의료 AI 에이전트를 평가할 때 흔한 설정은 이미 정리된 환자 컨텍스트를 모델에게 건네고, 그 안에서 답을 찾게 하는 것이다.
환자 요약, 최근 이벤트, 선택된 검사 결과, 이미 연결된 X-ray 이미지가 입력으로 들어오면 모델의 일은 주어진 evidence를 잘 읽고 결론을 내리는 쪽에 가까워진다.
하지만 실제 임상 의사결정 지원 workflow에서는 가장 어려운 부분이 종종 그 앞단에 있다.
어떤 테이블을 열어야 하는가.
어느 시간 범위를 봐야 하는가.
영상 신호와 EHR 이벤트, 외부 의학 지식을 어떻게 조합해야 하는가.
ClinSeekAgent: Automating Multimodal Evidence Seeking for Agentic Clinical Reasoning은 이 병목을 정면으로 겨냥한다.
논문의 핵심 주장은 임상 추론을 “주어진 근거 위에서 답하기”가 아니라 원자료에서 필요한 근거를 찾아내고, 그 과정을 반복적으로 수정하며, 최종 판단으로 통합하는 agentic evidence seeking 문제로 봐야 한다는 것이다.
이를 위해 저자들은 20개 도구를 가진 ClinSeekAgent, curated input과 automated evidence-seeking을 쌍으로 비교하는 ClinSeek-Bench, 그리고 Claude Opus 4.6 trajectory를 Qwen3.5-35B-A3B에 SFT한 ClinSeek-35B-A3B를 함께 공개했다.
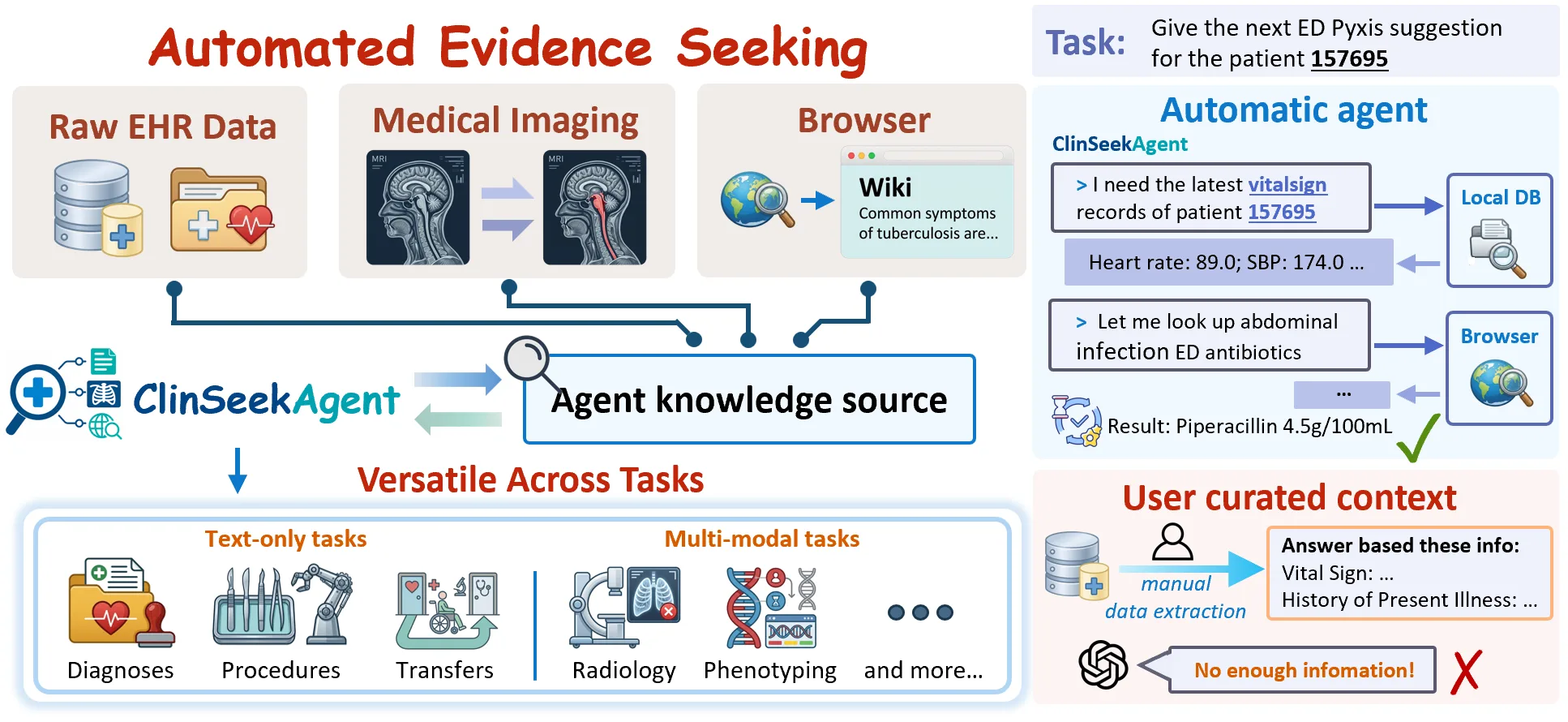
이 작업이 흥미로운 이유는 “의료 QA에서 LLM이 몇 점을 받았는가”보다 한 단계 운영적인 질문을 던지기 때문이다.
임상 에이전트가 실제 시스템으로 들어가려면 답변 생성 능력뿐 아니라 근거 수집 정책이 필요하다.
ClinSeekAgent는 그 정책을 benchmark와 training data 양쪽에서 관찰 가능한 trajectory로 만든다.
무엇을 해결하려는가
기존 의료 LLM 평가와 EHR benchmark는 대부분 curated-evidence paradigm 위에 있었다. source benchmark나 사람이 미리 task-relevant patient information을 골라 주고, 모델은 그 컨텍스트 안에서 다음 이벤트, 위험도, phenotype, 영상 finding을 예측한다.
이 접근은 재현성과 비교 가능성은 좋지만, 실제 임상 workflow의 “어디를 찾아봐야 하는가” 문제를 가린다.
ClinSeekAgent가 바꾸는 축은 입력의 형태다.
Curated Input setting에서는 모델이 source benchmark가 준비한 evidence package를 받는다.
Automated Evidence-Seeking setting에서는 그 context를 제거하고, 같은 task instruction과 label을 유지한 채 patient ID, reference timestamp, optional image identifier, 그리고 도구 접근권만 준다.
모델은 prediction cutoff 이후의 정보에 접근할 수 없고, 필요한 근거를 tool call로 모아야 한다.
이 차이는 단순한 프롬프트 변형이 아니다.
위험 예측처럼 환자 기록 전반에 흩어진 sparse signal을 찾아야 하는 작업에서는 curated context가 놓친 증거를 agent가 직접 찾을 수 있다.
반대로 next-row decision making처럼 최근 row-local pattern이 중요한 작업에서는 넓은 검색이 오히려 방해가 될 수 있다.
논문의 좋은 점은 이 양면성을 숨기지 않고, 어떤 task family에서 active search가 이득이고 어디서 손해인지 분리해 보여 준다는 데 있다.
핵심 아이디어 / 구조 / 동작 방식
ClinSeekAgent의 task instance는 patient identifier, reference timestamp 또는 prediction time, clinical task instruction, optional modality metadata, answer schema로 정의된다. inference 중 모델은 curated patient context를 받지 않는다.
대신 이전 tool action과 observation history를 보면서 다음 도구를 호출할지, 최종 답을 낼지 결정한다.
EHR task에서는 먼저 ehr.load_ehr로 patient-specific database를 열고, 모든 EHR query는 reference timestamp 이전 기록으로 제한된다.
도구 공간은 세 종류의 근거원을 포괄한다.
| 근거원 | 도구 수 | 역할 | 실무적으로 읽히는 의미 |
|---|---|---|---|
| EHR retrieval | 11 | schema inspection, temporal retrieval, SQL query, candidate-term grounding | 환자별 longitudinal record를 programmable database처럼 탐색 |
| Web / browser | 3 | external medical knowledge search, page open, in-page find | benchmark taxonomy나 의학적 정의를 외부 지식으로 보강 |
| Medical image | 6 | DICOM preprocessing, CXR classification, report generation, phrase grounding, anatomical segmentation | 모델의 native vision만이 아니라 전문 영상 도구 출력을 근거로 사용 |
중요한 설계는 retrieval 순서를 고정하지 않았다는 점이다. task에 따라 모델은 EHR schema부터 볼 수도 있고, X-ray classifier를 먼저 부를 수도 있으며, SQL query와 browser search를 여러 turn에 걸쳐 섞을 수도 있다.
즉 ClinSeekAgent는 “어떤 evidence source를 언제 쓸 것인가”를 규칙으로 쓰는 pipeline이 아니라, agentic model이 도구 사용 정책을 드러내는 환경에 가깝다.
ClinSeek-Bench는 이 환경을 평가하기 위한 paired benchmark다. text-only evaluation은 EHR-R1의 EHR-Bench에서 45개 EHR analysis subtask를 가져와 각 subtask당 40개씩, 총 1,800개 예제를 만든다. multimodal evaluation은 MIMIC-IV EHR과 MIMIC-CXR 기반의 EHRXQA, MedMod를 재구성해 989개 예제를 만든다.
여섯 task group은 CXR finding presence, CXR finding enumeration, CXR temporal change comparison, 24-hour decompensation prediction, in-hospital mortality prediction, phenotype prediction이다.
평가의 핵심은 같은 task와 label을 두 접근 방식으로 동시에 본다는 점이다.
Curated Input은 source benchmark가 제공한 evidence package를 쓰고, ClinSeekAgent는 raw data와 tools만으로 같은 답을 찾아야 한다.
그래서 점수 차이는 단순히 모델 지식 차이가 아니라, evidence access pattern 자체가 바뀌었을 때 생기는 차이로 읽을 수 있다.
공개된 근거에서 확인되는 점
text-only EHR task에서는 결과가 task family별로 갈린다.
Claude Opus 4.6은 overall F1이 Curated Input 60.0에서 ClinSeekAgent 63.2로 올라가며 +3.2를 얻는다.
MiniMax M2.5도 43.1에서 47.3으로 +4.2다.
하지만 여러 open-source 또는 mid-sized 모델은 overall에서 정체하거나 떨어진다.
Qwen3.5-35B-A3B는 거의 동률이고, Kimi K2.5와 Qwen3-VL-235B는 Curated Input보다 낮다.
더 중요한 패턴은 risk prediction과 decision making의 분리다. risk prediction에서는 9개 평가 agent 중 7개가 ClinSeekAgent에서 평균 gain을 보인다.
Claude Opus 4.6은 risk prediction에서 81.0에서 90.7로 +9.7, MiniMax M2.5는 68.4에서 86.7로 +18.3을 얻는다.
반면 decision making에서는 많은 모델이 하락한다.
예를 들어 Claude Opus 4.6도 45.9에서 44.8로 -1.1이고, Qwen3.5-35B-A3B는 29.0에서 22.0으로 내려간다.
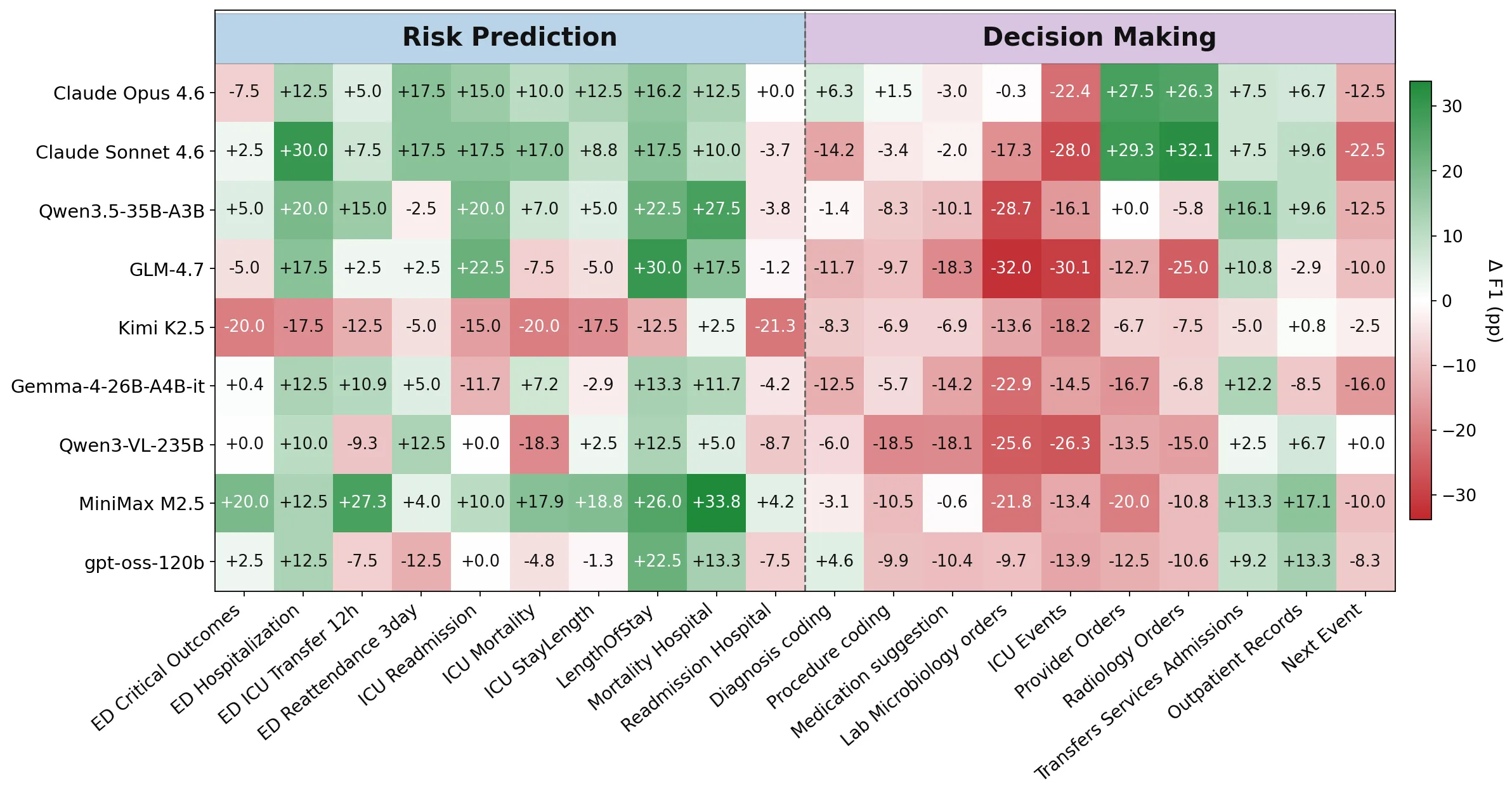
multimodal task에서는 active evidence seeking의 장점이 더 넓게 나타난다.
Claude Opus 4.6은 multimodal overall F1이 47.5에서 62.6으로 +15.1 올라가고, Claude Sonnet 4.6은 48.0에서 54.9로 +6.9 오른다.
Qwen3-VL-235B는 +5.9, Gemma-4-26B-A4B-it은 +6.7을 얻는다.
Kimi K2.5만 overall에서 -0.6으로 소폭 하락한다.
| 비교 지점 | Curated Input | ClinSeekAgent | 변화 | 해석 |
|---|---|---|---|---|
| Claude Opus 4.6, text-only overall | 60.0 | 63.2 | +3.2 | strong agentic model에서는 raw EHR search가 일부 이득 |
| Claude Opus 4.6, risk prediction | 81.0 | 90.7 | +9.7 | sparse longitudinal signal을 직접 찾는 setting이 유리 |
| Claude Opus 4.6, multimodal overall | 47.5 | 62.6 | +15.1 | CXR, EHR, 외부 지식 조합에서 active search 효과가 큼 |
| MiniMax M2.5, text-only overall | 43.1 | 47.3 | +4.2 | risk prediction gain이 decision-making 손실을 상쇄 |
| Qwen3.5-35B-A3B, decision making | 29.0 | 22.0 | -7.0 | 넓은 retrieval이 row-local pattern 포착을 방해할 수 있음 |
논문의 case study는 이 차이를 잘 보여 준다. phenotype question에서 ClinSeekAgent는 흉부 X-ray 분석 도구를 호출하고, ICU event를 SQL로 조회하고, browser search로 25-phenotype taxonomy를 확인한다.
이 조합으로 F1 83.3을 얻지만, Curated Input baseline은 imaging evidence가 부족해 실패한다.
즉 multimodal clinical reasoning에서 “이미지와 EHR을 같이 넣었다”보다 더 중요한 것은, 어떤 순서로 어떤 근거를 끌어와 답의 공간을 좁혔는가다.

training-time 결과도 중요하다.
저자들은 Claude Opus 4.6을 teacher로 삼아 ClinSeekAgent trajectory를 만들고, Qwen3.5-35B-A3B를 native tool-call format으로 SFT한다.
설정은 52K token maximum sequence length, 7,204 / 147 train-validation examples after filtering, 3 epochs, global batch size 32, 8×H200, Megatron + mbridge backend다.
그 결과 ClinSeek-35B-A3B는 AgentEHR-Bench five-task evaluation에서 Qwen3.5-35B-A3B base의 평균 F1 22.1을 34.0으로 끌어올린다. +11.9 point 개선이다.
논문 기준으로 이는 평가된 open-source 모델 중 가장 높은 값이며, Claude Opus 4.6의 36.0에 대해 94.4% 수준까지 접근한다.
Diagnoses는 +18.8, Labs는 +20.8, Microbiology는 +11.4, Procedures는 +9.8이지만 Transfers는 -1.4로 소폭 하락한다.
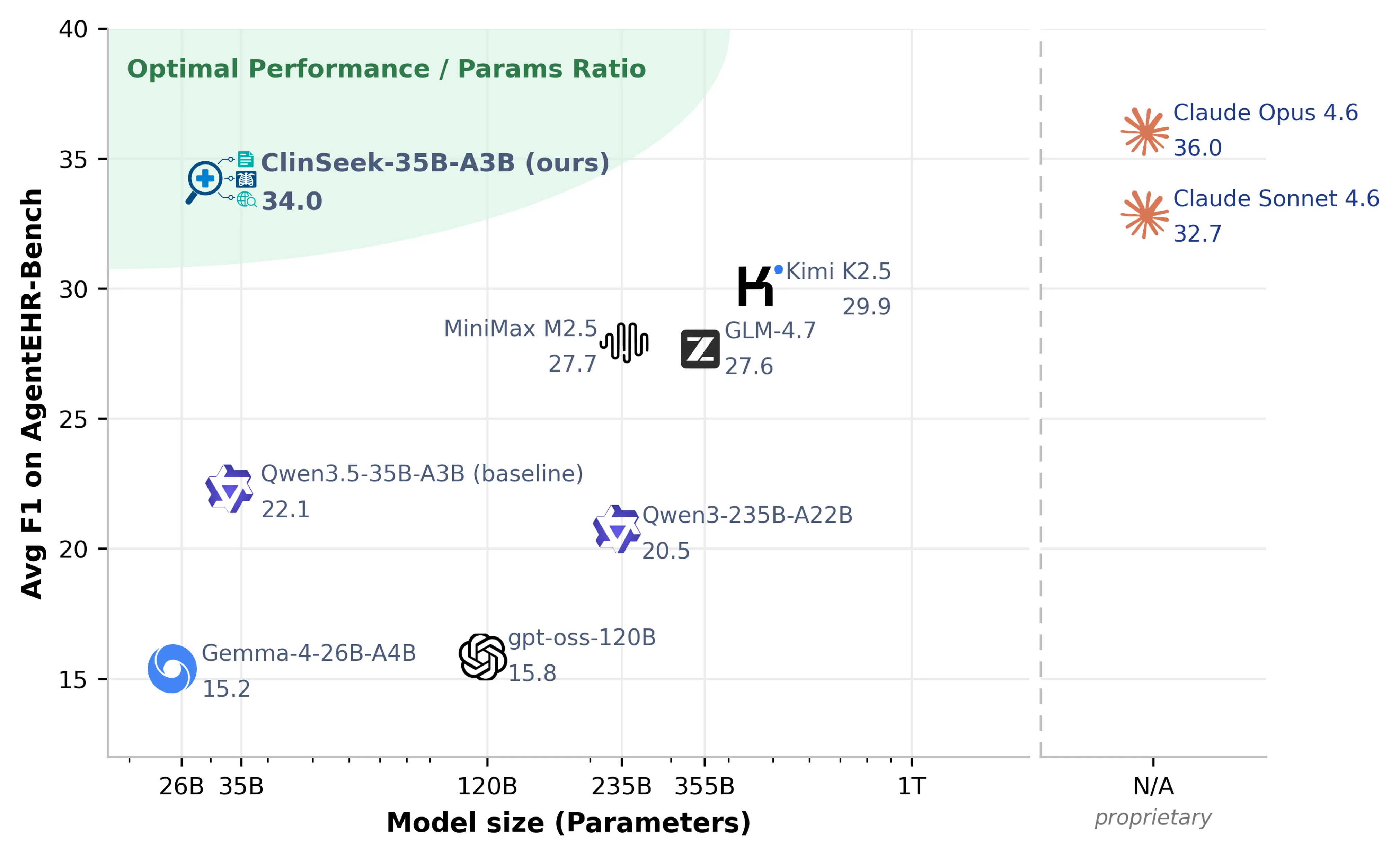
흥미로운 것은 SFT가 tool call 수를 단순히 줄이지 않았다는 점이다.
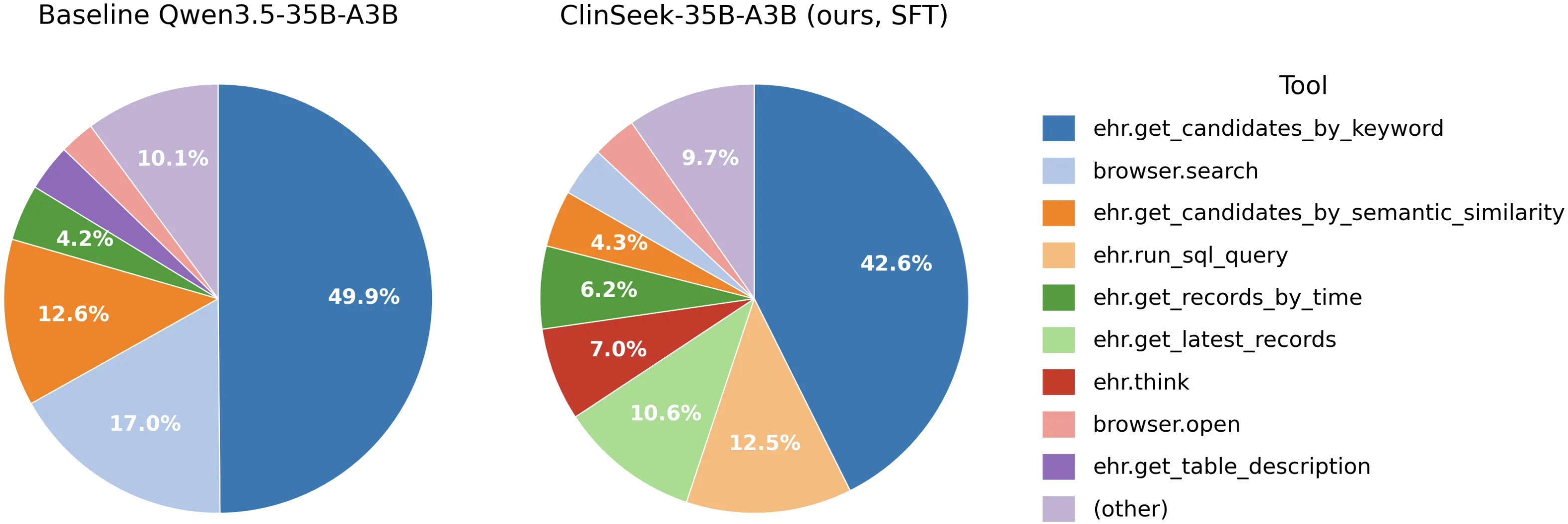
같은 500개 AgentEHR-Bench question에서 base model은 33,043 tool calls, ClinSeek-35B-A3B는 31,446 tool calls를 만든다.
총량은 크게 변하지 않지만 분포가 바뀐다.
특히 ehr.run_sql_query 사용 비중이 2.0%에서 12.5%로 증가한다.
논문의 해석처럼 이것은 final answer imitation만이 아니라, EHR을 고정 retrieval template이 아닌 programmable database로 다루는 절차적 행동이 일부 전이됐다는 신호다.
공개 artifact도 비교적 구체적이다.
GitHub 저장소는 Apache-2.0 라이선스이며, agent driver, EHR MCP server, image MCP server, public launch scripts, vendored VERL SFT recipe, synthetic manifest examples를 포함한다.
다만 README는 raw MIMIC data, generated patient databases, chest X-ray files, private trajectories, model weights, experiment logs를 GitHub에 포함하지 않는다고 명시한다.
데이터와 모델은 Hugging Face collection으로 분리되어 있고, Hub API 기준 ClinSeek-Bench, ClinSeek-Evaluation-Results, ClinSeek-35B-A3B가 공개되어 있다.
| 공개 표면 | 확인되는 내용 | 주의해서 읽을 점 |
|---|---|---|
| arXiv / project page | paper, benchmark 구조, figure, headline result | method와 결과 해석의 1차 근거 |
GitHub UCSC-VLAA/ClinSeekAgent |
Apache-2.0 code release, MCP servers, evaluation/SFT scripts, docs | raw clinical data와 private trajectory/log는 포함되지 않음 |
Hugging Face ClinSeek-Bench |
text-only / multimodal benchmark files 공개 | dataset card license는 other; 원천 MIMIC 계열 access 조건을 별도로 봐야 함 |
Hugging Face ClinSeek-35B-A3B |
Qwen3.5-35B-A3B 기반 SFT model checkpoint, Apache-2.0 tag | 임상 배치용 검증이 아니라 research artifact로 봐야 함 |
| Hugging Face evaluation results | model × mode × task scoring artifacts | 재현 분석에는 유용하지만 운영 배치 성능을 보장하지 않음 |
실무 관점에서의 해석
ClinSeekAgent의 가장 큰 의미는 의료 AI에 국한되지 않는다.
많은 agent benchmark는 아직 “주어진 컨텍스트에서 잘 답하는가”와 “컨텍스트를 잘 찾아오는가”를 분리하지 못한다.
ClinSeekAgent는 이 둘을 같은 task-label pair 안에서 비교한다.
같은 환자, 같은 질문, 같은 정답을 두고, 하나는 curated package를 주고 다른 하나는 raw source와 tool interface만 준다.
이 paired design은 agentic RAG나 enterprise data agent 평가에도 그대로 가져올 수 있는 구조다.
제품 관점에서 보면 ClinSeekAgent는 retrieval layer를 단순 검색기로 보지 않는다.
EHR schema inspection, temporal retrieval, SQL aggregation, candidate grounding, CXR tool, browser search가 모두 agent의 action space 안에 들어간다.
따라서 성능은 “좋은 embedding model을 붙였는가”가 아니라, 모델이 언제 schema를 보고, 언제 SQL을 쓰고, 언제 외부 지식으로 label space를 확인하며, 언제 충분하다고 멈추는지에 의해 결정된다.
이것이 clinical agent든 내부 데이터 분석 agent든 장기적으로 중요한 차이다.
다만 이 논문을 “active search가 항상 curated context보다 좋다”로 읽으면 안 된다. decision-making task에서의 하락은 오히려 핵심 경고다.
넓은 검색 권한은 정보량을 늘리지만, row-local 또는 최근 패턴을 봐야 하는 문제에서는 noise와 distractor를 늘릴 수 있다.
좋은 agent system은 더 많은 도구를 주는 것만으로 끝나지 않고, task family에 따라 검색 폭, recency bias, table-local attention, stop criterion을 조절하는 정책을 가져야 한다.
또 하나의 중요한 한계는 teacher trajectory의 품질이다.
논문 appendix는 Claude Opus 4.6 trajectory가 항상 tool-efficient하지 않으며, redundant 또는 low-value tool call이 context window를 오염시키고 학생에게 비효율적 행동을 가르칠 수 있다고 적는다.
ClinSeek-35B-A3B가 SQL 사용을 늘린 것은 좋은 신호지만, 다음 단계는 단순 SFT가 아니라 trajectory refinement, filtering, compression, 그리고 성공적이면서도 간결한 evidence seeking을 직접 최적화하는 RL 쪽으로 갈 가능성이 크다.
의료 도메인에서는 배치 해석도 보수적이어야 한다.
GitHub README의 responsible-use 문구처럼 ClinSeekAgent는 clinical evidence seeking 연구용 artifact이지, 별도 검증·거버넌스·규제 검토 없이 diagnosis, treatment, triage, patient management에 쓰기 위한 medical device가 아니다.
특히 MIMIC 계열 데이터 접근, 환자 개인정보, 기관별 EHR schema 차이, 영상 도구의 calibration 문제는 benchmark 점수와 별개의 deployment gate다.
그럼에도 이 논문은 “임상 에이전트가 답을 잘하는가”보다 더 실전적인 질문을 남긴다.
모델이 어떤 근거를 찾아야 하는지 스스로 결정할 수 있는가, 그리고 그 근거 찾기 행동을 더 작은 공개 모델에 이전할 수 있는가.
ClinSeekAgent의 답은 아직 완성형 제품이라기보다, 이 질문을 benchmark, tool environment, trajectory distillation이라는 세 층으로 동시에 묶은 research system에 가깝다.
그래서 이 작업의 핵심 가치는 점수 하나보다, agentic clinical reasoning을 evidence access pattern의 문제로 재정의했다는 데 있다.