Agentic RAG를 이야기할 때 논의는 자주 “벡터 검색이 좋은가, 키워드 검색이 좋은가”로 좁혀진다. 하지만 실제 에이전트 시스템에서는 retriever 하나만 바꿔서 끝나지 않는다. 모델은 어떤 하네스 안에서 실행되는가, 도구 결과는 채팅 컨텍스트에 바로 들어오는가 아니면 파일로 떨어지는가, corpus가 커질수록 불필요한 대화가 얼마나 섞이는가가 모두 함께 성능을 바꾼다.
Is Grep All You Need? How Agent Harnesses Reshape Agentic Search는 이 지점을 정면으로 다루는 짧지만 실무적인 실험 논문이다. 저자들은 LongMemEval의 116개 질문 샘플을 사용해 grep 기반 lexical search와 vector retrieval을 비교한다. 비교 대상도 단일 LangChain류 harness가 아니라, Chronos라는 custom harness와 Claude Code, Codex CLI, Gemini CLI 같은 provider-native CLI harness를 함께 둔다. 같은 conversation data를 놓고도 “검색 방법”만이 아니라 “에이전트가 검색 결과를 어떻게 받는지”를 같이 본다는 점이 이 논문의 핵심이다.
결론을 한 줄로 줄이면 이렇다. 이 실험 분포에서는 inline grep이 매우 강한 기본값이지만, grep이 항상 이긴다는 뜻은 아니다. 하네스와 tool-output delivery가 바뀌면 같은 retriever의 의미도 바뀐다.
무엇을 해결하려는가
대부분의 RAG 평가는 retriever를 비교할 때 검색기를 비교한다. BM25, dense embedding, reranker, hybrid index를 같은 query-document task 위에서 재고, top-k recall이나 nDCG 같은 지표를 본다. 이 평가는 여전히 중요하지만, 에이전트 루프에서는 검색기가 반환한 결과가 끝이 아니다. 모델은 무엇을 다시 검색할지 정하고, tool call을 반복하고, 중간 결과를 읽고, 충분하다고 판단되면 답변을 낸다.
이때 중요한 변수가 하나 더 생긴다. 검색 결과가 모델에게 어떤 형태로 노출되는가다. tool response가 바로 컨텍스트에 주입되면 모델은 그 텍스트를 즉시 읽는다. 반대로 결과가 파일로 저장되고 모델이 별도로 read나 grep을 해야 한다면, retrieval은 단순 정보 검색이 아니라 artifact 탐색 문제가 된다. 같은 검색 결과라도 에이전트가 그것을 소비하는 방식이 달라지는 것이다.
논문은 이 차이를 LongMemEval-S의 장기 대화 기억 QA로 검증한다. 질문은 사용자 선호, 단일 세션 사실, 여러 세션에 걸친 정보, 시간 순서와 기간 계산처럼 “대화 속 어딘가에 있는 증거를 찾아야 하는” 유형으로 구성된다. 이런 과제에서는 정확한 날짜, 이름, 표현, 상태 변화가 답의 핵심이 되는 경우가 많아서 lexical search가 유리할 가능성이 있다. 하지만 그 유리함이 하네스와 delivery 방식 위에서도 유지되는지는 별도 실험이 필요하다.
핵심 아이디어 / 구조 / 동작 방식
실험은 크게 두 축으로 나뉜다. 첫 번째는 retrieval mode, harness, tool-calling method를 함께 바꾸는 factorial 비교다. 두 번째는 관련 oracle session은 유지하면서 주변 distractor session을 늘려, corpus noise가 커질 때 grep과 vector가 어떻게 변하는지 보는 scaling 비교다.
공개 HTML과 PDF 기준으로 실험 구성을 정리하면 다음과 같다.
| 축 | 비교한 선택지 | 읽을 포인트 |
|---|---|---|
| Retrieval | grep 기반 lexical search, vector retrieval | 하나는 raw text/regex match, 다른 하나는 embedding index와 reranking을 사용 |
| Harness | Chronos custom harness, Claude Code, Codex CLI, Gemini CLI | 같은 모델/데이터라도 prompt, tool transcript, shell interface가 달라짐 |
| Delivery | inline tool result, programmatic file-based result | 결과를 바로 읽는가, 파일을 열고 다시 찾아야 하는가의 차이 |
| Dataset | LongMemEval-S 116문항 | 장기 대화 기억, 사용자 사실, 선호, temporal reasoning 중심 |
| Evaluation | GPT-4o auxiliary grader | reference answer와 agent hypothesis를 category-conditioned rubric으로 채점 |
| Noise scaling | s5, s10, s20, s30, full | oracle session은 유지하고 distractor session을 늘려 검색 pool을 키움 |
Chronos 쪽은 LongMemEval dialogue turn과 함께 시간 표현을 구조화한 temporal event를 per-question file로 저장한다. grep tool은 이 raw text와 event record 위에서 regex matching을 수행하고, vector tool은 ingestion 시 만든 per-question index에서 query embedding과 approximate nearest-neighbor search, reranking을 사용한다. CLI harness들은 질문과 동적으로 생성된 search strategy를 받고, 절대 경로의 wrapper script를 bash로 호출하는 형태다.
여기서 논문이 잘 짚은 점은 provider-native CLI harness가 단순히 “다른 UI”가 아니라는 것이다. Claude Code, Codex CLI, Gemini CLI는 shell execution, stdout 처리, file access, tool-use convention이 각각 다르다. 따라서 같은 retriever를 붙여도 모델이 언제 멈추고, 어떤 결과를 다시 읽고, 실패했을 때 어떤 행동으로 돌아가는지가 달라진다.
공개된 근거에서 확인되는 점
Experiment 1의 가장 강한 메시지는 inline delivery에서 나온다. 표 1에 따르면 inline grep은 보고된 모든 harness-model pair에서 inline vector보다 높다. 예를 들어 Chronos + Claude Opus 4.6은 grep 93.1%, vector 83.6%이고, Chronos + Gemini 3.1 Flash-Lite는 grep 86.2%, vector 62.9%다. GPT-5.4 + Codex CLI도 inline grep 93.1%, inline vector 75.9%로 큰 차이를 보인다.
하지만 이 결과를 “grep이 vector보다 본질적으로 우월하다”로 읽으면 곤란하다. 같은 backbone이라도 하네스가 바뀌면 성능 ceiling이 크게 움직인다. 논문은 Claude Opus 4.6이 Chronos inline grep에서는 93.1%지만 Claude Code inline grep에서는 76.7%라고 보고한다. 즉 retriever 차이만큼이나 harness 차이가 크다.
선별된 결과를 줄이면 다음과 같다.
| 조건 | grep inline | vector inline | grep programmatic | vector programmatic | 해석 |
|---|---|---|---|---|---|
| Claude Opus 4.6 / Chronos | 93.1 | 83.6 | 80.2 | 81.9 | inline에서는 grep 우세, 파일 기반에서는 vector가 근소 우세 |
| Claude Opus 4.6 / Claude Code | 76.7 | 75.0 | 68.1 | 79.3 | 같은 모델이라도 Claude Code에서는 programmatic vector가 더 높음 |
| GPT-5.4 / Codex CLI | 93.1 | 75.9 | 55.2 | 67.2 | Codex의 file-based grep은 큰 폭으로 무너짐 |
| Gemini 3.1 Pro / Gemini CLI | 81.9 | 75.0 | 81.0 | 82.8 | programmatic에서는 vector가 근소하게 역전 |
| Gemini 3.1 Flash-Lite / Chronos | 86.2 | 62.9 | 85.3 | 72.4 | 경량 모델에서도 Chronos inline grep의 lexical advantage가 큼 |
Programmatic delivery에서는 그림이 더 복잡해진다. 파일 기반 결과 전달은 검색 결과를 context에 바로 넣지 않고, agent가 별도 파일을 열어 필요한 부분을 소비하게 만든다. 이 경로는 context pressure를 줄일 수 있지만, 동시에 “결과 파일을 찾고 읽는” 추가 행동을 요구한다. 논문은 programmatic vector가 programmatic grep보다 높은 pair가 10개 중 5개라고 보고한다. 특히 GPT-5.4 + Codex CLI는 inline grep 93.1%에서 programmatic grep 55.2%로 급락한다. 검색 자체가 아니라 delivery path가 병목이 될 수 있다는 신호다.
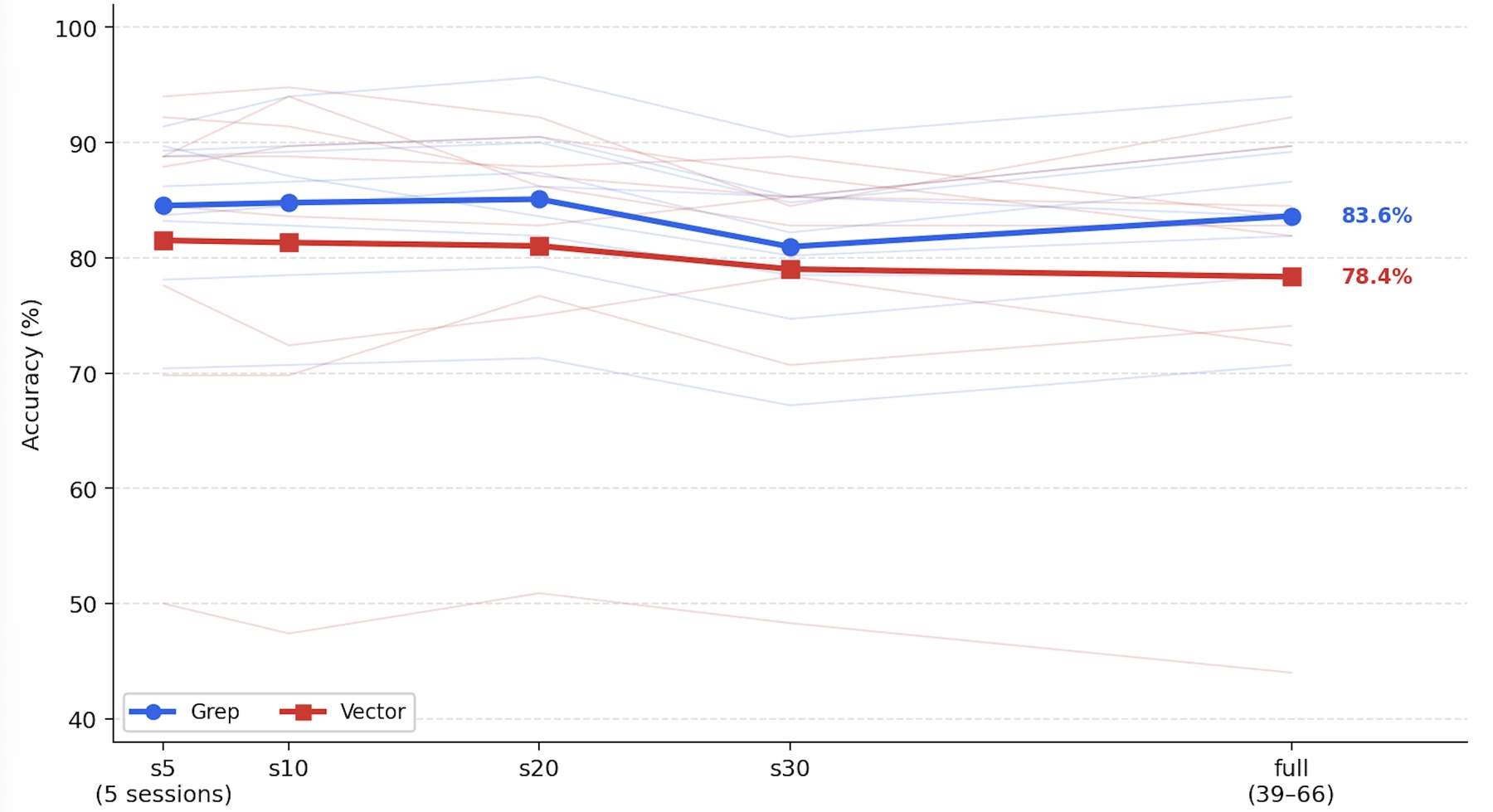
Experiment 2의 noise scaling 결과도 단순하지 않다. full haystack은 문항당 39~66 sessions이고, s5/s10/s20/s30은 oracle session을 유지한 채 distractor를 샘플링해 채운다. 평균선만 보면 grep은 full에서 83.6%, vector는 78.4%로 끝나며 grep이 높다. 그러나 개별 row에서는 vector가 강한 구간도 있다. Chronos + Claude Opus 4.6의 vector는 s10에서 94.8%, full에서 92.2%로 높고, Gemini CLI + Gemini 3.1 Pro는 full에서 vector 89.7%, grep 78.5%로 vector가 계속 앞선다.
논문의 한계도 분명하다. 이 실험은 장기 대화 기억 QA, 특히 verbatim span과 시간 표현이 중요한 분포에 묶여 있다. 과학 논문 synthesis, 이미지가 섞인 문서, code semantics처럼 증거가 더 많이 paraphrase되거나 구조적 의미를 필요로 하는 영역에서는 dense retrieval 또는 hybrid routing의 위치가 달라질 수 있다. 저자들도 grep이 일반적으로 vector를 이긴다고 주장하지 않고, 이 task distribution과 corpus에서 end-to-end로 강하게 나왔다는 점을 강조한다.
또 하나의 release signal은 공개 아티팩트 범위다. arXiv abs와 HTML에서 별도 공식 code/project link는 확인되지 않았고, arXiv ID와 제목 기반 GitHub/Hugging Face 검색에서도 명확한 companion repository, model, dataset은 찾지 못했다. 따라서 현재 글은 paper/html/PDF의 실험 결과와 figure/table에 근거한 분석이지, 바로 실행 가능한 공개 benchmark harness 검토는 아니다.
실무 관점에서의 해석
이 논문이 실무적으로 유용한 이유는 “vector DB를 쓰지 말라”는 결론 때문이 아니다. 오히려 더 중요한 교훈은 agentic search에서 retriever는 독립 부품이 아니라는 점이다. 같은 검색 결과라도 tool message로 들어오는지, shell stdout으로 쌓이는지, 파일로 저장되는지에 따라 모델이 실제로 소비하는 증거가 달라진다. Retrieval quality와 agent harness quality를 분리해 측정하기 어렵다는 뜻이다.
특히 장기 메모리, 고객지원 로그, 실험 로그, 코드베이스, 로컬 노트처럼 정확한 문자열과 주변 문맥이 중요한 corpus에서는 grep류 lexical tool이 생각보다 강한 기본값이 될 수 있다. embedding index를 만들지 않아도 되고, 최신 파일을 즉시 검색할 수 있으며, 날짜·이름·설정값·함수명처럼 verbatim clue가 많은 문제에 잘 맞는다. 이 점은 최근 Direct Corpus Interaction류 논문들이 강조하는 “에이전트에게 raw corpus 조작권을 주자”는 흐름과도 연결된다.
하지만 grep의 강점은 “단순함”에서 오면서 동시에 한계를 가진다. query 표현과 evidence 표현이 다르면 놓치기 쉽고, corpus가 커질수록 anchor term을 잘 못 잡으면 검색 폭이 빠르게 커진다. 반대로 vector retrieval은 paraphrase와 semantic neighborhood를 더 잘 잡을 수 있지만, agent loop 안에서는 top-k snippet을 어떻게 보여 주는지, chunk가 어떤 context를 잃었는지, reranker가 무엇을 버렸는지가 다시 문제가 된다.
그래서 제품 관점의 결론은 hybrid에 가깝다. 넓은 후보 공간에서는 vector 또는 sparse index가 first-pass recall을 만들고, 좁혀진 범위 안에서는 grep, regex, file read, local context inspection이 evidence verification을 담당하는 구조가 자연스럽다. 중요한 것은 이 조합을 “retriever benchmark”로만 보지 말고, 하네스 전체의 행동 단위로 평가하는 것이다.
내가 보기에 이 논문의 가장 좋은 문장은 제목의 농담보다 결과 해석에 있다. Agentic search의 성능은 검색 알고리즘 하나가 아니라, 모델이 증거와 상호작용하는 인터페이스의 산물이다. 앞으로 RAG/agent 평가를 할 때는 “어떤 embedding model을 썼는가”만큼이나 “도구 출력이 어디에 놓였는가”, “모델이 그 출력을 다시 탐색할 수 있었는가”, “하네스가 중간 실패에서 되돌아갈 루프를 줬는가”를 함께 기록해야 한다.