코딩 에이전트를 오래 쓰다 보면 병목은 금방 비슷한 곳에서 생긴다. 모델이 코드를 한 줄 더 잘 쓰는가보다, 매번 같은 설명을 다시 하고 같은 저장소 규칙을 다시 주입하고 같은 보조 작업을 다시 시키는 반복 비용이 더 크게 느껴진다. 세션이 바뀔 때마다 컨텍스트가 초기화되고, 팀원마다 프롬프트 스타일이 달라지고, 재현 가능한 작업 흐름이 사람 머릿속에만 남아 있으면 결국 생산성은 쉽게 흔들린다.
AI Engineer 채널의 **Skills at Scale — Nick Nisi and Zack Proser, WorkOS**는 바로 이 문제를 다룬다. 이 워크숍의 핵심 메시지는 단순하다. 좋은 에이전트 활용은 더 긴 시스템 프롬프트에서 나오지 않는다. 대신 설명, 제약, 참조 자료, 스크립트, 평가 루프를 묶은 skill로 업무 지식을 패키징하고, 그것을 여러 프로젝트와 여러 팀원이 재사용할 수 있게 만들어야 한다는 주장이다.
흥미로운 점은 이 발표가 skill을 “프롬프트 팁 모음”이 아니라 portable unit of work로 설명한다는 데 있다. 발표 초반에는 메모리 파일과 전역 규칙의 한계를 짚고, 중반에는 description을 routing rule로 쓰는 법과 script interpolation으로 deterministic base를 만드는 법을 보여 주며, 후반에는 WorkOS CLI처럼 실제 제품 표면에서 skill이 어떻게 프로덕션 기능의 두뇌가 되는지까지 연결한다.
무엇을 다루는 영상인가
이 영상은 AI Engineer 채널에 2026-05-06 업로드된 약 81분 길이의 워크숍으로, 발표자는 WorkOS의 Applied AI 팀에 있는 Nick Nisi와 Zack Proser다. transcript 기준 발표는 처음부터 끝까지 skill을 개인 프롬프트 습관이 아니라 팀이 공유할 수 있는 실행 자산으로 다룬다.
재미있는 점은 YouTube 설명란이 현재 영상 제목과 어긋나 있다는 것이다. oEmbed title과 실제 transcript는 분명히 Skills at Scale 워크숍인데, 설명란 텍스트는 다른 MCP Apps 세션 소개처럼 보인다. 그래서 이 글에서는 영상 제목, 발표자 소개 발화, transcript 본문을 기준으로 실제 내용을 추적했다.
발표의 범위는 생각보다 넓다. 초반에는 memory file과 repo-specific convention의 한계를 짚고, 중반에는 skill의 최소 구조와 설명문 작성법, script interpolation, 평가 루프를 설명한다. 후반에는 skill을 zip처럼 묶어 비개발 직군에도 전달하는 방식, 마켓플레이스와 멀티 툴 배포, 그리고 WorkOS CLI처럼 실제 제품 기능을 skill로 구동하는 구조까지 다룬다.
핵심 아이디어 / 구조 / 시연 흐름
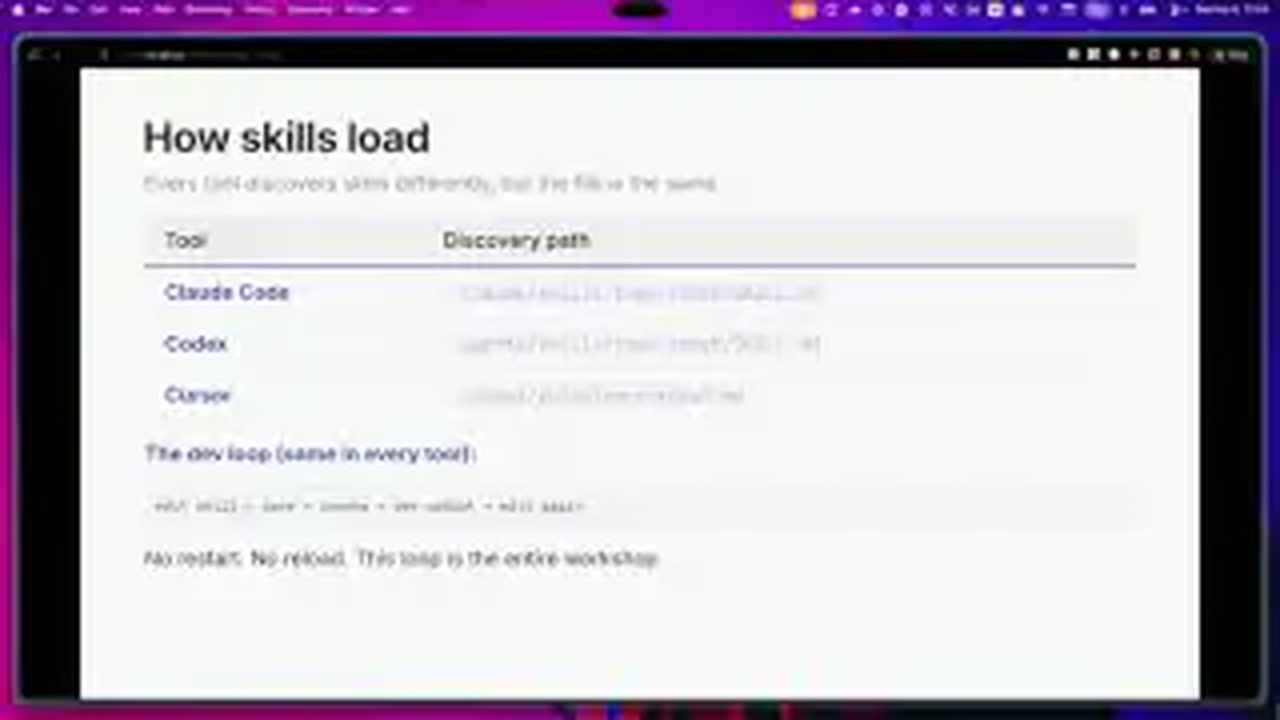
이 발표의 출발점은 간단하다. 에이전트는 매 대화마다 거의 0에서 다시 시작한다. 그래서 사람은 같은 맥락을 반복해서 주입해야 하고, repo에 붙인 AGENTS.md류 파일이나 전역 memory file만으로는 팀 차원의 재사용성과 결정론을 확보하기 어렵다.
Nick과 Zack은 여기서 skill을 작고 독립적인 작업 단위로 정의한다. transcript 3~8분대 설명을 보면 skill은 단순 markdown 하나일 수도 있지만, 실제로는 이름·description·참조 자료·스크립트·이미지까지 포함한 폴더 구조에 가깝다. 중요한 것은 이 묶음이 “어떤 일을 언제 어떤 방식으로 수행해야 하는지”를 에이전트가 다시 불러올 수 있게 해 준다는 점이다.
특히 발표가 강조하는 차별점은 description의 역할이다. 이들은 description을 사람용 소개문이 아니라 LLM용 routing rule로 설명한다. 즉 skill의 품질은 예쁜 문장보다도, 에이전트가 “이 작업에서 이 skill을 불러야 하는가”를 얼마나 잘 판단하게 만드느냐에 달려 있다는 뜻이다.
또 하나 중요한 부분은 script interpolation이다. 16~18분대에서 발표자들은 “최신 10개 커밋을 분석하라”고 모호하게 말하는 대신, 정확한 git 명령 결과를 미리 만들어 skill 컨텍스트에 주입하는 방식이 훨씬 안정적이라고 설명한다. 이때 skill은 비결정적인 대화 위에 결정적인 데이터층을 얹는 장치가 된다.
| 레이어 | 영상에서 설명하는 역할 | 실무적 의미 |
|---|---|---|
| Description | 언제 skill을 불러야 하는지 판단하는 routing rule | 프롬프트 기억 대신 자동 선택 가능 |
| Constraints | repo 규칙, 하지 말아야 할 것, 출력 형식 | 팀의 관용구를 일관되게 강제 |
| Scripts | git 로그, stale todo, hotspot file 같은 결정적 입력 생성 | 에이전트 추측 대신 재현 가능한 데이터 제공 |
| References | 슬라이드, docs, examples, 보조 이미지 | 매번 설명하지 않아도 되는 맥락층 |
| Eval loop | skill을 반복 사용하면서 edge case를 다시 반영 | skill이 시간에 따라 조직 자산으로 진화 |
발표 중반부의 repo roast 예시도 이 구조를 잘 보여 준다. skill은 단순히 “리포지토리를 평가해 줘”라고 요청하는 프롬프트가 아니다. stale todo를 찾는 명령, churn hotspot을 찾는 방식, README drift를 보는 기준, 출력 형식과 제약까지 함께 포함한 작업 패키지다. 그래서 누가 실행하든 비슷한 분석 표면을 얻을 수 있다.
타임라인으로 보는 핵심 구간
| 구간 | 핵심 장면 | 의미 |
|---|---|---|
| 00:00~00:07 | skill을 discrete unit of work로 소개하고 memory file의 한계를 짚음 | 반복 프롬프트를 재사용 자산으로 바꾸려는 문제 설정 |
| 00:07~00:15 | repo roast 예시와 skill 기본 구조 설명 |
skill이 단순 markdown이 아니라 description·constraints·references를 갖는 패키지라는 점 제시 |
| 00:15~00:19 | description은 사람이 아니라 LLM을 위한 routing rule이라고 설명 | 자동 로딩과 적합성 판단이 skill 품질의 핵심임을 강조 |
| 00:16~00:18 | script interpolation으로 deterministic base를 만드는 흐름 설명 | 에이전트의 추측을 줄이고 토큰 낭비도 절약 |
| 00:35~00:40 | 공개 skill 라이브러리, 마켓플레이스, image/video skill 사례 공유 | skill이 코딩 외 작업까지 확장되는 범용 인터페이스임을 보여 줌 |
| 00:48~00:55 | skill builder와 메타-skill로 자기 workflow를 다시 분석하는 루프 설명 | skill이 정적 문서가 아니라 점점 좋아지는 운영 자산이라는 관점 |
| 01:03~01:10 | WorkOS CLI, 비개발 직군용 skill 배포, blog writing/CI/RAG 사례로 확장 | skill이 실제 프로덕션 기능의 내부 두뇌가 될 수 있음을 시연 |
영상과 연결 자료에서 확인되는 점
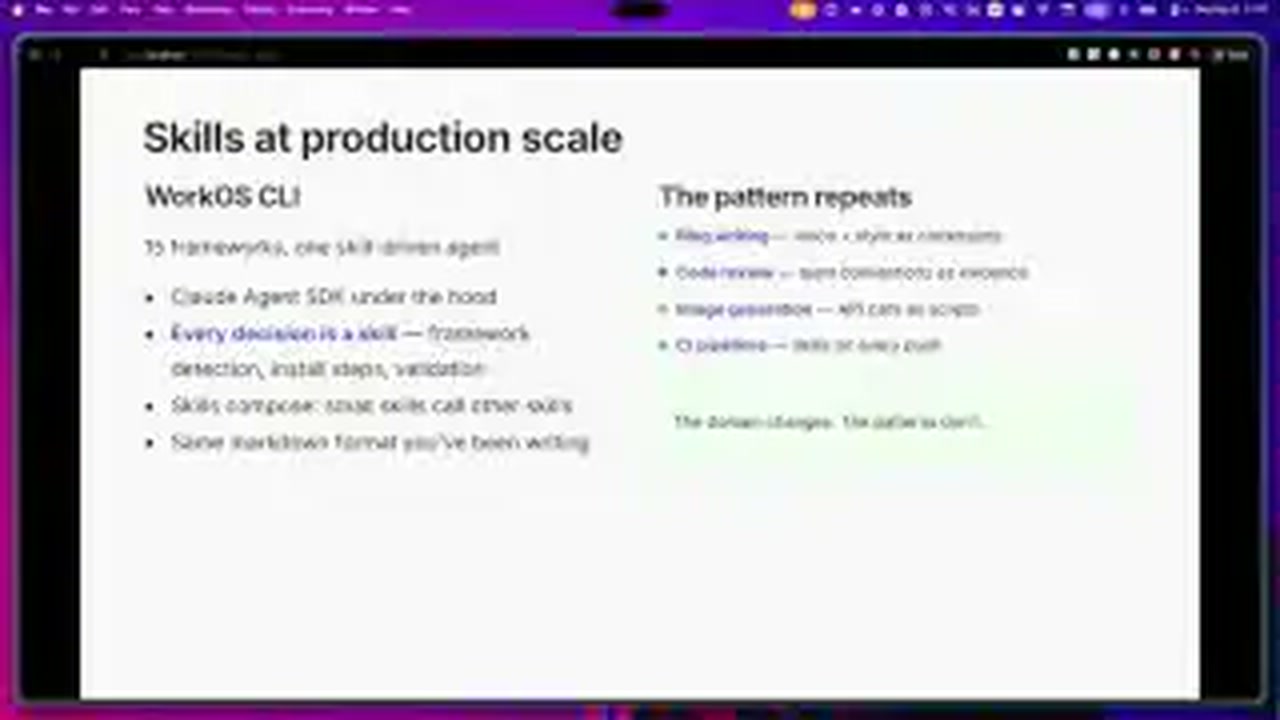
영상의 후반부 주장은 공개된 companion source와도 어느 정도 맞물린다. 발표자들이 언급하는 WorkOS CLI 저장소는 현재 GitHub에서 workos/cli로 공개되어 있으며, 설명은 “AI-powered CLI wizard that automatically integrates WorkOS AuthKit into your app”로 붙어 있다. 조회 시점 기준 이 저장소는 TypeScript 기반이며, 2026년 1월 생성 이후 2026년 5월까지 계속 푸시가 이어지고 있다.
이 사실은 발표 67분대의 주장과 연결된다. transcript에서 Nick은 WorkOS CLI의 install flow가 Claude Agent SDK를 쓰고 있으며, 그 “brains”가 실제로 work OS skills 디렉터리의 skill들이라고 설명한다. 즉 skill은 데모용 부가 기능이 아니라, 실제 제품 표면 뒤에서 CLI의 행동을 규정하는 실행 레이어로 배치된다.
또 하나 눈에 띄는 부분은 발표가 skill을 개발자 전용 artefact로 한정하지 않는다는 점이다. 65분대에서는 skill 폴더를 압축해 비개발 직군도 desktop 환경에서 drag-and-drop으로 쓸 수 있다고 설명하고, 같은 흐름에서 recruiting team이나 blog writing 같은 사례를 언급한다. 이건 skill을 “코딩 팁”보다 업무 방식의 전달 포맷으로 본다는 뜻에 가깝다.
설명란 불일치 역시 작은 신호는 아니다. 이 워크숍은 YouTube 메타데이터 관리가 완전히 정돈된 발표라기보다, 채널 운영 과정에서 다른 세션 설명이 남아 있는 상태로 보인다. 오히려 이런 상황은 영상 기반 글을 쓸 때 title 하나만 믿지 않고 transcript와 spoken identity를 함께 확인해야 한다는 점을 다시 보여 준다.
실무 관점에서의 해석
내가 보기엔 이 발표의 진짜 포인트는 “skill을 잘 쓰는 법”이 아니다. 더 중요하게는 조직의 업무 지식을 어떤 형식으로 에이전트에게 넘길 것인가에 대한 답을 제시한다는 점이다. 과거에는 이런 지식이 wiki, notion 문서, 시니어 구두 설명, 팀별 암묵지 형태로 흩어져 있었다.
하지만 skill 형식으로 묶으면 상황이 달라진다. repo roast처럼 특정 분석 작업을 하나의 실행 단위로 만들 수 있고, blog writing처럼 팀의 CMS 규칙과 문체를 재사용 가능한 흐름으로 패키징할 수 있으며, install wizard처럼 제품 기능 자체를 skill 기반으로 움직이게 만들 수도 있다. 이때 중요한 것은 모델을 더 많이 설명하는 것이 아니라, 어떤 입력을 결정적으로 만들고 어떤 제약을 명시하며 어떤 루프로 개선할지를 구조화하는 일이다.
이 접근의 장점은 분명하다.
- 개인 프롬프트 습관이 팀 공유 자산으로 바뀐다.
- tool이 달라도 동일한 업무 지식을 재사용할 수 있다.
- script를 통해 non-deterministic conversation 위에 deterministic base를 얹을 수 있다.
- 평가와 수정이 가능해서 시간이 갈수록 더 강한 조직 자산이 된다.
반면 한계도 있다.
- description과 constraint를 잘못 쓰면 skill이 과잉 규율이 되어 오히려 모델 성능을 떨어뜨릴 수 있다.
- 실제 배포 단계에서는 민감정보, connector 권한, 버전 관리 문제를 따로 다뤄야 한다.
- marketplace와 plugin 레이어가 늘어날수록 설치·발견·업데이트 경로도 다시 관리 대상이 된다.
그럼에도 방향성은 분명하다. 에이전트 시대의 차별점은 더 긴 프롬프트나 더 많은 예시 문장보다, 반복 업무를 얼마나 작은 실행 블록으로 정리하고 그것을 팀 전체가 공유 가능한 형태로 운용하느냐에서 나올 가능성이 크다. Skills at Scale은 바로 그 전환점을 꽤 선명하게 보여 주는 워크숍이다.
한 줄로 요약하면
Skills at Scale은 코딩 에이전트 활용의 핵심을 개인의 프롬프트 솜씨에서 찾지 않는다. 대신 설명·제약·스크립트·평가 루프를 갖춘 portable skill을 만들어, 사람 머릿속에 흩어진 업무 방식을 팀 전체가 재사용하는 운영 자산으로 바꾸자는 제안에 가깝다.