RAG 시스템이 틀렸을 때 가장 쉬운 처방은 “한 번 더 검색하자”다. adaptive retrieval, iterative retrieval, self-RAG 계열은 언제 검색할지, 몇 번 검색할지, 검색 결과를 어떻게 다시 넣을지를 꽤 정교하게 다듬어 왔다. 하지만 실제 실패 사례를 보면 문제가 단순히 검색 횟수 부족이 아닌 경우가 많다. 질문 표현이 문서 공간과 어긋나 있거나, 여러 전제가 한 쿼리에 얽혀 있거나, 이미 가져온 evidence에서 무엇을 더 좁혀야 할지 모르는 식이다.
Skill-RAG: Failure-State-Aware Retrieval Augmentation via Hidden-State Probing and Skill Routing는 이 지점을 정면으로 건드린다. 논문의 핵심 주장은 RAG 실패가 하나의 단일 현상이 아니라는 것이다. 특히 persistent retrieval failure의 상당수는 관련 evidence가 세상에 없어서가 아니라, query와 evidence space 사이의 alignment gap 때문에 생긴다. 그래서 Skill-RAG는 실패를 만나면 바로 재검색하지 않고, 먼저 모델 내부 hidden state로 지금 상태가 “답변 가능한 상태”인지 판별한 뒤, 실패라면 어떤 교정 skill을 쓸지 라우팅한다.
무엇을 해결하려는가
기존 RAG의 실패 처방은 크게 두 부류로 나뉜다. 하나는 검색을 언제 트리거할지 결정하는 방식이다. 생성 confidence가 낮아지면 검색하거나, attention signal을 보거나, query complexity를 분류해 retrieval depth를 정한다. 다른 하나는 검색 결과가 부족할 때 다시 검색하는 방식이다. 이전 reasoning trace나 intermediate query를 사용해 추가 문서를 가져온다.
Skill-RAG가 보기에 이 접근들은 검색 제어를 너무 거칠게 다룬다. “검색이 필요한가”와 “한 번 더 검색해야 하는가”는 묻지만, 왜 현재 evidence가 답변으로 이어지지 않는가를 충분히 구분하지 않는다. 같은 실패라도 원인은 다르다.
| 실패 유형 | 필요한 교정 | 단순 재검색의 위험 |
|---|---|---|
| 쿼리 표면형이 corpus 표현과 다름 | query rewriting | 계속 비슷하지만 틀린 문서만 검색 |
| 질문이 여러 hop으로 얽힘 | question decomposition | 한 번의 top-k가 중간 전제를 놓침 |
| evidence는 있지만 초점이 넓음 | evidence focusing | 관련 문서는 있으나 필요한 slot을 못 좁힘 |
| 지식이 없거나 retriever 한계가 큼 | exit | 비용만 쓰고 query drift가 누적 |
이 논문의 좋은 점은 RAG 실패를 추상적인 “retrieval quality” 문제가 아니라, typed failure state 문제로 본다는 데 있다. 실패 상태가 유형화될 수 있다면, 모든 케이스에 같은 재검색 루프를 적용할 필요가 없다. 어떤 경우에는 query를 다시 써야 하고, 어떤 경우에는 질문을 쪼개야 하며, 어떤 경우에는 지금 검색을 멈춰야 한다.
핵심 아이디어 / 구조 / 동작 방식
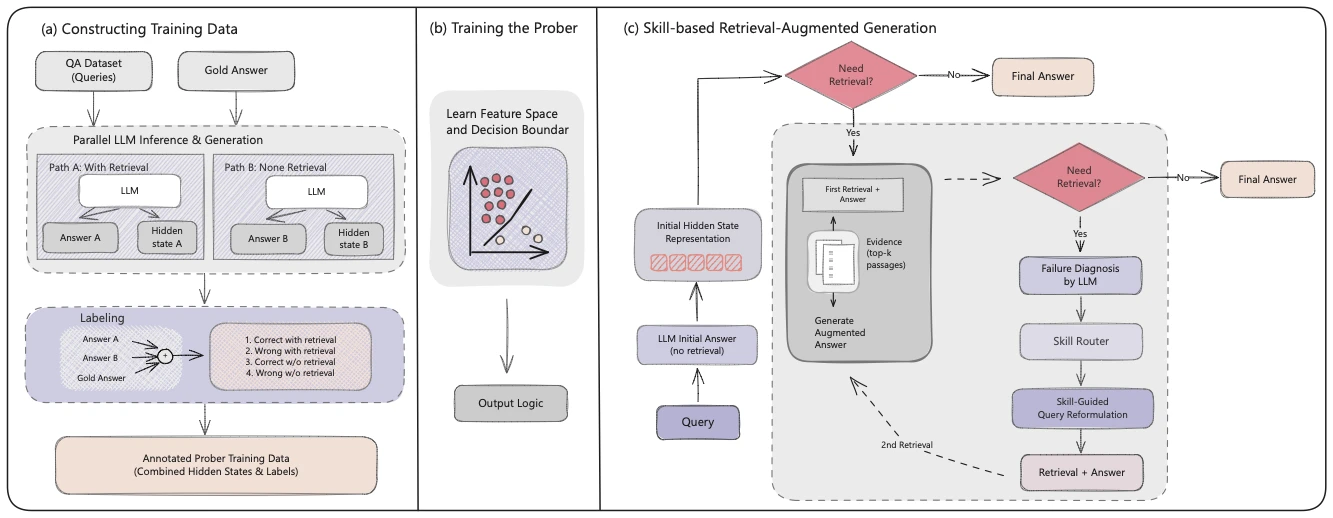
Skill-RAG는 두 개의 모듈을 붙인다. 하나는 hidden-state prober이고, 다른 하나는 prompt-based skill router다.
첫째, hidden-state prober는 모델의 내부 표현을 보고 현재 답변 상태가 충분한지 판단한다. 저자들은 HotpotQA, Natural Questions, TriviaQA의 training split에서 no-retrieval과 single-step retrieval을 모두 실행한다. 각 예제에 대해 모델이 chain-of-thought reasoning trace와 최종 답을 만들고, reasoning token과 answer token에 해당하는 hidden state를 posterior two-thirds layer에서 뽑는다. 그런 다음 생성 답과 gold answer를 비교해 correctness label을 붙인다.
prober 자체는 단일 hidden layer를 가진 feed-forward network와 binary classification head로 구성된다. 중요한 구현 포인트는 layer별로 prober를 따로 학습하고, inference 때는 각 layer prober의 확률을 평균해 하나의 gating signal로 만든다는 점이다. 즉 Skill-RAG는 별도의 LLM call을 추가로 쓰지 않고, 이미 생성 과정에서 얻을 수 있는 hidden state를 활용해 “지금 답변 가능한가”를 판단하려 한다.
둘째, skill router는 prober가 실패 상태를 감지했을 때만 호출된다. router는 원 질문, 실패한 reasoning과 answer, 현재 retrieved evidence를 보고 아래 네 가지 skill 중 하나를 고른다.
| Skill | 역할 | 직관적 의미 |
|---|---|---|
| Query rewriting | corpus indexing convention에 맞게 질문 표면형을 바꿈 | 같은 의도를 더 검색 친화적인 표현으로 바꿈 |
| Question decomposition | multi-hop query를 sub-query로 분해 | 얽힌 전제를 순차적 검색 문제로 바꿈 |
| Evidence focusing | 현재 evidence에서 빠진 정보 slot을 좁힘 | 너무 넓은 관련 문서에서 필요한 부분을 다시 겨냥 |
| Exit | irreducible case로 판단하고 종료 | 없는 지식이나 retriever 한계에 비용을 더 쓰지 않음 |
셋째, 이 둘을 합쳐 반복적 skill retrieval loop를 만든다. 입력 query가 들어오면 prober는 먼저 parametric knowledge만으로 답할 수 있는지 본다. 필요하면 retrieval을 수행하고, retrieved evidence를 넣은 답변 상태를 다시 prober가 평가한다. 충분하면 종료한다. 부족하면 skill router가 실패 원인을 진단하고 skill-guided query reformulation을 만든다. 이후 다시 retrieval과 answer generation을 수행한다. 루프는 router가 exit을 선택하거나, prober가 충분하다고 판단하거나, 최대 retrieval round에 도달할 때 멈춘다.
이 설계는 RAG를 “검색기 + 생성기”의 단순 조합보다 조금 더 agentic한 제어 문제로 바꾼다. 하지만 흥미롭게도 저자들은 복잡한 planner나 multi-agent 구조를 쓰지 않는다. 실패 진단은 prompt router가 하고, 종료/계속 여부는 hidden-state prober가 gate한다. 시스템 복잡도는 비교적 낮게 유지하면서도, 재검색의 방향만 더 세밀하게 만든다.
공개된 근거에서 확인되는 점
실험은 다섯 개 open-domain QA benchmark에서 진행된다. HotpotQA, NQ, TriviaQA는 in-domain으로 쓰고, MuSiQue와 2WikiMultiHopQA는 out-of-domain test로 둔다. in-domain 데이터에서는 prober training을 위해 3,000 examples를 샘플링하고 500 examples를 development로 사용한다. OOD 데이터셋은 각각 500 examples로 평가한다. retriever는 BM25이고, backbone은 Gemma2-9B다. 모든 방법은 4-shot prompting으로 비교하며 Exact Match와 Accuracy를 함께 본다.
비교 대상은 no retrieval, single-step RAG, FLARE, DRAGIN, Adaptive-RAG, Probing-RAG다. 핵심 결과만 평균 지표로 압축하면 다음과 같다.
| 방법 | 평균 EM | 평균 ACC | 읽을 포인트 |
|---|---|---|---|
| No Retrieval | 28.0 | 40.0 | parametric-only 기준선 |
| Single-step Approach | 26.7 | 41.5 | 한 번 검색이 항상 EM을 올리지는 않음 |
| FLARE | 26.7 | 34.5 | token uncertainty 기반 triggering의 한계 |
| DRAGIN | 32.7 | 38.7 | 평균 EM은 가장 높지만 ACC는 낮음 |
| Adaptive-RAG | 27.2 | 34.6 | query complexity routing만으로는 부족 |
| Probing-RAG | 30.1 | 42.4 | hidden-state gating baseline |
| Skill-RAG | 31.0 | 46.8 | 평균 ACC에서 가장 강함 |
가장 눈에 띄는 부분은 OOD에서의 차이다. 논문은 Skill-RAG가 Probing-RAG보다 MuSiQue ACC에서 6.1 points, 2WikiMultiHopQA ACC에서 13.6 points 높다고 보고한다. 전체 평균 ACC도 Probing-RAG 42.4에서 Skill-RAG 46.8로 올라간다. 즉 단순히 hidden-state로 retrieval을 gate하는 것보다, 실패 상태를 보고 어떤 skill로 고칠지 선택하는 쪽이 특히 distribution shift에서 더 잘 버틴다.
다만 결과를 과장해서 읽을 필요는 없다. DRAGIN은 HotpotQA와 2WikiMultiHopQA의 EM에서 더 높은 값을 보이고, Skill-RAG도 모든 metric에서 압도적 1등은 아니다. 이 논문의 강점은 “모든 benchmark에서 무조건 최고”라기보다, hard case와 OOD case에서 실패 원인을 나눠 조치하는 구조가 평균 ACC를 크게 끌어올린다는 쪽에 있다.
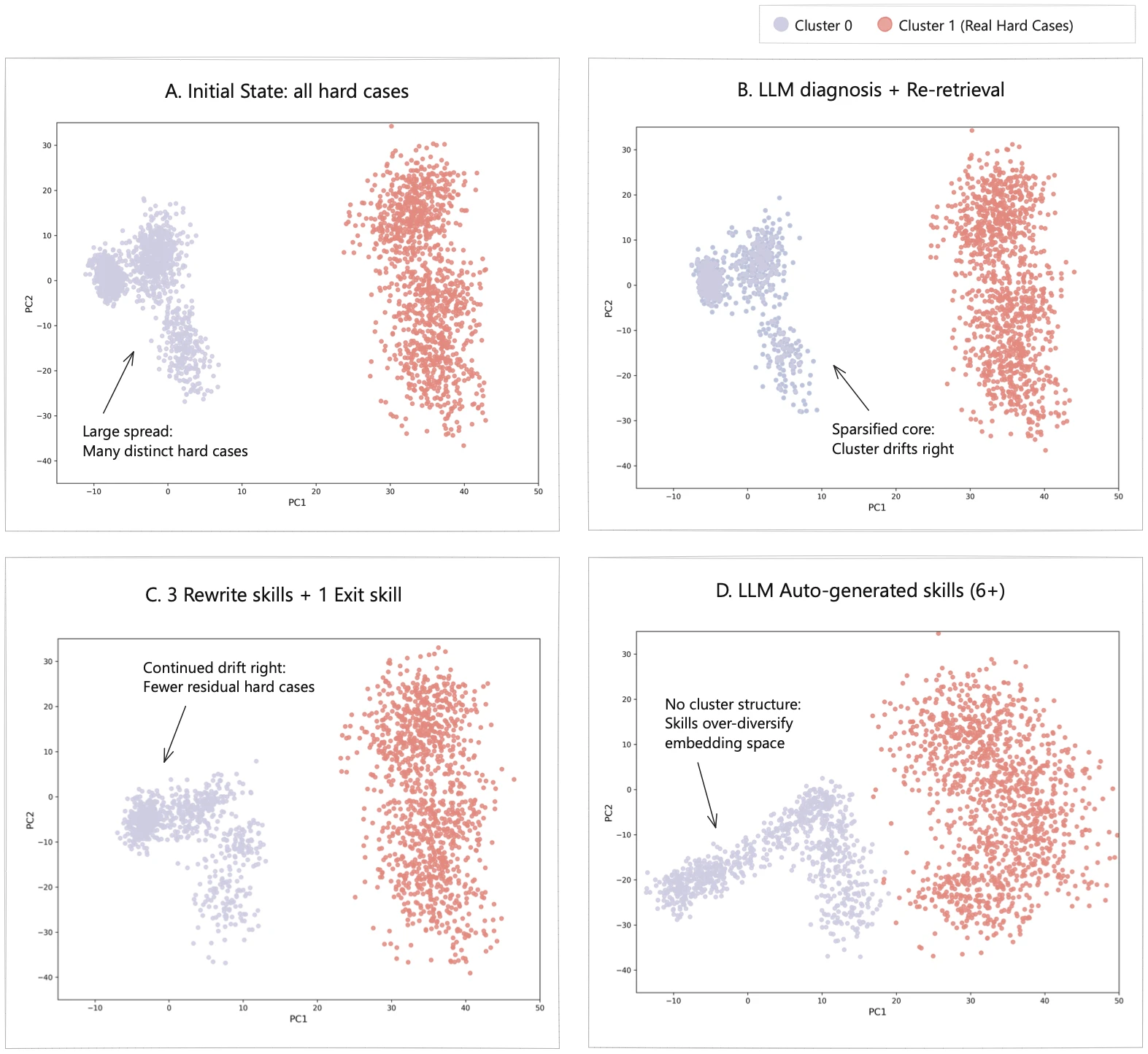
표현 공간 분석도 이 논문의 메시지를 강화한다. 저자들은 세 번의 standard retrieval 후에도 틀린 hard case의 hidden-state embedding을 t-SNE로 시각화한다. 초기 상태에서는 두 클러스터가 보인다. 하나는 query-evidence alignment gap으로 고칠 수 있는 실패이고, 다른 하나는 retriever 한계나 missing knowledge 때문에 쉽게 고치기 어려운 실패다.
이후 skill을 적용하면 alignment-fixable cluster가 점점 줄어든다. LLM diagnosis와 re-retrieval만 쓴 경우보다, query rewriting·decomposition·evidence focusing·exit으로 구성된 네 가지 skill vocabulary를 쓰는 경우 남은 hard case가 더 작아진다. 반대로 LLM에게 여섯 개 이상의 skill을 자동 생성하게 한 설정에서는 cluster 구조가 무너진다. 이 부분은 꽤 중요한 관찰이다. skill을 많이 만들수록 좋은 것이 아니라, 실패 표현 공간의 구조와 맞는 작고 안정적인 skill vocabulary가 더 유리할 수 있다는 뜻이다.
case study도 메시지가 선명하다. 질문은 “When does the new My Hero Academia movie come out?”이고 gold answer는 2018년 7월 5일이다. 초기 검색은 Funimation의 미국/캐나다 공개 시점 쪽 evidence를 가져와 실패한다. Probing-RAG는 다음 round에서 이전 context를 순진하게 이어 붙이다가 일본 록밴드 쪽으로 query drift가 발생하고, 세 번째 round에서도 회복하지 못한다. Skill-RAG는 Round 1 이후 실패를 query_misaligned로 진단하고, query를 “My Hero Academia Two Heroes Japan release date 2018”로 rewrite한다. 이 query는 일본 프리미어 날짜 evidence를 찾고, 시스템은 Round 2에서 정답으로 종료한다.
이 사례가 보여 주는 차이는 검색기 자체보다 실패 후 행동 정책이다. 같은 initial failure를 만나도, 한쪽은 더 긴 query drift로 빠지고, 다른 한쪽은 실패 유형을 좁혀 정확한 correction을 적용한다.
실무 관점에서의 해석
내가 보기에 Skill-RAG의 가장 중요한 실무적 메시지는 RAG pipeline에 failure taxonomy와 load-gating layer가 필요하다는 것이다. 많은 RAG 시스템은 retrieval score, reranker score, answer confidence 정도는 보지만, 실패 후 조치를 하나의 retry loop로 묶어 버린다. Skill-RAG는 그 사이에 “지금 실패는 어떤 종류인가”라는 얇은 진단 계층을 넣는다.
이 접근은 특히 다음 환경에서 유용해 보인다.
| 환경 | Skill-RAG식 접근이 유용한 이유 |
|---|---|
| multi-hop QA / research assistant | 질문 분해와 evidence focusing이 실제 성능 병목과 맞음 |
| 기업 내부 문서 RAG | query 표현과 문서 indexing convention이 자주 어긋남 |
| 긴 문서 기반 technical support | 관련 문서는 찾았지만 필요한 slot을 못 좁히는 경우가 많음 |
| 비용 민감한 retrieval loop | irreducible case에서 exit skill로 불필요한 round를 줄일 수 있음 |
특히 exit skill은 작지만 중요하다. RAG 시스템은 종종 “틀렸으니 더 검색”이라는 낙관적 루프에 빠진다. 하지만 검색 대상에 답이 없거나, retriever가 해당 corpus에서 회수할 수 없는 정보라면 계속 검색하는 것은 hallucination과 비용을 함께 늘린다. Skill-RAG의 exit은 실패를 인정하는 능력도 retrieval policy의 일부로 봐야 한다는 점에서 실무적으로 가치가 있다.
또 하나의 포인트는 hidden-state prober다. production RAG에서 모든 판단을 LLM call로 처리하면 latency와 비용이 커진다. Skill-RAG는 모델 내부 state를 이용해 retrieval gate를 만들기 때문에, 적어도 연구 설계상으로는 추가 LLM call 없이 “답변 가능성”을 추정할 수 있다. 물론 실제 제품에 적용하려면 사용하는 backbone의 hidden state 접근 가능성, serving stack, prober 학습 데이터, 모델 업데이트에 따른 recalibration 문제가 붙는다. API-only 모델에서는 이 부분이 곧바로 적용되기 어렵고, self-hosted 또는 logit/hidden-state 접근이 가능한 모델에서 더 현실적이다.
한계와 남은 질문
논문 자체도 한계를 분명히 적는다. 첫째, skill router가 prompt-based이기 때문에 underlying LLM의 instruction-following 능력에 민감하다. 작은 모델이나 지시 따르기가 약한 모델에서는 실패 진단 품질이 떨어질 수 있다.
둘째, 네 가지 skill vocabulary는 open-domain QA benchmark에서 관찰한 실패 패턴을 바탕으로 만든 것이다. 과학 논문 검색, 법률 문서, 다국어 corpus, 코드 검색처럼 retrieval 특성이 다른 환경에서도 같은 네 skill이 충분할지는 아직 검증이 필요하다. 예를 들어 코드 RAG에서는 API version mismatch, symbol resolution, dependency graph traversal 같은 별도 skill이 필요할 수 있다.
셋째, 실험은 Gemma2-9B 단일 model family를 중심으로 진행된다. prober가 hidden state를 쓰는 이상 모델 architecture와 layer representation에 영향을 받을 수밖에 없다. 더 큰 모델, 다른 tokenizer와 architecture, instruction-tuned model, long-context model에서도 같은 failure geometry가 유지되는지 확인해야 한다.
그럼에도 Skill-RAG는 RAG 연구에서 꽤 좋은 방향 전환을 보여 준다. retrieval을 더 많이 하는 것이 아니라, 실패를 더 잘 읽고 그에 맞는 조치를 고르는 것이다. 앞으로의 RAG 시스템은 retriever, reranker, generator만으로 구성되기보다, failure-state probe + skill router + termination policy를 함께 가진 형태로 진화할 가능성이 크다. 그런 의미에서 Skill-RAG는 RAG를 단순 검색 증강에서 실패-aware control system으로 옮기는 흥미로운 설계안으로 볼 만하다.