멀티 에이전트 시스템을 오래 쓰다 보면 병목은 “에이전트를 몇 개 더 붙일 것인가”가 아니라 “그 에이전트들을 어떤 조직으로 운영할 것인가”에 가까워진다.
지금의 많은 프레임워크는 역할을 나누고 메시지를 주고받게 만들 수는 있지만, 팀 구성, 채용, 권한, 리뷰, 실패 후 학습, 서로 다른 런타임의 공존까지 하나의 운영 레이어로 다루지는 못한다.
OneManCompany(OMC) 논문인 From Skills to Talent: Organising Heterogeneous Agents as a Real-World Company는 이 빈칸을 “AI organisation design”이라는 이름으로 정식화한다.
핵심 주장은 간단하다.
스킬은 한 에이전트를 더 유능하게 만들지만, Talent는 여러 에이전트를 실제 회사처럼 채용·배치·평가·교체할 수 있는 단위로 만든다.
OMC는 이 Talent를 실행 런타임과 분리하고, Talent Market에서 필요한 직무를 고용하고, E²R(Explore–Execute–Review) 트리로 프로젝트를 운영한다.
흥미로운 점은 이 논문이 단순한 은유에서 멈추지 않는다는 것이다.
공식 저장소는 npx @1mancompany/onemancompany로 실행되는 오픈소스 제품 표면을 제공하고, 별도 Talent Market은 에이전트 패키지를 Git 저장소 단위로 배포한다.
따라서 OMC는 논문 속 아키텍처 제안인 동시에, “브라우저에서 AI 회사를 운영한다”는 제품 실험이기도 하다.
무엇을 해결하려는가
기존 멀티 에이전트 시스템의 약점은 크게 세 가지로 정리된다.
첫째, 팀 구조가 고정적이다.
MetaGPT나 ChatDev류의 SOP 파이프라인은 미리 정해진 역할과 순서가 강하고, AutoGen이나 LangGraph류의 그래프 기반 시스템도 개발자가 미리 노드와 관계를 구성하는 경우가 많다.
새로운 프로젝트가 들어왔을 때 “지금 우리 팀에 디자이너가 없으니 채용하자” 같은 조직 차원의 동적 의사결정은 보통 외부 로직으로 빠진다.
둘째, 에이전트 정체성과 실행 런타임이 붙어 있다.
어떤 에이전트는 Claude Code 세션으로 돌고, 어떤 에이전트는 LangGraph 노드로 돌며, 또 어떤 에이전트는 스크립트 기반 실행기로 감쌀 수 있다.
하지만 오케스트레이션 레이어가 각 런타임의 세부 API를 직접 알아야 하면, 새 에이전트 계열을 붙일 때마다 조건문과 어댑터가 늘어난다.
셋째, 학습이 세션 안에 갇힌다.
프로젝트가 끝난 뒤 어떤 에이전트가 잘했는지, 어떤 SOP가 반복 가능한 지식으로 남아야 하는지, 어떤 역할은 승진·코칭·교체 대상인지가 조직 레벨의 자산으로 축적되지 않으면, 다음 프로젝트는 다시 비슷한 시행착오를 반복한다.
OMC가 겨냥하는 병목은 바로 이 “조직 레이어”다.
논문은 이를 “개별 에이전트가 무엇을 아는가”와 “에이전트 노동력을 어떻게 구성하고 개선하는가”를 분리하는 문제로 본다.
그래서 제목도 skills에서 talents로 이동한다.
스킬은 라이브러리라면, Talent는 채용 가능한 직원이다.
| 구분 | Skills & Skill Markets | Talents & Talent Markets |
|---|---|---|
| 레벨 | 한 에이전트 내부 | 에이전트 팀 전체 |
| 단위 | 재사용 가능한 도구·함수·절차 | 역할, 도구, 스킬, 행동 원칙을 갖춘 완전한 에이전트 패키지 |
| 목적 | 한 에이전트의 능력 확장 | 문제에 맞는 팀 구성과 운영 |
| 런타임 | 특정 시스템에 묶이기 쉬움 | 여러 실행 컨테이너 위에 배치 가능 |
| 생애주기 | 명확한 관리 루프가 약함 | 채용, 평가, 교체, 학습, 조직 개선 |
핵심 아이디어 / 구조 / 동작 방식
OMC의 중심 구조는 세 축으로 볼 수 있다.
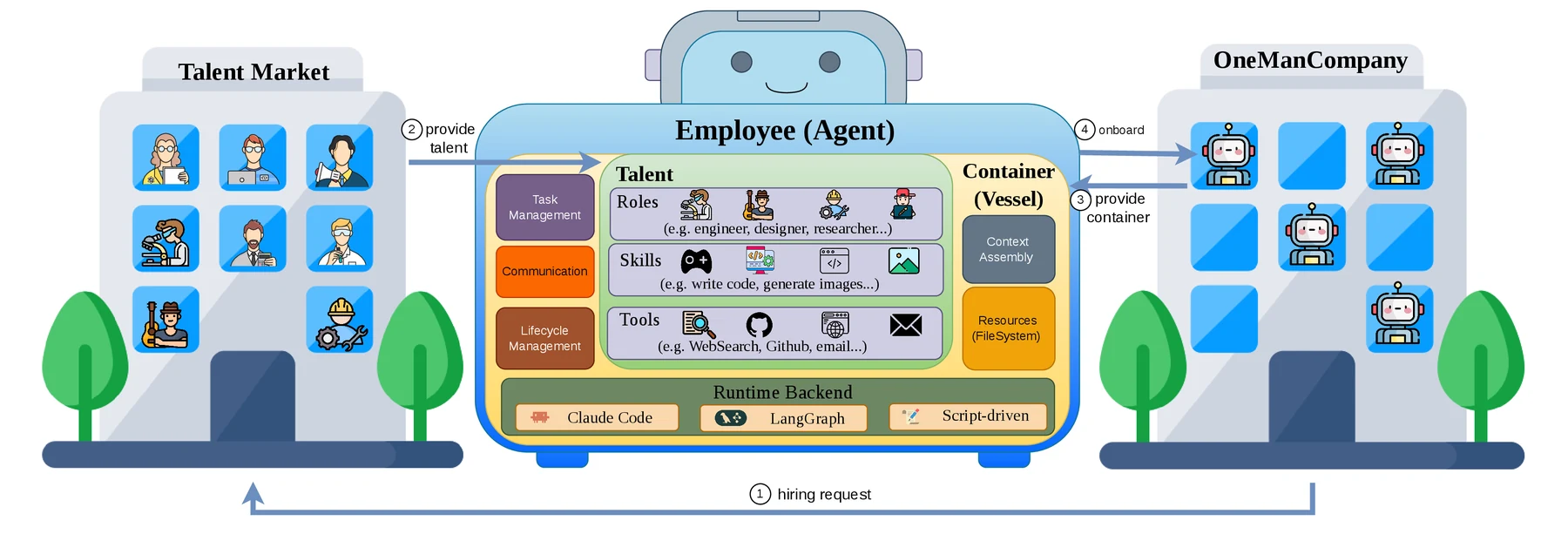
첫 번째는 Talent–Container 분리다.
OMC에서 Employee는 Talent와 Container의 합성물이다.
Talent는 역할, 프롬프트, 스킬, 도구, 작업 원칙, 보조 리소스처럼 “인지적 정체성”을 담는다.
Container는 그 Talent를 실제로 실행하는 런타임이다.
논문은 현재 Claude Code 기반, LangGraph 기반, script 기반 executor를 예로 든다.
이 분리가 중요한 이유는 같은 Talent를 다른 Container에 올릴 수 있고, 반대로 같은 Container에 다른 Talent를 태울 수 있기 때문이다.
OMC는 이를 위해 실행, 태스크 큐, 이벤트, 스토리지, 컨텍스트 조립, 라이프사이클 훅이라는 여섯 개의 typed organisational interface를 둔다.
OS 커널이 하드웨어 차이를 숨기듯, OMC는 에이전트 런타임 차이를 조직 인터페이스 뒤로 숨긴다.
두 번째는 Talent Market이다.
OMC는 필요한 직무를 미리 모두 정의해 두는 대신, HR 에이전트가 Talent Market에서 적절한 에이전트를 찾고 후보를 제시하며 온보딩하는 구조를 택한다.
공식 Talent Market 설명에 따르면 Talent는 profile.yaml, skills/, tools/, DESCRIPTION.md를 포함하는 Git 저장소 패키지다.
즉 “에이전트 한 명”이 설치 가능한 구성 파일과 스킬, MCP 도구 정의, 설명 문서를 포함하는 배포 단위가 된다.
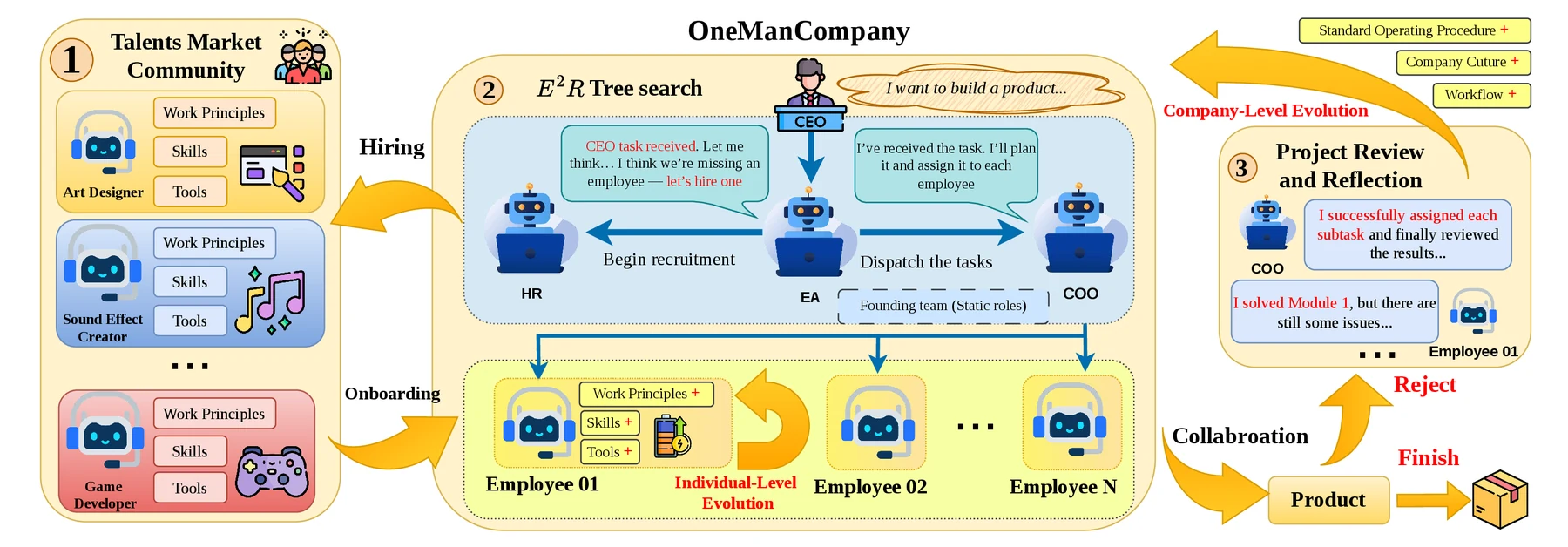
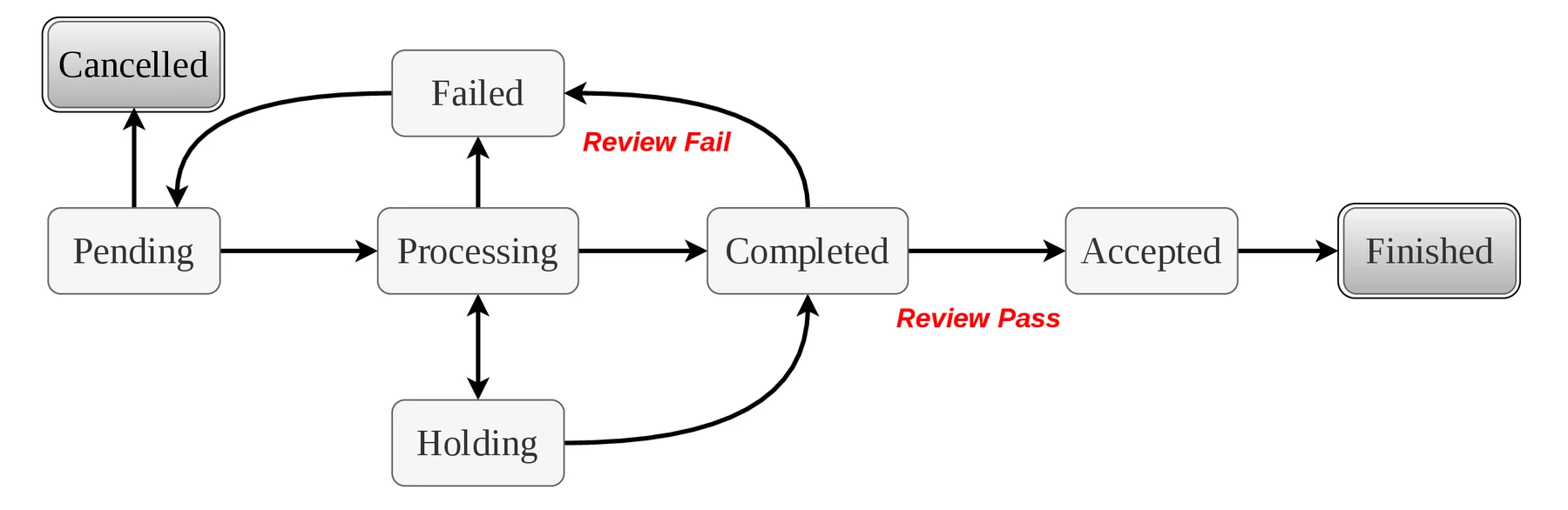
세 번째는 E²R tree search다.
OMC는 프로젝트 수행을 Explore, Execute, Review의 반복으로 본다.
Explore 단계에서는 태스크를 분해하고 필요한 직원을 할당하거나 채용한다.
Execute 단계에서는 실제 에이전트가 작업을 수행한다.
Review 단계에서는 결과를 상위 노드로 올리기 전에 감독자가 수락하거나 거절하고, 필요하면 재탐색이나 반복을 유도한다.
E²R은 MCTS와 비슷하게 트리를 확장하고 평가 신호를 다음 탐색에 반영하지만, 논문이 강조하듯 시뮬레이션 roll-out이나 UCB 선택을 쓰는 MCTS는 아니다.
여기서 실행은 실제 산출물을 만드는 실행이고, 보상은 터미널 reward가 아니라 명시적 supervisor review다.
트리에는 decomposition edge와 dependency edge가 함께 존재하고, 전체 실행 그래프는 DAG로 유지된다.
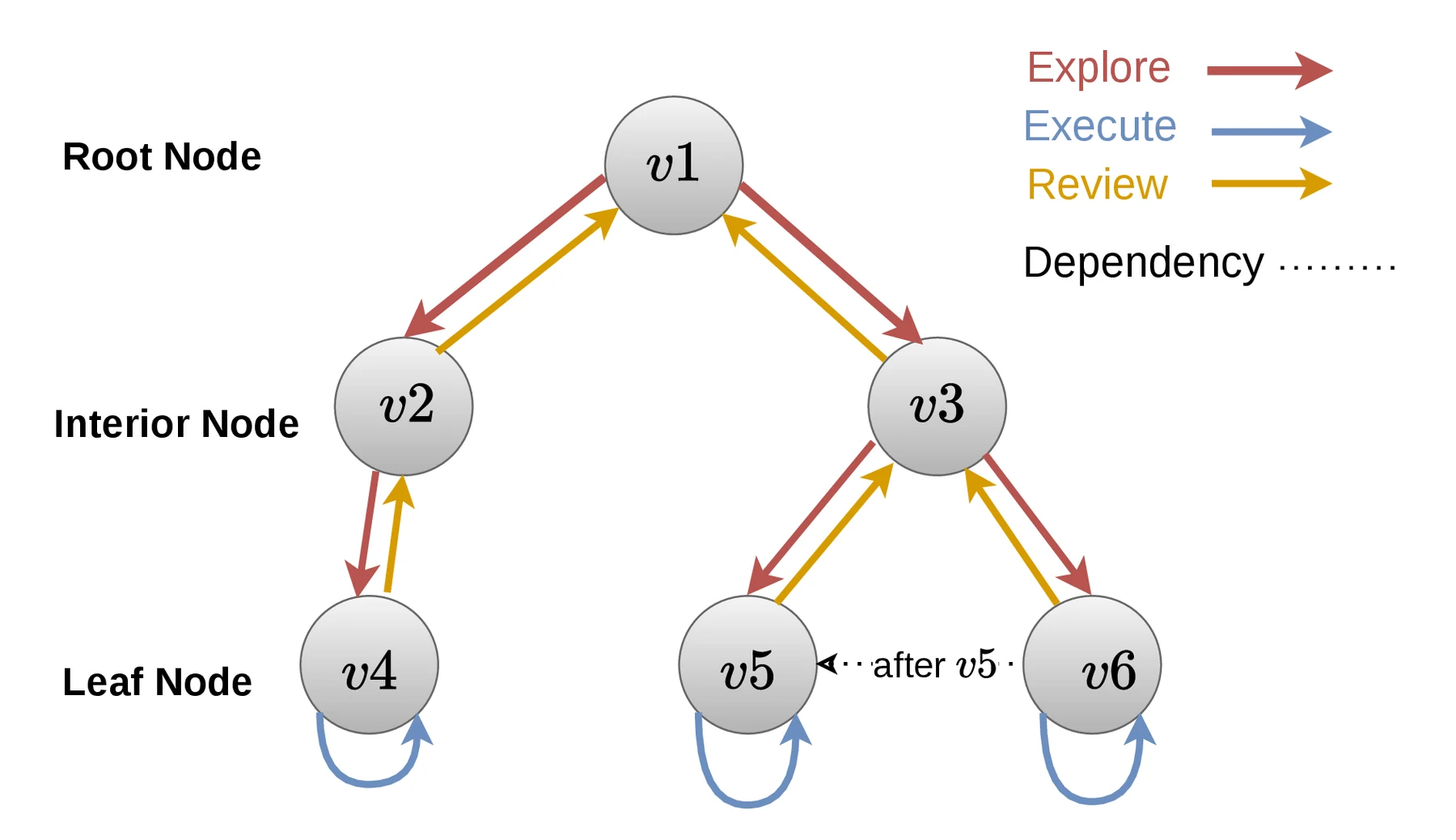
이 구조에서 특히 중요한 장치가 completed → accepted 게이트다.
에이전트가 작업을 끝냈다고 해서 바로 downstream 태스크가 시작되는 것이 아니라, supervisor가 결과를 수락해야 다음 단계로 전파된다.
논문은 bounded retry와 resource constraint, DAG 삽입 시 cycle detection, finite state machine을 통해 termination과 deadlock freedom을 보장한다고 주장한다.
마지막 축은 self-evolution이다.
개인 레벨에서는 post-task reflection, coaching, working principle refinement, skill accumulation을 통해 직원별 지식이 쌓인다.
조직 레벨에서는 프로젝트 회고, SOP 업데이트, 회사 문화 규칙, HR 성과 리뷰가 누적된다.
이 부분은 단순 메모리 저장소보다 더 강한 주장이다.
OMC는 “에이전트가 기억한다”가 아니라 “조직이 사람 회사처럼 리뷰하고 개선한다”는 형태로 학습 루프를 모델링한다.
공개된 근거에서 확인되는 점
정량 결과의 중심은 PRDBench다.
논문은 PRDBench를 50개의 project-level software development task와 20개 이상의 도메인으로 구성된 벤치마크로 설명한다.
각 태스크는 PRD, 평가 기준, 테스트 계획, 실행 가능한 평가 스크립트를 포함하며, 단순 코드 생성이 아니라 요구사항 해석, 태스크 분해, 구현, 검증까지 요구한다.
논문의 DEV mode 설정에서는 각 시스템이 PRD를 one-shot 입력으로 받고, 반복 피드백이나 외부 개입 없이 최종 산출물을 자동 평가한다.
OMC는 founding agent에 더해 HR이 Talent Market에서 Software Engineer, Software Architect, Code Reviewer를 채용하는 설정으로 평가됐다.
| 시스템 | 유형 | 성공률 | 비용 |
|---|---|---|---|
| Claude-4.5 | Minimal | 69.19% | 미보고 |
| GPT-5.2 | Minimal | 62.49% | 미보고 |
| CodeX | Commercial | 62.09% | 미보고 |
| Claude Code | Commercial | 56.65% | 미보고 |
| Qwen Code | Commercial | 39.91% | 미보고 |
| OMC | Multi-agent | 84.67% (+15.48) | $345.59 / 50 tasks |
이 숫자는 OMC가 표에 포함된 모든 baseline을 앞선다는 강한 신호다.
하지만 해석할 때 두 가지를 같이 봐야 한다.
첫째, baseline 비용이 보고되지 않아 cost-efficiency를 직접 비교할 수 없다.
둘째, OMC의 전체 비용은 50개 태스크에 $345.59, 태스크당 약 $6.91이다.
논문도 이 비용을 인정하고, 단순 질의에는 single-agent dispatch를 쓰고 복잡한 프로젝트에만 multi-agent coordination을 쓰는 adaptive dispatch를 언급한다.
사례 연구도 흥미롭다.
콘텐츠 생성 예시는 GitHub AI Agent weekly trend report를 만들고 이메일로 전달하는 작업을 한 문장 프롬프트에서 시작해, HR이 Researcher와 Writer를 채용하고, Researcher가 실제 저장소 링크와 요약을 모으고, Writer가 보고서를 작성하는 흐름을 보여준다.
논문은 이 파이프라인이 10분 미만, 약 $4.48 비용으로 완료됐다고 기록한다.
게임 개발 예시는 더 중요하다.
초기 산출물에서 sprite sheet 분할 문제가 발견되자, OMC는 단순 패치가 아니라 Art Designer에게 composite sprite sheet를 개별 이미지로 자르는 새 스킬을 만들어 다시 실행한다.
이 사례는 OMC가 내세우는 self-evolution 주장을 가장 잘 보여 준다.
실패가 생겼을 때 “다시 해봐”가 아니라, 조직의 능력 자체를 수정한다는 것이다.
오디오북 예시는 scriptwriting, image generation, voice synthesis, video assembly를 Novel Writer와 AV Producer가 나눠 수행한다.
논문은 16개 장면, 16개 voice-over track, 배경음악, 최종 영상 두 개를 $1.57 비용으로 만들었다고 기록한다.
자동 연구 survey 예시는 세 명의 specialist가 35개 seed paper, 17개 paper review, 8개 open problem, 11개 failure mode, 28개 system readiness benchmark, 931-line literature review framework, 3개 연구 아이디어를 만들고, 전체가 1시간 미만, $16.26, 15.9M token으로 완료됐다고 설명한다.
공개 구현 표면도 어느 정도 확인된다.
GitHub API 기준 1mancompany/OneManCompany 저장소는 2026-02-26 생성됐고, 조회 시점 기준 2026-05-12까지 push가 이어지고 있었다. stars 224, forks 41, open issues 6이며, GitHub API와 루트 LICENSE 모두 Apache-2.0을 가리킨다. latest release는 v0.7.73이고, release note는 provider pricing 표시와 Anthropic onboarding 관련 버그 수정을 언급한다.
패키징은 약간 더 복잡하다.
저장소의 package.json과 pyproject.toml은 0.7.77을 가리키지만, npm registry의 latest dist-tag는 0.7.73, dev dist-tag는 0.7.77이었다.
따라서 블로그 독자 관점에서는 “npx로 설치 가능한 공개 제품”이라고 말할 수 있지만, 정확한 안정 버전은 npm latest와 GitHub release를 기준으로 보는 편이 안전하다.
실행 요구사항은 README 기준 Node.js 18+와 Git이고, 첫 실행에서 UV와 Python 3.12, 의존성을 자동 설치한다고 설명한다.
실무 관점에서의 해석
OMC의 가장 큰 가치는 멀티 에이전트 시스템을 workflow orchestration이 아니라 workforce operation으로 바꿔 본다는 데 있다.
기존 프레임워크가 “어떤 노드가 어떤 메시지를 주고받는가”에 집중했다면, OMC는 “어떤 사람을 채용하고, 어떤 역할에 배치하고, 어떤 기준으로 결과를 수락하고, 실패 후 어떤 조직 지식을 남길 것인가”를 시스템의 1급 개념으로 올린다.
이 관점은 실무적으로 꽤 설득력이 있다.
실제 팀에서 에이전트를 도입할 때도 문제는 단일 모델 성능만이 아니다.
누가 리뷰할지, 어떤 도구 권한을 줄지, 어떤 업무 지식을 다음 프로젝트에 남길지, 특정 에이전트가 실패했을 때 교체할지 코칭할지, 서로 다른 에이전트 제품을 어떻게 한 팀 안에서 쓸지가 더 큰 운영 문제로 떠오른다.
OMC의 Talent–Container 분리는 이 운영 문제를 다루기 좋은 추상화다.
특히 “스킬에서 Talent로”라는 이동은 중요하다.
최근 에이전트 생태계에서 skill은 반복 업무를 패키징하는 단위로 빠르게 커지고 있다.
하지만 skill만으로는 조직이 되지 않는다.
여러 skill을 가진 어떤 주체가 어떤 역할을 맡고, 어떤 책임을 지며, 어떤 평가를 받고, 어느 런타임 위에서 실행되는지까지 묶어야 실제 팀 운영에 가까워진다.
Talent는 그 묶음을 에이전트 패키지로 끌어올리는 제안이다.
다만 한계도 분명하다.
첫째, 정량 평가는 PRDBench라는 소프트웨어 개발 벤치마크에 집중되어 있다.
콘텐츠, 게임, 오디오북, 연구 survey 사례는 범용성을 보여 주는 데 유용하지만, non-coding benchmark에서 체계적으로 검증된 것은 아니다.
둘째, self-evolution의 기여는 아직 분해돼 있지 않다.
논문은 one-on-one, retrospective, performance review, SOP 업데이트를 구현·배포했다고 설명하지만, 각 메커니즘이 성공률을 얼마나 올렸는지는 ablation으로 분리하지 않았다.
따라서 84.67%라는 숫자를 “조직 리뷰 구조 전체의 효과”로 볼 수는 있어도, “성과 리뷰가 몇 퍼센트 기여했다”처럼 읽으면 안 된다.
셋째, Talent Market은 강력한 만큼 공급망 위험을 함께 만든다.
Talent가 Git 저장소 단위로 skills, tools, MCP 설정, system prompt를 포함한다면, 그 안에는 코드 실행, 외부 API 접근, 권한 설정, 비용 구조, 라이선스 경계가 들어간다.
논문은 tool permission category와 typed interface를 제시하지만, 실제 marketplace가 커질수록 보안 리뷰, provenance, 서명, 샌드박싱, 비용 상한, 데이터 경계가 핵심 운영 문제가 될 것이다.
넷째, 회사 은유는 양날의 검이다.
HR, COO, performance review, PIP 같은 표현은 복잡한 에이전트 운영을 직관적으로 이해하게 해 주지만, 실제 조직의 사회적 맥락을 지나치게 단순화할 위험도 있다.
제품 관점에서는 재미있는 UX이고, 연구 관점에서는 강한 abstraction이다.
하지만 실무 도입에서는 은유가 아니라 typed interface, review gate, audit log, cost control이 얼마나 견고한지가 더 중요하다.
그럼에도 OMC가 던지는 질문은 좋다.
“에이전트를 몇 개 병렬로 돌릴 것인가”보다 더 중요한 질문은 “에이전트 노동력을 어떤 조직 구조로 관리할 것인가”일 수 있다.
MCP와 A2A가 도구와 통신의 표준화라면, OMC는 그 위에서 채용·배치·리뷰·학습이라는 운영 표준화를 시도한다.
멀티 에이전트 시스템이 실제 업무 인프라가 되려면, 결국 이런 조직 레이어가 필요해질 가능성이 높다.
한 줄로 요약하면, OneManCompany는 “AI가 회사를 대신 운영한다”는 마케팅 문구보다 이기종 에이전트를 채용 가능한 Talent로 추상화하고, E²R 리뷰 루프로 산출물과 조직 지식을 함께 관리하는 agent operating system 실험으로 보는 편이 훨씬 더 흥미롭다.