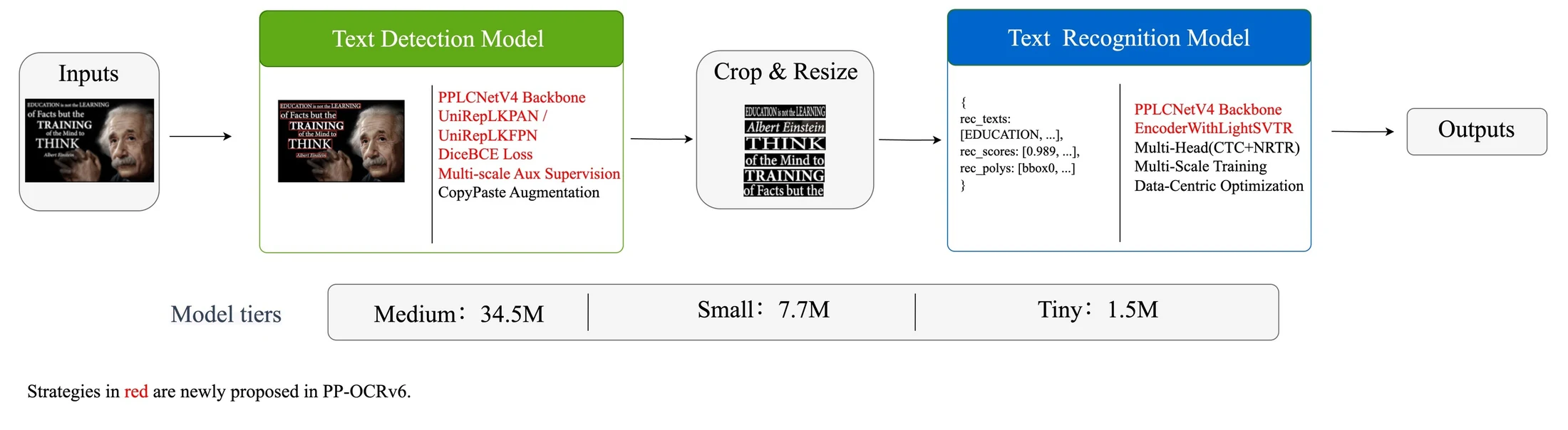
PP-OCRv6은 PaddlePaddle 팀이 공개한 범용 텍스트 OCR 시스템이다.
논문 제목은 꽤 직설적이다.
1.5M~34.5M 파라미터 모델이 OCR task에서는 billion-scale VLM을 넘어선다는 주장이다. arXiv 논문은 arXiv:2606.13108이고, PaddleOCR GitHub 릴리스 v3.7.0과 Hugging Face PaddlePaddle/pp-ocrv6 컬렉션까지 함께 공개되어 있다.
이 글에서 흥미로운 지점은 “작은 모델이 큰 모델을 이겼다”는 숫자 하나가 아니다.
PP-OCRv6은 OCR을 일반 VLM prompting 문제가 아니라, detection, recognition, language coverage, CPU/edge inference, hallucination control이 얽힌 전문 파이프라인 문제로 다시 정의한다.
대형 VLM은 문서나 이미지의 의미를 잘 설명할 수 있지만, 실제 OCR 운영에서는 한 글자, 한 박스, 한 crop boundary가 비용으로 이어진다.

무엇을 해결하려는가
논문은 VLM이 OCR에서 겪는 약점을 세 가지로 정리한다.
첫째, bounding box와 polygon localization이 충분히 타이트하지 않다.
둘째, 비표준 철자, 반복 문자, 숫자·문자 혼합처럼 언어 prior와 충돌하는 입력에서 hallucination이 생긴다.
셋째, OCR만 하려고 수십억~수천억 파라미터 모델을 부르는 것은 배치 처리, 지연 시간, 엣지 배포에서 너무 비싸다.
그래서 PP-OCRv6의 질문은 “VLM을 어떻게 더 잘 prompt할 것인가”가 아니다.
오히려 OCR에 필요한 inductive bias를 가진 작은 모델을 어디까지 밀어붙일 수 있는가에 가깝다.
텍스트 영역을 찾는 detection 모델, crop에서 문자열을 읽는 recognition 모델, 언어별 모델 전환 없이 쓰는 다국어 recognition 모델, 그리고 CPU/OpenVINO/ONNX/TensorRT 같은 배포 경로가 하나의 시스템으로 묶인다.
논문과 공식 문서가 제시하는 모델 계층은 다음처럼 읽을 수 있다.
| 계층 | 전체 파라미터 범위 | 목표 배포 | 논문이 강조하는 역할 |
|---|---|---|---|
| PP-OCRv6_tiny | 1.5M급 end-to-end | edge, CPU, 초저지연 | 작은 footprint와 빠른 추론 |
| PP-OCRv6_small | 7.7M급 end-to-end | mobile/desktop 균형점 | 정확도와 속도의 절충 |
| PP-OCRv6_medium | 34.5M급 end-to-end | server, high-accuracy | detection Hmean 86.2%, recognition accuracy 83.2% |
핵심 구조: LCNetV4를 공통 언어로 쓴다
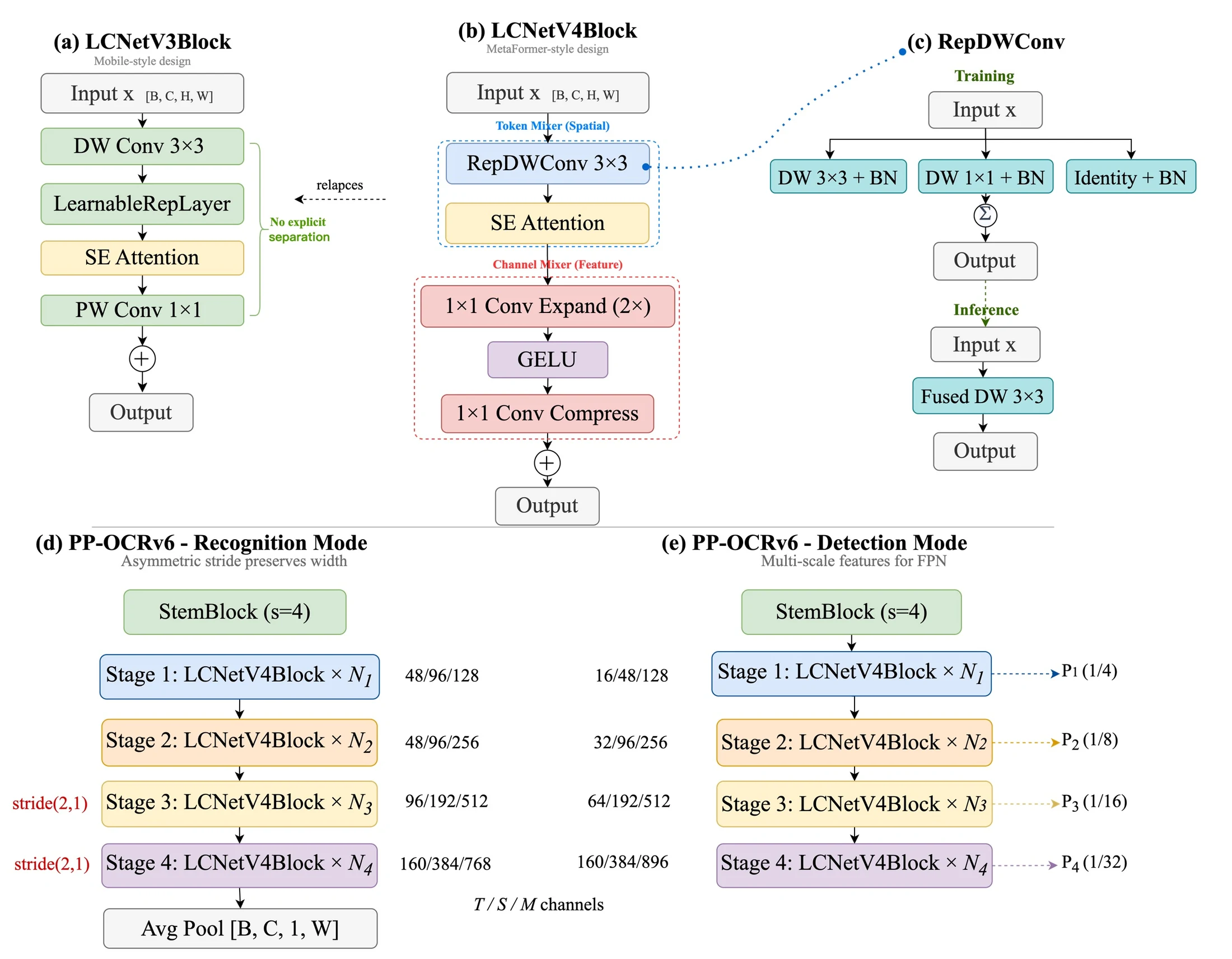
PP-OCRv6의 구조적 중심은 LCNetV4, 공식 문서 표기로는 PPLCNetV4다.
논문은 이를 MetaFormer 스타일의 경량 backbone으로 설명한다.
각 block은 spatial token mixing과 channel mixing을 분리하고, token mixer에는 reparameterizable depthwise convolution을 넣는다. detection과 recognition 모두 같은 block primitive를 쓰되, recognition에서는 너비 방향 정보를 보존하기 위해 stage 3~4에 asymmetric stride (2, 1)을 사용한다.
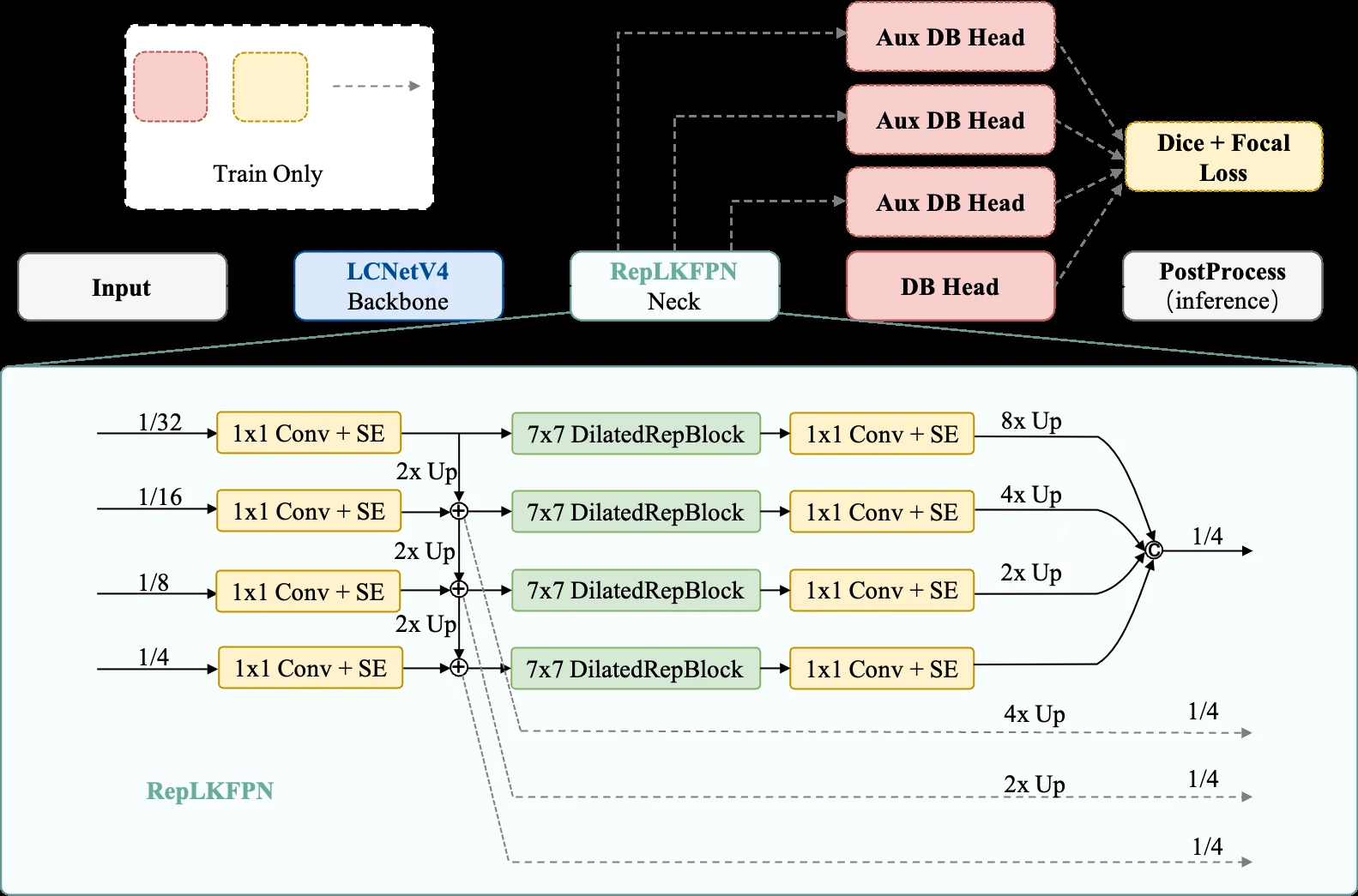
Detection 쪽에서는 RepLKFPN이 중요하다.
PP-OCRv5의 RSEFPN보다 작은 parameter budget으로 7×7 receptive field를 만들기 위해, 학습 시 dilated reparameterization branch를 쓰고 추론 시 7×7 depthwise convolution으로 접는다.
여기에 training-only auxiliary DB heads와 Focal Loss를 더해 작은 글자나 밀집 텍스트에 대한 pixel supervision을 강화한다.
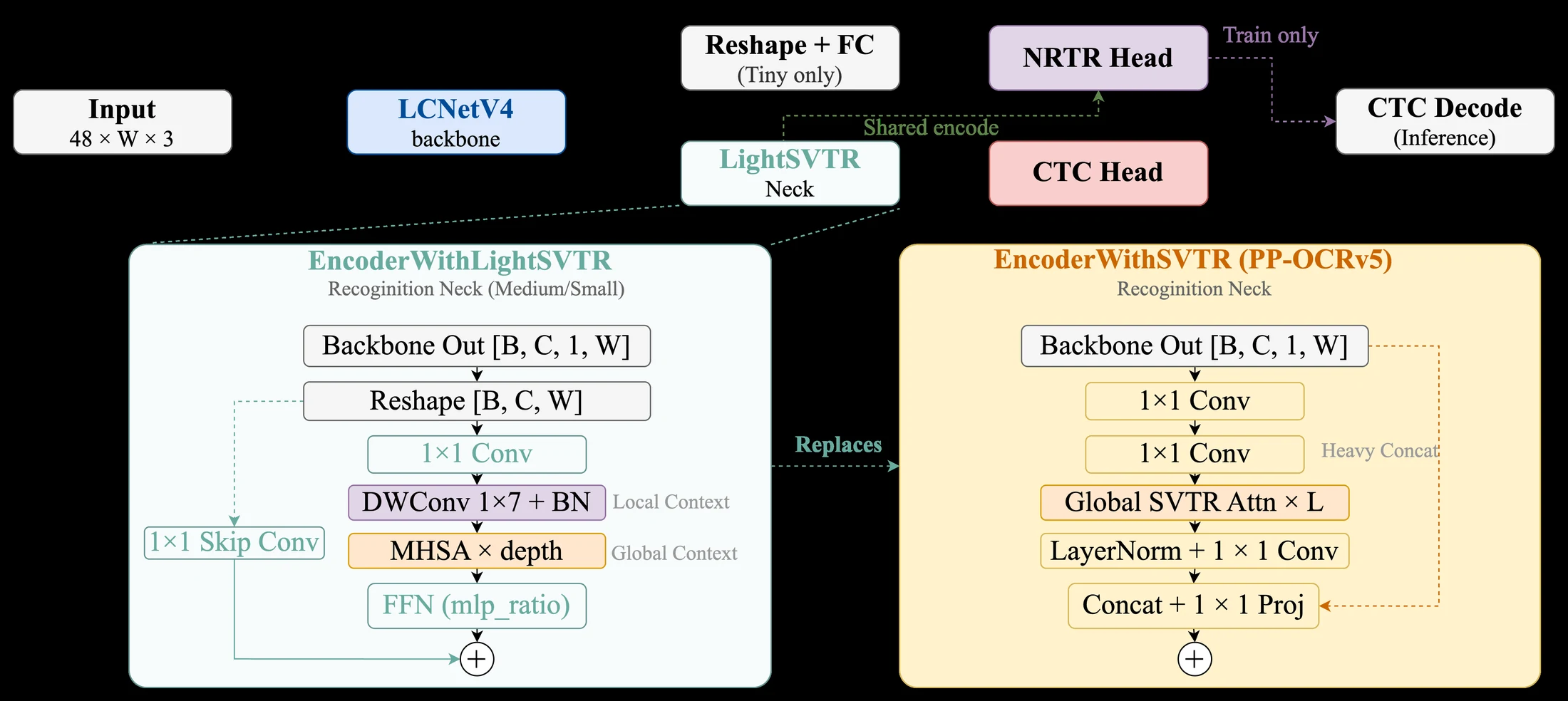
Recognition 쪽에서는 EncoderWithLightSVTR가 들어간다.
PP-OCRv5의 SVTR neck이 concat skip을 쓰던 것과 달리, LightSVTR는 1×7 depthwise convolution으로 local context를 잡고 Transformer block으로 global dependency를 처리한 뒤 additive skip을 사용한다. medium/small 모델은 LightSVTR neck과 CTC/NRTR multi-head decoder를 함께 쓰고, tiny 모델은 더 단순한 reshape+FC 경로와 distillation으로 속도를 우선한다.
공개된 근거에서 확인되는 점
논문 수치의 중심은 in-house OCR benchmark다.
PP-OCRv6_medium은 detection 평균 Hmean 86.2%, recognition weighted average accuracy 83.2%를 보고한다.
같은 표에서 PP-OCRv5_server는 각각 81.6%, 78.1%다.
VLM과의 비교에서는 Gemini-3.1-Pro, GPT-5.5, Qwen3-VL-235B, Kimi-K2.6, MiniMax-M3가 들어가는데, detection에서는 가장 높은 VLM 평균 Hmean이 46.8%, recognition에서는 Qwen3-VL-235B가 74.9%다.
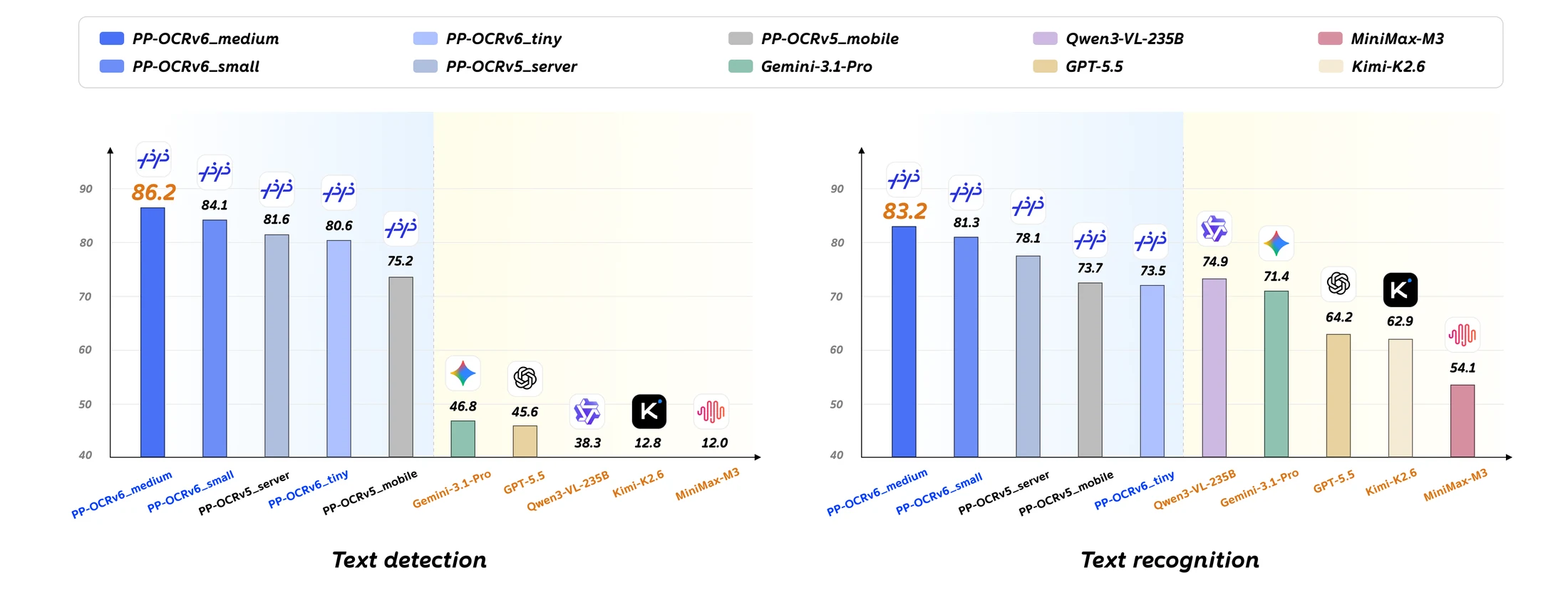
핵심 숫자만 압축하면 다음과 같다.
| 비교 지점 | PP-OCRv6_medium | 기준 / 비교 | 해석 |
|---|---|---|---|
| Detection Hmean | 86.2% | PP-OCRv5_server 81.6% | +4.6점 개선 |
| Recognition W-Avg | 83.2% | PP-OCRv5_server 78.1% | +5.1점 개선 |
| VLM detection best | 86.2% | Gemini-3.1-Pro 46.8% | OCR localization에서는 큰 격차 |
| VLM recognition best | 83.2% | Qwen3-VL-235B 74.9% | recognition에서도 +8.3점 |
| Hallucination test | 93.2% | Kimi-K2.6 85.0%, Qwen3-VL-235B 80.56% | 언어 prior보다 시각 입력을 더 충실히 보존 |
| Intel Xeon OpenVINO | 1.40s/image | PP-OCRv5_server 7.30s/image | medium 기준 약 5.2× 빠름 |
| Tiny OpenVINO | 0.20s/image | PP-OCRv5_mobile 0.78s/image | tiny 기준 약 3.9× 빠름 |
이 수치를 읽을 때는 두 가지를 동시에 봐야 한다.
한쪽으로는 “공식 in-house benchmark라서 외부 leaderboard처럼 받아들이면 안 된다”는 보수성이 필요하다.
다른 한쪽으로는 VLM이 OCR을 틀리는 방식이 단순 평균 정확도 문제가 아니라는 점을 봐야 한다.
OCR에서는 문자를 자연스럽게 고쳐 쓰는 능력보다, 보이는 대로 틀리지 않게 옮기는 능력이 더 중요할 때가 많다.

릴리스 표면: 논문만 있는 발표는 아니다
이번 발표는 arXiv PDF 하나로 끝나지 않는다.
PaddleOCR GitHub는 2026년 6월 11일 v3.7.0 release note에서 PP-OCRv6을 정식 릴리스로 올렸고, 최신 태그도 v3.7.0이다.
확인 시점의 GitHub API 기준 PaddleOCR 저장소는 Apache-2.0 라이선스, 기본 브랜치 main, 82k+ stars, 10k+ forks 규모의 공개 프로젝트다.
Hugging Face 쪽도 별도 collection이 있다.PaddlePaddle/pp-ocrv6 컬렉션은 “From 1.5M to 34.5M Parameters, Surpassing Billion-Scale VLMs on OCR Tasks”라는 설명과 함께 detection/recognition 모델을 tiny/small/medium, safetensors/ONNX/기본 포맷으로 나눠 공개한다.
API로 확인한 공개 모델 항목은 18개이고, 각 항목의 tags에는 arxiv:2606.13108, PaddleOCR, image-to-text, license:apache-2.0가 붙어 있다.
다만 이 배포 상태는 “모든 사용자가 바로 같은 benchmark를 재현할 수 있다”와는 다르다.
논문 benchmark는 in-house이고, 모델은 task별 component로 쪼개져 있으며, 실제 시스템 품질은 detection model, recognition model, preprocessing, backend, crop policy, post-processing을 함께 맞춰야 나온다.
특히 법률·금융·의료 문서처럼 오류 비용이 큰 도메인에서는 OCR confidence, 원문 region 링크, human review, downstream validation을 같이 설계해야 한다.
왜 실무적으로 중요한가
PP-OCRv6의 메시지는 “VLM을 쓰지 말자”가 아니다.
문서 이해, 질의응답, reasoning, cross-page synthesis에는 여전히 VLM이 강하다.
하지만 OCR의 가장 낮은 층, 즉 글자 위치와 원문 문자열을 만드는 단계에서는 VLM generalist보다 작은 전문 모델이 더 적합할 수 있다.
특히 대량 문서 ingestion, RAG index 구축, 영수증·신분증·산업 문자 처리, 엣지/CPU 배포에서는 호출 비용과 hallucination 위험이 품질 숫자만큼 중요하다.
내가 보기에는 PP-OCRv6이 보여주는 방향은 꽤 현실적이다.
OCR 파이프라인은 모델 하나의 지능보다 오류가 어디서 생기는지 분해할 수 있는 구조가 중요하다.
Text box가 틀렸는지, crop margin이 흔들렸는지, recognition neck이 언어별 long-tail을 놓쳤는지, post-processing이 과하게 보정했는지 따로 봐야 운영이 된다.
PP-OCRv6은 backbone, detection neck, recognition neck, language support, deployment tier를 분리해 개선한다는 점에서 이런 운영 관점과 잘 맞는다.
그렇다고 논문 숫자를 그대로 “OCR 문제 해결”로 읽으면 안 된다.
비교 대상 VLM의 prompting, bbox output 형식, OCR 전용 fine-tuning 여부, in-house 데이터 구성은 결과를 크게 바꿀 수 있다.
따라서 이 글의 결론은 더 좁다.
OCR을 안정적인 인프라로 써야 한다면, 거대 VLM을 바로 부르기 전에 PP-OCRv6 같은 전문 OCR stack을 먼저 baseline으로 세우는 것이 합리적이라는 것이다.