장기 실행 에이전트의 메모리 문제는 점점 더 단순한 “컨텍스트 창이 작다”의 문제가 아니다. 웹을 탐색하고, API를 호출하고, 중간 로그를 남기고, 이전 실패를 참고하고, 여러 턴 뒤 과거 화면이나 액션을 다시 찾아야 하는 에이전트에게 history는 작업 자산이면서 동시에 비용 폭탄이다. 원문 trajectory를 계속 프롬프트에 넣으면 토큰이 터지고, 요약하면 나중에 필요한 세부가 사라지며, 텍스트 검색만으로는 UI 구조와 장기 순서를 충분히 보존하기 어렵다.
OCR-Memory: Optical Context Retrieval for Long-Horizon Agent Memory는 이 병목을 꽤 독특한 방식으로 건드린다. 논문은 에이전트 경험을 텍스트 로그로만 저장하지 않고, 상호작용 기록을 multi-resolution 이미지로 렌더링한 뒤, 시각적 anchor를 통해 관련 위치를 찾고, 최종적으로는 해당 index에 연결된 원문 텍스트를 결정적으로 fetch하는 구조를 제안한다. 즉 기억을 “요약 생성” 문제가 아니라 시각적 locate-and-transcribe 검색 문제로 바꾼다.
논문은 2026년 4월 29일 arXiv에 공개되었고, arXiv 메타데이터 기준 ACL 2026 Main Conference accepted로 표시되어 있다. 별도 공식 GitHub, 프로젝트 페이지, Hugging Face release는 arXiv abs/html 표면에서 확인되지 않는다. 따라서 현재 공개 근거의 중심은 논문 본문, arXiv HTML figure/table, 그리고 paper가 보고한 실험 수치다.
무엇을 해결하려는가
에이전트 메모리의 가장 흔한 기본값은 세 가지다. 첫째, 이전 trajectory를 가능한 한 텍스트로 많이 넣는다. 둘째, 길어지면 요약한다. 셋째, 벡터 검색으로 관련 chunk를 가져온다. 모두 실무적으로 유용하지만, long-horizon task에서는 각자 약점이 선명하다.
원문을 그대로 넣는 방식은 faithful하지만 token budget을 너무 빨리 소모한다. 요약은 비용을 줄이지만 무엇이 나중에 중요해질지 예측하기 어렵고, 매끄러운 요약문 속에서 근거 손실이 숨어 버린다. 텍스트 RAG는 검색 가능한 외부 메모리를 만들지만, UI 화면의 구조, 여러 단계에 걸친 action history, 특정 위치의 세부 문구처럼 structural grounding이 필요한 장면에서는 evidence가 쪼개지거나 빠질 수 있다.
OCR-Memory의 문제의식은 여기서 출발한다. 에이전트가 긴 history를 “다시 읽어야” 한다면, 꼭 그 history를 전부 텍스트 토큰으로 보관해야 할까? 사람은 오래된 기억을 모든 글자 단위로 들고 있지 않고, 흐릿한 장면이나 위치감을 통해 단서를 찾은 뒤 필요한 세부를 다시 복원한다. 논문은 이 비유를 시스템으로 옮겨, history를 고밀도 시각 표현으로 압축하고, 필요한 순간에만 관련 segment의 원문을 되찾는 방식을 택한다.
핵심 아이디어 / 구조 / 동작 방식
OCR-Memory의 핵심은 memory bank를 세 부분으로 나누는 것이다. 하나는 trajectory chunk를 렌더링한 이미지다. 다른 하나는 이미지 속 segment와 1:1로 연결된 원문 텍스트 로그다. 마지막은 episode id, timestamp 같은 metadata다. primary reasoning agent는 모든 history를 직접 읽지 않는다. 별도의 optical retriever가 query를 보고 이미지 속 관련 segment ID를 고른 뒤, 시스템이 그 ID에 대응하는 원문을 결정적으로 가져와 agent context에 넣는다.
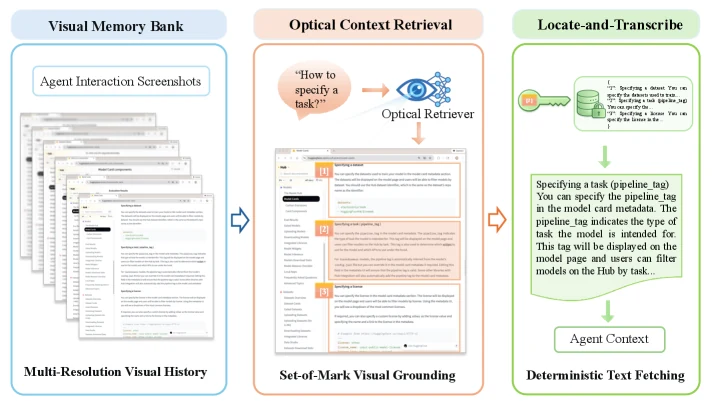
여기서 중요한 장치가 Set-of-Mark, SoM이다. OCR-Memory는 이미지 속 각 텍스트 segment에 빨간 bounding box와 숫자 ID를 붙인다. 모델에게 원문을 자유롭게 생성하라고 하지 않고, “어떤 ID가 query와 관련 있는가”를 0/1 label vector로 고르게 한다. 이후 텍스트는 모델이 생성하지 않는다. 저장된 로그에서 해당 ID의 원문을 그대로 가져온다.
이 설계는 역할 분리를 만든다. optical retriever는 reasoning을 하지 않는다. 관련 evidence의 위치를 찾는다. primary agent는 retrieved evidence를 보고 reasoning한다. 논문이 강조하는 hallucination 감소도 이 지점에서 나온다. free-form OCR/text generation으로 근거를 다시 쓰는 것이 아니라, index를 고르고 원문을 fetch하기 때문에 “선택된 segment가 정확히 어떤 텍스트였는가”는 deterministic하다.
또 하나의 장치는 multi-resolution active recall이다. 최근 상호작용은 1024×1024 고해상도 이미지로 유지하고, 오래된 history는 512×512 저해상도 이미지로 낮춘다. 오래된 기억은 흐릿하지만 전체 맥락과 위치 단서는 남아 있다. 만약 저해상도 memory에서 관련 segment가 발견되면, 원래 로그로부터 고해상도 이미지를 다시 렌더링해 episode 동안 active visual cache에 유지한다. 논문은 이를 human memory의 “vivid-to-fuzzy” 성질을 모방한 optical forgetting으로 설명한다.
학습 측면에서는 DeepSeek-OCR 3B를 기반으로 한다. 사전학습 모델은 literal transcription에는 강하지만 query와 supporting evidence를 맞추는 instruction-following retrieval에는 바로 최적화되어 있지 않다. 그래서 논문은 HotpotQA의 supporting facts를 재활용해, paragraph들을 SoM이 붙은 이미지로 렌더링하고, question에 대해 어떤 paragraph가 supporting fact인지 binary vector로 맞추도록 fine-tuning한다. 구현 세부는 vision encoder를 freeze하고 language decoder 쪽에 LoRA를 적용하는 방식이다.
공개된 근거에서 확인되는 점
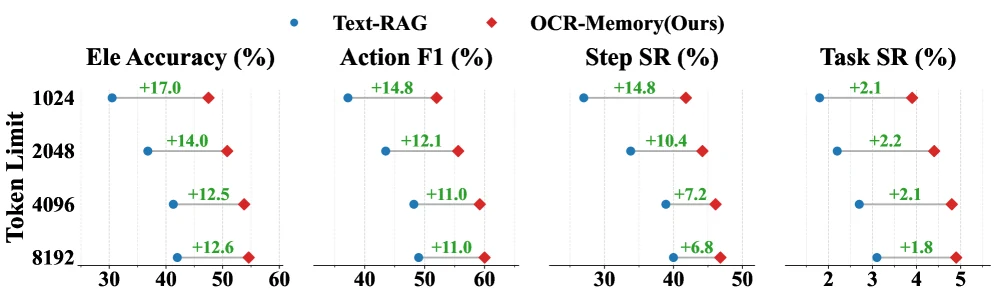
주요 실험은 Mind2Web과 AppWorld에서 진행된다. Mind2Web은 웹 navigation task에서 element accuracy, action F1, step success, task success를 보고하고, AppWorld는 API interaction task의 difficulty별 success rate를 본다. 논문은 memory module의 context window를 기본 4096 tokens로 제한한 상태에서 비교한다.
| 방법 | Mind2Web Ele Acc | Mind2Web Step SR | Mind2Web Task SR | AppWorld Hard SR | AppWorld Avg SR |
|---|---|---|---|---|---|
| Zero-Shot | 40.1 | 37.9 | 2.2 | 20.9 | 41.9 |
| Dense Retrieval | 41.3 | 38.9 | 2.7 | 21.4 | 46.2 |
| MemoryBank | 43.8 | 39.2 | 3.3 | 24.9 | 52.1 |
| AWM | 49.1 | 42.6 | 4.3 | 27.2 | 55.0 |
| ACON | 48.2 | 41.4 | 4.1 | 28.7 | 56.2 |
| OCR-Memory | 53.8 | 46.1 | 4.8 | 30.8 | 58.1 |
결과만 보면 OCR-Memory는 특히 structural grounding이 필요한 지표에서 강하다. Mind2Web Element Accuracy는 AWM의 49.1에서 53.8로 올라가고, Step Success Rate는 42.6에서 46.1로 올라간다. AppWorld에서도 평균 success rate가 58.1로 가장 높고, Hard subset은 30.8로 Retrieval baseline의 21.4와 AWM의 27.2를 앞선다. 절대 Task SR 자체는 여전히 낮지만, long-horizon agent task의 난도를 감안하면 memory mechanism의 차이가 성능으로 드러난다는 점이 핵심이다.
Ablation은 이 구조가 단순히 “이미지를 썼다”가 아니라, index 기반 retrieval과 multi-resolution 정책의 조합이라는 점을 보여 준다. SoM을 제거하고 원문을 생성하게 하면 latency가 크게 증가하고 성능도 떨어진다. bounding box를 직접 예측하는 방식은 text generation보다는 빠르지만, segment ID를 고르는 방식만큼 정확하지 않다.
| 구성 | Ele Acc | Step SR | Retrieval latency |
|---|---|---|---|
| OCR-Memory full | 53.8 | 46.1 | 1.7s |
| w/o SoM, Text Gen | 46.5 | 39.2 | 5.3s |
| w/o SoM, BBox | 49.2 | 44.5 | 2.1s |
Multi-resolution active recall도 비용-성능 trade-off를 잘 보여 준다. 모든 history를 저해상도로 두면 visual token은 적게 쓰지만 Step SR이 39.7로 떨어진다. 모든 history를 고해상도로 두면 Step SR은 46.5로 높지만 평균 visual token이 256으로 커진다. dynamic 방식은 Step SR 46.1을 유지하면서 평균 token을 82로 낮춘다. 고해상도 fidelity와 저해상도 비용 사이의 중간점을 찾는 셈이다.
| Resolution strategy | Step SR | Task SR | Avg visual tokens |
|---|---|---|---|
| Static Low-Res | 39.7 | 2.9 | 65 |
| Static High-Res | 46.5 | 4.9 | 256 |
| Dynamic active recall | 46.1 | 4.8 | 82 |
긴 context에서 retrieval fidelity를 직접 보는 Needle-in-a-Haystack 실험도 흥미롭다. 논문은 RULER benchmark를 agent setting에 맞게 변형해 문서를 이미지로 렌더링하고 Recall@1을 측정한다. 4k context에서는 98.5%, 32k context에서도 94.1%를 유지하며, raw text 대비 visual token compression ratio는 대략 10× 수준으로 보고한다.
| Context length | Visual token compression | Recall@1 |
|---|---|---|
| 4k | 10.3× | 98.5 |
| 8k | 10.2× | 97.2 |
| 16k | 10.7× | 95.8 |
| 32k | 10.6× | 94.1 |
다만 OCR-Memory가 모든 자원을 줄이는 것은 아니다. 시스템 효율성 표를 보면 reasoning LLM에 들어가는 text tokens per step은 Text-RAG의 3,980에서 OCR-Memory의 596으로 줄어든다. 약 6.7× 감소다. 하지만 disk per episode는 18KB에서 1.47MB로 늘고, retrieval latency는 0.3초에서 1.7초로 늘어난다. 즉 비용을 없애는 기술이라기보다, scarce reasoning context token을 더 싼 저장공간·전처리·retrieval latency로 바꾸는 기술이다.
retrieval-level 평가도 이 논문의 중요한 근거다. Mind2Web에서 만든 Experience Retrieval Evaluation Subset에서 Dense Text-RAG는 Recall@1 52.7, Recall@10 82.1, MRR 0.61을 기록한다. OCR-Memory는 Recall@1 78.6, Recall@10 96.2, MRR 0.84로 오른다. 또한 content-level faithfulness에서 free-form generative retrieval variant는 84.3%인 반면, OCR-Memory는 segment index를 고른 뒤 원문을 fetch하기 때문에 100.0%로 보고된다. 다만 이 100%는 “선택된 segment의 텍스트가 원문과 일치한다”는 뜻이지, 선택된 segment가 항상 task에 관련 있다는 뜻은 아니다.
실무 관점에서의 해석
내가 보기에 OCR-Memory의 핵심 메시지는 “agent memory는 더 긴 텍스트 프롬프트가 아니라, 증거를 찾는 별도 하네스가 되어야 한다”는 것이다. 장기 실행 에이전트에서 memory는 단순히 모델이 더 많이 기억하게 하는 장치가 아니다. 어떤 history를 고밀도로 저장하고, 어떤 단서로 다시 찾고, reasoning context에는 얼마나 좁게 주입할지 결정하는 시스템 레이어다.
이 관점은 특히 웹·UI·데스크톱·API 에이전트에 잘 맞는다. 이런 환경의 history는 자연어 대화만으로 구성되지 않는다. 화면 레이아웃, 버튼 위치, 폼 구조, 이전 action의 순서, 특정 로그 줄, 테이블 셀 같은 정보가 섞인다. 텍스트 chunk만으로 검색하면 구조적 단서가 약해질 수 있고, 요약하면 나중에 필요한 세부가 사라질 수 있다. OCR-Memory는 시각적 representation을 통해 이 구조를 압축해 보존하려는 시도다.
동시에 이 방식은 꽤 무거운 시스템 가정을 둔다. 논문 자체도 limitation에서 training-free baseline과 달리 specialized optical retrieval model을 fine-tune해야 하며, interaction log를 이미지로 렌더링하는 비용과 disk 사용량, vision encoder를 함께 유지하는 memory footprint가 추가된다고 인정한다. 따라서 작은 챗봇이나 짧은 tool-use workflow에는 과한 해법일 수 있다. 반대로 긴 세션, 반복되는 웹 navigation, 많은 history backtracking, 엄격한 context budget이 동시에 존재하는 agent product라면 검토할 가치가 있다.
또 하나의 현실적 제약은 공개 구현 표면이다. arXiv abs/html에서 별도 Code 링크나 프로젝트 페이지는 확인되지 않았고, Hugging Face Papers 페이지도 조회 시점에는 공개 markdown/page가 없었다. 그래서 현재 독자가 바로 재현할 수 있는 연구 코드 번들로 보기보다는, 논문 중심의 방법 제안과 실험 보고로 보는 편이 안전하다. DeepSeek-OCR 기반 fine-tuning, HotpotQA repurposing, SoM rendering, active recall cache 같은 세부가 Appendix에 비교적 구체적으로 쓰여 있지만, production 적용에는 별도 구현 부담이 남아 있다.
그럼에도 이 논문은 agent memory 논의에서 좋은 방향 전환을 제안한다. 지금까지 많은 memory system은 “무엇을 요약할 것인가” 또는 “무엇을 검색할 것인가”에 집중했다. OCR-Memory는 한 걸음 더 나아가 기억을 어떤 modality로 저장해야 가장 token-efficient하게 다시 찾을 수 있는가를 묻는다. 장기 실행 에이전트가 실제 제품의 기본 인터페이스가 된다면, memory는 text store 하나가 아니라 text log, visual index, deterministic fetch, active cache가 결합된 다층 시스템이 될 가능성이 크다.