금융 시계열에서 foundation model을 만든다는 말은 자연어 모델을 그대로 가져다 붙이는 것보다 훨씬 까다로운 문제다.
가격과 거래량은 연속값이고, 노이즈가 크며, 시장 국면이 바뀌면 같은 패턴도 전혀 다른 의미를 갖는다.
일반적인 time series foundation model(TSFM)이 여러 도메인의 시계열을 함께 학습하더라도, 금융 K-line, 즉 Open·High·Low·Close·Volume·Amount로 구성된 캔들 데이터가 충분히 잘 표현된다는 보장은 없다.
Kronos는 이 문제를 정면으로 겨냥한 논문이자 공개 모델 릴리스다.
논문 제목 그대로 금융시장의 “언어”를 만들겠다는 접근이다.
핵심은 OHLCVA로 이루어진 연속 K-line 관측치를 먼저 이산 토큰으로 바꾸고, 그 토큰열을 디코더 전용 Transformer가 autoregressive하게 예측하도록 사전학습하는 것이다.
논문은 45개 글로벌 거래소에서 수집한 12B개 이상의 K-line 기록을 학습 말뭉치로 사용했다고 밝힌다.
흥미로운 점은 Kronos가 단순한 forecast model 하나가 아니라는 데 있다.
가격 시계열 예측, 수익률 예측, realized volatility 예측, synthetic K-line 생성, 투자 시뮬레이션까지 같은 토큰 기반 생성 모델로 묶으려 한다.
GitHub와 Hugging Face에는 Kronos-mini, Kronos-small, Kronos-base와 tokenizer가 공개되어 있고, README 기준 Kronos-large는 표에는 있지만 아직 오픈소스 공개 대상은 아니다.
무엇을 해결하려는가
Kronos가 겨냥하는 첫 번째 병목은 금융 K-line 데이터가 일반 시계열 말뭉치 안에서 주변부로 밀려난다는 점이다.
논문은 금융 시계열이 낮은 signal-to-noise ratio, 비정상성, OHLCVA 속성 간의 복잡한 상호작용을 갖는다고 지적한다.
실제로 부록의 TSFM 비교 표는 여러 범용 TSFM의 pretraining corpus에서 금융 데이터 비중이 매우 작다고 정리한다.
Kronos는 이 문제를 “금융 전용 말뭉치로 학습한 토큰 기반 모델”이라는 방향으로 푼다.
두 번째 병목은 금융 실무의 작업이 단순한 point forecasting에 그치지 않는다는 점이다.
가격을 맞히는 것만으로는 리스크 관리, 변동성 추정, synthetic scenario 생성, 포트폴리오 신호 검증까지 충분히 다루기 어렵다.
Kronos는 같은 autoregressive model이 여러 미래 경로를 샘플링할 수 있다는 점을 이용해, 예측값 하나가 아니라 확률적 경로와 분포를 다루는 쪽으로 설계를 넓힌다.
세 번째 병목은 연속 시계열을 Transformer가 다루기 좋은 discrete sequence로 바꾸는 문제다.
자연어에서는 tokenizer가 이미 기본 인프라지만, K-line에서는 무엇을 하나의 token으로 볼 것인지가 명확하지 않다.
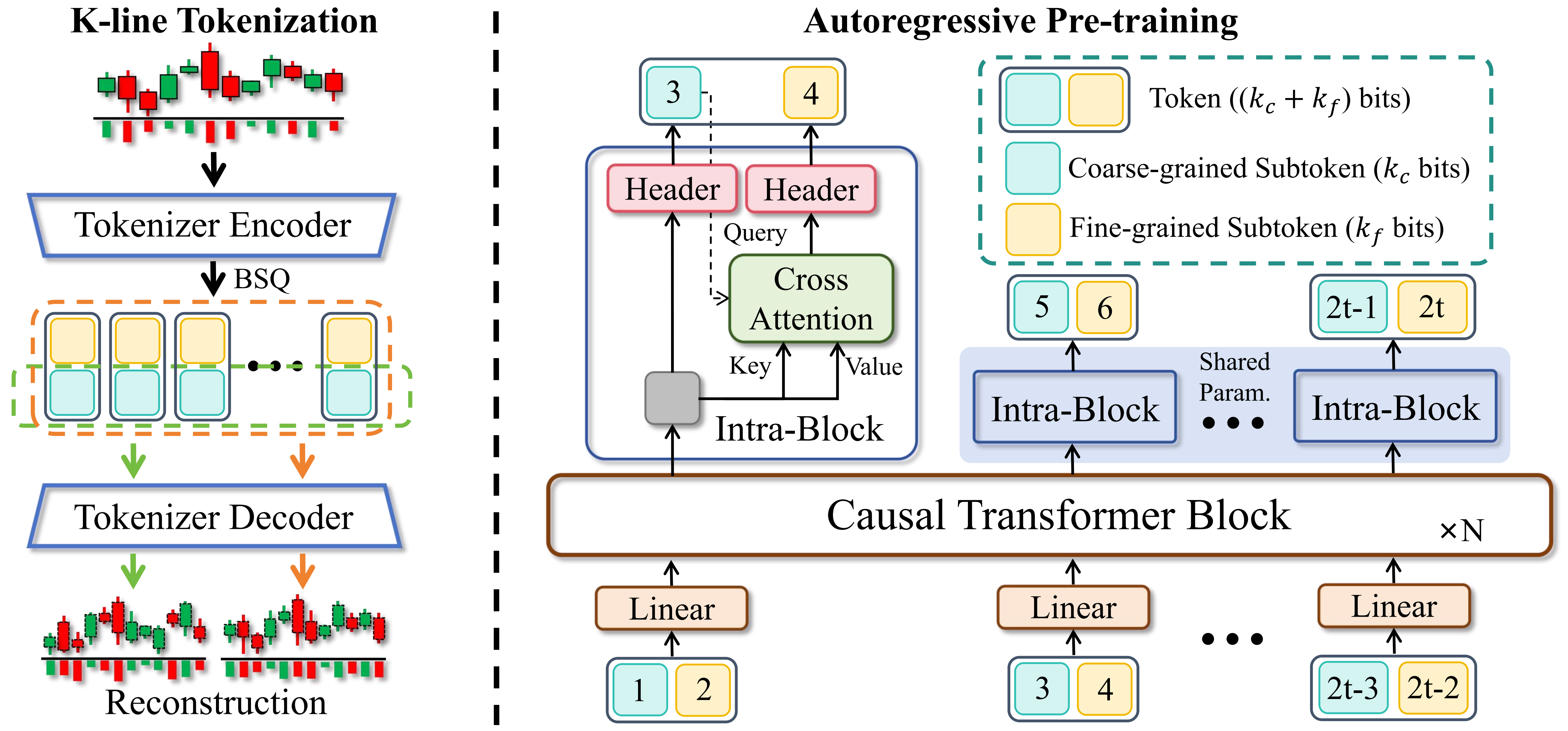
Kronos는 각 시점의 6차원 OHLCVA 관측치를 하나의 instance로 보고, 이를 coarse subtoken과 fine subtoken으로 나뉜 계층적 discrete token으로 양자화한다.
이 선택이 전체 모델의 중심축이다.
핵심 아이디어 / 구조 / 동작 방식
Kronos의 구조는 크게 두 단계로 읽으면 된다.
첫째, K-line Tokenizer가 연속 OHLCVA 벡터를 이산 토큰으로 바꾼다.
둘째, decoder-only Transformer가 이 토큰열 위에서 다음 시점의 token을 예측한다.
겉보기에는 LLM 학습과 비슷하지만, 입력 단위가 단어가 아니라 시장의 한 시점 관측치라는 점이 다르다.
토크나이저는 Transformer 기반 autoencoder와 Binary Spherical Quantization(BSQ)을 결합한다.
논문은 각 token을 coarse-level subtoken과 fine-level subtoken으로 분해하고, hierarchical reconstruction loss를 통해 두 subtoken이 서로 다른 granularity의 정보를 맡도록 유도한다.
부록의 codebook usage 표에서는 coarse codebook 사용률 97.66%, fine codebook 사용률 85.25%가 보고된다.
즉 거대한 vocabulary를 무작정 선언한 것이 아니라 실제 사용률과 분해 방식까지 점검한 구조다.
Kronos-base의 경우 20-bit token을 그대로 2^20 vocabulary로 쓰면 embedding 파라미터가 폭증한다.
논문은 이를 2개의 10-bit subtoken으로 나누는 설계를 택한다.
부록의 trade-off 표에 따르면 no-split 설정은 vocabulary parameter만 약 1,744.8M까지 커지지만, Kronos의 2-split 구성은 core Transformer 약 97.5M, vocabulary 약 3.4M, fusion 약 1.4M 수준으로 전체 102.3M 파라미터에 머문다.
토큰 분해는 단순한 표현 기법이 아니라 모델 크기를 현실적으로 유지하기 위한 핵심 압축 장치다.
| 계층 | 공개 자료에서 확인되는 구성 | 실무적 의미 |
|---|---|---|
| 입력 표현 | OHLCVA 6차원 K-line 관측치 | 가격·거래량·거래대금을 하나의 시장 상태로 묶음 |
| Tokenizer | Transformer autoencoder + BSQ | 연속 금융 데이터를 discrete language modeling 문제로 변환 |
| Token 구조 | coarse subtoken + fine subtoken | 거대한 vocabulary를 작은 sub-vocabulary 조합으로 분해 |
| Backbone | decoder-only autoregressive Transformer | 여러 금융 작업을 next-token generation 형태로 통일 |
| Pretraining corpus | 45개 글로벌 거래소, 12B+ K-line records | 범용 TSFM보다 금융 도메인 비중을 극단적으로 높임 |
| Downstream tasks | 가격·수익률·변동성 예측, synthetic K-line, 투자 시뮬레이션 | 단일 forecast보다 quant workflow 전반을 겨냥 |
모델 패밀리도 비교적 명확하다.
논문 표에는 Kronos-small, Kronos-base, Kronos-large가 등장하고, GitHub README의 model zoo에는 더 작은 Kronos-mini가 추가된다.
공개 상태를 보면 mini, small, base는 Hugging Face에 열려 있고, large는 공개 표에서만 확인된다.
| 모델 | Tokenizer | Context length | Params | 공개 상태 |
|---|---|---|---|---|
| Kronos-mini | Kronos-Tokenizer-2k | 2048 | 4.1M | Hugging Face 공개 |
| Kronos-small | Kronos-Tokenizer-base | 512 | 24.7M | Hugging Face 공개 |
| Kronos-base | Kronos-Tokenizer-base | 512 | 102.3M | Hugging Face 공개 |
| Kronos-large | Kronos-Tokenizer-base | 512 | 499.2M | README 기준 미공개 |
공개된 근거에서 확인되는 점
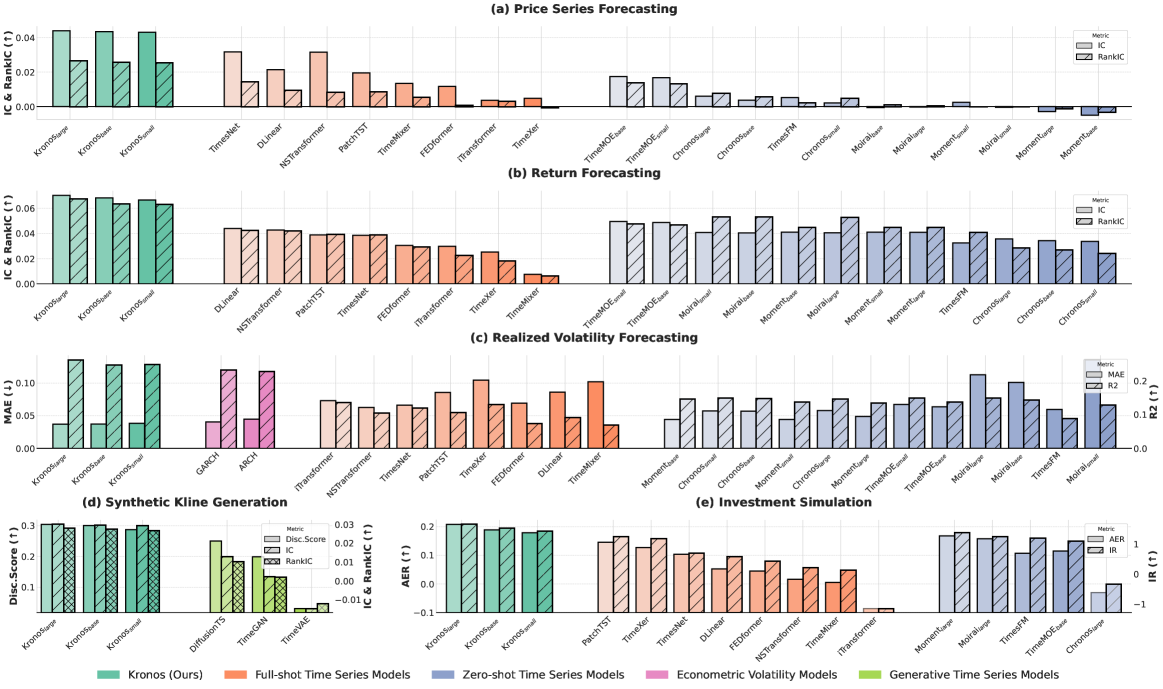
논문이 가장 크게 내세우는 수치는 가격 시계열 예측에서의 RankIC 개선이다. arXiv abstract와 본문은 Kronos가 price series forecasting에서 가장 강한 TSFM baseline 대비 RankIC를 93%, 가장 강한 non-pre-trained baseline 대비 87% 끌어올렸다고 주장한다.
또한 realized volatility forecasting에서는 MAE를 9% 낮추고, synthetic K-line generation에서는 generative fidelity를 22% 개선했다고 보고한다.
평가 범위는 꽤 넓다.
논문은 세 가지 예측 작업, 하나의 생성 작업, 하나의 투자 시뮬레이션을 함께 다룬다.
Price series와 return forecasting은 IC/RankIC로 평가하고, volatility는 MAE와 R²를 사용한다.
Synthetic K-line은 discriminative score와 Train-on-Synthetic-Test-on-Real(TSTR) 방식의 usefulness로 평가한다.
투자 시뮬레이션은 중국 A-share 시장에서 예측 신호로 top-k long-only 포트폴리오를 구성해 Annualized Excess Return(AER)과 Information Ratio(IR)를 본다.
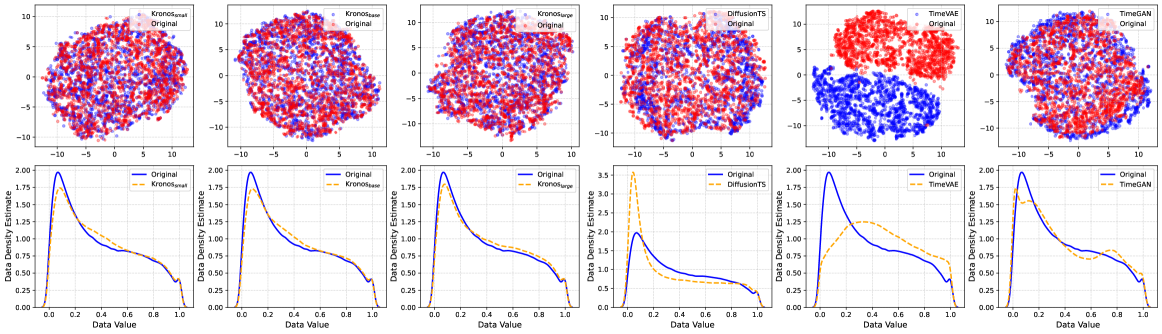
Synthetic K-line 결과도 흥미롭다.
논문은 원본과 생성 샘플을 t-SNE와 KDE로 비교해, Kronos의 합성 데이터가 실제 데이터 분포와 더 잘 겹친다고 주장한다.
이 지점은 단순 forecast 성능보다 더 중요할 수 있다.
금융 모델 개발에서 synthetic path는 리스크 시나리오, 데이터 증강, strategy stress test에 연결될 수 있기 때문이다.
릴리스 표면은 연구 코드와 공개 모델 사이의 중간 단계에 가깝다.
GitHub API 기준 저장소는 MIT license로 표시되며, LICENSE 파일도 MIT License다.
2026-05-11 현재 API 기준 stars는 23,845, forks는 4,166, open issues는 189다.
다만 /releases/latest는 404이고 /tags도 비어 있다.
즉 관심도와 공개 코드는 충분하지만, 아직 semantic versioning이나 패키지 릴리스가 정리된 성숙한 라이브러리 형태라고 보긴 어렵다.
Hugging Face 쪽 공개는 더 직접적이다.NeoQuasar/Kronos-mini, Kronos-small, Kronos-base, Kronos-Tokenizer-base, Kronos-Tokenizer-2k가 모두 public, ungated, safetensors 기반으로 확인된다.
각 모델 cardData는 MIT license와 time-series-forecasting pipeline tag를 갖고 있다.
API 카운터 기준 다운로드 수는 tokenizer와 모델별로 수십만에서 수백만 단위로 잡히지만, 이는 Hugging Face API의 현재 값으로만 보수적으로 해석하는 편이 맞다.
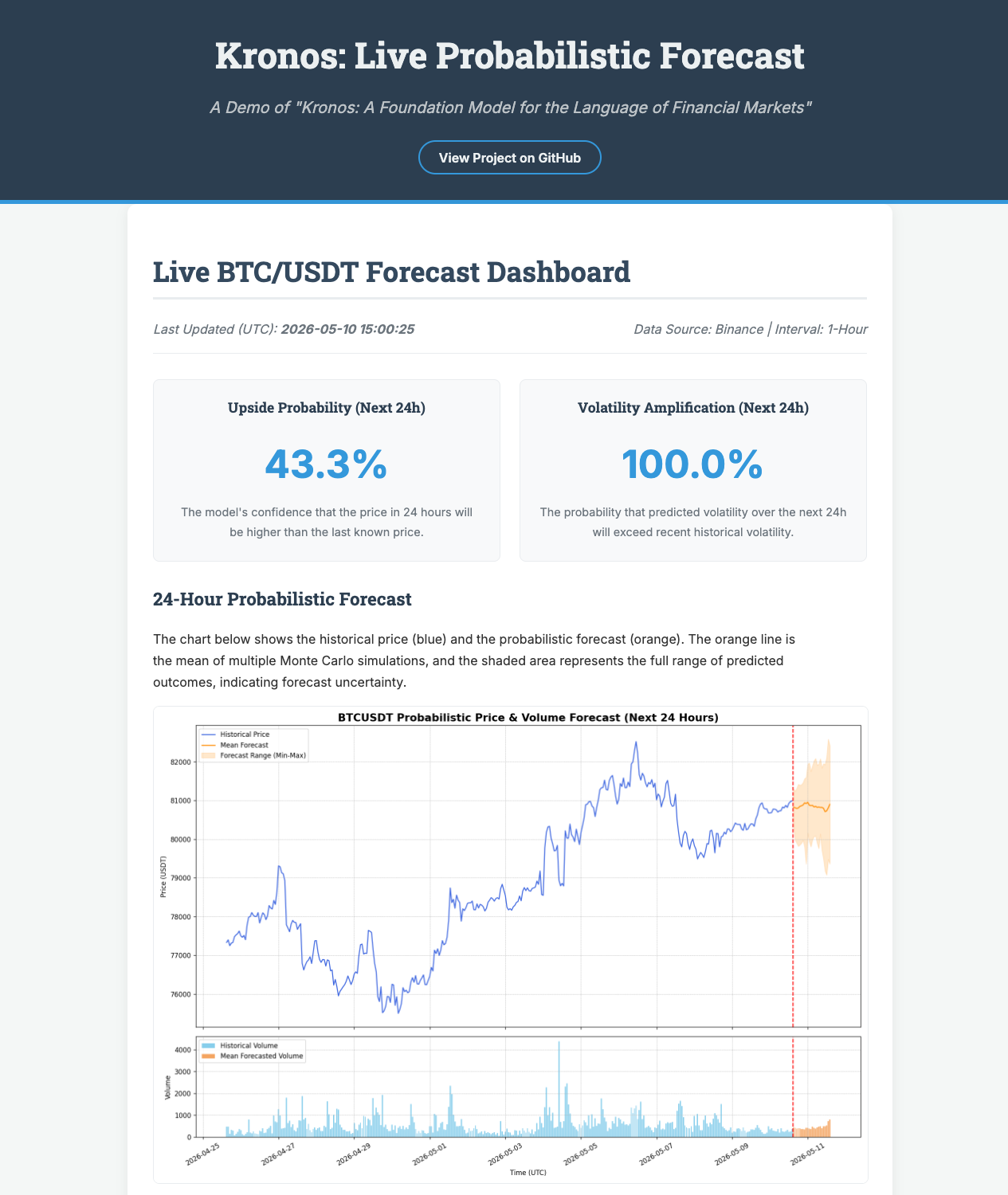
GitHub README에는 live demo도 연결되어 있다.
이 데모는 BTC/USDT 1시간봉을 대상으로 Kronos-mini를 사용해 최근 360시간을 context로 삼고, Monte Carlo sampling 30개 경로로 다음 24시간의 확률적 예측을 시각화한다.
다만 이런 데모는 모델 사용 예시이지 투자 판단 근거가 아니다.
블로그 독자 입장에서는 “Kronos가 단일 점 예측이 아니라 경로 분포와 불확실성을 내보내는 방식으로 쓰일 수 있다”는 정도로 받아들이는 것이 안전하다.
실무 관점에서의 해석
내가 보기에 Kronos의 가장 중요한 의미는 금융 시계열을 언어 모델링 문제로 번역하는 방식이 꽤 구체화됐다는 점이다.
지금까지 time series foundation model 논의는 종종 “시계열에도 foundation model을 만들 수 있는가”라는 큰 문장에 머물렀다.
Kronos는 그보다 더 좁고 실용적인 질문을 던진다.
금융 캔들 데이터를 하나의 domain language로 보고, tokenizer·corpus·downstream task를 모두 그 언어에 맞게 설계하면 어떤 일이 벌어지는가.
이 접근은 quant research 팀에 두 가지 가능성을 준다.
하나는 forecast backbone이다.
기존에는 자산군·빈도·작업별로 모델을 따로 만들었다면, Kronos식 모델은 공통된 market-token representation 위에서 여러 작업을 처리하는 방향을 제안한다.
다른 하나는 scenario generation이다.
샘플링 가능한 autoregressive model은 불확실성 범위, synthetic K-line, volatility path를 함께 다룰 수 있어 리스크 분석이나 데이터 증강에 더 자연스럽게 연결된다.
하지만 한계도 분명하다.
논문 성능은 공개 benchmark와 authors’ evaluation protocol 위에서 나온 값이다.
실제 trading system에서는 transaction cost, slippage, market impact, 데이터 지연, survivorship bias, regime shift 같은 요소가 훨씬 크게 작동한다.
Kronos가 RankIC와 volatility MAE에서 좋은 결과를 냈다는 사실은 중요하지만, 곧바로 안정적인 초과수익을 보장한다는 뜻은 아니다.
배포 성숙도도 아직은 조심스럽게 봐야 한다.
모델과 tokenizer는 공개되어 있고, README에는 예측·fine-tuning·backtesting 흐름까지 있다.
그러나 GitHub release/tag가 비어 있고, 설치 경로도 pip install -r requirements.txt와 repo-local import 중심이다.
즉 현재 Kronos는 완성된 금융 SaaS나 production SDK라기보다, 공개된 금융 시계열 foundation model 연구 산출물과 초기 실행 harness에 더 가깝다.
그럼에도 Kronos는 꽤 선명한 방향을 보여준다.
금융 데이터를 범용 TSFM의 주변 도메인으로 취급하지 않고, 전용 tokenizer와 전용 말뭉치, 전용 평가 작업으로 재구성했다.
이 방향이 계속 발전한다면 앞으로 quant stack에서 “feature engineering + task-specific model”의 일부 역할은 “market tokenizer + pretrained backbone + task adapter”로 이동할 가능성이 있다.
Kronos는 그 전환을 가장 노골적으로 보여주는 초기 공개 사례 중 하나다.