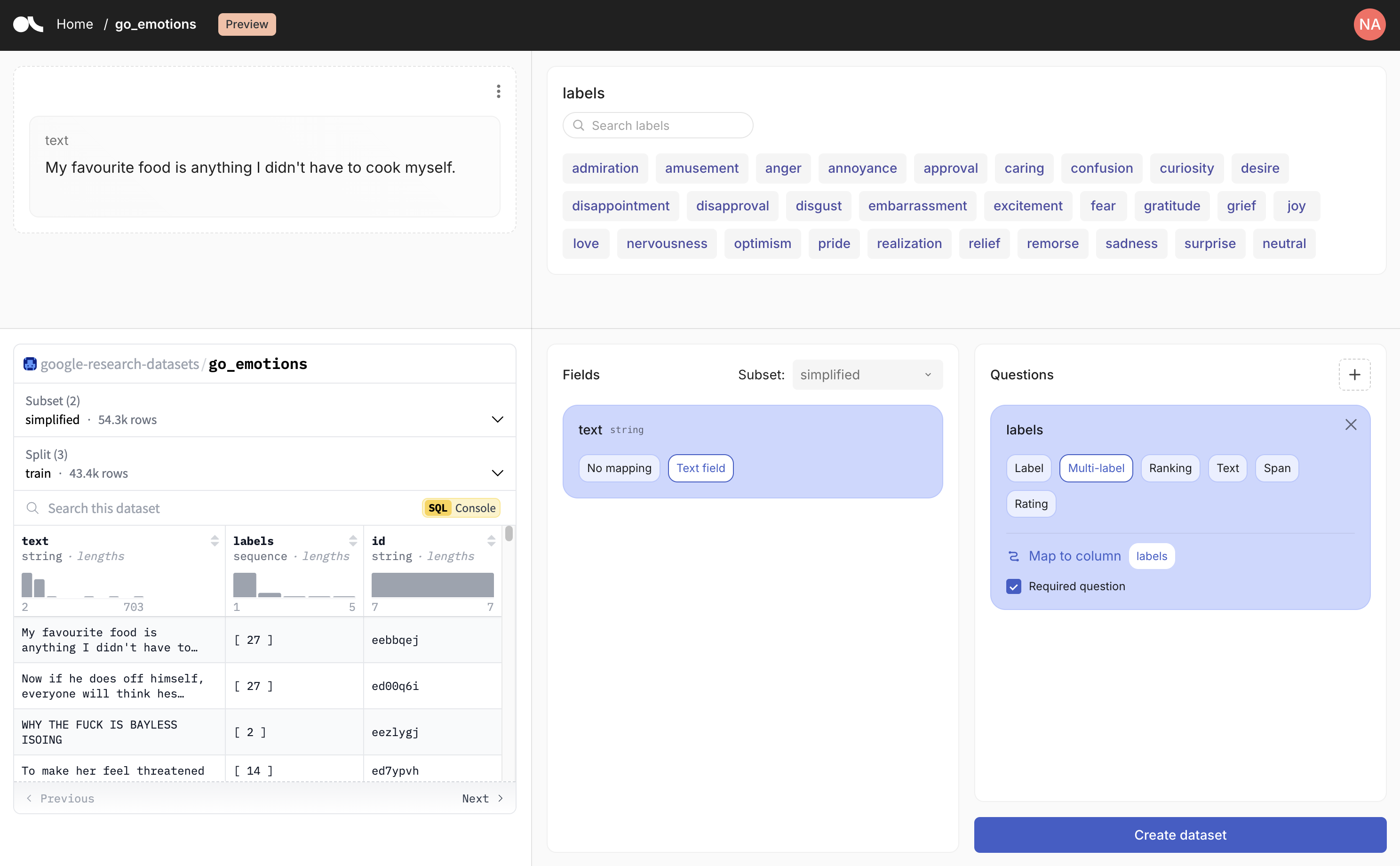
1) Python SDK로 데이터셋 스키마를 코드로 정의한다
공식 quickstart와 dataset guide에서 가장 먼저 등장하는 객체는 rg.Argilla, rg.Dataset, rg.Settings다.
사용자는 단순 CSV 업로드보다 한 단계 더 구조적인 방식으로 작업을 시작한다.
예를 들어 텍스트 필드, 라벨 질문, 메타데이터, 벡터 필드, 가이드라인, 제출 분배 규칙을 코드로 정의한 뒤 이를 서버에 생성한다.
이 접근 덕분에 데이터셋 설계가 UI 클릭 결과가 아니라 재현 가능한 코드 자산이 된다.
문서가 보여 주는 기본 예제도 이 철학을 잘 드러낸다.TextField와 LabelQuestion만으로 간단한 분류 데이터셋을 만들 수 있지만, 같은 구조를 확장하면 review, chat, image 같은 입력과 다중 질문, guidelines, semantic vector를 붙인 복합 검수 프로젝트로 자연스럽게 이어진다.
Argilla를 도입하는 팀 입장에서 중요한 점은, annotation project가 ad-hoc 화면이 아니라 버전 관리 가능한 데이터 계약이 된다는 것이다.
2) 서버와 UI가 사람 중심 검수 루프를 담당한다
README와 quickstart는 사용자가 Hugging Face Spaces 또는 Docker로 서버를 띄운 뒤 UI에서 sign-in하고, dataset을 생성하고, records를 확인하며 피드백을 남기는 흐름을 전면에 둔다.
특히 HF Spaces 경로는 5분 안에 시작할 수 있는 onboarding surface로 설계되어 있고, Docker 경로는 로컬 또는 서버 배포용으로 분리돼 있다.
즉 실험 시작은 가볍게, 운영 제어는 self-hosted 쪽으로 가져가는 이중 진입 구조다.
서버 쪽 구성도 저장소 구조에서 비교적 선명하게 드러난다.
루트에는 argilla SDK, argilla-server, argilla-frontend, docs, examples가 분리돼 있고, 서버 README는 FastAPI 기반 API, SQLAlchemy 모델, background worker, OAuth2, webhooks, dataset import 등을 명시한다.
이 구조는 Argilla가 단일 데스크톱 앱이 아니라 SDK + API server + frontend + docs/examples의 조합으로 운영되는 제품이라는 사실을 보여 준다.
3) 데이터 품질 루프를 annotation에서 끝내지 않는다
공식 소개 페이지는 Argilla를 traditional NLP뿐 아니라 LLM, RAG, preference tuning, multimodal 프로젝트에 사용할 수 있다고 설명한다.
README에는 UltraFeedback 정제본, Notus/Notux 모델, distilabeled Intel Orca DPO 데이터셋 같은 사례가 등장한다.
즉 Argilla의 역할은 사람이 라벨을 달고 끝나는 것이 아니라, 피드백으로 데이터를 고치고 그 결과를 모델 개선으로 연결하는 폐루프에 있다.
이 점은 Distilabel과의 관계에서도 읽힌다.
Distilabel이 synthetic data와 AI feedback 파이프라인을 담당하는 쪽이라면, Argilla는 사람이 최종적으로 보고 선별하고 수정하는 협업 계층에 가깝다.
둘은 경쟁 관계라기보다, synthetic generation과 human curation을 연결하는 상하위 계층처럼 보인다.
공개 자료를 바탕으로 Argilla의 표면을 간단히 정리하면 다음과 같다.
| 층위 | 공개 자료에서 확인되는 구성 | 실무적 의미 |
|---|---|---|
| SDK | rg.Argilla, rg.Dataset, rg.Settings, TextField, LabelQuestion |
데이터셋 스키마를 코드로 정의하고 재현 가능하게 유지 |
| Server | FastAPI, OAuth2, background workers, dataset import, webhooks | 다중 사용자 협업과 운영형 배포를 위한 백엔드 기반 |
| Frontend | sign-in UI, dataset configuration, record annotation 화면 | 도메인 전문가가 실제로 피드백을 남기는 작업면 |
| Data model | fields, questions, metadata, vectors, guidelines, distribution | 단순 샘플 묶음이 아니라 구조화된 피드백 계약 |
| Deployment | Hugging Face Spaces, Docker | 빠른 체험과 self-hosted 운영을 모두 지원 |
공개된 근거에서 확인되는 점
현재 공개 GitHub 저장소 기준으로 argilla-io/argilla는 약 4.9k stars, 484 forks, Apache 2.0 라이선스를 갖고 있다.
공식 docs의 현재 최신 버전 표면은 latest와 v2.8 계열을 함께 보여 주며, GitHub latest release는 v2.8.0이다.
저장소의 default branch는 develop으로 잡혀 있고, latest release 역시 develop을 target commitish로 사용한다.
흥미로운 부분은 유지보수 메시지다.
README 최상단에는 원저자들이 다른 프로젝트로 이동했고, 앞으로는 새 기능 추가보다 bug fix와 patch 중심의 유지보수를 하겠다는 공지가 직접 적혀 있다.
즉 Argilla는 초기 성장 국면의 빠른 확장형 프로젝트라기보다, 이미 성숙한 코드베이스를 안정적으로 관리하는 단계로 읽는 편이 맞다.
배포 경로도 비교적 명확하다. quickstart는 Hugging Face Spaces 배포를 “recommended choice”로 제시하며, Python SDK의 deploy_on_spaces 경로도 제공한다.
동시에 Docker 배포 가이드를 별도로 유지하고 있어, 데모와 팀 운영 환경을 분리해 생각할 수 있다.
문서에서 특히 눈에 띄는 운영상 주의점은 HF Spaces persistent storage를 SMALL 이상으로 두지 않으면 재시작 시 데이터가 유실될 수 있다는 경고다.
이건 단순 quickstart 팁이 아니라, 실사용과 체험판을 구분해야 한다는 중요한 신호다.
데이터셋 모델도 꽤 풍부하다.
공식 dataset guide는 설정 요소로 fields, questions, metadata, vectors, guidelines, TaskDistribution(min_submitted=...)를 직접 보여 준다.
또한 dataset 관리 권한을 owner와 admin 역할로 분리하고 있어, Argilla가 개인용 라벨링 앱보다 협업형 데이터 운영 도구에 더 가깝다는 점을 확인할 수 있다.
저장소 구조에서 확인되는 구현 범위 역시 넓다.
루트에 argilla, argilla-server, argilla-frontend, docs, examples, argilla-v1가 함께 존재한다. argilla-server의 의존성에는 FastAPI, SQLAlchemy, RQ, OAuth2, webhook, Hugging Face dataset import 관련 패키지가 포함돼 있고, argilla-frontend는 별도 Nuxt 기반 프런트엔드로 분리돼 있다.
즉 이 프로젝트는 단순 Python 패키지 하나가 아니라 제품형 풀스택 레포다.
실무 관점에서의 해석
내가 보기에 Argilla의 진짜 강점은 “라벨링을 쉽게 한다”가 아니다.
더 중요한 점은 사람의 판단을 운영 가능한 데이터 구조로 고정한다는 데 있다.
많은 팀이 품질 개선 루프를 말로는 중요하다고 하지만, 실제로는 Slack 스레드, CSV, 노트북, 평가 로그가 서로 분리돼 있다.
Argilla는 이 흩어진 층을 dataset이라는 중심 객체로 다시 묶는다.
엔지니어는 SDK로 구조를 정의하고, 도메인 전문가는 UI에서 판단을 남기며, 팀은 그 결과를 다시 모델 개선이나 데이터셋 릴리스로 연결한다.
특히 LLM 애플리케이션에서는 이 구조가 점점 더 중요해진다. preference tuning, RAG answer review, classification refinement, multimodal verification은 전부 “모델을 한 번 더 학습시키기 전에 사람이 무엇을 봤는가”의 기록이 필요하기 때문이다.
그런 점에서 Argilla는 training stack 이전 단계의 부속품이 아니라, 모델 개선을 위한 human feedback control plane처럼 해석하는 편이 더 적절하다.
물론 한계도 분명하다.
README가 직접 밝히듯 현재 프로젝트는 feature velocity보다 안정 유지에 가까운 상태다.
최신 flashy workflow나 완전히 새로운 agentic surface를 기대하면 다소 보수적으로 느껴질 수 있다.
또 self-hosted 철학은 장점이지만, 반대로 말하면 조직이 배포와 권한 관리, 저장소 운용을 직접 감당해야 한다는 뜻이기도 하다.
HF Spaces quickstart는 훌륭한 진입점이지만, 지속 운영 단계에서는 Docker나 자체 인프라 설계가 결국 필요해진다.
그럼에도 불구하고 Argilla는 여전히 가치가 크다.
데이터 품질을 모델 바깥의 부차적 작업으로 보지 않고, 사람·스키마·UI·파이프라인을 하나의 시스템으로 본다는 점 때문이다.
합성 데이터나 자동 평가가 아무리 발전해도, 최종적으로 사람이 보고 책임지는 데이터 루프는 사라지지 않는다.
그런 팀이라면 Argilla는 오래된 annotation tool이 아니라, 지금도 유효한 AI 데이터 협업의 기반 레이어로 볼 만하다.