AI 코딩 에이전트가 라이브러리 함수나 작은 벤치마크 문제를 고치는 사례는 이제 낯설지 않다. 하지만 전자설계자동화(EDA) 도구처럼 수십 년 동안 축적된 C 코드, 복잡한 내부 자료구조, 강한 correctness 제약, 회로 품질 지표가 얽힌 시스템을 에이전트가 직접 진화시킬 수 있는지는 훨씬 어려운 질문이다.
Autonomous Evolution of EDA Tools: Multi-Agent Self-Evolved ABC는 이 질문을 ABC logic synthesis framework 위에서 다룬다. ABC는 학계와 산업계에서 널리 쓰이는 논리 합성·검증 시스템이고, 논문은 이 코드베이스가 120만 줄 이상의 C 코드와 4,000개 이상의 source file로 구성돼 있다고 설명한다. 저자들은 이 전체 통합 코드베이스를 대상으로 LLM agent가 소스 코드를 고치고, 컴파일하고, equivalence check를 통과하고, QoR 평가를 받아 다시 다음 수정을 계획하는 self-evolving loop를 구성했다.
핵심은 “에이전트가 코드를 써 준다”가 아니라, EDA 도구 개발을 측정 가능한 closed-loop search 문제로 바꿨다는 데 있다. 변경은 품질 개선처럼 보여도 회로 의미를 깨뜨리면 즉시 폐기된다. 반대로 컴파일·CEC·벤치마크를 통과한 개선은 champion version으로 누적된다. 이 점에서 이 논문은 agentic coding 데모라기보다, repository-scale tool evolution을 위한 실험 하네스에 가깝다.
무엇을 해결하려는가
EDA 도구 개발은 일반적인 소프트웨어 리팩터링보다 더 까다롭다. 논리 합성은 Boolean network를 더 작고 빠른 구현으로 바꾸는 과정인데, 최적화와 technology mapping은 NP-hard에 가깝고 실무 도구는 수많은 heuristic의 조합으로 성능을 낸다. 작은 threshold나 cost model 변경도 회로 구조, timing, area, mapping 결과에 예상 밖의 영향을 줄 수 있다.
ABC 같은 도구는 특히 interdependency가 강하다. 한 subsystem의 수정이 다른 optimizer, mapper, verifier에 파급될 수 있고, “더 좋아 보이는” 결과가 실제로는 기능적으로 다른 netlist를 만든 것일 수도 있다. 따라서 단순 unit test나 benchmark score만으로는 충분하지 않고, 컴파일·sanity check·formal equivalence check·end-to-end QoR 평가가 하나의 loop 안에 있어야 한다.
논문이 겨냥하는 병목은 바로 이 지점이다. 사람이 매번 코드베이스를 읽고, hypothesis를 만들고, 안전한 수정 범위를 정하고, 수많은 회로 벤치마크를 돌려 feedback을 해석하는 과정을 agent system으로 바꿀 수 있는가. 더 구체적으로는, LLM agent가 단일 함수가 아니라 120만 줄 규모의 EDA repository 안에서 점진적이고 correctness-preserving한 개선을 만들 수 있는가를 묻는다.
핵심 아이디어 / 구조 / 동작 방식
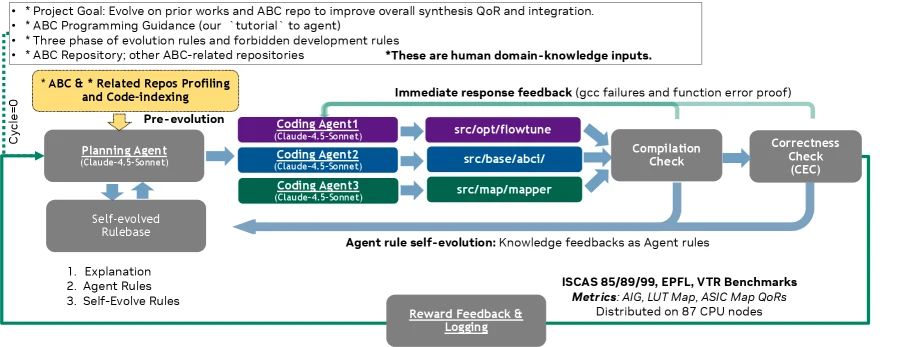
시스템은 단일 만능 코딩 에이전트가 아니라, ABC의 기능적 subsystem에 맞춰 역할을 나눈 다중 에이전트 구조다. Flow Agent는 src/opt/flowtune/ 아래의 flow scheduling과 pass orchestration을 담당한다. Mapper Agent는 src/map/mapper/에서 cut enumeration, pruning, cost scoring heuristic을 수정한다. Logic Minimization Agent는 src/base/abci/와 technology-independent optimization 계층을 다룬다.
각 coding agent는 Claude Sonnet 4.5 기반으로 구현됐고, 중앙에는 planning agent가 있다. Planner는 이전 cycle의 QoR feedback, 각 agent의 hypothesis, code change를 종합해 다음에 어느 subsystem을 진화시킬지 정한다. 중요한 설계 선택은 cycle 0에만 사람이 구조화된 지식을 제공한다는 점이다. 초기에는 ABC repository profiling, Markdown tutorial, command/API 사용법, 합성 flow 설명 같은 bootstrap 자료를 넣지만, 이후 cycle은 agent가 자체적으로 계획하고 실행한다. 사람이 개입하는 경우는 10회 이상 연속 compile error나 equivalence-checking violation이 발생하는 safety trigger로 제한된다.
실제 iteration은 다음 순서로 돈다.
| 단계 | 역할 | 의미 |
|---|---|---|
| Repository profiling / bootstrapping | ABC와 관련 오픈소스 synthesis component를 분석 | agent가 안전하게 수정할 수 있는 구조적 prior를 만든다 |
| Planning | 이전 QoR delta와 실패 원인을 보고 다음 수정 방향 결정 | 단발성 patch가 아니라 feedback-driven evolution으로 만든다 |
| Coding | subsystem별 agent가 지정된 directory 안에서 diff 생성 | 역할 범위를 제한해 충돌과 구조 훼손을 줄인다 |
| Compilation / self-debugging | 빌드 실패 로그를 다시 agent에게 반환 | syntax-level 실패를 빠르게 수리한다 |
| CEC correctness check | ABC의 combinational equivalence checking 사용 | QoR 개선처럼 보이는 잘못된 회로 변경을 차단한다 |
| Benchmark evaluation | 87개 CPU node에서 8개 synthesis flow와 benchmark suite 실행 | timing, area, depth, mapping metric을 dense feedback으로 만든다 |
| Rulebase update | 지나치게 보수적인 규칙을 planner가 조정 | early stability에서 later exploration으로 이동한다 |
이 구조가 흥미로운 이유는 agent가 단순히 코드 diff를 생성하는 데서 끝나지 않기 때문이다. evaluator는 agent 밖에 있다. ABC compile, CEC, ASAP7 기반 timing/area 평가, ISCAS·ITC·EPFL·VTR benchmark가 agent의 주장을 검증한다. 따라서 시스템은 “그럴듯한 설명”보다 실제 synthesis 결과와 equivalence 결과를 중심으로 움직인다.
공개된 근거에서 확인되는 점
실험은 87개의 AMD EPYC CPU node를 사용하는 distributed cluster에서 실행됐다. 각 evolution cycle은 모든 benchmark와 8개 synthesis flow, CEC를 병렬로 돌리며 약 2-3시간이 걸렸다고 적혀 있다. 모델은 enterprise-version Cursor 환경에서 Claude 4.5 Sonnet으로 구성됐고, 평가에는 ASAP7 7nm library가 사용됐다. benchmark suite는 ISCAS’85, ISCAS’89, ITC’99, EPFL, VTR DSP, arithmetic block을 포함한다.
가장 중요한 결과는 Table 2의 ablation이다. QoR은 vanilla FlowTune + vanilla AIG synthesis + vanilla Map 조합을 1.000으로 정규화했고, 낮을수록 좋다. 단일 subsystem만 진화시키면 FlowTune은 0.962, AIG synthesis는 0.957, Map은 0.988까지 내려간다. 두 subsystem을 같이 진화시키면 더 큰 개선이 나오며, 세 subsystem을 모두 진화시킨 All Evo는 0.917에 도달한다. 이는 통합 vanilla baseline 대비 약 8.3% 개선에 해당한다.
| 구성 | FlowTune | AIG synthesis / Orch | Mapping | Avg QoR |
|---|---|---|---|---|
| Vanilla ABC | - | - | - | 1.213 |
| Vanilla all | Vanilla | Vanilla | Vanilla | 1.000 |
| + Evo FT | Evo | Vanilla | Vanilla | 0.962 |
| + Evo Orch | Vanilla | Evo | Vanilla | 0.957 |
| + Evo Map | Vanilla | Vanilla | Evo | 0.988 |
| + Evo FT + Orch | Evo | Evo | Vanilla | 0.924 |
| + Evo FT + Map | Evo | Vanilla | Evo | 0.939 |
| + Evo Orch + Map | Vanilla | Evo | Evo | 0.942 |
| All Evo | Evo | Evo | Evo | 0.917 |
논문 본문은 fully evolved system이 전체 benchmark suite에서 static timing과 area-delay product를 모두 개선했다고 설명한다. Worst negative slack은 vanilla integrated baseline 대비 평균 약 8-9% 좋아졌고, 일부 EPFL arithmetic circuit에서는 12-15% 개선이 관찰됐다. Area-delay product 감소는 0.917 정규화 값과 맞는 약 8.3% 수준이다. 중간 구조 지표도 같은 방향을 보인다. arithmetic-heavy design에서 AIG node count는 3-8% 줄고, post-mapping depth는 mapping agent가 도입한 depth-aware heuristic 덕분에 4-6% 감소했다고 정리한다.
비용 구조도 꽤 투명하다. 전체 LLM token의 68%는 ABC codebase 초기 profiling, 11%는 외부 codebase profiling에 쓰였고, 실제 evolution cycle 자체는 21%라고 한다. 한 cycle의 token 비용은 수리 횟수에 따라 약 $60-80, 초기 profiling 비용은 약 $1,400, 전체 시스템 비용은 약 $2,400으로 제시된다. 생성 산출물 중 C source code는 87,749줄, 비중으로는 45%였고, 나머지는 Markdown, bash, Python, log로 구성됐다고 설명한다.
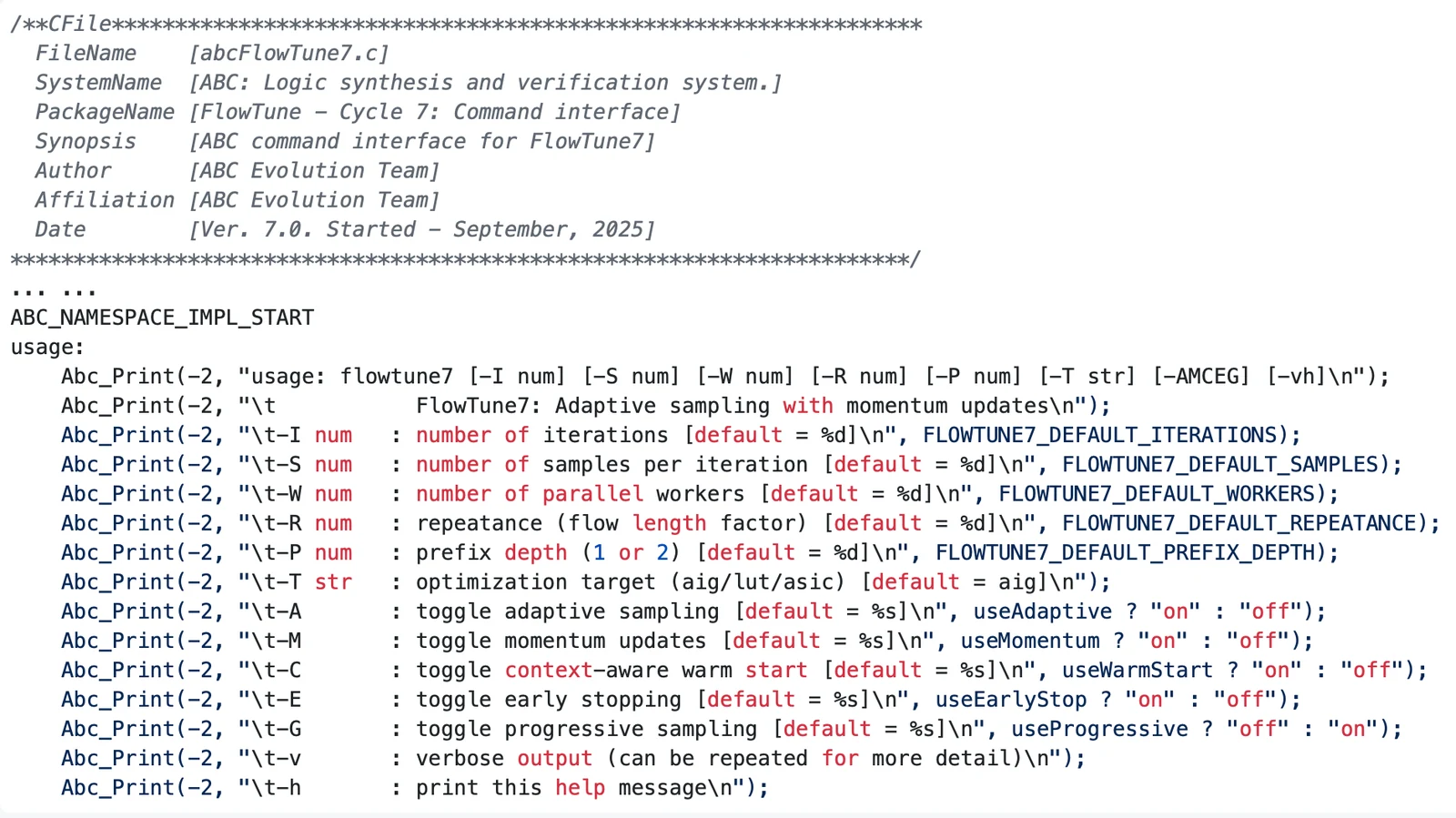
코드 품질에 대한 관찰도 중요하다. 논문은 agent가 여러 외부 연구 repository를 초기화 단계에서 보았음에도, 실제 생성 C code는 ABC의 formatting, naming convention, comment structure, macro organization에 강하게 수렴했다고 설명한다. Figure 2의 abcFlowTune7.c 예시는 자동 생성된 module이 ABC식 header, namespace, Abc_Print help string, default parameter macro를 비교적 자연스럽게 따르는 모습을 보여 준다.
반대로 한계도 명확하다. agent는 기존 ABC 안에 구조적 선례가 있는 방향, 예를 들어 threshold 조정, depth-aware scoring, conditional heuristic refinement에는 강했다. 그러나 기존 invariant에 anchor가 없는 완전히 새로운 algorithmic construct를 넣으려는 시도는 compile error, segmentation fault, subtle correctness violation으로 실패하는 경우가 많았다고 한다. 즉 이 시스템은 아직 “새 이론을 발명하는 에이전트”라기보다, 인간이 만든 prior와 code structure를 재조합·증폭하는 closed-loop optimizer에 가깝다.
또 하나의 release-maturity 신호도 있다. arXiv abs와 HTML 페이지는 논문, PDF, HTML, DOI를 제공하지만 공식 code repository 링크는 노출하지 않는다. 논문은 output repository와 single-binary execution model을 언급하지만, 공개 페이지 기준으로 독자가 즉시 clone해서 결과를 재현할 수 있는 공식 저장소는 확인되지 않는다. 따라서 현재 이 작업은 공개 코드 제품이라기보다, 논문 안의 방법론과 결과 중심으로 읽는 편이 안전하다.
실무 관점에서의 해석
이 논문의 강점은 agentic coding을 EDA라는 매우 엄격한 도메인으로 끌고 들어간 데 있다. 일반 코드 벤치마크에서는 테스트 통과가 최종 목표처럼 보일 수 있지만, EDA에서는 functional correctness와 QoR가 동시에 필요하다. 회로 의미가 같아야 하고, timing·area·depth가 좋아져야 하며, 특정 flow에서만 우연히 좋아지는 것이 아니라 여러 benchmark suite와 synthesis flow에서 버텨야 한다.
그런 의미에서 Self-Evolved ABC는 agent system 설계의 중요한 기준을 보여 준다. 좋은 agent framework는 모델 호출을 많이 하는 시스템이 아니라, 실패를 즉시 버릴 수 있는 외부 evaluator와 충분히 dense한 feedback surface를 가진 시스템이다. 여기서는 CEC가 semantic guardrail이고, QoR delta vector가 search signal이며, role-specific directory boundary가 codebase safety boundary로 작동한다.
실무적으로 보면 이 방식은 EDA에만 국한되지 않을 수 있다. compiler, database optimizer, numerical solver, ML training runtime처럼 오래된 C/C++ 코드와 복잡한 benchmark가 있는 도구에도 비슷한 구조가 들어갈 수 있다. 다만 전제는 분명하다. agent가 자유롭게 코드를 고치는 것보다, 안전한 수정 범위, formal 또는 strong oracle, 대규모 benchmark 자동화, 실패 로그를 다음 planning에 넣는 memory가 더 중요하다.
동시에 과장해서 읽으면 안 된다. 공개 결과는 약 8.3%의 의미 있는 QoR 개선을 보여 주지만, 이것이 곧바로 모든 EDA 개발을 자동화한다는 뜻은 아니다. 초기 profiling과 human-authored tutorial이 컸고, 외부 연구 component로 bootstrapping했으며, 공식 재현 repository는 arXiv 페이지에 직접 연결돼 있지 않다. 또한 agent가 완전히 새로운 알고리즘을 안정적으로 발명하기보다는, 기존 구조 안의 heuristic을 발견·조정하는 쪽에서 강했다는 점도 중요하다.
그럼에도 방향성은 꽤 강하다. AI coding agent의 다음 단계는 “작은 문제를 잘 푼다”가 아니라, 수년간 축적된 전문 도구를 안전한 평가 루프 안에서 조금씩 개선할 수 있는가일 가능성이 크다. Self-Evolved ABC는 그 질문에 대해 EDA라는 어려운 도메인에서 꽤 설득력 있는 첫 실험을 제시한다.