멀티모달 모델이 이미지를 보고 답하는 방식은 크게 두 갈래로 나뉜다. 하나는 모델이 한 번의 forward pass 안에서 이미지와 질문을 읽고 바로 답하는 방식이고, 다른 하나는 답을 찾기 위해 이미지를 다시 자르고, 흐릿한 부분을 보정하고, OCR을 돌리고, 웹 검색과 이미지 검색을 반복하며 증거를 쌓는 방식이다. 후자는 단순 VQA라기보다 멀티모달 딥서치 에이전트에 가깝다.
OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents가 흥미로운 이유는 이 후자를 “좋은 모델 하나”의 문제가 아니라 공개 가능한 훈련 레시피의 문제로 다룬다는 점이다. 논문은 OpenSearch-VL을 통해 데이터 생성 파이프라인, 도구 환경, SFT/RL 학습 절차, 모델 체크포인트와 데이터셋을 함께 공개하는 방향을 제시한다. 즉 결과 모델만 보여주는 것이 아니라, 왜 그런 도구 사용 행동이 학습되는지까지 재현 가능한 형태로 만들려는 시도다.
공식 GitHub README의 표현을 빌리면 OpenSearch-VL 에이전트는 이미지를 한 번 보고 추측하지 않는다. 이미지를 관찰하고, 필요한 영역을 crop하거나 enhance하고, text/image/web search와 page visit을 수행한 뒤, 여러 증거를 조합해 답한다. 이 차이는 작아 보이지만 지식집약적 시각 질문에서는 본질적이다. 질문의 답이 이미지 안에 직접 적혀 있지 않거나, 이미지가 특정 장소·사물·문서의 단서만 제공하는 경우에는 모델 내부 지식만으로는 안정적인 근거를 만들기 어렵기 때문이다.
무엇을 해결하려는가
프론티어급 멀티모달 검색 에이전트는 아직 재현하기 어렵다. 상용 시스템은 강력한 검색·브라우징·시각 도구 루프를 갖추고 있지만, 어떤 데이터로 훈련했는지, 도구 사용 trajectory를 어떻게 만들었는지, 실패한 rollout을 RL에서 어떻게 처리했는지 공개하지 않는 경우가 많다. 그래서 외부 연구자는 “검색을 쓰는 VLM이 좋아진다”는 결과는 볼 수 있어도, 그 능력을 체계적으로 복제하거나 분석하기는 어렵다.
OpenSearch-VL은 이 병목을 세 부분으로 나눈다.
- 데이터 병목: 단순 이미지-질문-답변 쌍이 아니라, 실제로 여러 번의 검색과 시각 도구 사용을 요구하는 멀티홉 VQA가 필요하다.
- 도구 환경 병목: 학습 데이터 생성, RL rollout, inference가 서로 다른 도구 정의를 쓰면 에이전트 행동이 일관되게 학습되기 어렵다.
- RL credit assignment 병목: 긴 멀티턴 tool-use trajectory에서는 중간의 도구 실패가 뒤쪽 토큰 전체를 망가뜨릴 수 있다. 그렇다고 실패한 trajectory 전체를 벌점 처리하면, 실패 직전까지의 유효한 추론까지 함께 눌러 버린다.
이 논문의 출발점은 특히 데이터 쪽에서 분명하다. 저자들은 Wikipedia hyperlink graph에서 멀티홉 entity path를 샘플링하고, 중간 entity를 fuzzy descriptor로 바꾸며, 질문의 시각 anchor를 answer node가 아니라 source node의 대표 이미지에 둔다. 이 설계는 “이미지 검색 한 번으로 정답 entity를 찾아버리는” shortcut을 줄이려는 장치다. 에이전트가 정말로 여러 단계를 거쳐야 하는 문제를 만들기 위해 데이터 생성 자체에 anti-shortcut 구조를 넣은 셈이다.
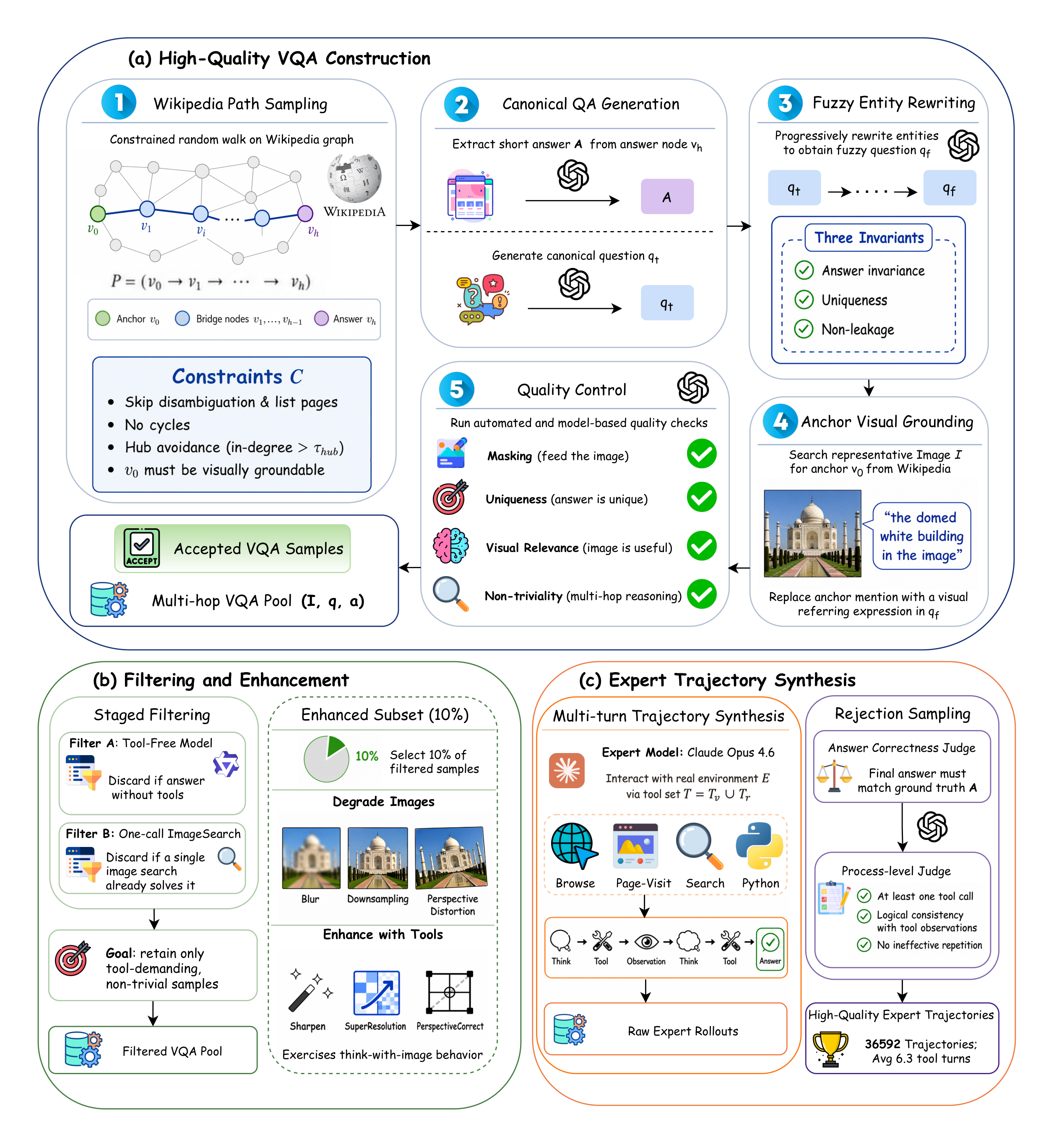
핵심 아이디어 / 구조 / 동작 방식
OpenSearch-VL의 구조는 “데이터 → 도구 환경 → 학습 알고리즘”이라는 세 층으로 읽는 것이 가장 깔끔하다.
| 층 | 핵심 설계 | 역할 |
|---|---|---|
| 데이터 | SearchVL-SFT-36K, SearchVL-RL-8K | SFT와 RL에 사용할 멀티턴 검색·시각 도구 trajectory를 제공한다. |
| 도구 환경 | text/image/web search, visit, OCR, crop, sharpen, super-resolution, perspective correction | 에이전트가 이미지 단서와 외부 지식을 결합하도록 만든다. |
| 학습 | Agentic SFT 이후 multi-turn fatal-aware GRPO | 실패 trajectory의 유효한 prefix를 보존하면서 정책을 개선한다. |
| 배포 아티팩트 | OpenSearch-VL-8B, 30B-A3B, 32B | Qwen3-VL 계열 base model 위에 학습된 공개 checkpoint 세트를 제공한다. |
먼저 SFT 단계에서는 합성된 expert trajectory를 통해 모델에게 도구 사용 문법과 검색 흐름을 cold-start로 가르친다. 이때 중요한 것은 단순히 “도구를 불러라”가 아니라, 어느 시점에 이미지를 crop해야 하는지, 검색 질의를 어떻게 좁혀야 하는지, OCR이나 이미지 보정을 언제 써야 하는지를 trajectory 안에 담는 것이다.
그 다음 RL 단계에서는 실제 환경을 상대로 멀티턴 rollout을 생성한다. 보상은 최종 정답 성공뿐 아니라 검색 질의 품질과 format check를 함께 본다. 여기서 OpenSearch-VL의 특징적인 기여가 multi-turn fatal-aware GRPO다.
일반적인 search-augmented GRPO에서는 한 trajectory가 중간에 치명적 도구 실패를 만나면, 그 이후의 토큰이 정책 업데이트를 오염시킬 수 있다. hard masking은 post-failure token을 잘라내지만, 실패 직전 prefix가 꽤 좋은 방향이었는지까지 섬세하게 보존하지는 못한다. OpenSearch-VL은 fatal step 이후 토큰을 masking하면서도, pre-failure prefix의 group-normalized score가 충분히 좋으면 one-sided advantage clamping으로 그 prefix를 강화한다. 쉽게 말해 실패한 rollout이라도 실패하기 전까지 잘한 부분은 살린다는 것이다.
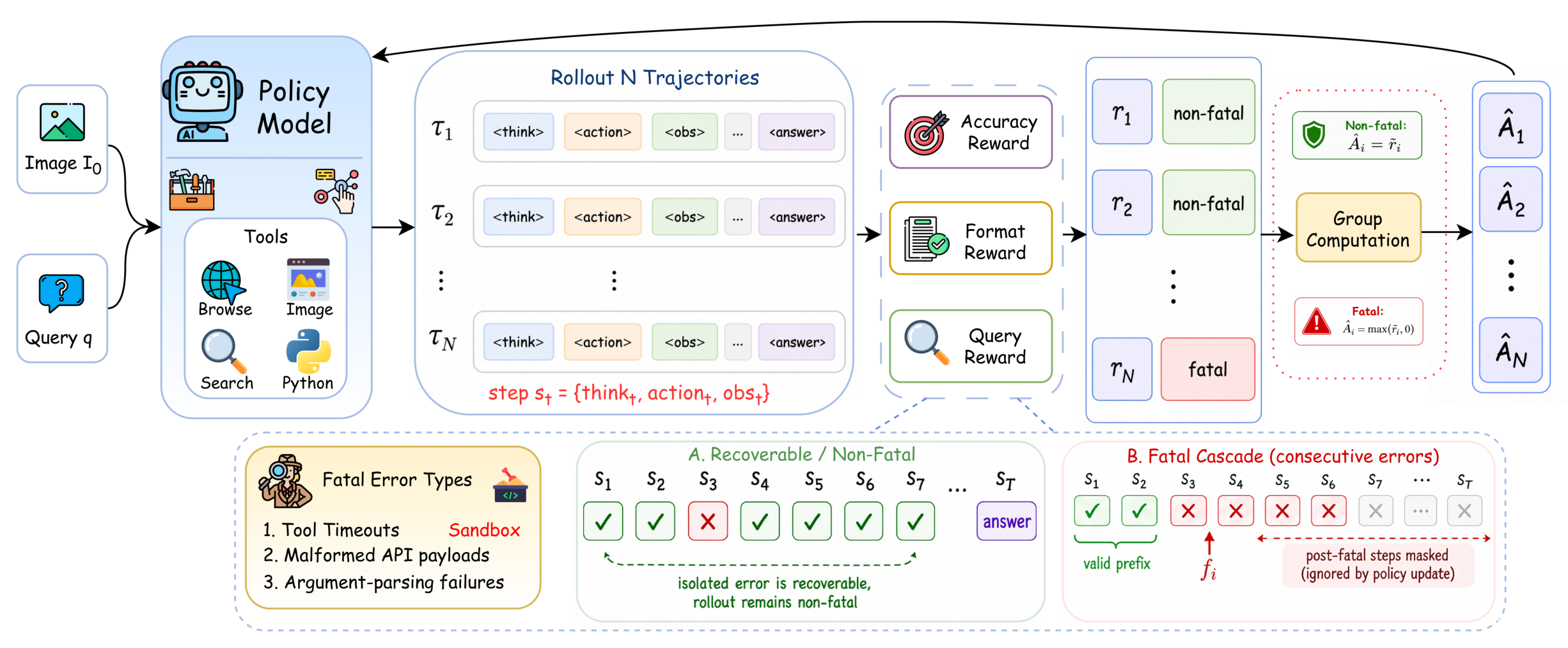
이 설계가 중요한 이유는 멀티모달 검색 에이전트의 실패가 보통 깔끔하지 않기 때문이다. 잘못된 crop, 흐릿한 OCR, 부정확한 이미지 검색, 죽은 웹 페이지, 과도하게 넓은 검색 질의가 연쇄적으로 뒤쪽 행동을 망가뜨린다. 전체 trajectory를 하나의 실패로만 보면 모델은 어려운 탐색을 피하는 쪽으로 학습될 수 있다. 반대로 유효한 prefix를 살리면, 어려운 질문에서 더 오래 탐색하고 더 나은 검색 행동을 시도할 여지가 생긴다.
공개된 근거에서 확인되는 점
논문과 공식 저장소가 공개한 결과에서 가장 눈에 띄는 부분은 agentic workflow의 이득이다. OpenSearch-VL은 SimpleVQA, VDR, MMSearch, LiveVQA, BrowseComp-VL, FVQA, InfoSeek의 7개 multimodal knowledge-intensive QA / web-search benchmark에서 평가됐다.
| 모델 / 조건 | 평균 점수 | 읽을 포인트 |
|---|---|---|
| Qwen3-VL-8B agentic baseline | 42.0 | 같은 8B 계열의 출발점 |
| SenseNova-MARS-8B | 52.7 | 기존 강한 open 8B agent 기준선 |
| OpenSearch-VL-8B | 56.6 | SenseNova-MARS-8B 대비 +3.9p |
| Qwen3-VL-30B-A3B agentic baseline | 47.8 | MoE 계열 baseline |
| OpenSearch-VL-30B-A3B | 61.6 | baseline 대비 +13.8p |
| Qwen3-VL-32B agentic baseline | 48.0 | 32B dense baseline |
| OpenSearch-VL-32B | 63.7 | 세 OpenSearch-VL 모델 중 최고 평균 |
이 표에서 중요한 것은 OpenSearch-VL이 단순히 더 큰 모델을 쓴 것이 아니라, 같은 Qwen3-VL 계열 baseline 대비 agentic search recipe로 큰 폭의 이득을 얻었다는 점이다. 특히 30B-A3B에서는 평균 점수가 47.8에서 61.6으로 올라가며, 논문이 주장하는 “훈련 레시피의 효과”가 가장 선명하게 보인다.
Ablation도 메시지가 명확하다. 데이터 파이프라인에서는 full pipeline의 평균 64.6을 기준으로 source-anchor grounding을 제거하면 -11.5p, fuzzy entity rewriting을 제거하면 -10.3p, staged filtering을 제거하면 -8.2p가 떨어진다. 즉 이 문제에서는 “데이터를 많이 모으는 것”보다 shortcut을 막고 실제 도구 사용을 요구하는 데이터로 만드는 것이 핵심이다. enhancement subset을 제거했을 때도 64.6에서 63.3으로 내려가는데, 이는 이미지 복원 trajectory가 core gain보다는 robustness 쪽에 더 기여한다는 해석을 가능하게 한다.
RL 쪽 ablation은 더 직접적이다. Qwen3-VL-8B 기준 SFT는 base model을 53.7에서 64.6으로 올리고, vanilla GRPO는 67.6까지 끌어올린다. 하지만 Vision-DeepResearch식 hard masking은 67.7로 거의 정체된다. fatal masking은 69.1, full fatal-aware GRPO with one-sided advantage clamping은 71.8에 도달한다. vanilla GRPO 대비 +4.2p다.
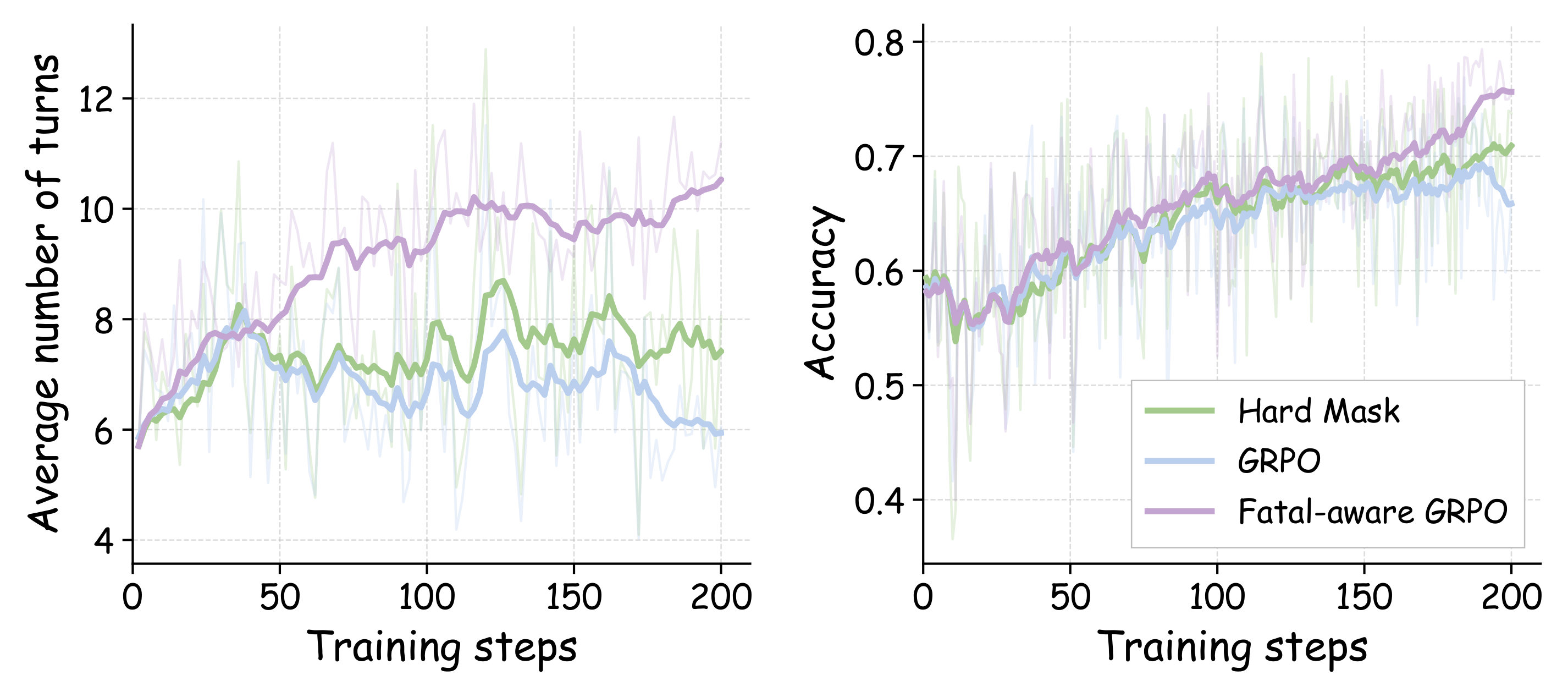
공개 아티팩트 측면에서도 꽤 많은 것이 나와 있다. GitHub 저장소 shawn0728/OpenSearch-VL은 Apache-2.0 라이선스로 공개되어 있고, SFT, RL, inference/evaluation 디렉터리를 포함한다. Hugging Face에는 OpenSearch-VL/OpenSearch-VL-8B, OpenSearch-VL-30B-A3B, OpenSearch-VL-32B 모델과 Search-VL-SFT-36K, Search-VL-RL-8K 데이터셋이 연결되어 있다. 조회 시점 기준 GitHub API는 131 stars와 9 forks를 반환했고, Hugging Face API는 8B 모델이 38 downloads / 3 likes, SFT 데이터셋이 342 downloads / 6 likes, RL 데이터셋이 83 downloads / 4 likes를 반환했다. 이 숫자들은 빠르게 변할 수 있으므로 popularity 자체보다 모델·데이터·코드가 같은 논문 ID와 함께 묶여 배포된 구조가 더 중요한 신호다.
다만 release maturity는 아직 초기 단계로 보는 편이 맞다. GitHub /releases/latest는 404였고 tags도 비어 있었다. README의 TODO에는 data curation pipeline을 standalone toolkit으로 공개하는 일과 interactive demo가 아직 남아 있다고 적혀 있다. 즉 checkpoint와 데이터셋은 공개됐지만, 데이터 생성 전체를 버튼 하나로 재현하는 완성형 제품이라기보다는, 연구자가 레시피를 검토하고 일부를 재현할 수 있는 초기 공개 연구 번들에 가깝다.

실무 관점에서의 해석
OpenSearch-VL의 핵심 가치는 “또 하나의 VLM checkpoint”라기보다, 멀티모달 검색 에이전트를 훈련할 때 무엇을 함께 설계해야 하는지 보여주는 데 있다. 강한 base model, 검색 도구, OCR, 이미지 보정 도구를 단순히 붙이는 것만으로는 충분하지 않다. 그 도구들을 쓰도록 유도하는 데이터, shortcut을 막는 질문 구성, 학습 중 실패를 다루는 RL 업데이트가 함께 맞아야 한다.
이 관점은 실제 제품팀에도 중요하다. 이미지 기반 고객지원, 문서 QA, 현장 점검, e-commerce visual search, 지식집약적 리서치 assistant처럼 “이미지에 단서는 있지만 답은 외부 지식에 있는” 문제에서는 direct VLM 답변보다 agentic search loop가 더 자연스럽다. 하지만 그 루프를 운영하려면 inference orchestration만이 아니라, 모델이 언제 어떤 도구를 써야 하는지 학습된 policy가 필요하다. OpenSearch-VL은 그 policy를 만드는 레시피를 데이터와 RL 수준에서 공개하려는 시도다.
동시에 도입 관점의 한계도 분명하다. README의 prerequisites는 Python 3.10+, CUDA 12.1+, PyTorch 2.4+, 8B 기준 H100/H800/A100-80GB급 GPU, 30B/32B 기준 multi-node 환경을 요구한다. inference/evaluation 역시 검색 API, Jina reader, OCR/layout endpoint, judge model 등 여러 외부 키와 서비스를 연결하는 구조다. 따라서 이것은 즉시 SaaS처럼 붙여 쓰는 경량 에이전트 패키지라기보다, 연구팀이나 인프라가 있는 조직이 멀티모달 딥서치 학습 스택을 참고할 때 더 가치가 크다.
내가 보기에 가장 중요한 메시지는 “멀티모달 search agent의 성능은 모델 크기만의 함수가 아니다”라는 점이다. OpenSearch-VL은 세 가지 축을 동시에 건드린다. 첫째, 데이터는 shortcut을 제거해야 한다. 둘째, 도구 환경은 시각 인식과 외부 검색을 같은 루프 안에서 다룰 수 있어야 한다. 셋째, RL은 실패한 멀티턴 trajectory를 전부 폐기하지 않고 유효한 reasoning prefix를 보존해야 한다. 이 세 가지가 합쳐질 때, VLM은 단순히 이미지를 설명하는 모델에서 증거를 찾아 움직이는 에이전트로 이동한다.
앞으로 이 계열의 연구를 볼 때는 benchmark 숫자만큼이나 공개 레시피의 모양을 함께 봐야 한다. 데이터 생성기가 실제로 공개됐는지, tool schema가 학습과 inference에서 일관되는지, 실패 rollout을 어떻게 다루는지, release가 checkpoint 수준인지 end-to-end reproduction 수준인지가 중요해진다. OpenSearch-VL은 아직 초기 공개 단계이지만, 멀티모달 딥서치 에이전트 연구가 어떤 구성요소를 공개해야 “재현 가능한 frontier recipe”에 가까워지는지 꽤 선명한 기준선을 제시한다.