오픈모델 경쟁에서 이제 더 흥미로운 질문은 “누가 더 큰 모델을 내놓았는가”보다 적은 활성 계산량으로 어디까지 reasoning 성능을 끌어올릴 수 있는가에 가깝다.
특히 수학, 코딩, 장기 추론처럼 test-time compute를 더 태울수록 성능이 올라가는 작업에서는 총 파라미터보다도 활성 파라미터, routing 안정성, 긴 추론을 다루는 harness 설계가 훨씬 중요해진다.
Zyphra가 공개한 ZAYA1-8B는 이 지점을 정면으로 겨냥한 릴리스다.
공식 블로그와 기술 보고서, Hugging Face 모델 카드 기준으로 이 모델은 roughly 0.7B 안팎의 활성 파라미터와 8B급 총 파라미터를 갖는 reasoning-focused mixture-of-experts 모델이다.
Zyphra는 이 모델을 단순히 “작은 MoE”로 소개하지 않는다.
대신 AMD Instinct MI300 스택에서 end-to-end 학습했다는 점, Compressed Convolutional Attention(CCA)·MLP router·learned residual scaling을 조합한 MoE++ 계열 구조, 그리고 Markovian RSA라는 test-time compute 방법론까지 한 번에 묶어 지능 밀도(intelligence density) 자체를 상품처럼 내세운다.
내가 보기에 ZAYA1-8B의 핵심은 8B 모델 하나를 잘 만든 데 있지 않다.
더 본질적인 메시지는, Zyphra가 reasoning 모델 경쟁을 모델 아키텍처 + 학습 인프라 + post-training + inference harness의 공동 설계 문제로 보고 있다는 점이다.
그래서 이 모델은 파라미터 수보다 “작은 활성 계산량으로 frontier 근처까지 얼마나 올라가느냐”를 보여 주는 데 더 많은 지면을 쓴다.
무엇을 해결하려는가
ZAYA1-8B가 풀려는 첫 번째 문제는 작은 모델의 reasoning ceiling이다.
일반적으로 4B~8B급 공개 모델은 배포 비용은 낮지만, 어려운 수학·코딩·장기 추론에서는 금방 한계를 드러낸다.
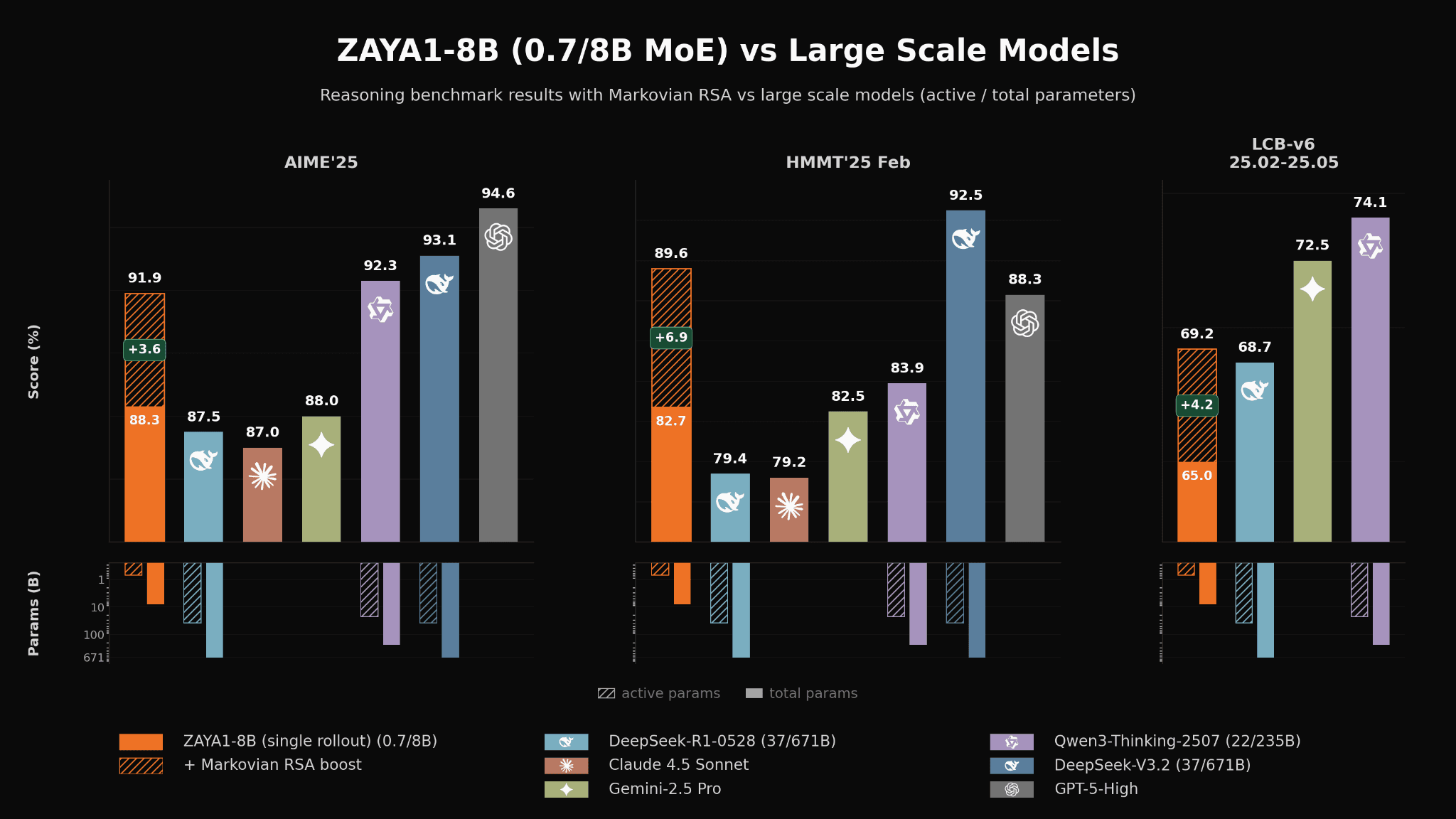
Zyphra의 블로그는 ZAYA1-8B가 “under 1 billion active parameters”로도 Mistral-Small-4-119B 같은 훨씬 큰 공개 모델과 경쟁하고, 일부 항목에서는 DeepSeek-R1-0528, Gemini 2.5 Pro, Claude 4.5 Sonnet 같은 훨씬 큰 reasoning 모델과도 비교 가능한 수준까지 올라간다고 주장한다.
즉 목표는 작은 모델을 싸게 돌리는 것이 아니라, 작은 활성 예산으로 큰 모델의 추론 영역을 얼마나 침범할 수 있는가다.
둘째는 test-time compute를 길게 태울수록 문맥 길이와 비용이 폭발하는 문제다. reasoning 모델은 여러 candidate trace를 생성하고 비교할수록 좋아지지만, 그대로 밀어붙이면 intermediate chain-of-thought가 길어지고 context window 부담이 커진다.
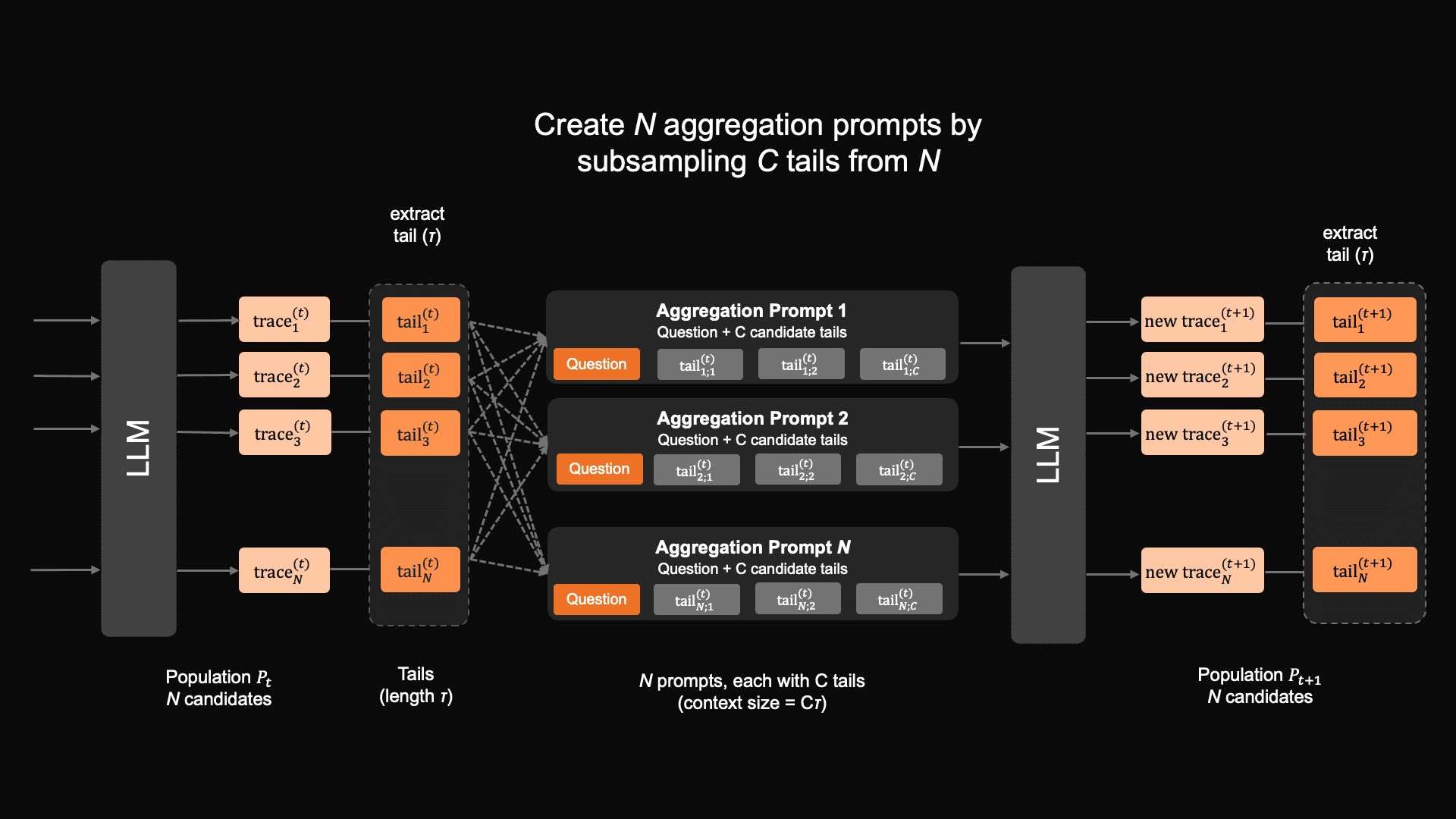
Zyphra는 이 문제를 Markovian RSA로 다룬다.
병렬 trace 생성과 recursive self-aggregation을 결합하되, 각 단계에서 이전 추론의 tail segment만 다음 단계로 넘겨 context를 bounded하게 유지한다는 발상이다.
셋째는 NVIDIA 중심 서사에 가려져 있던 학습 인프라 다변화다.
이 페이지가 굳이 trained on AMD를 제목에 걸고, pretraining 섹션에서 1,024개 MI300X 노드와 AMD Pensando Pollara interconnect, IBM과 만든 custom cluster를 명시하는 것은 우연이 아니다.
ZAYA1-8B는 모델 자체의 성능뿐 아니라, frontier급 reasoning 모델 학습이 AMD 스택에서도 가능하다는 산업적 메시지를 함께 싣고 있다.
핵심 아이디어 / 구조 / 동작 방식
구조적으로 보면 ZAYA1-8B는 “작은 활성량의 reasoning MoE”라는 익숙한 포맷 위에 꽤 공격적인 설계 선택을 올려놓은 모델이다.
기술 보고서와 Hugging Face 공개 자료를 종합하면 핵심 포인트는 네 가지다.
1) MoE++ 계열의 초소형 활성 구조
기술 보고서 abstract는 ZAYA1-8B를 700M active / 8B total 파라미터 모델로 설명하고, Hugging Face README는 760M active / 8.4B total이라고 적는다.
표현에는 약간의 반올림 차이가 있지만, 공통 메시지는 분명하다.
이 모델은 대략 0.7B 안팎의 활성 계산량으로 8B급 총 용량을 쓰는 초소형 활성 MoE다.
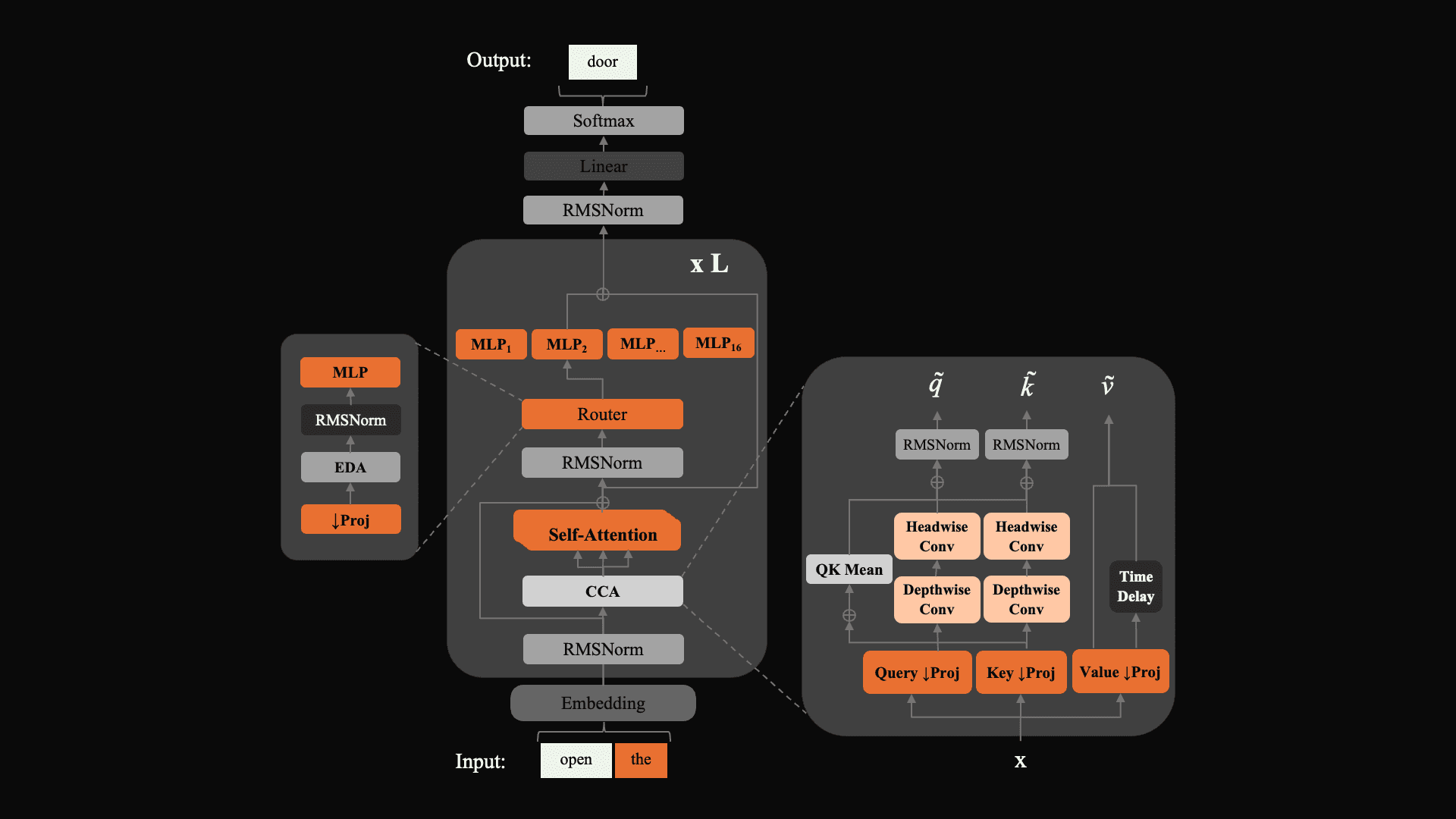
실제 config.json에는 num_hidden_layers: 80, hidden_size: 2048, num_experts: 16, moe_router_topk: 1, max_position_embeddings: 131072, cca: true, scale_residual_merge: true가 드러난다.
즉 이 모델은 단순히 expert를 많이 쌓은 MoE가 아니라, 적은 active path 위에 깊이를 깊게 가져가고 routing과 residual 제어를 함께 최적화한 구조로 읽는 편이 맞다.
2) CCA + MLP router + learned residual scaling
Zyphra 블로그가 가장 앞세우는 아키텍처 차별점은 세 가지다.
- Compressed Convolutional Attention (CCA): Zyphra가 별도 논문으로 연결한 attention 변형
- MLP-based router: linear router보다 routing stability를 높이기 위한 expert 선택기
- learned residual scaling: depth가 깊어질수록 residual norm이 커지는 문제를 적은 비용으로 제어
이 조합의 핵심은 MoE의 성능 병목을 expert 개수 자체보다 routing 안정성, 깊이 방향 제어, attention 효율에서 풀겠다는 데 있다.
특히 topk=1 routing과 16 experts라는 설정을 함께 보면, ZAYA1-8B는 “많은 expert를 넓게 섞는 모델”보다는 작고 깊은 active path를 얼마나 안정적으로 다루느냐에 더 초점을 둔 모델로 보인다.
3) AMD 기반 pretraining과 full-stack co-design
Pretraining 섹션은 이 모델을 단순 체크포인트보다 인프라 데모로도 보게 만든다.
공식 블로그에 따르면 ZAYA1-8B는 1,024개 MI300X 노드, AMD Pensando Pollara interconnect, IBM과 구축한 custom cluster 위에서 pretraining을 수행했다.
이는 추론 성능만이 아니라, 프런티어급 학습 파이프라인이 AMD 가속기와 네트워킹 생태계에서도 현실화되고 있음을 보여 주는 사례다.
이 점은 실무적으로 꽤 중요하다.
최근 오픈모델 생태계가 아무리 활발해도 학습 스택은 여전히 NVIDIA 중심으로 읽히기 쉽다.
ZAYA1-8B는 모델 릴리스이면서 동시에 “AMD에서도 reasoning MoE를 끝까지 학습할 수 있다”는 공급망·클러스터 메시지를 함께 내보낸다.
4) Markovian RSA라는 harness-aware reasoning 전략
ZAYA1-8B의 가장 독특한 부분은 아마 Markovian RSA다.
Zyphra는 이 방법을 parallel trace generation, recursive self-aggregation, fixed-duration chunking을 결합한 TTC(test-time compute) 방식으로 설명한다.
여러 추론 trace를 병렬로 만든 뒤, 각 trace의 tail segment만 남겨 다음 aggregation 단계의 seed로 넘기기 때문에 context window를 무한정 늘리지 않고도 긴 reasoning loop를 구성할 수 있다는 것이다.
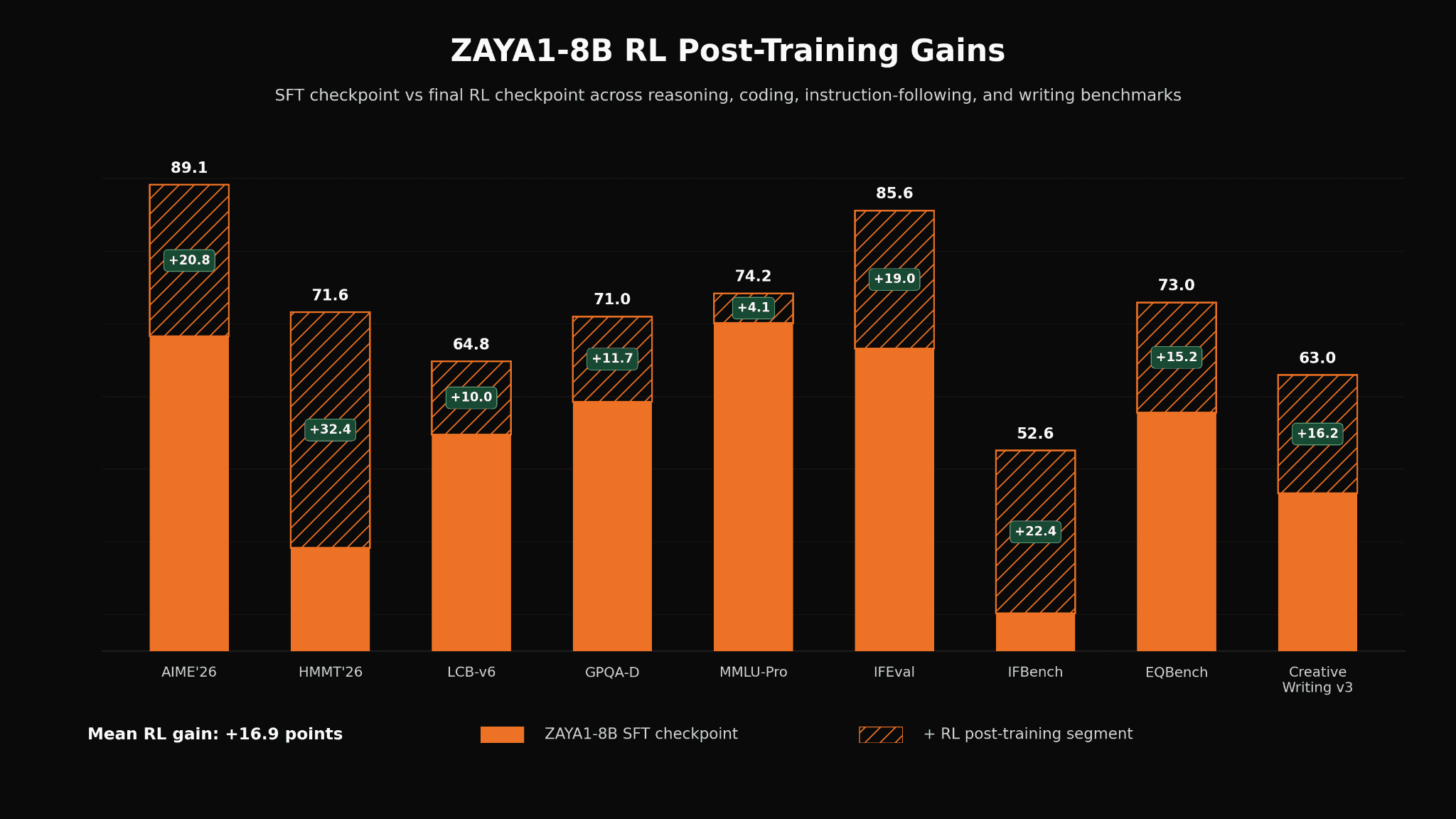
더 흥미로운 점은 이 harness가 단순 inference trick이 아니라 SFT와 RL 과정에서 모델이 이 aggregation prompt와 chunking 행동을 이해하도록 함께 학습됐다는 점이다.
Zyphra는 같은 방법을 Qwen3-4B-Thinking-2507에 적용했을 때 uplift가 훨씬 작았다고 적는데, 이는 TTC 성능이 단순 wrapper보다 모델과 harness의 공동 설계 결과임을 시사한다.
| 레이어 | 공개 자료에서 확인되는 구성 | 실무적 의미 |
|---|---|---|
| Core model | 약 0.7B active / 8B급 total, 80 layers, 16 experts, top-1 routing | 작은 활성 계산량으로 깊은 reasoning path를 구성 |
| Attention + routing | CCA, MLP-based router, learned residual scaling | attention 효율·routing 안정성·깊이 제어를 함께 최적화 |
| Training stack | 1,024 MI300X, Pollara interconnect, IBM-built cluster | AMD 스택에서도 대형 reasoning 학습이 가능함을 시사 |
| Inference strategy | Markovian RSA, bounded context chunking, self-aggregation | 긴 추론을 context 폭증 없이 반복하는 TTC 설계 |
| Deployment surface | Zyphra Cloud, Hugging Face open weights, vLLM/transformers fork 필요 | 공개는 되었지만 아직 vanilla serving보다는 전용 스택 친화적 |
공개된 근거에서 확인되는 점
가장 직접적인 공개 근거는 Hugging Face README의 benchmark table과 Zyphra 블로그의 headline claim이다.
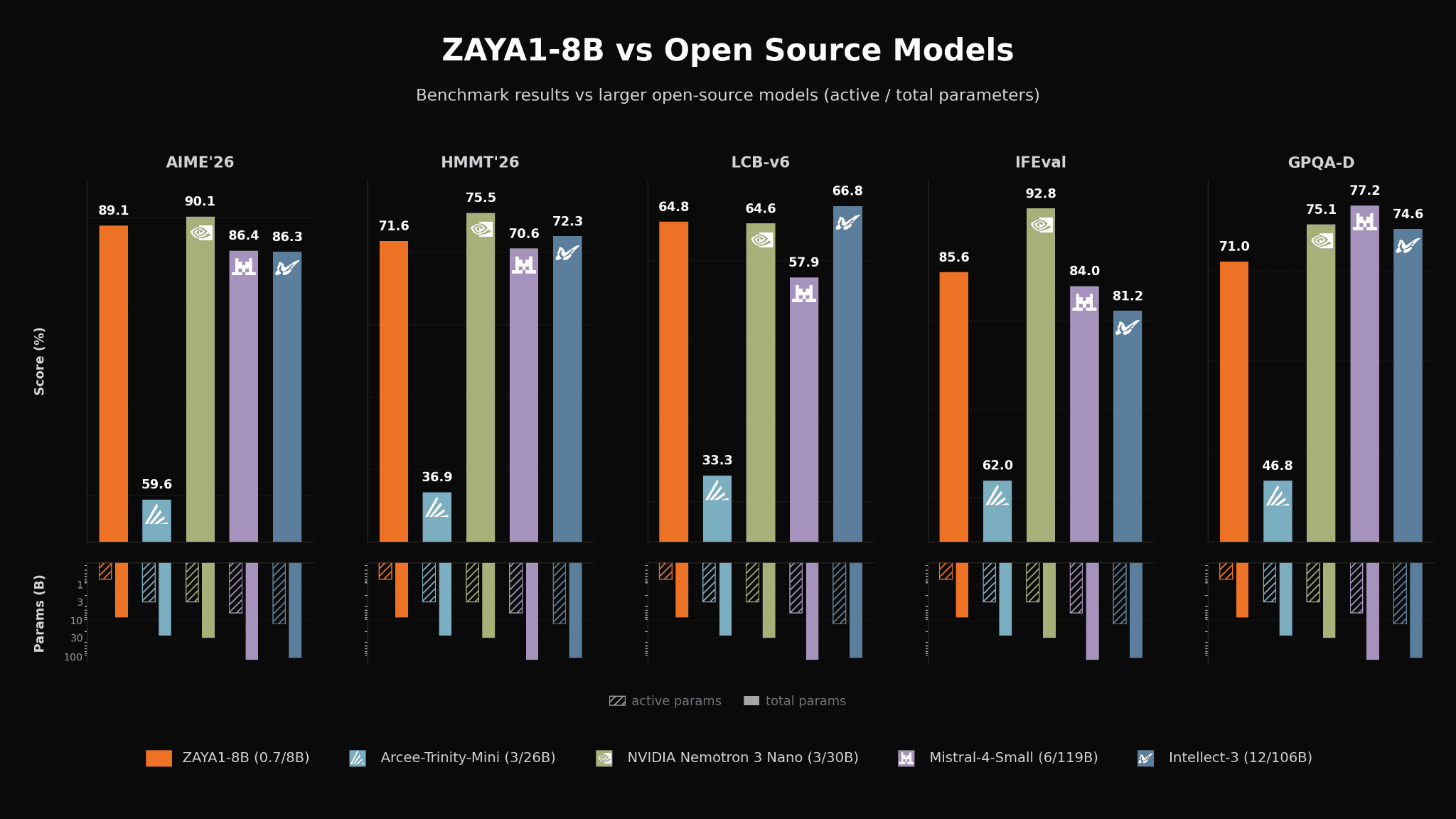
In-class 비교에서 ZAYA1-8B는 Qwen3-4B-Thinking-2507, Qwen3.5-4B, Gemma-4-E4B-it 같은 비슷한 체급 모델과 비교된다.
| 비교 축 | ZAYA1-8B | 비교군 해석 |
|---|---|---|
| AIME’26 | 89.1 | Qwen3-4B-Thinking-2507 77.5, Qwen3.5-4B 84.5보다 높음 |
| HMMT Feb.‘26 | 71.6 | Qwen3-4B-Thinking-2507 60.8, Qwen3.5-4B 63.6보다 높음 |
| IMO-AnswerBench | 59.3 | 같은 체급 공개 reasoning 모델 대비 우위 |
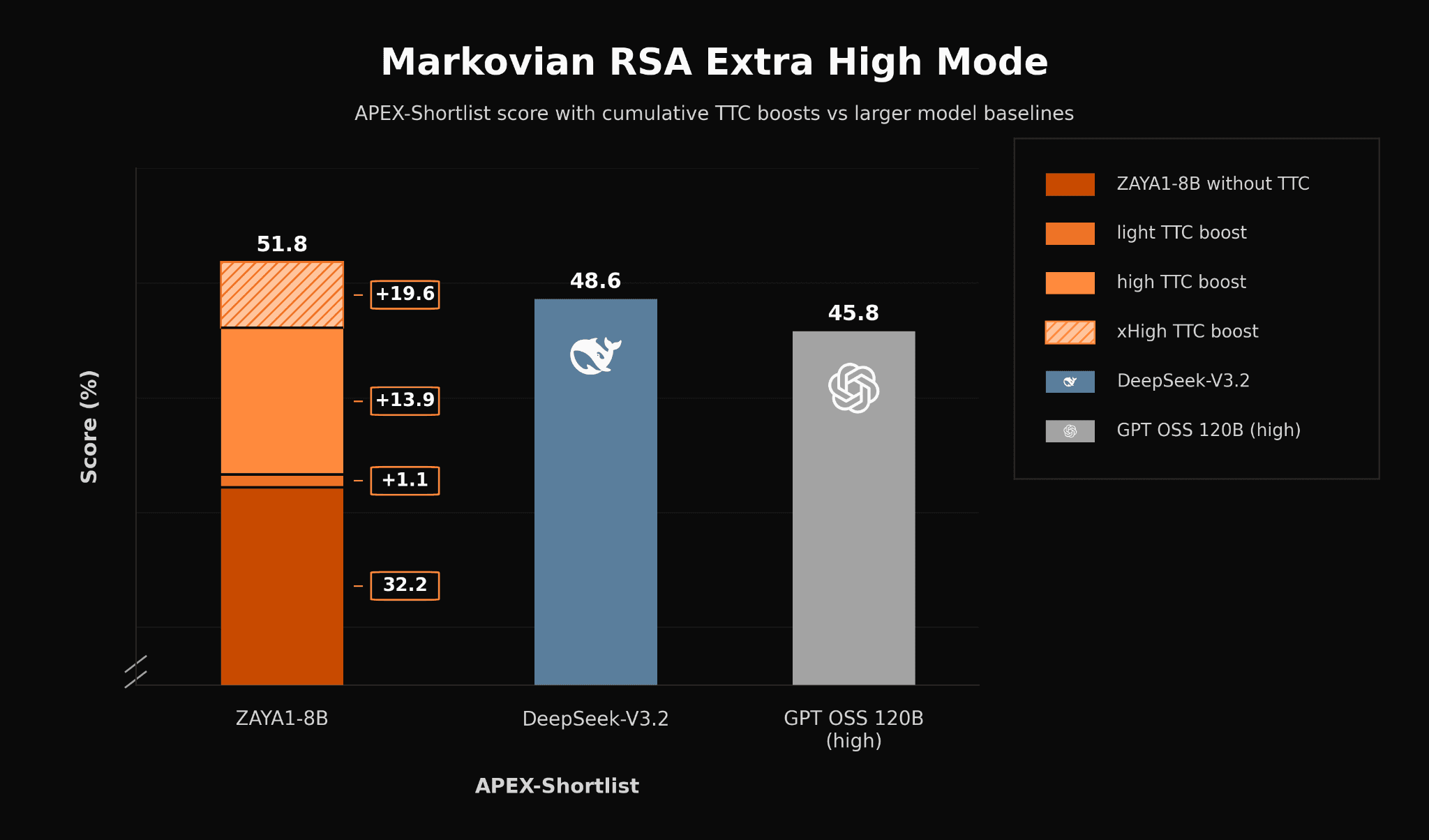
| APEX-shortlist | 32.2 | Qwen3-4B-Thinking-2507 16.9, Gemma-4-E4B-it 6.1보다 높음 |
| LiveCodeBench-v6 | 65.8 | Qwen3-4B-Thinking-2507 54.2, Gemma-4-E4B-it 54.2보다 높음 |
| GPQA-Diamond | 71.0 | Qwen3.5-4B 76.2보다 낮아 지식 축은 절대 우위 아님 |
| IFEval | 85.58 | instruction following은 Qwen 계열과 비슷하거나 약간 낮음 |
| IFBench | 52.56 | reasoning/수학 대비 지시 이행은 상대적으로 덜 인상적 |
즉 공개 표만 보면 ZAYA1-8B의 진짜 강점은 수학·코딩·TTC 친화형 reasoning에 있다.
반면 instruction following이나 broad agentic benchmarks에서는 모든 비교군을 압도한다고 보긴 어렵다.
이건 오히려 솔직한 신호다.
Zyphra는 이 모델을 범용 만능 모델보다 reasoning specialist로 포지셔닝하고 있다.
Scaling comparison도 흥미롭다.
README 표에서 ZAYA1-8B는 total 26B~119B급 공개 reasoning 모델들과 비교될 만큼 자신감을 보인다.
예를 들어 AIME’26 89.1, HMMT’26 71.6, GPQA-Diamond 71.0, MMLU-Pro 74.2는 8B total 모델 치고 상당히 높은 편이고, 일부 벤치마크에서는 Mistral-Small-4-119B를 앞선다.
다만 N3-Nano-30B나 Qwen3-Next-80B-A3B-Think 같은 더 큰 reasoning 모델이 여전히 우세한 항목도 분명해, 이 모델을 frontier absolute winner로 보기는 어렵다.
TTC 쪽 headline은 더 공격적이다.
Zyphra 블로그는 Markovian RSA를 사용하면 40K intermediate CoT budget과 4K forwarded tail만으로 ZAYA1-8B가 DeepSeek-V3.2와 Qwen3-A22B 근처까지 올라가고, extra-high TTC에서는 APEX-shortlist에서 DeepSeek-V3.2와 GPT-OSS-High를 넘는다고 주장한다.
또 HMMT’25에서는 Claude 4.5 Sonnet 88.3을 넘는 89.6을 제시한다.
이 수치는 분명 인상적이지만, Zyphra의 자체 evaluation harness에서 측정된 값이라는 점도 함께 기억해야 한다.
공개 패키징 상태도 살펴볼 만하다.
Hugging Face API 기준으로 이 모델은 2026-05-04 생성, 2026-05-08 수정, 현재 likes 356, downloads 44,834 수준이며 model-00001-of-00004.safetensors부터 model-00004-of-00004.safetensors까지 4개 shard로 배포된다. usedStorage는 약 53.1GB다.
즉 공개는 꽤 빠르게 이루어졌고, 실제 weights도 이미 올라와 있다.
하지만 배포 성숙도는 완전히 매끈하진 않다.
README quickstart는 vanilla vllm이나 transformers가 아니라 Zyphra 포크 브랜치 설치를 요구한다.
vllm @ git+https://github.com/Zyphra/vllm.git@zaya1-prtransformers @ git+https://github.com/Zyphra/transformers.git@zaya1
이건 실무적으로 중요한 신호다.
모델이 공개됐다고 해서 곧바로 주류 서빙 스택에 무리 없이 꽂히는 단계는 아니라는 뜻이다.
또 라이선스는 Hugging Face cardData와 모델 페이지에서 apache-2.0으로 표시되지만, 현재 저장소 sibling 목록에는 별도 LICENSE 파일이 보이지 않는다.
즉 라이선스 표기는 분명하지만 checked-in license artifact는 비어 있는 상태라, 엄격한 법무 검토가 필요한 팀이라면 이 점을 한 번 더 확인하는 편이 좋다.
실무 관점에서의 해석
내가 보기에 ZAYA1-8B의 가장 중요한 의미는 “작은 모델이 얼마나 똑똑한가”가 아니라, reasoning 모델의 성능을 더 이상 base checkpoint 하나로 설명하지 않는 흐름을 잘 보여 준다는 데 있다.
Zyphra는 모델 구조, AMD 학습 인프라, staged post-training, RL, 그리고 Markovian RSA 같은 inference harness를 한 묶음으로 제시한다.
이는 앞으로의 reasoning 경쟁이 단순 parameter race보다 system-level co-design 경쟁이 될 가능성을 강하게 시사한다.
또 하나 눈에 띄는 점은 이 모델이 오픈 웨이트 공개와 제품 표면을 동시에 갖는다는 것이다.
Zyphra Cloud에서 serverless endpoint로 바로 써볼 수 있고, Hugging Face weights도 내려받을 수 있다.
하지만 실제 self-hosting은 포크된 vllm/transformers에 기대고 있어, 지금 단계에서는 완전히 commodity한 오픈모델이라기보다 특정 런타임 경로를 전제로 한 연구-제품 하이브리드 릴리스에 더 가깝다.
벤치마크 해석도 냉정할 필요가 있다.
수학과 코딩에서는 확실히 매우 인상적이지만, GPQA-Diamond나 IFEval/IFBench를 보면 broad knowledge나 instruction following에서 절대적인 SOTA라고 보긴 어렵다.
다시 말해 ZAYA1-8B는 “모든 일에 가장 좋은 8B”라기보다, TTC를 충분히 태울 수 있는 reasoning-heavy 워크로드에서 특히 매력적인 초소형 활성 MoE다.
그럼에도 시사점은 크다.
첫째, AMD 기반 대규모 학습 서사가 더 이상 데모 수준이 아니라 실제 공개 reasoning model release로 이어지고 있다.
둘째, 0.7B 안팎 active parameter로도 frontier 근처의 수학·코딩 reasoning을 보여 줄 수 있다는 점은 이후 오픈모델 설계 방향에 꽤 큰 압력을 줄 수 있다.
셋째, Markovian RSA처럼 모델 자체와 harness를 함께 학습하는 접근은 앞으로 test-time compute 시대의 중요한 설계 패턴이 될 가능성이 높다.
ZAYA1-8B는 그 패턴을 꽤 선명하게 먼저 보여 준 사례다.