검색 증강 생성(RAG)의 기본 가정은 오랫동안 비슷했다. 문서를 chunk로 나누고, sparse/dense index를 만들고, 질문이 들어오면 top-k 후보를 꺼낸 뒤, 그 후보 안에서 모델이 답을 조합한다. 이 구조는 빠르고 운영하기 쉽지만, 에이전트가 여러 단계로 단서를 찾아야 하는 딥서치 문제에서는 묘한 병목이 된다. 모델이 아무리 강해도, retriever가 처음에 버린 증거는 뒤에서 다시 볼 수 없기 때문이다.
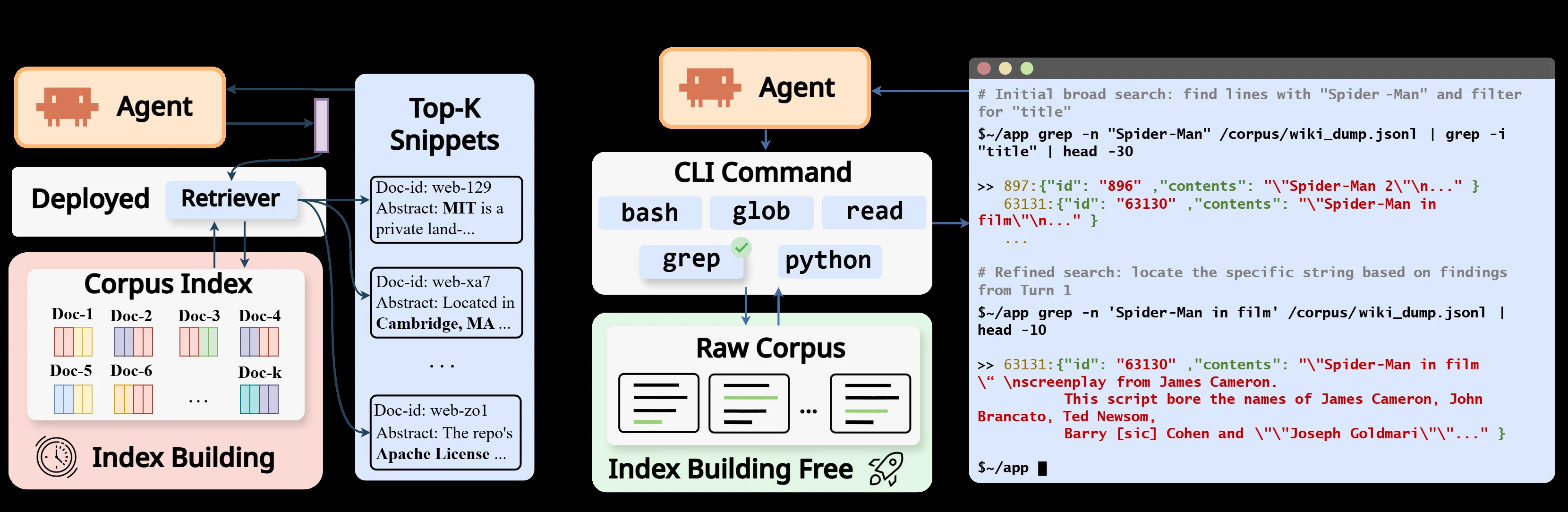
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction는 이 병목을 검색 모델의 성능 부족이 아니라 corpus를 노출하는 인터페이스의 해상도 부족으로 해석한다. 논문이 제안하는 Direct Corpus Interaction(DCI)은 별도의 임베딩 모델, vector index, retrieval API 없이 에이전트가 raw corpus를 직접 다루게 한다. 도구는 거창하지 않다. grep, rg, find, glob, read, bash, 작은 스크립트 같은 일반 터미널 도구다.
흥미로운 점은 이 단순한 방향이 단순한 데모가 아니라는 데 있다. 논문은 DCI-Agent-Lite라는 최소 구현체와 Claude Code 기반의 DCI-Agent-CC를 함께 평가하고, BrowseComp-Plus, multi-hop QA, BRIGHT/BEIR IR ranking에서 기존 sparse/dense/re-ranking 또는 retrieval-agent baseline을 꽤 큰 폭으로 앞선다고 보고한다. 즉 이 글의 핵심은 “검색을 버리자”가 아니라, 강한 에이전트에게 어떤 검색 인터페이스를 줘야 하는가다.
무엇을 해결하려는가
기존 retriever-mediated search는 corpus 접근을 “질문 → top-k 문서/스니펫”으로 압축한다. 이 추상화는 일반적인 QA나 검색 결과 노출에는 효율적이지만, agentic search에서는 불리할 수 있다. BrowseComp-Plus 같은 문제는 중간 entity를 찾고, 희박한 단서를 묶고, 정확한 문자열 제약을 걸고, 한 문서 안의 주변 문맥을 여러 번 확인하는 행동을 요구한다.
예를 들어 “어떤 인터뷰의 세 번째 마지막 질문에서 언급된 별명의 출처” 같은 문제는 단순 semantic similarity만으로 풀기 어렵다. 먼저 후보 문서를 넓게 찾고, 특정 표현이 들어간 줄을 좁히고, 주변 문맥을 읽고, 그 단서에서 다시 다른 entity를 찾아야 한다. 이때 retriever가 반환한 snippet이 너무 짧거나, top-k 밖에 결정적 단서가 있거나, 여러 조건을 동시에 만족하는 문서를 직접 필터링해야 하면 에이전트는 retriever API의 형식에 갇힌다.
DCI의 문제의식은 여기서 출발한다. 검색 품질은 embedding similarity나 reranker만의 함수가 아니라, 에이전트가 corpus와 상호작용할 수 있는 조작 단위의 함수라는 것이다. 문서 단위 top-k만 볼 수 있는 인터페이스와, 파일 경로·줄 번호·정규식 매치·주변 context·파이프라인 조합을 직접 만들 수 있는 인터페이스는 같은 corpus를 전혀 다르게 노출한다.
핵심 아이디어 / 구조 / 동작 방식
DCI는 retriever를 더 정교하게 만드는 대신, 에이전트에게 raw corpus 위의 범용 조작권을 준다. 논문은 이를 두 가지 구현체로 나눈다.
| 구현체 | 기반 | 도구/환경 | 해석 |
|---|---|---|---|
| DCI-Agent-Lite | Pi 기반의 최소 coding-agent scaffold | bash, read, rg 중심, runtime context management 포함 |
DCI 인터페이스 자체의 효과를 보기 위한 경량 구현 |
| DCI-Agent-CC | Claude Code 기반 | Claude Code의 도구 오케스트레이션을 사용하되 web-search, web-fetch, subagent는 비활성화 | 강한 harness에서 DCI의 성능 상한을 보는 구현 |
이 구조에서 중요한 것은 DCI가 “검색 도구가 많은 agent”가 아니라는 점이다. 오히려 반대에 가깝다. DCI-Agent-Lite는 retrieval-specific module이 없고, offline indexing도 없다. corpus를 다운로드해 로컬 파일로 놓고, 에이전트는 grep -n, find, head, sed, python 같은 일반 도구를 조합해 단서를 찾는다.
이 방식은 세 가지 행동을 자연스럽게 만든다.
- 정확한 lexical constraint: 특정 문자열, 이름, 날짜, 표현을 정규식이나 pipe로 강하게 제한한다.
- local context verification: 매치된 줄만 보는 것이 아니라 주변 문맥을 읽어 가설을 검증한다.
- iterative hypothesis refinement: 한 단서에서 다음 검색어를 만들고, 다시 좁히고, 실패하면 다른 경로로 되돌아간다.
논문은 이 차이를 retrieval interface resolution이라고 부른다. retriever가 문서 또는 passage 단위 후보를 반환하는 저해상도 인터페이스라면, DCI는 줄, span, 파일 경로, regex match, local neighborhood까지 내려가는 고해상도 인터페이스다. 강한 LLM 에이전트가 실제 연구자처럼 “찾고, 줄이고, 읽고, 다시 찾는” 행동을 할 수 있다면, 이 고해상도 인터페이스가 downstream reasoning보다 앞단의 병목을 줄인다.
공개된 근거에서 확인되는 점
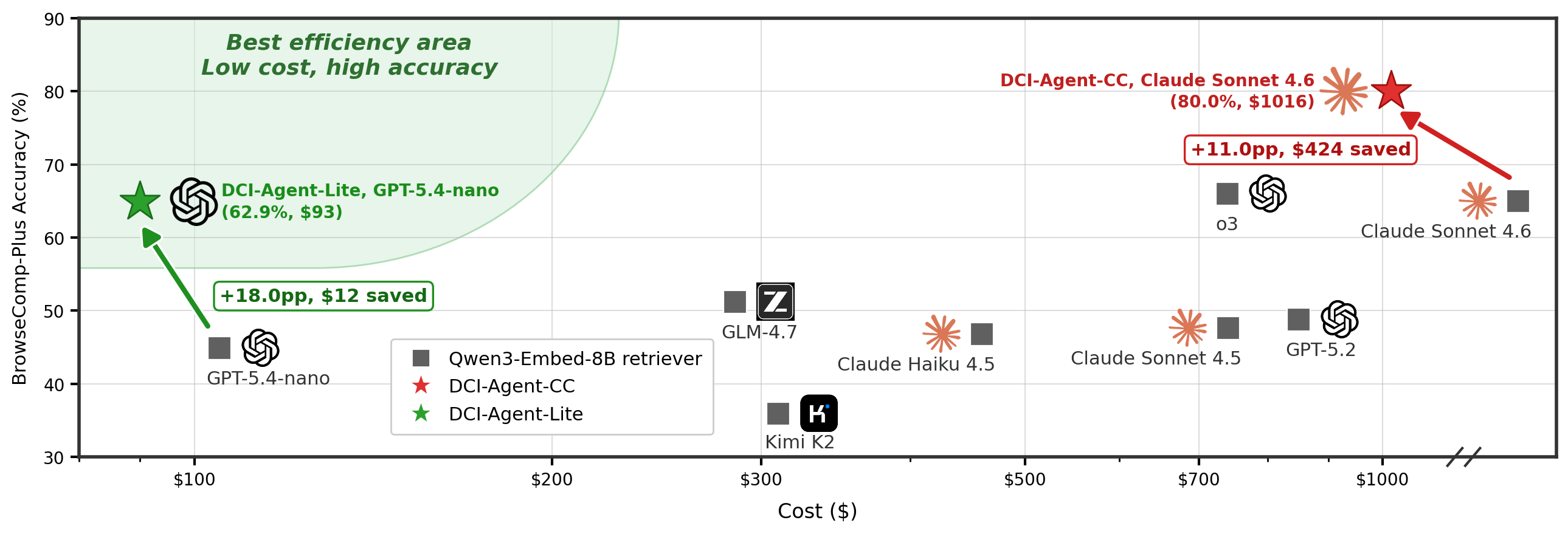
공식 논문과 저장소가 보여주는 수치는 꽤 공격적이다. BrowseComp-Plus에서는 같은 Claude Sonnet 4.6 backbone에서 Qwen3-Embedding-8B retrieval tool을 DCI로 바꾸면 정확도가 69.0%에서 80.0%로 올라가고, 평가 비용은 $1,440에서 $1,016으로 내려간다고 보고한다. DCI-Agent-Lite는 GPT-5.4 nano 기반으로 62.9%를 $93 비용에 달성해, 더 비싼 retrieval-agent와 다른 비용-성능 지점을 만든다.
multi-hop QA와 IR ranking에서도 메시지는 비슷하다.
| 평가 축 | 강한 baseline | DCI 결과 | 읽을 포인트 |
|---|---|---|---|
| BrowseComp-Plus | Claude Sonnet 4.6 + Qwen3-Embedding-8B 69.0% | DCI-Agent-CC 80.0% | 같은 backbone에서 retrieval interface만 바꿔 +11.0p |
| Multi-hop QA 평균 | ASearcher-Local-14B 52.3 | DCI-Agent-CC 83.0 | NQ, TriviaQA, Bamboogle, HotpotQA, 2Wiki, MuSiQue 평균에서 +30.7p |
| IR ranking 평균 NDCG@10 | ReasonRank-32B 47.0 | DCI-Agent-CC 68.5 | BRIGHT 4개와 BEIR 2개 subset 평균에서 +21.5p |
| 경량 DCI | retrieval-agent baseline 대비 혼합 | DCI-Agent-Lite QA 평균 68.0, IR 평균 56.7 | 최소 도구 scaffold만으로도 retrieval baseline을 넘는 구간이 있음 |
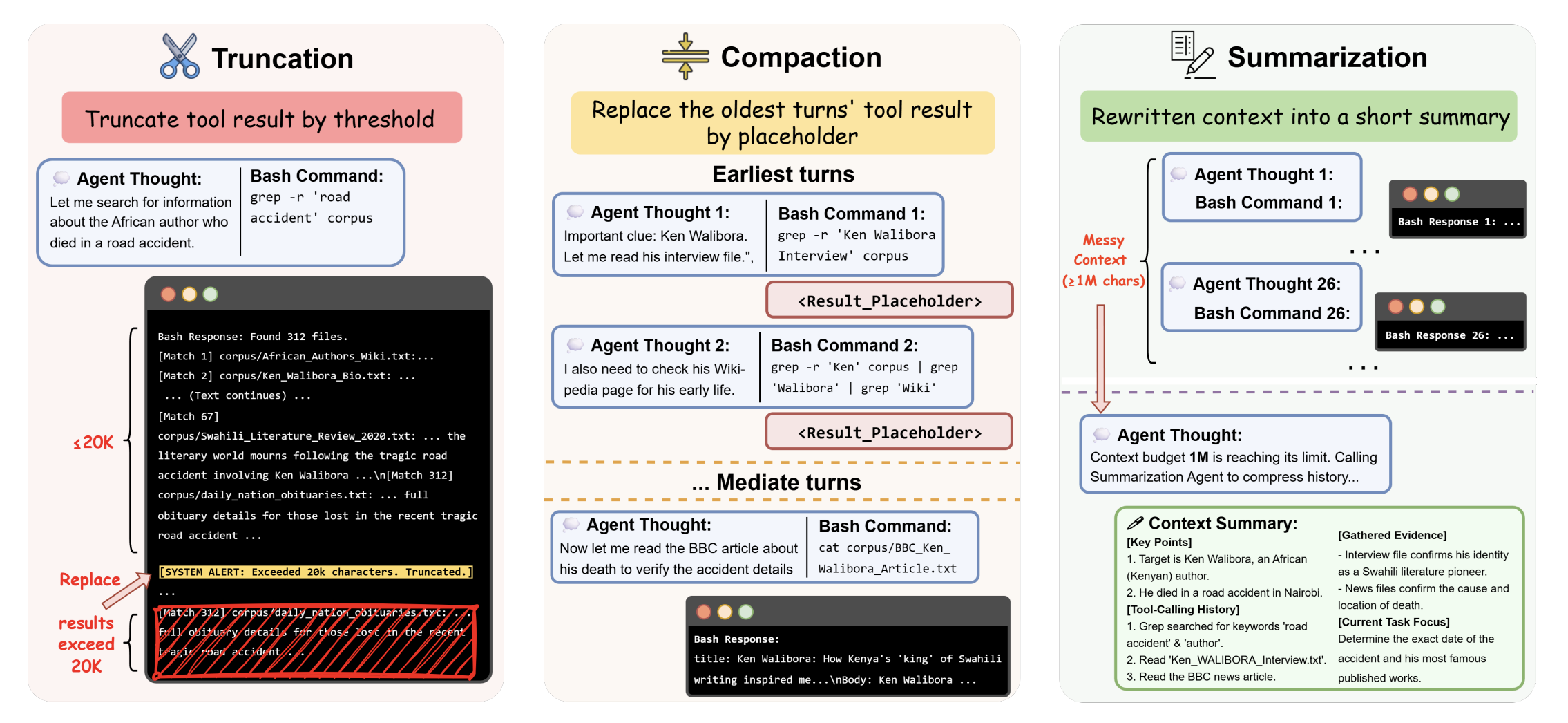
특히 중요한 것은 trajectory 분석이다. DCI-Agent-Lite는 Qwen3-Embedding-8B보다 gold document를 더 많이 회수해서 이기는 것이 아니었다. BrowseComp-Plus subset 분석에서 mean gold-document coverage는 DCI가 28.0으로 Qwen3-Embedding-8B의 56.7보다 낮다. 하지만 coverage_any는 70.0 대 74.0으로 비슷하고, localization score는 48.4 대 21.7로 DCI가 훨씬 높다. 즉 DCI는 모든 gold chain을 넓게 회수하기보다, 일단 유용한 문서 하나에 닿으면 그 안에서 더 정밀하게 파고드는 방식으로 이득을 얻는다.
논문은 DCI-Agent-CC의 도구 사용도 분석한다. 전체 tool call에서 Bash가 62.4%, grep 계열이 33.0%를 차지한다. Bash 내부에서도 chained search, local context peeking, regex matching, file localization이 주된 행동으로 나타난다. 이는 DCI의 강점이 복잡한 custom script 작성에 있다기보다, 단순한 텍스트 검색과 주변 문맥 확인을 반복적으로 조합하는 데 있음을 보여준다.
공개 아티팩트도 함께 볼 필요가 있다. 공식 GitHub 저장소 DCI-Agent/DCI-Agent-Lite는 MIT 라이선스, Python 패키지명 dci, dci-agent-lite CLI, setup.sh, benchmark/corpus 다운로드 스크립트, Pi 기반 실행 예제를 포함한다. 조회 시점 기준 GitHub API는 71 stars, 4 forks, 기본 브랜치 main, /releases/latest 404, tags 없음으로 응답했다. 따라서 현재 형태는 완성된 production retrieval framework라기보다, 논문 결과를 검토하고 일부 benchmark run을 재현하기 위한 초기 research harness에 가깝다.
Hugging Face 쪽에는 DCI-Agent/dci-bench, DCI-Agent/corpus, DCI-Agent/eval-logs 데이터셋과 DCI-Agent/demo Space가 공개되어 있다. API 조회 시점 기준 세 데이터셋은 모두 manual gated 상태였고, corpus는 BrowseComp-Plus, BRIGHT 4개 subset, Wikipedia dump 파일을 포함하며 약 16.2GB storage를 사용한다. eval-logs에는 DCI-Agent-CC BrowseComp-Plus run의 JSONL 로그들이 다수 공개되어 있어, 주장된 결과가 단순 요약표에만 머물지 않고 trajectory artifact로도 남아 있다는 점이 눈에 띈다.
실무 관점에서의 해석
DCI의 실무적 의미는 “vector DB를 버리자”가 아니다. 대규모 정적 corpus, latency가 빡빡한 검색 서비스, 사용자-facing 검색 UI에서는 여전히 dense/sparse retrieval이 좋은 기본값이다. DCI가 강한 지점은 조금 다르다. 에이전트가 로컬 지식베이스, 코드베이스, 문서 묶음, 로그, 평가 결과처럼 파일 시스템에 가까운 corpus를 붙잡고 긴 탐색을 해야 할 때다.
이런 환경에서는 offline index를 만드는 비용과 freshness 문제가 실제 병목이 된다. 문서가 계속 바뀌거나, 파일 구조 자체가 단서가 되거나, 검색 조건이 매번 바뀌면 top-k retriever는 너무 이른 추상화일 수 있다. 반대로 DCI는 별도 인덱스를 만들지 않고도 바로 시작할 수 있고, 에이전트가 파일명·디렉터리·문자열·주변 문맥을 하나의 탐색 공간으로 쓸 수 있다.
하지만 한계도 명확하다. DCI는 search breadth가 커질수록 비용이 빠르게 증가한다. 논문은 BrowseComp-Plus corpus를 100K에서 200K 문서로 늘리면 DCI-Agent-CC의 평균 tool call이 38.5에서 86.9로 증가하고, latency와 cost가 두 배 이상 늘며, 정확도는 13.6p 떨어진다고 보고한다. 400K 문서에서는 성능 저하가 더 크다. 즉 DCI는 “유망한 문서에 도달한 뒤”의 고해상도 탐색에는 강하지만, 너무 넓은 후보 공간에서 첫 anchor를 찾는 비용은 여전히 문제다.
그래서 제품 관점에서는 hybrid가 자연스럽다. 넓은 웹 또는 수천만 문서에서는 retriever가 첫 후보 영역을 잡고, 그 다음 에이전트가 DCI식 로컬 탐색으로 증거를 검증하는 구조가 더 현실적이다. 코드베이스 QA, 기업 내부 문서 검색, 실험 로그 분석, 로컬 Obsidian/Notion export 탐색, benchmark corpus 조사처럼 corpus가 파일화되어 있고 정밀한 근거 확인이 중요한 환경에서는 DCI가 특히 매력적인 선택지가 된다.
내가 보기에 이 논문의 가장 큰 기여는 retrieval을 “어떤 embedding model이 더 좋은가”의 싸움에서 한 단계 옮겼다는 데 있다. 강한 에이전트에게는 top-k snippet보다 raw corpus를 직접 조작하는 인터페이스가 더 잘 맞는 순간이 있다. 앞으로 agentic RAG나 deep research 시스템을 평가할 때는 retriever 성능뿐 아니라, 에이전트가 증거를 어떤 해상도로 관찰하고, 어떤 단위로 조작하고, 실패했을 때 어떤 경로로 돌아갈 수 있는지를 함께 봐야 한다.