LLM에게 데이터베이스를 붙이면 곧바로 BI 에이전트가 되는 것처럼 보일 때가 많다. 하지만 실제 현장에서는 SQL을 쓸 수 있느냐 보다, 그 SQL이 조직의 의미 체계를 제대로 반영하느냐가 훨씬 더 어렵다. 같은 revenue라도 어떤 테이블을 기준으로 보고, 어떤 join 경로를 허용하고, 어떤 계산식을 표준으로 삼고, 어떤 객체는 아예 접근시키지 않을지를 정하지 않으면 모델은 문법적으로 그럴듯한 쿼리를 내놓아도 비즈니스적으로는 틀린 답을 만든다.
Canner/WrenAI가 흥미로운 이유는 바로 이 문제를 정면으로 다룬다는 점이다. 이 프로젝트는 자신을 단순한 text-to-SQL 앱이 아니라 **“The open context layer that gives AI agents grounded, governed SQL across 20+ data sources”**라고 정의한다. 다시 말해 핵심은 SQL 생성기 자체보다, 에이전트와 데이터 웨어하우스 사이에 semantic layer, memory, governed access, reusable project structure를 끼워 넣는 것에 있다.
내가 보기에 WrenAI의 진짜 포인트는 “LLM이 SQL을 잘 쓰게 하자”가 아니다. 더 중요한 것은 여러 에이전트와 여러 툴이 같은 데이터 의미를 공유하도록 만드는 운영 계층을 오픈소스로 제품화했다는 점이다. 최근의 agent stack에서 검색용 context layer가 중요해졌듯, 데이터 질의에서도 raw schema 위에 바로 에이전트를 올리는 대신 context-first query plane을 따로 두겠다는 발상이다.
무엇을 해결하려는가
WrenAI README가 던지는 문제 정의는 꽤 명확하다. 에이전트가 비즈니스 데이터에서 실패하는 이유는 SQL 문법을 몰라서가 아니라, warehouse가 무엇을 의미하는지 모르기 때문이라는 것이다. 실제 조직의 데이터는 보통 다음 문제를 함께 가진다.
- 비슷한 이름의 테이블과 컬럼이 중복된다.
- metric 정의가 SQL 파일, BI 대시보드, 사람 머릿속에 흩어져 있다.
- 어떤 join이 조직에서 허용된 관계인지 모델이 스스로 판단하기 어렵다.
- 운영/보안 관점에서 에이전트가 모든 warehouse 객체를 마음대로 뒤져서는 안 된다.
이 상황에서 LLM에 raw DB access를 주면, README 표현대로 “day one의 신입사원처럼” 추측하면서 질의하게 된다. WrenAI는 이를 막기 위해 MDL(Modeling Definition Language)로 entity, relationship, calculation, governed access pattern을 먼저 모델링하고, 이후의 query planning과 execution을 그 모델 위에서 수행한다.
이 문제 설정은 단순 text-to-SQL보다 한 단계 넓다. 공식 docs의 benefits_llm.md는 Wren AI Core가 LLM workflow에 주는 가치를 다섯 가지 이상으로 분해한다.
- shared business context
- more reliable planning for text-to-SQL
- better context for RAG and agent memory
- consistent answers across tools and agents
- governed access to data
- memory and self-learning
즉 이 프로젝트는 “질문 한 번에 SQL 한 번 생성”이 아니라, 여러 에이전트가 공통 semantic definition을 참조하며 점진적으로 더 안전하고 일관된 데이터 액션을 수행하는 환경을 만들려 한다.
핵심 아이디어 / 구조 / 동작 방식
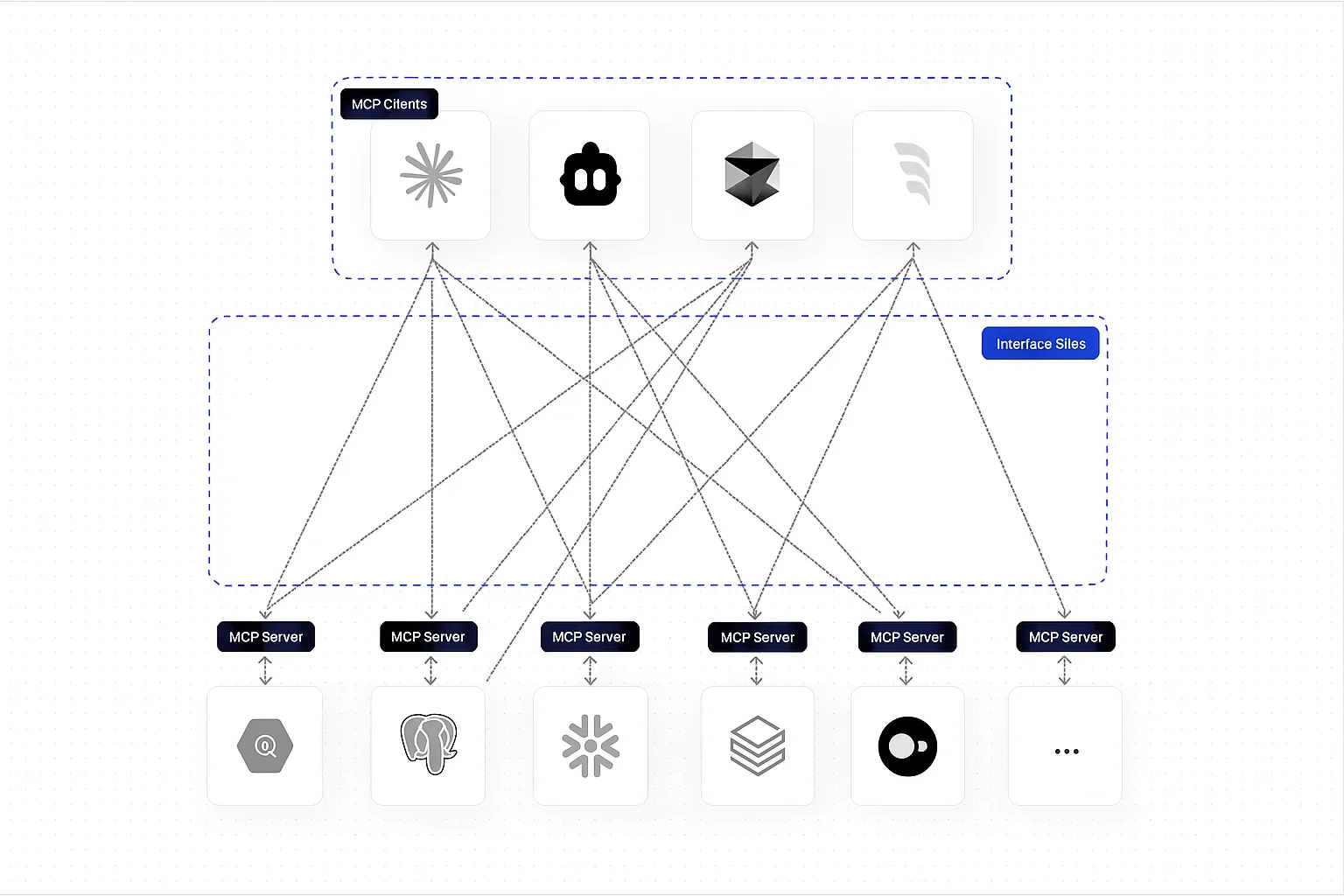
WrenAI를 이해할 때는 이 프로젝트를 하나의 앱보다 네 겹짜리 계층으로 보는 편이 훨씬 정확하다.
첫째는 semantic modeling layer다. 사용자는 YAML 기반 wren_project.yml, models/, views/ 구조 안에서 MDL을 정의한다. 여기서 비즈니스 엔티티, 관계, 계산식, curated dataset structure를 명시한다. 중요한 점은 이 레이어가 단순 스키마 카탈로그가 아니라 에이전트가 질의에 쓸 수 있는 합법적 의미 체계가 된다는 점이다.
둘째는 execution layer다. README와 core/wren/README.md에 따르면 Wren Engine은 Apache DataFusion과 Ibis 기반으로 semantic SQL layer를 제공하며, 20개 이상의 데이터 소스에 대해 계획과 실행을 수행한다. CLI 흐름도 꽤 분명하다.
wren context init
wren profile add my-db --ui
wren context build
wren --sql 'SELECT order_id FROM "orders" LIMIT 10'
이때 wren context build는 YAML 기반 프로젝트를 target/mdl.json으로 컴파일하고, 실제 질의는 raw schema 대신 이 manifest를 경유해 이뤄진다. 여기에 strict_mode와 denied_functions 같은 보안 정책도 붙일 수 있다. 즉 Wren은 단순 프롬프트 기법이 아니라 semantic plan + governed execution runtime에 가깝다.
셋째는 memory layer다. 이 부분이 특히 agent 시대와 잘 맞는다. 문서에 따르면 wren-engine[memory]를 설치하면 LanceDB 기반 memory 기능을 쓸 수 있고, wren memory index, fetch, store, recall 명령으로 schema context retrieval과 성공한 NL→SQL pair 재사용을 지원한다. 공식 문서가 강조하듯 모든 질문을 처음 보는 것처럼 처리하지 않고, 성공한 질의와 관련 schema context를 재호출하는 self-learning loop를 제공하는 셈이다.
넷째는 agent integration layer다. 이 저장소는 에이전트 연동을 README의 부차적 예시가 아니라 전면 UX로 취급한다. 가장 빠른 시작 경로가 npx skills add Canner/WrenAI --skill '*'이고, 이후 에이전트에게 wren-onboarding skill을 사용하라고 안내한다는 점이 상징적이다. sdk/wren-langchain은 LangChain/LangGraph 쪽에 WrenToolkit.from_project()를 제공하고, 여기서 wren_query, wren_dry_plan, wren_list_models에 더해 memory tools까지 붙일 수 있다. 즉 사람 사용자용 CLI를 먼저 만든 뒤 억지로 agent adapter를 덧댄 구조가 아니라, agent가 Wren project를 runtime substrate처럼 쓰는 구조를 아예 공식 지원한다.
| 레이어 | 공개 자료에서 확인되는 구성 | 역할 |
|---|---|---|
| Semantic modeling | wren_project.yml, models/, views/, MDL |
비즈니스 엔티티·관계·계산식을 reviewable context로 고정 |
| Execution runtime | Rust engine, Apache DataFusion, Ibis, wren --sql, dry-plan, dry-run |
semantic layer를 경유한 governed query planning/execution |
| Memory | wren memory index/fetch/store/recall, LanceDB |
schema retrieval과 성공 질의 재사용을 통한 self-learning |
| Agent integration | npx skills add, wren-onboarding, sdk/wren-langchain, WASM |
사람용 BI 도구를 넘어 agent runtime substrate로 확장 |
이 구조를 더 압축하면, WrenAI는 text-to-SQL 모델이라기보다 agent-facing semantic database operating layer라고 부르는 편이 더 맞다.

공개된 근거에서 확인되는 점
공개 저장소 메타데이터만 봐도 이 프로젝트는 꽤 빠르게 성숙하고 있다. 조회 시점 기준 GitHub 저장소는 약 15.1k stars, 1.7k forks, 2,421 commits, 140 branches, 438 tags를 보이고 있었다. 기본 언어는 Rust로 표시되지만, GitHub languages API를 보면 Rust와 Python 비중이 모두 크고 Shell/HTML/JavaScript/TypeScript가 함께 보인다. 즉 단일 바이너리 툴보다 engine + CLI + docs + SDK + packaging이 함께 움직이는 제품 저장소에 가깝다.
또 하나 중요한 신호는 2026-05-07 repo consolidation이다. 루트 README와 CHANGELOG.md는 이전 Canner/wren-engine 저장소가 현재 WrenAI 저장소의 core/로 합쳐졌고, 과거 WrenAI GenBI 앱은 legacy/v1 브랜치와 v1-final 태그로 보존된다고 밝힌다. 이건 단순 폴더 이동이 아니라, 프로젝트 정체성이 “GenBI app”에서 core context layer 중심 플랫폼으로 재정렬되고 있다는 뜻으로 읽힌다.
릴리스 구조도 흥미롭다. 최신 GitHub release는 wren-core-wasm-v0.3.0이고, .release-please-manifest.json에는 다음 패키지 버전이 명시돼 있다.
core/wren-core-py:0.5.0core/wren:0.5.0core/wren-core-wasm:0.3.0sdk/wren-langchain:0.1.0
이 분해는 WrenAI를 “하나의 앱”보다 여러 표면으로 배포되는 platform repo로 봐야 한다는 걸 잘 보여준다. Python CLI/SDK, Python bindings, browser WASM, LangChain integration이 각각 별도 패키지로 관리되기 때문이다.
라이선스 체계도 단순하지 않다. GitHub API의 top-level license 필드는 Other / NOASSERTION으로 보이지만, 실제 루트 LICENSE를 읽어보면 multi-license 구조다.
core/**,sdk/**,skills/**,examples/**: Apache-2.0docs/**: CC BY 4.0- future modules 일부: AGPL-3.0 가능성 사전 고지
즉 “Apache-2.0 오픈소스”라고 한 줄로 끝내기보다, repo path에 따라 라이선스가 나뉜다는 사실을 알고 보는 편이 정확하다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| GitHub repo metadata | 약 15.1k stars, 1.7k forks, 2,421 commits, Rust 중심 다언어 저장소 | 실험용 데모가 아니라 빠르게 성장 중인 OSS 플랫폼 |
| README / CHANGELOG | wren-engine를 core/로 병합, legacy/v1 보존 |
제품 중심축이 GenBI 앱에서 core context layer로 이동 |
| release-please manifest | wren/wren-core-py 0.5.0, wren-core-wasm 0.3.0, wren-langchain 0.1.0 |
CLI, bindings, WASM, agent SDK가 병렬 진화 |
| docs/core/README | docs site와 repo docs가 GitHub Actions로 sync | 문서 운영을 제품 파이프라인의 일부로 다룸 |
skills/wren-onboarding |
에이전트가 step-by-step으로 온보딩하도록 설계 | 사람 사용보다 agent-driven install UX를 적극 지원 |
| LICENSE | path-based multi-license | 엔터프라이즈 도입 시 라이선스 해석을 더 정교하게 해야 함 |
실무 관점에서의 해석
내가 보기엔 WrenAI의 가장 큰 의미는 semantic layer를 다시 AI agent 친화적으로 재포장했다는 데 있다. 기존 BI/analytics 세계에서 semantic layer는 새 개념이 아니다. 하지만 대부분은 인간 분석가, 대시보드, metric store, dbt 모델과의 관계 안에서 이해돼 왔다. WrenAI는 이 레이어를 Claude, Cursor, ChatGPT, internal copilot, LangGraph agent가 직접 공통으로 참조하는 open context layer로 다시 배치한다.
이건 실무적으로 꽤 중요하다. 많은 팀이 agentic analytics를 시도할 때 다음 순서로 실패한다.
- 모델에 DB schema를 많이 넣는다.
- 몇 개 데모 질문은 맞는다.
- join이 복잡해지고 metric 정의가 늘어나면 답변 일관성이 깨진다.
- 보안상 raw warehouse exposure가 문제 된다.
- 결국 prompt patch와 allowlist를 덕지덕지 붙인다.
WrenAI는 이 과정을 프롬프트 엔지니어링으로 수습하지 않고, context object 자체를 구조화된 프로젝트로 만들자고 제안한다. MDL이 바로 그 핵심이다. 이 접근이 설득력 있는 이유는, 에이전트에게 필요한 것은 사실 “더 많은 schema text”가 아니라 더 적지만 더 믿을 수 있는 business context이기 때문이다.
또 하나 실용적인 지점은 memory를 query learning plane으로 넣었다는 점이다. 많은 text-to-SQL 시스템이 매 질문을 stateless하게 처리하는데, WrenAI는 schema retrieval과 confirmed NL→SQL pair recall을 공식 기능으로 넣었다. 이는 RAG를 얹은 SQL assistant와 비슷해 보이지만, 더 정확히는 semantic layer 위에서 동작하는 query memory에 가깝다. 특히 팀이 반복적으로 비슷한 metric 질문을 던지는 환경에서는 이 차이가 꽤 커질 수 있다.
에이전트 통합 전략도 좋다. README가 가장 빠른 설치 경로로 npx skills add ...를 제시하고, LangChain toolkit이 system_prompt()까지 함께 제공하는 것은 단순 convenience를 넘는다. 프로젝트가 **“사람이 제품을 쓰는 법”보다 “에이전트가 제품을 operational substrate로 쓰는 법”**을 더 앞에 놓고 있다는 신호다. 최근 agentic tooling에서 이런 시점 전환은 생각보다 중요하다.
물론 한계도 있다. 첫째, semantic layer 구축 비용은 공짜가 아니다. MDL을 잘 정의하려면 결국 조직이 자기 metric과 관계를 어느 정도 명시적으로 합의해야 한다. 둘째, 20+ connector 지원은 매력적이지만 실제 운영에서는 datasource별 인증·권한·성능·SQL dialect 차이를 계속 관리해야 한다. 셋째, multi-license 구조와 fast-moving package split은 엔터프라이즈 도입 시 버전/정책 확인을 더 꼼꼼히 하게 만든다.
그럼에도 방향은 꽤 강력하다. 앞으로 BI agent의 경쟁력은 “SQL을 얼마나 그럴듯하게 생성하느냐”보다, 여러 agent와 tool이 같은 governed business context를 얼마나 안정적으로 공유하느냐로 이동할 가능성이 크다. 그런 관점에서 WrenAI는 또 하나의 text-to-SQL 데모가 아니라, AI agent 시대의 semantic query plane을 오픈소스로 밀어붙이는 프로젝트로 읽힌다.
한 줄로 요약하면
WrenAI는 LLM이 SQL을 쓰게 만드는 툴이라기보다, 비즈니스 의미를 MDL로 고정하고 그 위에 memory, governance, SDK, skills를 얹어 여러 에이전트가 같은 데이터 정의 위에서 움직이게 만드는 open context layer다.