에이전트를 둘러싼 최근 서사는 꽤 낙관적이다.
바이브 코딩, delegated work, autonomous knowledge work 같은 표현이 반복되면서, 이제 사람은 목표만 말하고 모델은 긴 작업을 대신 완주해 줄 것처럼 들린다.
하지만 실제 현장에서 더 중요한 질문은 “모델이 일을 끝내는가”보다 중간에 문서를 얼마나 조용히 망가뜨리는가일 수 있다.
arXiv 논문 LLMs Corrupt Your Documents When You Delegate는 바로 이 지점을 정면으로 겨냥한다.
Microsoft Research는 DELEGATE-52라는 새 벤치마크를 통해, LLM이 긴 위임형 문서 편집 워크플로우를 거치는 동안 얼마나 안정적으로 원문 구조와 의미를 보존하는지를 측정한다.
논문의 결론은 꽤 불편하다.
19개 LLM을 52개 전문 도메인에 걸쳐 시뮬레이션한 결과, 최상위권 frontier 모델조차 긴 위임 과정이 끝날 즈음 평균 25% 수준의 문서 내용을 잃거나 왜곡했다.
더 약한 모델은 훨씬 심하게 무너졌고, 도구를 쥐여 준 agentic setting도 이 문제를 해결하지 못했다.

무엇을 해결하려는가
이 논문이 푸는 문제는 단순한 text editing benchmark가 아니다.
더 정확히는 전문 지식이 필요한 긴 문서 편집 업무를 모델에게 위임했을 때, 사람이 놓치기 쉬운 silent corruption이 얼마나 발생하는가를 측정하려는 시도다.
기존 편집 계열 평가는 대개 단일 도메인에 머무르거나, 짧은 상호작용 안에서 정답과의 문자열 유사도를 보는 경우가 많았다.
그러나 실제 delegated work는 훨씬 복잡하다.
모델은 코드를 고칠 수도 있고, crystallography 파일을 편집할 수도 있고, genealogy 데이터나 music sheet notation처럼 일반 사용자가 쉽게 검수하기 어려운 형식도 다루게 된다.
이때 가장 큰 위험은 즉시 눈에 띄는 대형 실패가 아니다.
오히려 겉으로는 작업이 진행되는 것처럼 보이지만, 원문 일부가 삭제되거나, 구조가 망가지거나, 의미가 비틀리는 sparse but severe error가 더 위험하다.
사람은 시간이 없거나 해당 포맷 전문성이 부족해서 그 오류를 제때 잡지 못할 수 있기 때문이다.
논문은 이 문제를 신뢰의 문제로 본다. delegated work가 성립하려면 사용자는 모델이 문서를 고치는 동안 최소한 원래 정보와 구조를 함부로 망가뜨리지 않을 것이라고 믿어야 한다.DELEGATE-52는 바로 그 신뢰의 기반이 현재 얼마나 약한지를 수치화한다.
핵심 아이디어 / 구조 / 동작 방식
논문의 첫 번째 기여는 DELEGATE-52 벤치마크 자체다. arXiv HTML 본문 기준으로 이 벤치마크는 52개 전문 도메인, 310개 work environments, 그리고 도메인당 5~10개의 복잡한 reversible editing task로 구성된다.
각 환경은 실제 온라인 문서에서 가져온 seed document와 distractor context를 포함하고, 전체 맥락 길이는 대략 15k tokens 수준이다.
핵심 아이디어는 단순하지만 매우 강력하다.
연구진은 각 편집 작업을 forward instruction과 그 반대 작업인 backward instruction 쌍으로 정의한다.
예를 들어 문서를 카테고리별로 분리한 뒤, 다시 시간순으로 합치는 식이다.
이 두 작업을 연속으로 수행하면 이상적인 모델이라면 원래 문서를 완벽히 복원해야 한다.
연구진은 이 왕복 구조를 한 번만 쓰지 않고 연속적으로 이어 붙인다.
논문이 말하는 round-trip relay가 바로 그것이다.
즉 모델이 문서를 한 번 고쳤다가 되돌리고, 다시 다른 구조 편집을 하고 또 복원하는 식으로 긴 위임 상호작용을 시뮬레이션한다.
각 단계가 끝날 때마다 원본 문서와 얼마나 가까운지를 domain-specific evaluator로 재측정한다.
이 설계가 좋은 이유는 reference solution을 일일이 사람이 만들지 않아도 된다는 점이다.
정답 파일을 수작업으로 구축하는 대신, **“되돌릴 수 있는 작업이면 원래 상태로 돌아와야 한다”**는 원리를 이용해 장기 안정성을 평가한다.
논문과 companion repo를 함께 보면 구현 구조도 비교적 명확하다.
run_relay.py: 여러 round-trip을 연속으로 실행하는 메인 실험 러너run_single.py: 개별 edit pair를 분리 평가하는 QA 도구model_openai.py: OpenAI/Azure OpenAI 계열 래퍼model_agentic.py: 파일 읽기/쓰기/삭제, Python 실행 등을 포함한 agentic harnessdomains/: 52개 도메인별 parser와 evaluatorprompts/: 시뮬레이션 프롬프트 템플릿
즉 이 프로젝트는 단순 논문 artifact라기보다, benchmark dataset + evaluator + simulation harness + agentic ablation 코드를 함께 공개한 재현형 평가 스택에 가깝다.
| 구성 요소 | 논문/레포에서 확인되는 내용 | 역할 |
|---|---|---|
| Benchmark scope | 52 domains, 310 work environments, 19 LLMs | delegated workflow 안정성을 폭넓게 측정 |
| Relay design | reversible forward/backward edits를 연쇄 적용 | 장기 상호작용에서 누적 손상을 평가 |
| Evaluator | domain-specific parser/similarity functions | 문자열 유사도 대신 포맷별 의미 보존 측정 |
| Distractor context | 8–12k token 관련 문서 포함 | 실제 작업 환경의 retrieval noise를 반영 |
| Agentic harness | tools를 쓰는 multi-turn loop 구현 | 툴 사용이 문제를 완화하는지 별도 점검 |
공개된 근거에서 확인되는 점
가장 강한 수치는 메인 결과다.
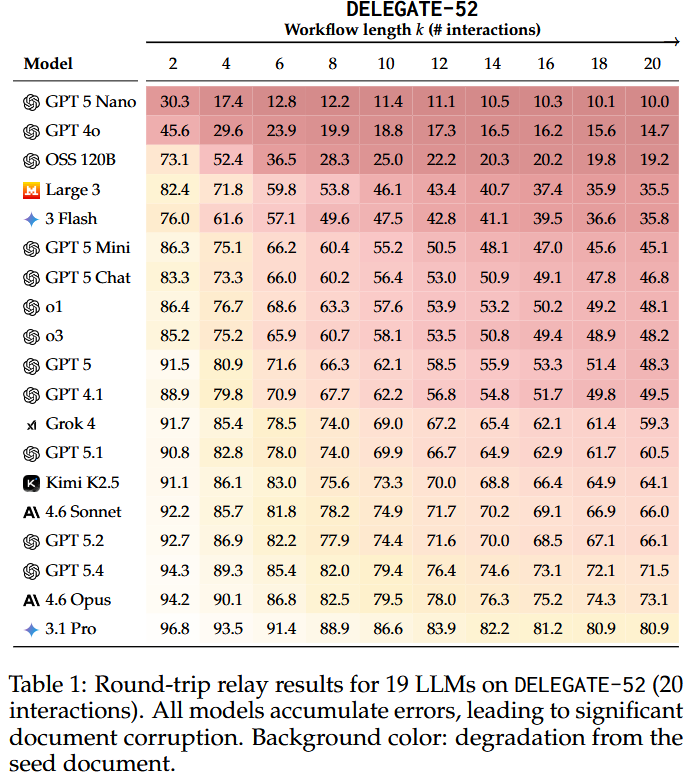
논문 Table 1과 본문 설명에 따르면, 20 interactions가 끝난 시점에서 전체 19개 모델 평균 degradation은 약 50% 수준까지 내려간다. frontier 모델만 따로 보면 Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4도 평균적으로 문서 내용의 약 25%를 잃거나 왜곡한다.
논문 HTML에 노출된 Table 1 수치를 보면 상위권 모델 간에도 차이가 있다.
최종 상호작용 시점 기준으로 Gemini 3.1 Pro는 약 80.9, Claude 4.6 Opus는 73.1, GPT 5.4는 71.5 수준의 reconstruction score를 보인다.
반대로 더 약한 모델들은 초반부터 빠르게 무너져 GPT 4o는 14.7, GPT 5 Nano는 10.0 수준까지 떨어진다.
이 결과가 더 무서운 이유는 단지 평균 점수가 낮아서가 아니다.
Table 2 해석 문단에서 연구진은 모델들이 전체 도메인의 80%에서 적어도 -20% 수준의 심각한 훼손을 일으킨다고 적는다.
즉 실패가 특정 niche domain에만 국한되지 않는다.
또 하나 중요한 보조 결과는 tool use다.
Section 4.2에서 논문은 tool-enabled agentic setting을 별도로 테스트했지만, 도구를 준 네 개 모델 모두 non-agentic baseline보다 더 나빴고, 평균적으로 시뮬레이션 종료 시점의 degradation이 약 6% 추가 악화됐다고 설명한다.
직관적으로는 search-and-replace나 Python 실행이 손상을 줄일 것 같지만, 실제로는 interactive overhead와 tool misuse가 오히려 누적 오류를 키웠다는 해석이다.
문서 길이와 컨텍스트도 중요한 변수다.
메인 실험은 3–5k token 문서와 8–12k token distractor context, 20 interactions로 구성되는데, 논문은 이것조차 현실보다 보수적인 설정이라고 밝힌다.
추가 실험에서는 문서 크기가 1k에서 10k tokens로 커질수록 GPT 5.4의 최종 score가 59.9까지 하락했고, 논문은 document size, interaction length, distractor context가 모두 degradation을 악화시킨다고 명시한다.
companion source들도 흥미롭다.
GitHub repo microsoft/delegate52는 확인 시점 기준 약 57 stars, 7 forks, MIT license를 갖고 있고, 생성 시점은 2026-04-06으로 매우 신생이다.
README는 full paper benchmark가 310 environments / 52 domains라고 말하면서도, Hugging Face dataset microsoft/delegate52에는 redistribution 가능한 234 environments / 48 domains subset만 공개한다고 밝힌다.
즉 논문 전체 벤치마크와 공개 데이터셋 사이에는 명시적인 공개 범위 차이가 있다.
| 공개 근거 | 확인된 내용 | 해석 |
|---|---|---|
| arXiv abstract / Table 1 | frontier 모델도 장기 위임 끝에 평균 25% 수준 corruption | delegated work의 신뢰 기반이 아직 약함 |
| Table 2 해석 문단 | 80% 도메인에서 severe corruption | 특정 niche 포맷만의 문제가 아님 |
| Section 4.2 | agentic tools 사용 시 평균 6% 추가 악화 | “툴을 주면 해결된다”는 가정이 성립하지 않음 |
| Context-size ablation | 10k token 문서에서 GPT 5.4 최종 score 59.9 | 긴 문서일수록 delegated editing이 더 위험 |
| GitHub + HF dataset | repo는 52/310을 지향하지만 공개 dataset은 48/234 subset | 연구 artifact 공개 범위와 재현 범위를 구분해 봐야 함 |
실무 관점에서의 해석
내가 보기에 이 논문의 가장 큰 가치가 “모델이 아직 별로다”라는 단순한 비관론에 있지는 않다.
더 중요한 점은, 이 논문이 에이전트 실패를 정답률 문제가 아니라 artifact integrity 문제로 재정의했다는 데 있다.
지금까지 많은 평가가 최종 답이 맞는지, task completion이 되었는지, 또는 judge model이 답변을 좋게 보는지에 집중했다.
하지만 실제 delegated work에서는 최종 답이 그럴듯해 보여도 중간 파일 하나가 망가지면 전체 워크플로우가 무너질 수 있다.
코드에서 import 한 줄이 빠지거나, ledger에서 날짜 정렬이 깨지거나, notation 파일에서 구조적 토큰 하나가 잘못 바뀌면 사용자는 사후에 발견하기 어렵다.
이 벤치마크는 그런 위험을 매우 실무적인 방식으로 드러낸다.
특히 reversible edit를 relay로 이어 붙이는 설계는, 장기 에이전트 평가에서 앞으로 더 많이 쓰일 가능성이 있다. reference solution을 만들지 않고도 **“되돌렸을 때 원상복구되는가”**를 통해 안정성을 측정할 수 있기 때문이다.
동시에 이 논문은 agent tooling에 대한 흔한 낙관론도 경계하게 만든다.
현재 많은 팀이 “채팅형 모델은 불안정하지만 file tools와 shell을 주면 해결될 것”이라고 믿는다.
그러나 DELEGATE-52는 적어도 현재 세대 모델과 단순 harness 조합에서는 그 가정이 자동으로 성립하지 않는다는 점을 보여준다.
물론 한계도 있다.
우선 이 논문은 시뮬레이션 기반이다.
실제 사람-에이전트 협업에서는 사용자 검토, 중간 승인, linting, unit test, typed schema, document-specific validator 같은 방어막이 더 들어갈 수 있다.
또한 공개 dataset이 234/48 subset이기 때문에 full benchmark를 그대로 재현하기는 어렵다.
그럼에도 메시지는 충분히 강하다.
현 시점의 LLM을 지식 노동의 대리인으로 볼 때, 우리는 생성 품질보다 문서 보존, 구조 안정성, 누적 오류, 그리고 silent corruption 탐지를 훨씬 더 중요하게 다뤄야 한다.DELEGATE-52는 바로 그 평가 축을 강제로 전면에 끌어올린다.
한 줄로 요약하면
DELEGATE-52는 “모델이 일을 대신 해줄 수 있는가”를 묻지 않는다.
대신 **“긴 위임형 워크플로우가 끝났을 때 원래 문서가 아직 살아 있는가”**를 묻고, 현재 frontier LLM조차 그 질문에 아직 신뢰할 만한 답을 주지 못한다는 사실을 보여준다.