언어 모델에서는 Transformer가 비교적 빠르게 표준이 됐지만, 비전에서는 이야기가 훨씬 더 꼬여 있었다.
이미지 쪽에는 이미 convolution이라는 강한 inductive bias가 있었고, locality와 translation invariance는 실제로 잘 작동했다.
반면 Vision Transformer는 처음 등장했을 때부터 구조적으로 더 단순했지만, 계산량은 거칠고 데이터와 pretraining에 훨씬 더 많이 의존하는 방식처럼 보였다.
그래서 한동안의 질문은 늘 같았다.
정말 비전에서도 결국 Transformer가 끝까지 이길 수 있느냐였다.
AI Engineer Europe에서 Roboflow의 Isaac Robinson이 발표한 How Transformers Finally Ate Vision은 이 질문에 대한 17분짜리 압축 답안에 가깝다.
발표의 핵심은 단순히 “ViT가 CNN보다 좋다”가 아니다.
오히려 비전에서 Transformer가 늦게 이긴 이유, 그리고 그럼에도 결국 승리한 이유를 architecture 자체가 아니라 pretraining, systems optimization, deployment economics까지 포함한 더 큰 흐름으로 설명한다.
ViT, Swin, ConvNeXt, Hiera, DINOv3, SAM3, RF100-VL, RF-DETR까지 이어지는 계보를 따라가 보면, 이제 비전의 경쟁축이 더 이상 “누가 더 자연스러운 inductive bias를 갖고 있나”에만 머물지 않는다는 점이 분명해진다.
무엇을 다루는 영상인가
이 영상은 AI Engineer 채널에 공개된 AI Engineer Europe 발표 녹화본으로, Roboflow의 Research Lead인 Isaac Robinson이 약 17분 동안 비전 백본의 계보를 빠르게 훑는다.
형식은 제품 데모보다 짧은 역사 정리 + 현재 실무 해석 + Roboflow식 해법 제안에 가깝다.
즉 순수 논문 리뷰라기보다, 왜 비전에서도 결국 Transformer가 foundation backbone이 되었는지에 대한 관점을 압축적으로 제시하는 발표다.
질문 자체는 단순하다.
왜 이미지처럼 강한 도메인 prior가 필요한 영역에서, 오히려 그 prior가 약한 Transformer가 최종 승자가 되었는가?
하지만 Robinson이 던지는 답은 구조 하나의 승리가 아니다.
대규모 self-supervised pretraining이 비전 inductive bias를 다시 학습했고, LLM 붐이 만든 attention 최적화와 accelerator-friendly infra가 그 구조를 실용적으로 만들었으며, 마지막으로 RF100-VL과 RF-DETR처럼 그 backbone을 현실적인 deployment envelope에 맞춰 다시 조정하는 기술이 붙으면서 판이 완전히 바뀌었다는 것이다.

핵심 아이디어 / 구조 / 시연 흐름
발표의 첫 축은 CNN의 강한 inductive bias 대 ViT의 약한 inductive bias라는 고전 구도다.
CNN은 locality와 translation invariance를 구조적으로 갖고 시작한다.
반면 ViT는 이미지를 patch token으로 쪼갠 뒤 attention에 넣는 비교적 단순한 구조다.
발표는 이 단순함이 처음에는 장점이 아니라 약점처럼 보였다고 짚는다.
특히 해상도가 올라갈수록 토큰 수가 빠르게 늘어나는 구조 때문에, naïve한 ViT는 비전에서 비용이 너무 큰 선택처럼 보이기 쉬웠다.
그다음은 “Transformer를 비전에 맞게 손보는” 단계다.
Swin은 윈도우 단위 attention과 shifted window를 통해 locality와 계산 효율을 되찾으려 했다.
ConvNeXt는 더 흥미롭다.
아예 convolution 쪽으로 되돌아가되, Transformer 시대에 효과적이었던 학습 관례와 블록 설계를 역수입한다.
여기까지는 비전 커뮤니티가 단순히 Transformer에 항복한 것이 아니라, 양쪽 진영이 서로의 장점을 흡수하며 중간지대를 넓혀 가던 시기로 읽힌다.
하지만 발표가 진짜로 힘을 주는 대목은 그다음이다.
Robinson은 Hiera와 MAE, 그리고 DINOv2/DINOv3 계열을 거치며 판이 바뀌었다고 본다.
과거에는 구조 안에 직접 넣어야 했던 비전 inductive bias를, 이제는 대규모 self-supervised pretraining이 다시 학습해 준다.
MAE는 빠진 patch를 복원하게 만들면서 구조에 없던 bias를 데이터에서 회수하고, DINO 계열은 단순 분류 성능을 넘어 feature map 자체를 풍부하게 만든다.
즉 ViT는 더 이상 “bias가 없는 구조”가 아니라, pretraining으로 bias를 다시 획득한 범용 backbone으로 바뀐다.
여기에 systems layer가 얹힌다.
FlashAttention 같은 attention 최적화, 더 성숙한 accelerator support, Transformer-friendly inference stack이 비전에도 그대로 흘러들어오면서, 한때는 구조적 약점처럼 보였던 계산비용이 점점 덜 치명적이 된다.
그래서 이 발표가 제시하는 결론은 분명하다.
비전용 Transformer의 승리는 architecture 단독 승리가 아니라, pretraining + infra + deployment adaptation의 결합 승리라는 것이다.
| 단계 | 대표 계열 | 무엇을 보완하려 했나 | 이 발표가 읽는 의미 |
|---|---|---|---|
| 고전 비전 | CNN / ResNet | locality, translation invariance를 구조적으로 내장 | 비전에서는 원래 inductive bias가 강한 쪽이 상식이었다 |
| 초기 전환 | ViT | 단순한 patch + attention으로 전역 상호작용 확보 | 구조는 단순하지만 계산량과 bias 부족이 약점처럼 보였다 |
| 중간 절충 | Swin | window attention으로 locality와 계산 효율 회복 | “Transformer를 비전에 맞게 손보는” 단계 |
| 역수입 실험 | ConvNeXt | Transformer 시대의 학습 관례를 convolution에 재적용 | CNN도 여전히 강력했음을 보여준 반격 |
| 단순화된 재정렬 | Hiera | 불필요한 장식을 빼고 pretraining으로 bias 복구 | 구조보다 pretraining 전략이 더 중요해지기 시작한 지점 |
| 기반모델 시대 | DINOv2/DINOv3, SAM3, RF-DETR | 풍부한 feature, 더 넓은 transfer, 실제 배포 성능 | ViT가 연구 구조를 넘어 foundation backbone으로 굳어진 단계 |
타임라인으로 보는 핵심 구간
이 영상에는 공식 chapter가 없지만, transcript와 슬라이드 전개를 기준으로 하면 핵심 흐름은 비교적 명확하게 나뉜다.
| 시간 | 구간 | 화면에서 주로 보이는 것 | 발표의 핵심 주장 |
|---|---|---|---|
| 00:14–03:22 | CNN vs ViT 문제 설정 | 타이틀 슬라이드와 CNN/ViT 비교 설명 | ViT가 처음엔 더 비싸고 비전 친화적이지 않아 보였다는 문제를 제기 |
| 03:22–05:11 | Swin의 locality 복원 | 윈도우 기반 attention 설명 슬라이드 | Transformer도 locality를 구조적으로 다시 주입하려는 시도가 있었다 |
| 05:13–07:14 | ConvNeXt와 Hiera 전환 | conv 재설계와 bias 제거/복구 논리 | 중요한 것은 구조 장식보다 어떤 bias를 어디서 회수하느냐라는 점 |
| 07:27–10:24 | MAE·DINOv3·FlashAttention | feature map 예시와 pretraining/infra 논의 | ViT-specific pretraining과 LLM 인프라가 Transformer의 약점을 약화시켰다 |
| 10:42–12:36 | SAM 계보와 비용 문제 | SAM 계열과 백본 계보 설명 | massively pretrained ViT가 강력하지만, 그대로는 너무 무겁고 비싸다 |
| 12:38–15:11 | RF100-VL·RF-DETR 해법 | benchmark, latency/accuracy, tunable knobs | foundation backbone을 현실 하드웨어에 맞게 번역하는 능력이 더 중요해졌다 |
| 15:22–16:44 | Q&A | 영상·JEPA 관련 질의응답 | 다음 경쟁은 멀티모달·비디오 pretraining으로 확장될 수 있다 |
이 타임라인이 중요한 이유는, 발표가 단순한 backbone 역사 요약이 아니라 연구 구조 → pretraining → infra → deployment라는 네 개 층을 차례대로 밟아 내려간다는 점을 잘 보여주기 때문이다.
즉 “왜 Transformer가 이겼는가”라는 질문에 대해, 구조적 미학이 아니라 학습 규모와 시스템 최적화가 그 구조를 실무적으로 밀어줬다는 쪽으로 논리를 조립한다.
영상과 연결 자료에서 확인되는 점
강연 transcript에서 직접 확인되는 주장 몇 가지는 분명하다.
첫째, Robinson은 ViT의 최종 승인을 설명할 때 구조적 우월성보다 VIT-specific pretraining의 누적 효과를 핵심 원인으로 둔다.
둘째, DINOv3류의 self-supervised pretraining이 feature map의 semantic richness를 크게 끌어올렸다고 설명한다.
셋째, SAM 계열의 backbone 진화도 결국 heavily pretrained ViT 쪽으로 다시 기울었다고 해석한다.
넷째, 발표 후반에서는 SAM3가 강력하지만 무겁고, deployment flexibility가 부족한 one-size-fits-all 모델일 수 있다는 비판을 명시적으로 제기한다.
이 가운데 실무적인 뒷받침이 가장 잘 잡히는 부분은 Roboflow의 공개 자산이다.
RF100-VL 공식 저장소는 이 벤치마크를 100개의 멀티도메인 object detection 데이터셋으로 설명하며, flora/fauna, sport, industrial, document, medical/laboratory, aerial, miscellaneous 등 여러 도메인을 한 벤치마크 표면에 묶는다.
즉 발표에서 말하는 “foundation model transfer를 실제 downstream 다양성 위에서 다시 봐야 한다”는 문제의식은 단순 수사만이 아니라, Roboflow가 실제로 공개한 benchmark 설계와 맞물려 있다.

RF-DETR 공개 저장소도 같은 방향을 보여준다.
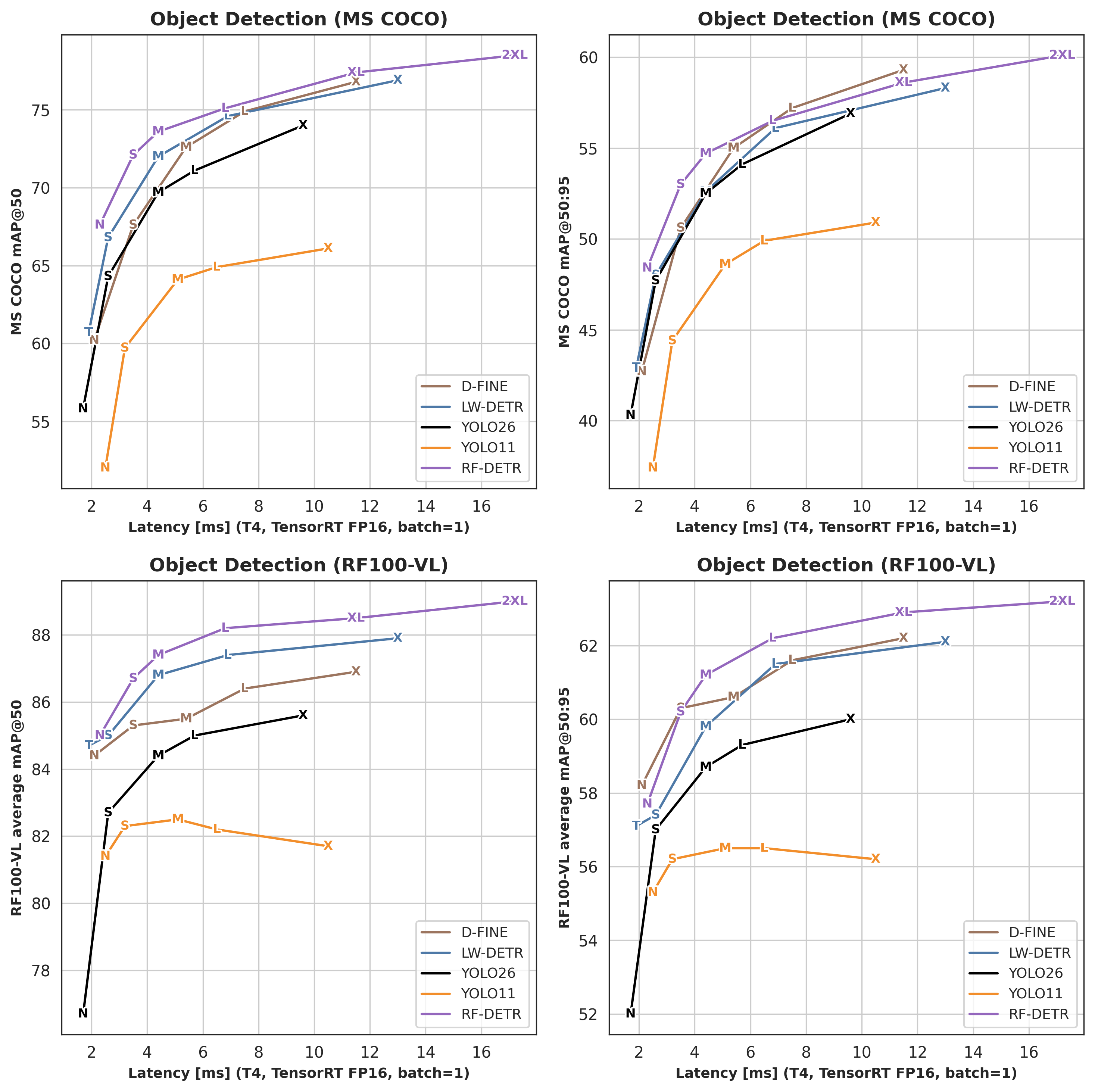
GitHub README 기준 RF-DETR은 DINOv2 vision transformer backbone 위에 구축된 실시간 detection/instance segmentation 아키텍처로 소개되며, COCO와 RF100-VL에서 accuracy-latency trade-off를 전면에 내세운다.
벤치마크 수치는 NVIDIA T4, TensorRT, FP16, batch size 1 조건으로 제시돼 있어 단순 연구 수치보다 deployment surface를 강하게 의식한 자료다.
저장소 메타데이터상 roboflow/rf-detr는 2025년 3월 생성 이후 현재 약 6.9k stars, 887 forks, 다수의 태그와 릴리스를 유지하고 있고, 기본 브랜치는 develop이다.
즉 이것은 아이디어 메모 수준이 아니라, 실제 사용자와 배포 경로를 가진 공개 프로젝트다.
영상 후반의 Roboflow 파트는 이 공식 자료와도 잘 연결된다.
12분대 후반 이후의 슬라이드에서는 RF100-VL과 RF-DETR을 단순 모델 소개가 아니라 foundation backbone을 target hardware와 target data에 맞게 변형하는 패키징 전략으로 설명한다.
즉 RF-DETR은 “Transformer가 비전에서 이겼다”는 결론의 종착점이 아니라, 그 승리를 edge/real-time/production 쪽으로 다시 번역하는 한 가지 구현으로 읽는 편이 맞다.
라이선스 구조도 흥미롭다.
RF-DETR 저장소와 오픈소스 rfdetr 패키지는 Apache 2.0으로 공개되지만, README는 일부 Plus 컴포넌트가 별도 PML 1.0 라이선스를 따른다고 분리해 적는다.
이건 “Transformer backbone이 강해졌다”는 이야기와 별개로, 실제 비전 기반모델 시대에는 오픈소스 모델, 상용 확장, 배포 스택이 함께 얽힌다는 사실을 보여준다.
다시 말해 비전 Transformer의 승리는 논문 승리가 아니라, 이미 제품 패키징과 사업 모델까지 닿아 있는 승리다.
실무 관점에서의 해석
내가 보기에 이 발표의 가장 좋은 점은 “Transformer가 CNN보다 좋다”는 단순 구호를 반복하지 않는다는 데 있다.
오히려 왜 CNN이 한동안 계속 의미 있었는지를 인정한 뒤, 그 장점을 이제는 구조보다 pretraining과 transfer에서 회수할 수 있게 됐다는 흐름을 보여준다.
이 해석은 중요하다.
왜냐하면 실제 팀이 모델을 고를 때는 더 이상 “convolution이냐 attention이냐” 같은 교과서식 대립보다, 어떤 backbone이 더 넓은 downstream 표면을 커버하고, 어떤 inference stack과 hardware path를 공유하며, 어떤 fine-tuning 전략으로 재활용될 수 있는가를 먼저 보기 때문이다.
특히 비전에서 foundation model이 진짜로 자리 잡으려면 두 가지가 동시에 필요하다.
하나는 DINOv2/DINOv3, MAE처럼 generic representation을 크게 끌어올리는 pretraining이고, 다른 하나는 RF100-VL이나 RF-DETR처럼 그 representation을 특정 deployment envelope에 맞게 다시 압축하고 최적화하는 방법이다.
발표는 바로 이 두 층을 이어 붙인다.
그래서 이 영상은 “ViT가 이겼다”는 선언보다, 이제 비전의 핵심 경쟁력이 backbone 발명보다 backbone 활용과 재배치에 있다는 점을 더 설득력 있게 보여준다.
또 하나 눈에 띄는 점은, 이 발표가 foundation model의 승리를 곧바로 “모든 문제가 끝났다”로 해석하지 않는다는 것이다.
12분 이후부터는 오히려 승리한 backbone이 너무 무거워졌기 때문에, 이제는 flexibility가 새로운 병목이라고 말한다.
SAM3의 800M 파라미터와 T4 기준 300ms 언급, RF100-VL의 전이 평가, RF-DETR의 speed/accuracy family 구성은 모두 같은 방향을 가리킨다.
즉 다음 경쟁은 더 강한 backbone 하나를 발명하는 것이 아니라, 이미 강해진 backbone을 얼마나 다양한 전력·메모리·지연 시간 제약으로 번역하느냐에 있다.
물론 한계도 있다.
이 발표는 17분짜리 요약이기 때문에 Swin·ConvNeXt·Hiera·DINOv3 각각의 수치와 반례를 세세하게 따지지는 않는다.
또 SAM3의 parameter/latency나 Roboflow의 speedup 수치는 영상 속 주장과 동반 공개자료를 함께 읽어야 하므로, 제품 의사결정에 그대로 옮길 때는 원 논문·벤치마크 문서·재현 환경을 다시 확인하는 편이 안전하다.
그럼에도 방향성만큼은 분명하다.
비전에서 Transformer의 승리는 늦었지만, 한 번 전환점이 만들어진 뒤에는 backbone 구조 하나가 아니라 pretraining, infra, deployment stack 전체를 끌고 들어온 승리였다.
이 지점에서 남는 질문도 자연스럽다.
다음 경쟁은 “Transformer냐 아니냐”가 아니라, 그렇게 만들어진 거대한 시각 backbone을 얼마나 싸고 빠르고 유연하게 task-specific product로 바꿀 수 있느냐일 가능성이 크다.
그리고 바로 그 지점에서 Roboflow가 RF100-VL과 RF-DETR로 던지는 메시지는 꽤 선명하다.
비전의 미래는 더 강한 backbone 하나보다, foundation backbone을 다양한 현실 세계 제약으로 번역하는 능력에 달려 있다.