LLM 학습 속도를 이야기할 때 가장 먼저 떠오르는 것은 더 빠른 attention kernel, 더 좋은 GPU, 더 큰 병렬화 전략이다.
그런데 실제 파인튜닝 스택에서는 메인 연산이 아닌 주변부가 생각보다 자주 병목이 된다. padding을 줄이기 위한 sequence packing, 메모리를 아끼기 위한 activation checkpointing, MoE 라우팅을 위한 동적 인덱싱처럼 이미 표준처럼 쓰이는 기법들도 구현 경로에 따라 CPU-GPU 동기화나 불필요한 복사 대기를 만들 수 있다.
Unsloth가 NVIDIA의 도움을 받아 공개한 “How to Make LLM Training Faster with Unsloth and NVIDIA”는 바로 이 주변부 병목을 겨냥한다.
글의 주장은 단순하다.
새로운 학습 알고리즘을 제안하기보다, 이미 Unsloth가 제공하던 빠른 LoRA/QLoRA 학습 경로 위에서 반복 metadata 재구성, host-device synchronization, copy/compute serialization을 줄이면 추가로 꽤 큰 속도 향상을 얻을 수 있다는 것이다.
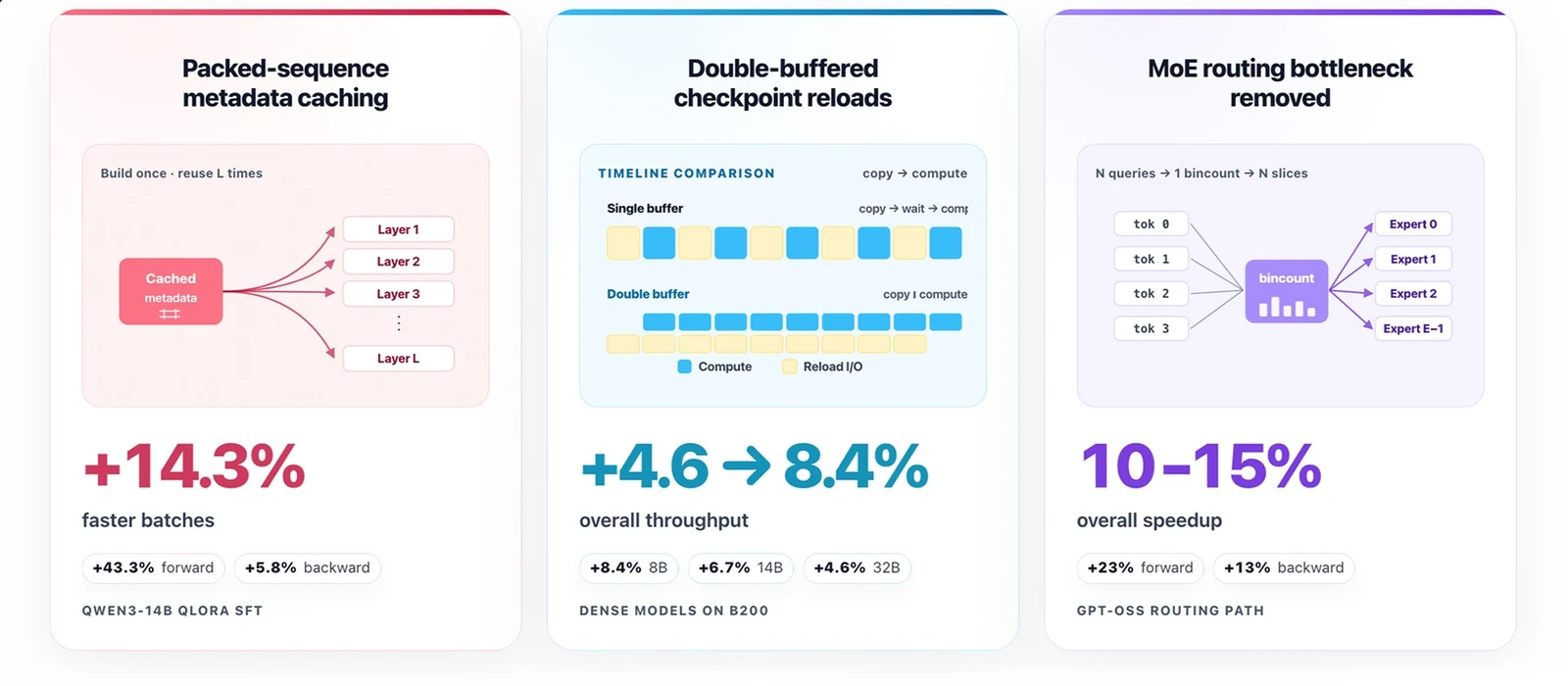
공식 글은 전체적으로 LLM training을 약 25% 더 빠르게 만들었다고 설명한다.
세부 개선은 packed-sequence metadata caching, double-buffered async gradient checkpointing, GPT-OSS MoE routing 최적화로 나뉘며, Unsloth의 기존 2-5배 속도 향상 위에 추가되는 개선으로 소개된다.
또한 RTX 노트북, 데이터센터 GPU, DGX Spark 환경에서 최신 Unsloth 업데이트만으로 자동 활성화된다고 설명한다.
무엇을 해결하려는가
이 글이 겨냥하는 문제는 “모델이 느리다”가 아니라 “학습 스텝 안에서 GPU가 기다리는 시간이 남아 있다”는 점이다. packed sequence를 쓰면 padding token 계산을 줄일 수 있지만, 각 layer마다 같은 sequence metadata와 attention mask를 다시 만들면 그 자체가 새로운 병목이 된다. activation checkpointing은 VRAM을 줄이지만, offload된 activation을 backward 전에 GPU로 다시 가져오는 과정이 compute와 직렬화되면 GPU idle bubble이 생긴다.
MoE에서는 expert별 token 목록을 매번 동적으로 찾는 코드가 expert 수만큼 synchronization point를 만들 수 있다.
흥미로운 점은 이 병목들이 모델 구조의 거대한 변화 없이도 나타난다는 것이다.
이미 성숙한 PyTorch/CUDA 학습 스택 위에서도 item(), tolist(), torch.where() 같은 작은 host-visible 연산, 혹은 한 개의 공유 buffer를 둘러싼 copy 대기 같은 세부 구현이 step time을 밀어 올릴 수 있다.
특히 Blackwell 같은 최신 GPU에서 주요 kernel이 빨라질수록, 예전에는 노이즈처럼 보이던 주변부 오버헤드가 상대적으로 더 잘 보인다.
따라서 이 협업의 핵심은 “더 강한 optimizer”나 “새로운 fine-tuning recipe”가 아니다.
이미 쓰고 있는 학습 경로에서 같은 정보를 반복 계산하지 않고, 피할 수 없는 데이터 이동은 compute 뒤에 숨기고, 동적 shape 질의를 한 번으로 줄이는 시스템 엔지니어링이다.
핵심 아이디어 / 구조 / 동작 방식
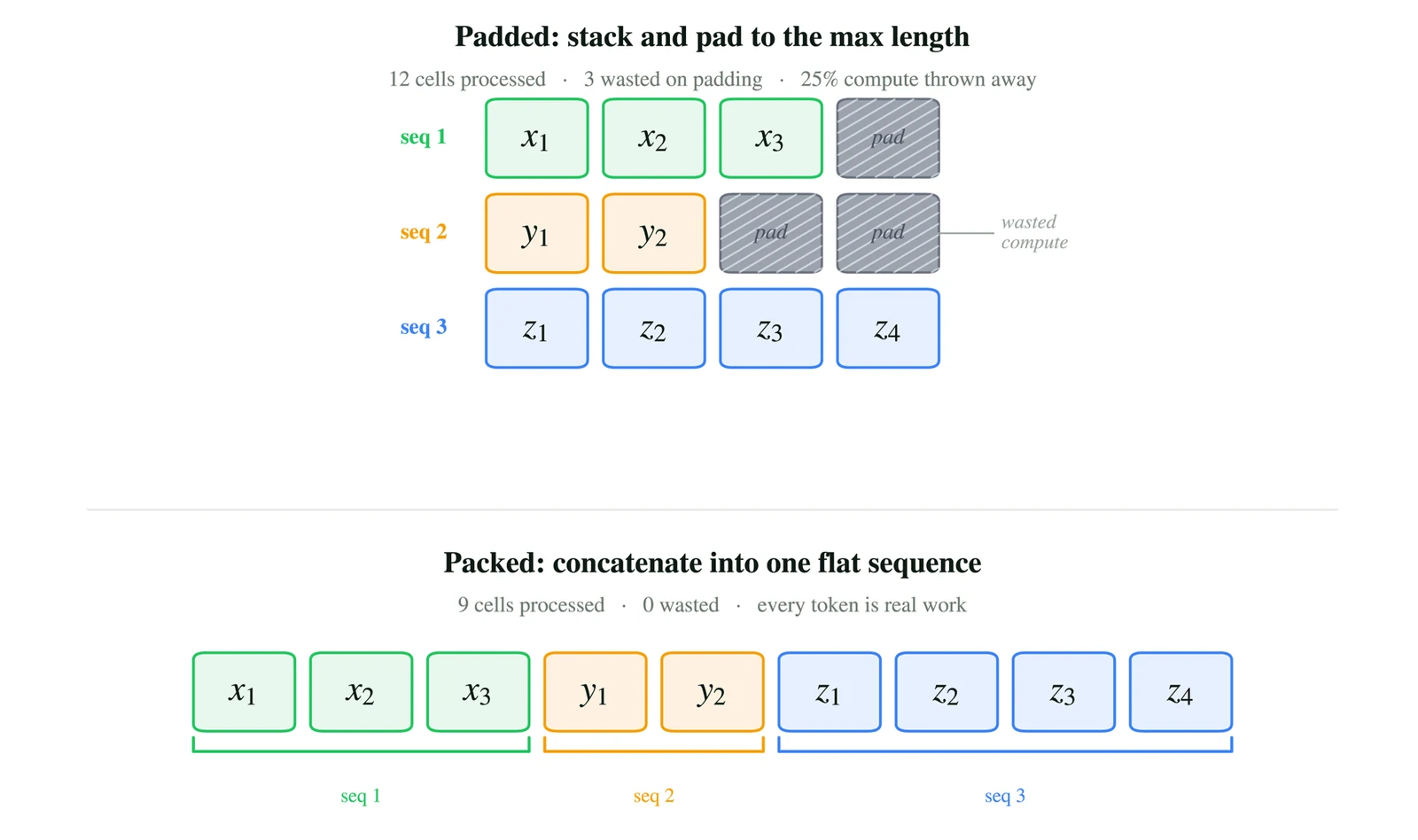
첫 번째 개선은 packed-sequence metadata caching이다.
여러 짧은 샘플을 하나의 긴 sequence로 이어 붙이면 padding 낭비를 줄일 수 있다.
하지만 모델은 여전히 각 원래 sequence의 길이, 누적 offset인 cu_seqlens, 최대 sequence 길이, attention 구조를 알아야 한다.
문제는 이 정보가 같은 packed batch 안에서는 모든 transformer layer가 공유하는 값이라는 점이다.
기존 경로에서는 packed info, SDPA packed mask, xFormers block causal mask를 layer마다 다시 준비하면서 device-to-host copy나 cudaStreamSynchronize가 반복될 수 있었다.
Unsloth의 변경은 이 정보를 현재 packed batch와 device 기준으로 캐싱해, 한 번 만든 metadata와 mask 구조를 여러 layer에서 재사용한다.
즉 유용한 계산은 그대로 두고, 같은 경계 정보를 layer 수만큼 반복해서 묻는 일을 줄인다.
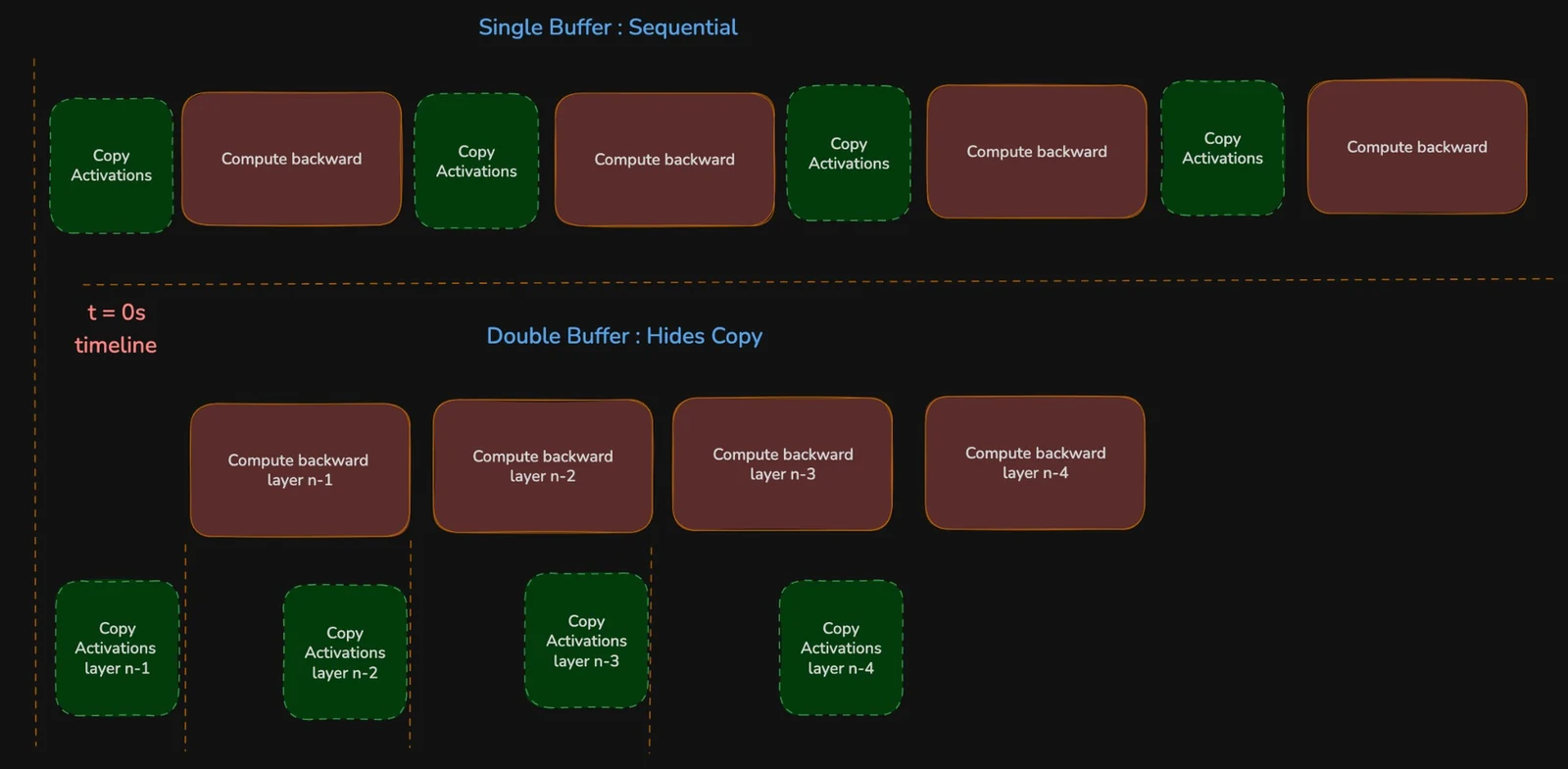
두 번째 개선은 double-buffered checkpoint reload다.
Unsloth의 smart checkpointing 경로에서는 activation을 pinned CPU memory에 staged했다가 backward 시점에 GPU로 다시 가져올 수 있다.
이 방식은 VRAM을 줄여 주지만, 하나의 buffer만 사용하면 “CPU에서 GPU로 복사 → 복사 완료 대기 → backward compute → 다음 복사”가 순차적으로 이어진다.
Double buffering은 이 직렬화를 pipeline으로 바꾼다. backward가 buffer A의 activation으로 계산하는 동안, copy stream은 다음 activation을 buffer B에 미리 올린다.
다음 layer에서는 두 buffer의 역할이 바뀐다.
수학 연산량이 줄어드는 것은 아니지만, host-to-device copy latency를 backward compute 뒤에 숨길 수 있다.
구현은 VRAM 여유가 있을 때만 extra buffer를 쓰고, 메모리 예산이 빡빡하면 fallback할 수 있도록 guardrail을 둔다.
세 번째 개선은 GPT-OSS MoE routing 쪽이다.
MoE에서는 token이 어느 expert로 갈지 정한 뒤, expert별 token 목록을 만들어야 한다.
단순 구현은 expert마다 torch.where(router_indices == expert_idx)를 호출할 수 있는데, 이 연산은 결과 크기가 batch마다 달라지는 data-dependent path라 synchronization을 유발하기 쉽다. expert 수가 늘면 이 동적 질의도 expert 수만큼 반복된다.
Unsloth Zoo의 변경은 expert assignment를 한 번 flatten하고, expert ID 기준으로 stable sort한 뒤, bincount로 expert별 token 수를 한 번 구하고, offset으로 slice하는 방식이다.
핵심은 라우팅 논리를 바꾼 것이 아니라, runtime에 “이번 expert에 token이 몇 개냐”고 반복해서 묻는 횟수를 줄였다는 점이다.
| 최적화 | 줄인 병목 | 공개된 구현 근거 |
|---|---|---|
| Packed-sequence metadata caching | layer마다 같은 packed metadata와 mask를 재구성하며 생기는 D2H sync | unslothai/unsloth PR #4243, 2026-03-12 merge |
| Double-buffered checkpoint reload | offloaded activation의 H2D copy와 backward compute가 한 buffer에서 직렬화되는 문제 | unslothai/unsloth-zoo PR #534, 2026-05-04 merge |
| GPT-OSS MoE routing 최적화 | expert별 torch.where가 만드는 반복 동적 indexing/sync |
unslothai/unsloth-zoo PR #535, 2026-03-18 merge |
공개된 근거에서 확인되는 점
공식 글의 수치 중 가장 큰 headline은 packed-sequence metadata caching이다.Qwen3-14B QLoRA SFT 기준으로 forward는 +43.3%, backward는 +5.8%, per-batch는 +14.3% 빨라졌다고 제시된다. forward 쪽 개선 폭이 큰 이유도 자연스럽다.
같은 packed metadata와 mask preparation이 여러 layer의 forward path에서 반복되기 때문이다.
Unsloth는 Blackwell GPU에서의 microbenchmark도 함께 적었다.
낮은 수준의 host-visible metadata call 자체는 약 0.2 ms로 작았지만, packed SDPA mask construction path는 synthetic packed batch, 총 2048 packed token 기준 약 13.7 ms로 측정됐다고 설명한다.
더 작은 모델에서도 비슷한 패턴이 나온다.Llama-3.2-1B 16-layer run에서는 step당 약 199 ms, end-to-end step time 기준 약 11.5%가 줄었고, Qwen3-0.6B 28-layer run에서는 step당 약 319 ms, 약 14.8%가 줄었다고 정리한다.
Double-buffered checkpoint reload는 NVIDIA B200 Blackwell GPU에서 benchmark됐다.
큰 dense model run 기준으로 8B는 0.3739 -> 0.4053 steps/s, 즉 +8.40%, 14B는 0.2245 -> 0.2395 steps/s, +6.70%, 32B는 0.1979 -> 0.2070 steps/s, +4.61% 개선으로 제시된다.
추가 VRAM 비용은 각각 +0.37 GB, +0.47 GB, +0.23 GB 수준이었고, final loss는 사실상 변하지 않았다고 설명한다.
MoE routing 쪽은 더 좁은 최적화지만 방향은 같다.
공식 글은 GPT-OSS-specific routing improvement에 대해 팀 validation에서 대략 10-15% 속도 향상을 봤고, target routing path에서는 forward +23%, backward +13%를 확인했다고 적는다.
PR 설명도 기존 torch.where 반복이 expert 수만큼 CUDA synchronization point를 만들 수 있고, argsort + bincount + offset 방식으로 이를 한 번의 동기화에 가깝게 줄인다고 설명한다.
| 항목 | 대표 측정 결과 | 해석 |
|---|---|---|
| Packed-sequence metadata caching | Qwen3-14B QLoRA SFT per-batch +14.3% |
같은 packed batch metadata를 layer마다 다시 만들지 않음 |
| Packed SDPA mask construction | synthetic 2048 packed token 기준 약 13.7 ms |
작은 host call보다 mask rebuild 자체가 반복 비용의 큰 축 |
| Double-buffered checkpoint reload | B200 기준 8B +8.40%, 14B +6.70%, 32B +4.61% |
H2D copy를 backward compute 뒤에 숨김 |
| Double buffer VRAM overhead | +0.23 GB~+0.47 GB |
속도 향상 대비 비교적 작은 추가 메모리 비용 |
| GPT-OSS MoE routing | team validation 10-15%, target path forward +23% |
expert별 동적 token query를 group-once 방식으로 축소 |
실무 관점에서의 해석
이 사례에서 가장 중요한 교훈은 학습 최적화가 항상 더 화려한 kernel에서만 나오지 않는다는 점이다.
이미 FlashAttention, SDPA, xFormers, checkpointing, packing 같은 구성요소를 쓰고 있어도, 그 사이를 연결하는 Python/PyTorch glue code가 작은 동기화 지점을 만들 수 있다.
GPU utilization을 올리는 마지막 몇 퍼센트는 이런 지점들을 찾아 없애는 데서 나온다.
특히 fine-tuning 팀 입장에서는 packed sequence와 gradient checkpointing을 거의 기본값처럼 사용한다.
그렇다면 이 개선은 특정 benchmark hack이라기보다, 일상적인 LoRA/QLoRA 학습 경로에서 발생하는 overhead hygiene에 가깝다.
같은 batch 경계 정보를 반복 계산하지 말고, CPU-GPU copy가 보이면 compute와 겹칠 수 있는지 확인하고, 동적 shape query를 반복하는 loop를 stable grouping으로 바꾸라는 식의 원칙은 다른 학습 스택에도 그대로 적용된다.
다만 모든 환경에서 같은 숫자가 나온다고 읽으면 안 된다.
공개 수치는 Blackwell/B200, 특정 model size, packed sequence 사용 여부, checkpointing 설정, MoE backend에 강하게 의존한다.
또한 공식 글이 말하는 “약 25%“는 여러 개선의 조합과 적용 경로를 묶은 제품적 headline에 가깝고, 개별 run에서는 4-15%대의 개선도 함께 보인다.
따라서 이 글은 보편적 상수보다 병목을 찾는 방향을 보여주는 사례로 읽는 편이 안전하다.
그럼에도 이 협업은 최근 LLM 학습 시스템의 성숙도를 잘 보여준다.
큰 모델을 더 싸게 학습하려면 알고리즘뿐 아니라 runtime의 작은 대기 시간을 계속 제거해야 한다.
모델이 커지고 GPU가 빨라질수록, “커널 밖의 시간”은 더 비싸진다.
Unsloth와 NVIDIA의 이번 작업은 그 비용을 실제 PR과 benchmark로 줄여 보인, 꽤 실용적인 시스템 최적화 사례다.